") 芯來科技與華東師范大學(xué)SOLE實(shí)驗(yàn)室合作推動(dòng)LLVM/CLANG編譯器優(yōu)化
芯來科技與華東師范大學(xué)SOLE實(shí)驗(yàn)室合作推動(dòng)LLVM/CLANG編譯器優(yōu)化
隨著RISC-V這一革命性的開源指令集架構(gòu)在全球范圍內(nèi)的迅速普及,它為半導(dǎo)體行業(yè)帶來了前所未有的機(jī)遇與挑戰(zhàn)。在此大背景下,芯來科技和華東師范大學(xué)SOLE實(shí)驗(yàn)室攜手合作,致力于在RISC-V處理器上進(jìn)行深入的LLVM/CLANG編譯器優(yōu)化以及程序性能優(yōu)化和調(diào)優(yōu)。
我們不僅優(yōu)化了LLVM編譯器的多個(gè)關(guān)鍵環(huán)節(jié),提升了代碼生成效率和執(zhí)行性能,還針對視頻編解碼、性能測試等應(yīng)用場景進(jìn)行了深入分析和優(yōu)化,提高了相關(guān)軟件的執(zhí)行效率。
此次合作在RISC-V處理器上實(shí)現(xiàn)了一定程度的性能提升,同時(shí),我們也希望能夠?yàn)镽ISC-V性能優(yōu)化領(lǐng)域的同仁們提供一些有益的借鑒和參考。我們相信,通過持續(xù)的技術(shù)創(chuàng)新和開放的合作精神,我們可以共同推動(dòng)這一領(lǐng)域的發(fā)展和進(jìn)步。下面是我們本次合作的主要成果。
一、MCPPass冗余指令的刪除優(yōu)化
在LLVM-17.x版本當(dāng)中,生成的RISC-V端代碼會(huì)出現(xiàn)冗余數(shù)據(jù)搬運(yùn)指令無法刪除的問題,詳情如下圖所示。在兩個(gè)紅框顯示的vmv指令當(dāng)中,v0以及v8寄存器的值都沒有得到改變,但LLVM最終生成的RISC-V代碼依然會(huì)對這兩個(gè)值進(jìn)行重復(fù)搬運(yùn)。

冗余vmv指令無法在LLVM/Clang中消除的示例
經(jīng)過核查,出現(xiàn)該問題的根因是LLVM的Machine Copy Propagation Pass對寄存器使用的Def-Use記錄不當(dāng)所導(dǎo)致。經(jīng)過對該問題進(jìn)行修復(fù)后,該工作已經(jīng)提交到了LLVM的上游倉庫。該優(yōu)化亦應(yīng)用到了LLVM多個(gè)后端的代碼生成當(dāng)中,如RISC-V、X86以及AMDGPU的后端代碼生成當(dāng)中。
