") 免費時代到來!價格戰(zhàn)帶領(lǐng)AI大模型走出商業(yè)化困局?
免費時代到來!價格戰(zhàn)帶領(lǐng)AI大模型走出商業(yè)化困局?
電子發(fā)燒友網(wǎng)報道(文/梁浩斌)大模型廠商徹底瘋狂!電商618大促剛剛開始,大模型廠商就開始輪番瘋狂降價。每千Tokens的價格,從過去幾分錢,再下降一個數(shù)量級至幾厘,甚至還有直接開放大模型全面免費試用。
大模型進入免費時代
5月21日,阿里云宣布通義千問4款商業(yè)化模型和5款開源模型大降價,其中GPT-4級別的主力模型Qwen-Long價格直降97%,從此前API輸入0.02元/千Tokens,降價至0.0005元/千Tokens;API輸出從0.02元/千Tokens,也降了90%到0.002元/千Tokens。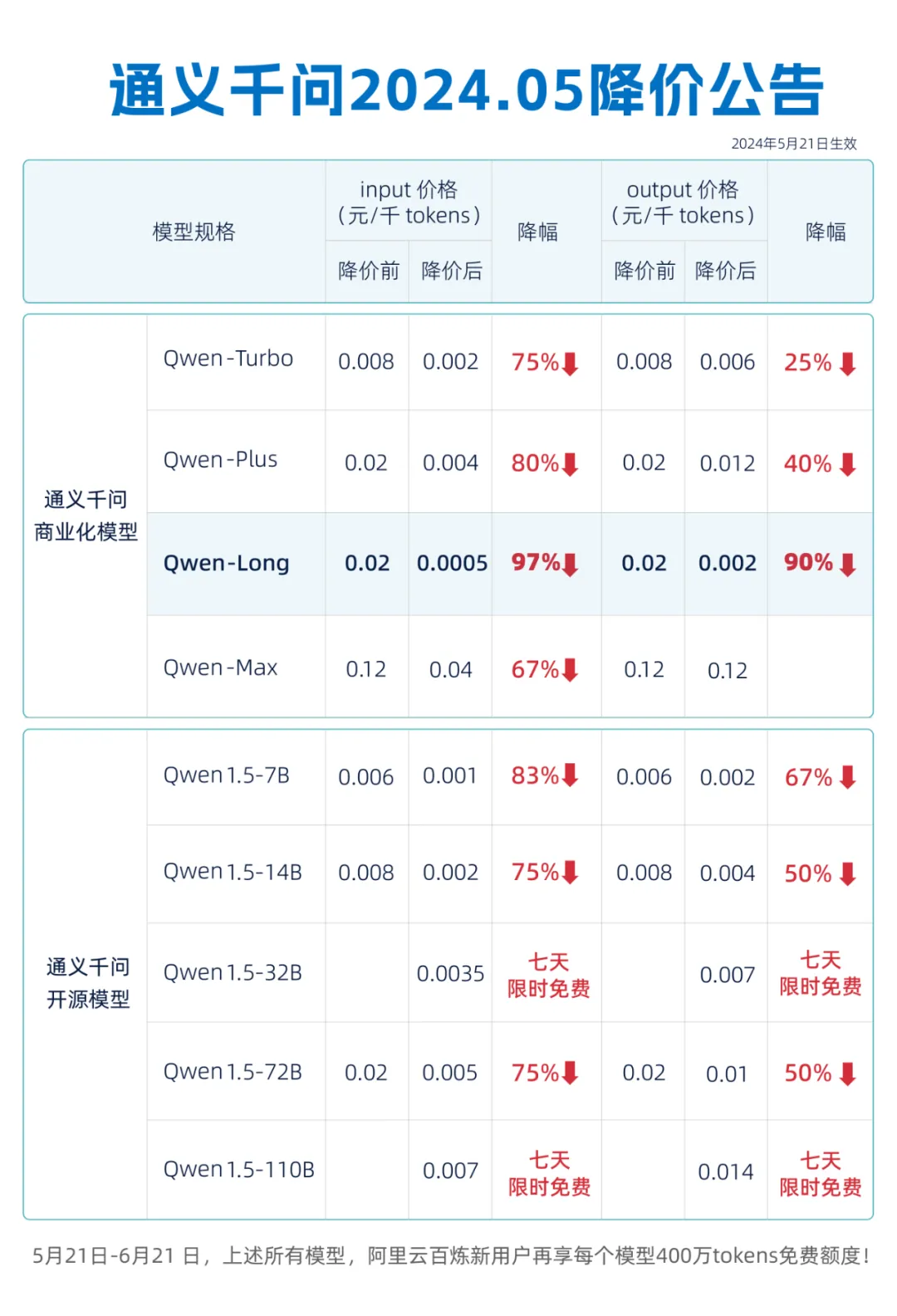
Token在自然語言處理中是指文本被分割成的最小單元或標(biāo)記,通常1個中文詞語、英文單詞、數(shù)字、符號計為 1 個Token,由于不同模型采用的分詞器不同,同一段文字可能分成不同數(shù)量的Tokens,比如在某個模型中,“使用者”被分為一個Tokens,但“大模型”就被分為“大”和“模型”兩個Tokens。粗略估算,1Tokens可以理解為相當(dāng)于1.5個中文漢字。
然而就在上午通義千問降價之后,下午百度言簡意賅,在公眾號上發(fā)文宣布:文心大模型兩大主力模型全面免費,立即生效!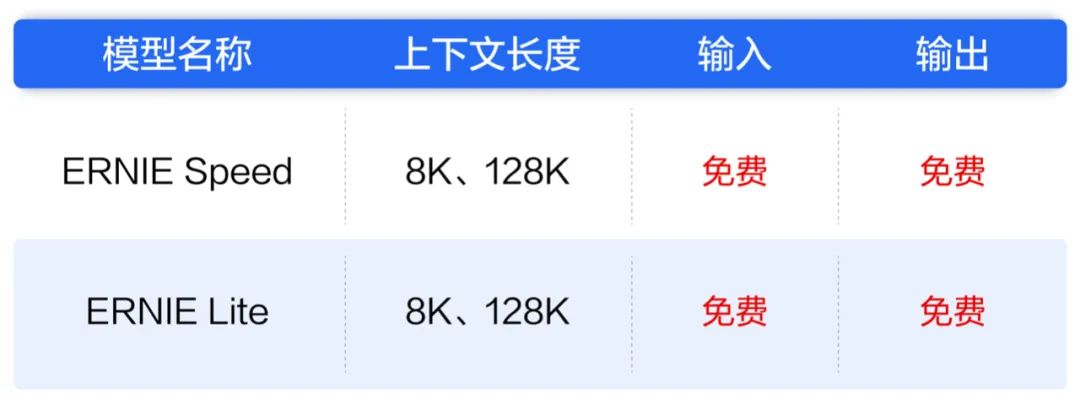
這次免費的兩大主力模型分別是ERNIE Speed和ERNIE Lite,上下文長度均支持8K、128K,均為輕量級大模型。其中ERNIE Speed適用于自然語言處理任務(wù)中的多種場景,如文本分類、命名實體識別、語義匹配等,在智能客服、搜索引擎、智能推薦等領(lǐng)域的應(yīng)用表現(xiàn)突出,在閱讀理解、close-book問答、創(chuàng)作與續(xù)寫等復(fù)雜任務(wù)上,也能達到甚至超越千億大模型的效果。
而ERNIE Lite則適合搭載在低算力的AI加速卡上處理推理任務(wù),應(yīng)用于檢索、推薦、意圖識別等高并發(fā)、低延時等場景。
在文心大模型之后,5月22日,科大訊飛也宣布旗下訊飛星火Lite API永久免費開放,此前該模型版本價格為0.018元/千Tokens。Spark Lite同樣是輕量級大語言模型,支持在線聯(lián)網(wǎng)搜索功能,適用于低算力推理與模型精調(diào)等定制化場景。