二、RVV的低精度數(shù)據(jù)向量化取余以及右移代碼生成優(yōu)化
C語言會(huì)采用Promotion Rule來保證混合精度或者是低精度數(shù)據(jù)運(yùn)算結(jié)果的準(zhǔn)確性,當(dāng)遇到低精度數(shù)據(jù)如int8或者int16類型的數(shù)據(jù)進(jìn)行逐元素(Element-Wise)取余或者是算術(shù)右移操作時(shí),會(huì)先將相應(yīng)的數(shù)據(jù)提升至32位,再將結(jié)果進(jìn)行截?cái)嘀猎瓉淼木纫员WC運(yùn)算結(jié)果的正確性。然而,取決于RVV 1.0指令集動(dòng)態(tài)調(diào)整元素大小的特性,該過程需要一系列的vsetvli類指令進(jìn)行操作。
考慮到相關(guān)的計(jì)算溢出結(jié)果以及指令的行為在RVV 1.0指令集中已經(jīng)得到明確定義,在LLVM編譯器生成相關(guān)代碼時(shí)可以進(jìn)行下圖所示的優(yōu)化:
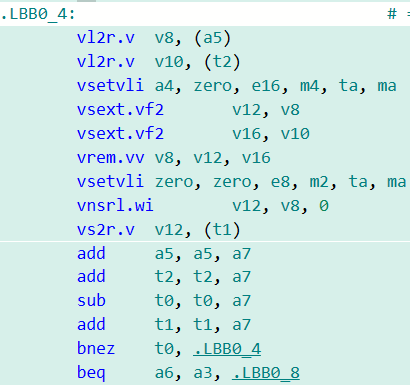
Element-wise vrem.vv優(yōu)化前

Element-wise vrem.vv優(yōu)化后

Element-wise vsra.vv優(yōu)化前

Element-wise vsra.vv優(yōu)化后 這些優(yōu)化不僅可以從指令的語義上保證計(jì)算結(jié)果的正確性,而且能有效地避免頻繁復(fù)雜的數(shù)據(jù)精度提升與下降操作,這些優(yōu)化工作亦被提交到了LLVM的上游倉庫當(dāng)中。
三、FFMPEGX264編解碼熱點(diǎn)采集分析
RISC-V Vector 1.0向量化指令集可以被用于視頻編解碼應(yīng)用的加速處理當(dāng)中,而FFMPEG作為最常見的音視頻處理軟件之一,在其關(guān)鍵核心且可向量化函數(shù)當(dāng)中,大部分亦都利用RVV 1.0匯編或者Intrinsic進(jìn)行了重寫。盡管如此,如何針對其常用的x264編解碼功能進(jìn)行編譯優(yōu)化機(jī)會(huì)的探索,依然是提高其執(zhí)行效率的一個(gè)重要手段。
我們采集對比了GCC 14.1與LLVM/Clang 17.2編譯出來的FFMPEG,在進(jìn)行x264視頻編解碼時(shí)的熱點(diǎn)函數(shù),詳情下圖所示。根據(jù)結(jié)果可以看到,熱點(diǎn)函數(shù)都聚集在了libx264的x264_piexel_sad類函數(shù)之上。
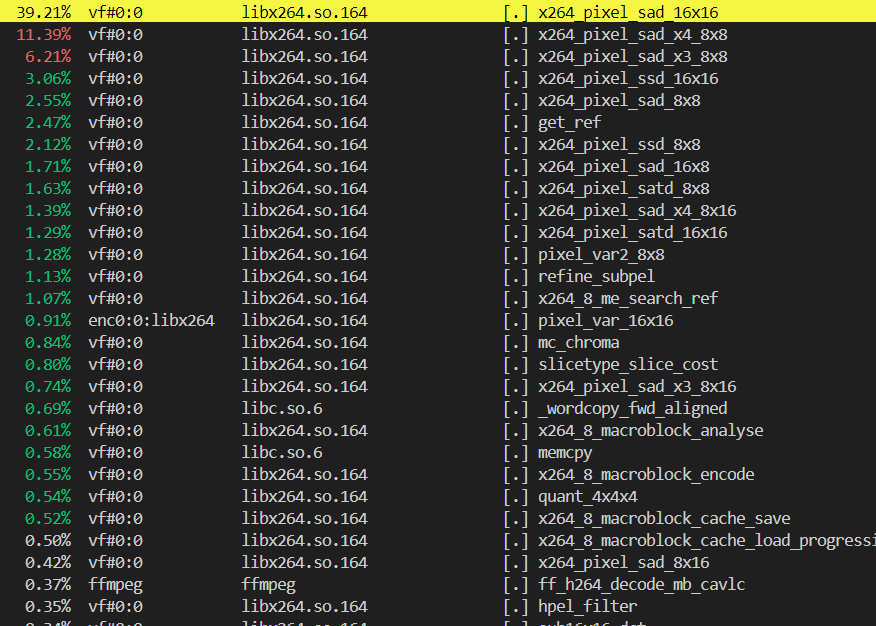
FFMPEG X264編碼熱點(diǎn)分析(GCC)

FFMPEG X264編碼熱點(diǎn)分析(LLVM/Clang)
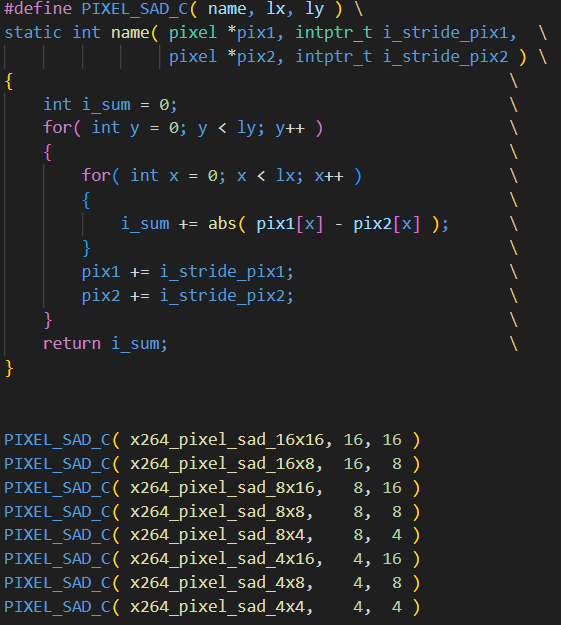
x264_pixel_sad類函數(shù)聲明
而這類x264_piexel_sad函數(shù)本質(zhì)上就是一系列的abs函數(shù)的處理,這類函數(shù)的定義可以如上圖所示。
以16x16的迭代大小為例子,下面的圖分別對比了LLVM/Clang以及GCC在該函數(shù)上生成代碼的細(xì)致區(qū)別(開啟-O3)。
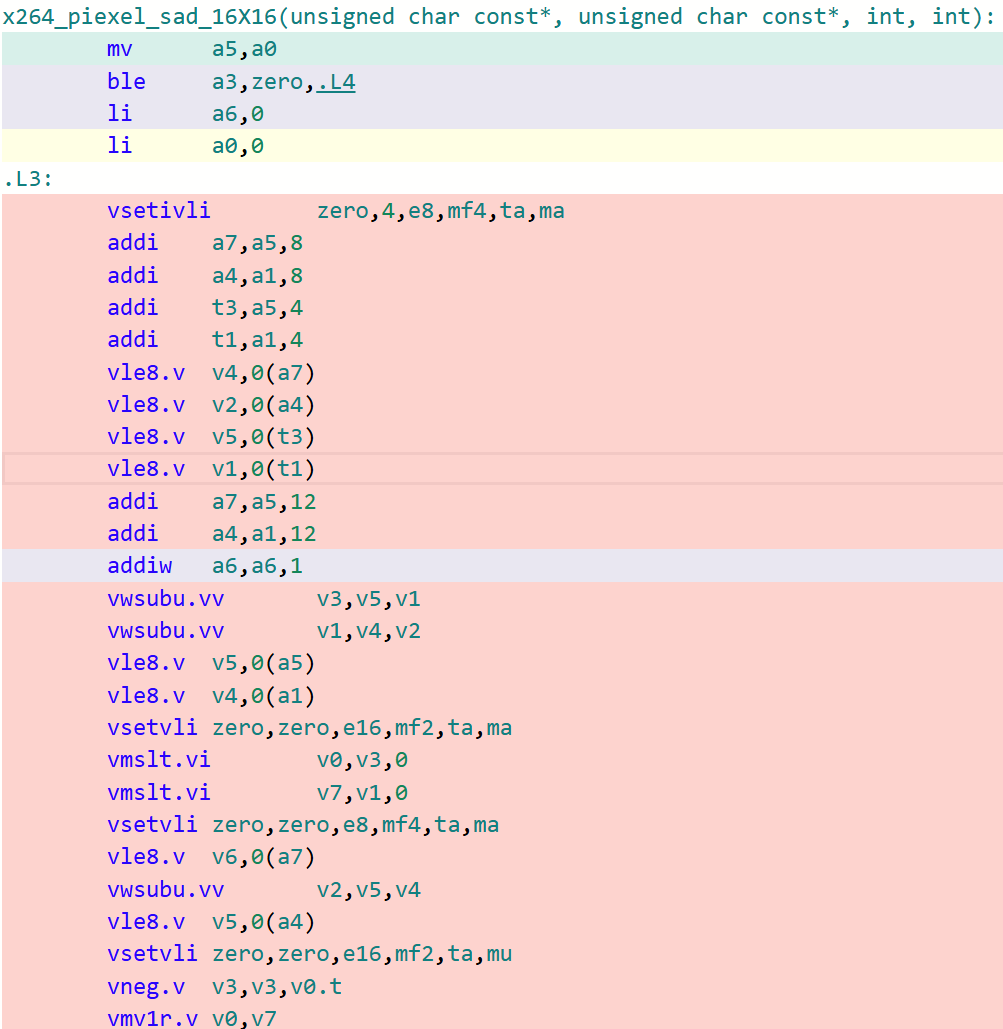
x264_piexel_sad_16x16函數(shù) GCC生成代碼
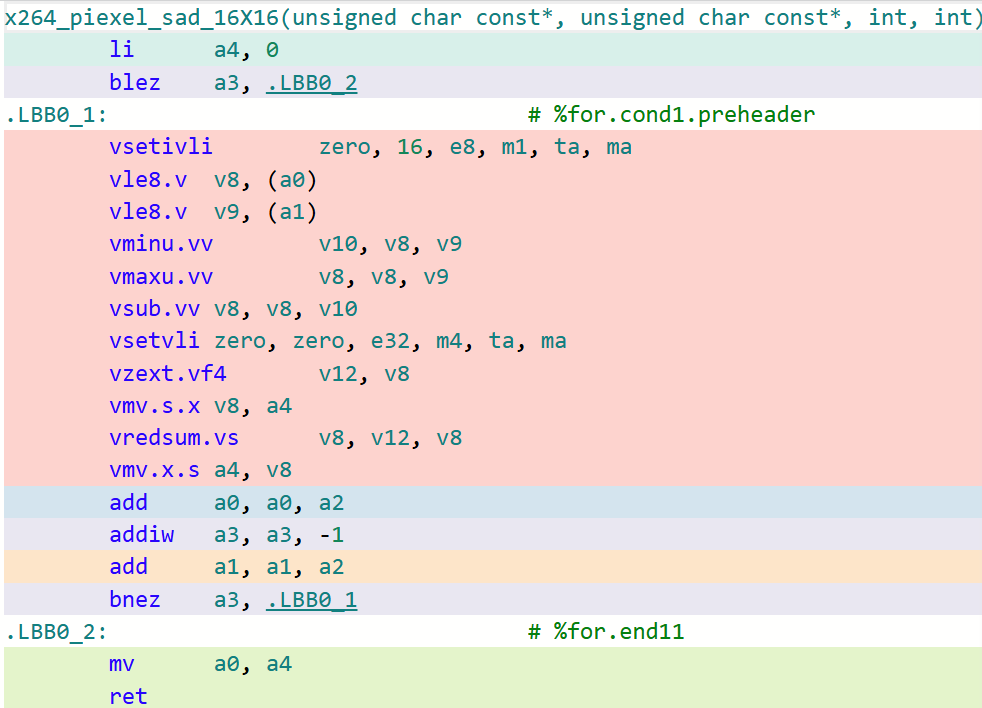
x264_piexel_sad_16x16函數(shù) LLVM/Clang生成代碼
可以看到,在默認(rèn)O3的選項(xiàng)下,GCC生成的代碼對于這類核心函數(shù)的處理效率遠(yuǎn)不如LLVM/Clang。這是因?yàn)镚CC默認(rèn)采用LMUL=1(向量化分組大小為1)的大小進(jìn)行代碼生成,即其生成的RVV代碼采用的LMUL大小不能高于1。在探索到這些根因后,可以采用GCC最新14.1版本中所提供的-mrvv-max-lmul=dynamic選項(xiàng)對這類生成的代碼進(jìn)行改進(jìn),采用該選項(xiàng)優(yōu)化后的代碼如下圖所示:

LMUL設(shè)置為dyanamic時(shí)GCC生成的代碼
此時(shí),GCC在此處生成的代碼執(zhí)行效率已經(jīng)能夠和LLVM/Clang相匹配。因此,我們在采用GCC編譯的FFMPEG進(jìn)行x264視頻編解碼時(shí),為了更高的核心代碼執(zhí)行效率,建議將GCC動(dòng)態(tài)調(diào)整LMUL大小的編譯選項(xiàng)進(jìn)行開啟。
四、CoreMark的JumpThreading優(yōu)化
Coremark是評估CPU性能常見的一個(gè)測試程序,但是采用LLVM/Clang編譯器編譯優(yōu)化coremark程序跑分效果遠(yuǎn)遠(yuǎn)比不上GCC,因此我們分析了Coremark程序的熱點(diǎn)函數(shù),發(fā)現(xiàn)可以通過Jump Threading技術(shù)來進(jìn)行優(yōu)化,Jump Threading是一種專門用于控制流程圖(CFG)優(yōu)化的一種編譯優(yōu)化技術(shù),它會(huì)在執(zhí)行分支前遇到確定變量的值時(shí),直接執(zhí)行確認(rèn)值在分支以后的路徑,即采用無條件的跳轉(zhuǎn)替代條件跳轉(zhuǎn),詳情如下圖所示:
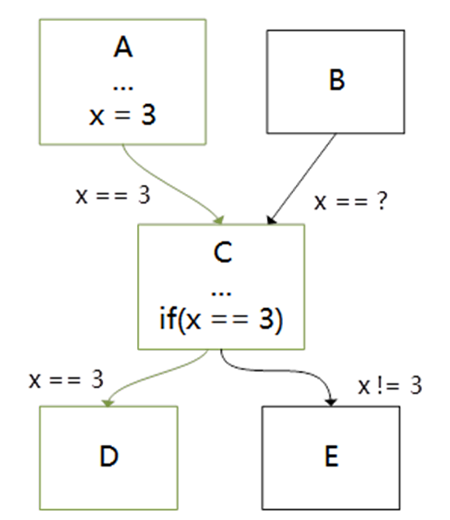
優(yōu)化前的CFG
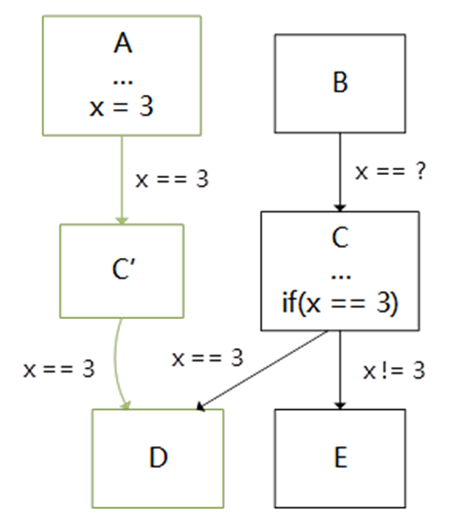
優(yōu)化后的CFG
該優(yōu)化會(huì)對CFG路徑中變量的值進(jìn)行掃描遍歷,并尋找到可以利用無條件跳轉(zhuǎn)替換條件判斷的路徑,并進(jìn)行基本塊的克隆與路徑的替換。考慮到該掃描過程較為耗時(shí),LLVM中默認(rèn)的Jump Threading優(yōu)化采取較為輕量級的掃描方式。通過在芯來編譯工具鏈的LLVM/Clang中引入一系列更為激烈的Jump Threading掃描優(yōu)化手段后,將采用Clang編譯的CoreMark并運(yùn)行在芯來N300模擬器上的跑分提升約18%。
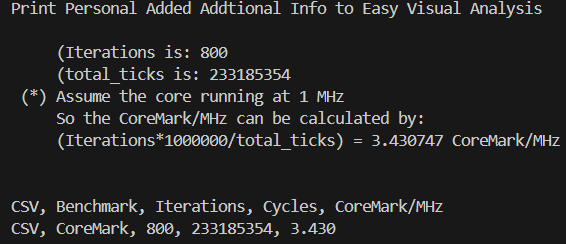
LLVM/Clang調(diào)優(yōu)前CoreMark跑分
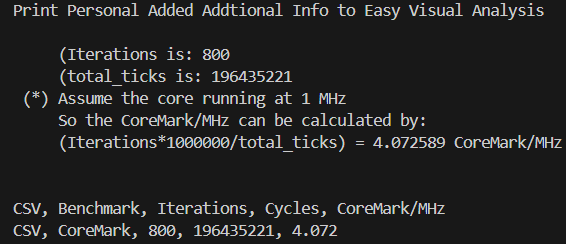
引入額外Jump Threading優(yōu)化后的CoreMark跑分
五、SPECCPU2006的編譯選項(xiàng)調(diào)優(yōu)
SPEC CPU 2006 INT是業(yè)界常用的CPU性能基準(zhǔn)測試套件,為了提高SPEC CPU 2006 INT的測試跑分,常常需要找到更適合的編譯選項(xiàng)來對編譯器進(jìn)行調(diào)優(yōu),以獲得更好的SPEC分?jǐn)?shù)。然而,考慮到目前大部分的最佳跑分配置都是利用業(yè)界專用編譯器,如Intel的ICC編譯器以及AMD的AOCC編譯器等進(jìn)行跑分。對于RISC-V指令集架構(gòu)平臺,這類專用的編譯器并不能夠適用。同時(shí),假如采用Ref測試集來進(jìn)行編譯選項(xiàng)的調(diào)優(yōu),則需要消耗大量的測試時(shí)間。
為了加速調(diào)優(yōu),我們采用了一種更為靈活且快捷的基于Qemu仿真器的動(dòng)態(tài)指令計(jì)數(shù)對比的編譯選項(xiàng)調(diào)優(yōu)方法。下圖展示了采用GCC-13對SPEC CPU2006 INT的TEST測試集進(jìn)行選項(xiàng)調(diào)優(yōu)的結(jié)果。
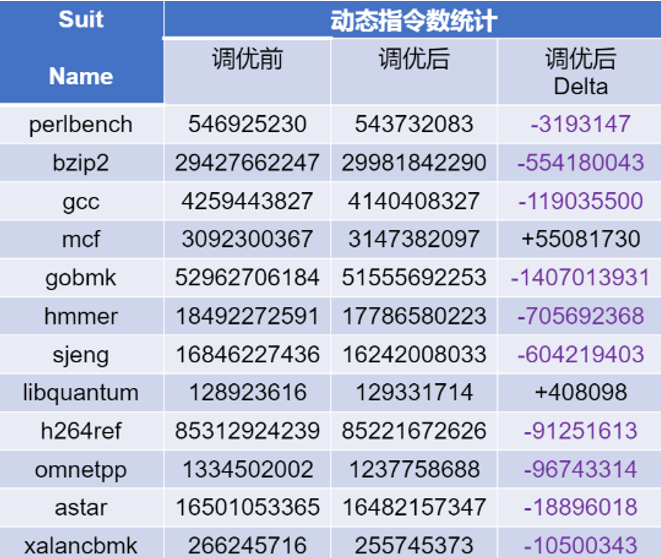
SPEC CPU 2006 INT動(dòng)態(tài)指令數(shù)目調(diào)優(yōu)結(jié)果
經(jīng)過精心調(diào)優(yōu)的編譯選項(xiàng)在SPEC CPU2006 INT的多項(xiàng)測試程序中顯著降低了動(dòng)態(tài)指令的數(shù)量。進(jìn)一步地,我們在FPGA開發(fā)板上進(jìn)行了實(shí)際的性能對比測試。結(jié)果表明,這種基于動(dòng)態(tài)指令計(jì)數(shù)的調(diào)優(yōu)方法不僅有效,而且在資源受限的開發(fā)板或仿真CPU主頻受限的FPGA環(huán)境中,為編譯選項(xiàng)的優(yōu)化提供了一種切實(shí)可行的策略。這一發(fā)現(xiàn)為在類似條件下的性能提升開辟了新的探索路徑。
此次合作是雙方在技術(shù)研究和應(yīng)用開發(fā)領(lǐng)域共同努力的成果,它體現(xiàn)了我們團(tuán)隊(duì)在探索和實(shí)踐過程中的專注與努力。同時(shí),我們對于能夠參與到產(chǎn)學(xué)研合作這一推動(dòng)技術(shù)革新的重要力量中來而深感榮幸。相信通過這樣的合作模式,我們能夠與業(yè)界同仁共同學(xué)習(xí)、相互啟發(fā),為整個(gè)技術(shù)社區(qū)的發(fā)展貢獻(xiàn)綿薄之力。
審核編輯:彭菁
-
代碼
+關(guān)注
關(guān)注
30文章
4825瀏覽量
69045 -
編譯器
+關(guān)注
關(guān)注
1文章
1642瀏覽量
49284 -
視頻編解碼
+關(guān)注
關(guān)注
2文章
54瀏覽量
11797 -
芯來科技
+關(guān)注
關(guān)注
0文章
62瀏覽量
3084
原文標(biāo)題:芯來科技與華東師范大學(xué)SOLE實(shí)驗(yàn)室合作推動(dòng)RISC-V性能優(yōu)化
文章出處:【微信號:nucleisys,微信公眾號:芯來科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
龍芯“百芯計(jì)劃”聯(lián)合實(shí)驗(yàn)室首批高校名單揭曉
Triton編譯器的優(yōu)化技巧
Triton編譯器與其他編譯器的比較
深開鴻與華南師范大學(xué)簽署戰(zhàn)略合作框架協(xié)議,共探產(chǎn)學(xué)研協(xié)同創(chuàng)新

HighTec C/C++編譯器套件全面支持芯來RISC-V IP
DFRobot與西北師范大學(xué)教育技術(shù)學(xué)院簽署院企協(xié)同育人暨戰(zhàn)略合作協(xié)議
分享關(guān)于編譯器的科普
Keil編譯器優(yōu)化方法
龍芯中科與南京師范大學(xué)達(dá)成產(chǎn)教合作
華東師范大學(xué)的老師 上課已經(jīng)用上了大模型
SEGGER編譯器優(yōu)化和安全技術(shù)介紹 支持最新C和C++語言

采用OpenACC框架的FVCOM模型實(shí)現(xiàn)超百倍計(jì)算加速

科大訊飛與華中師范大學(xué)合作 大模型賦能教育
浙江大學(xué)與燧原科技共建“云邊智能聯(lián)合實(shí)驗(yàn)室”
華東師范大學(xué)教授:生活中的傳感器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論