除了輕量級大模型之外,在頂配的Spark 3.5 Max版本上,價格也降到0.21-0.3元/萬Tokens,即0.021-0.03元/千Tokens,這個價格相比文心一言和通義千問同級別大模型也要更低。比如文心一言的ERNIE-4.0輸入、輸出均為0.12元/千Tokens;通義千問Qwen-Max輸入0.04元/千Tokens,輸出0.12元/千Tokens。
這一輪大模型降價,可以追溯到5月初。幻方量化旗下深度求索(DeepSeek)在5月6日正式開源第二代MoE模型DeepSeek-V2,而其API的定價為輸入1元/百萬Tokens,輸出2元/百萬Tokens,算下來大概是0.001-0.002元/千Tokens,價格幾乎是GPT-4-Turbo的百分之一。
5月11日,智譜大模型官宣降價,其中個人版 GLM-3Turbo模型產(chǎn)品的API調(diào)用價格從0.005元/千Tokens,降至0.001元/千Tokens;最頂配的GLM-4和GLM-4V價格也來到0.1元/千Tokens。
字節(jié)跳動旗下的云服務(wù)平臺火山引擎,在5月15日推出了豆包大模型家族,其中豆包主力模型的推理輸入定價僅為0.0008元/千Tokens,當(dāng)時火山引擎表示,這個價格要比行業(yè)便宜99.3%。
但大模型內(nèi)卷的趨勢,并不是“中國特色”,5月13日,OpenAI推出了新一代的大模型GPT-4o,除了性能上的大幅提升之外,更重磅的消息是該新模型將全部功能免費使用。
此前OpenAI僅免費開放GPT-3.5供用戶使用,而GPT-4是要付費使用的。但在GPT-4o發(fā)布后,不僅性能上超越GPT-4,而且還免注冊開放使用。當(dāng)然,免費用戶使用GPT-4o只能每三小時使用十次,超過10次將自動降級至GPT-3.5。
與此同時,商業(yè)用戶方面,GPT-4o的API調(diào)用價格也相比GPT-4 Turbo全面下降50%。
所以,大模型的全面降價,甚至是免費,已經(jīng)成為目前全球AI行業(yè)的趨勢。
價格戰(zhàn)是“良藥”還是“雙輸”?
在互聯(lián)網(wǎng)行業(yè),瘋狂燒錢的零和博弈打法已經(jīng)司空見慣,從電商到外賣、再到共享單車,在行業(yè)發(fā)展初期都依靠低價打開市場規(guī)模。
零一萬物創(chuàng)始人兼CEO李開復(fù)認為,大模型降價對整個行業(yè)來說是好消息,行業(yè)每年降低10倍推理成本是可以期待的,而且也應(yīng)該是必然發(fā)生的,但同時他也表示價格戰(zhàn)是一個“雙輸”的打法,大模型公司不會這樣不理智。
“當(dāng)其團隊認定自己的技術(shù)值得的時候,就會堅持一個合適的價格,而絕不會靠貼錢、賠錢去做生意。”
AI大模型的商業(yè)化,一直以來都是行業(yè)的頭號難題。首先是大模型訓(xùn)練成本居高不下,比如李飛飛團隊分析報告顯示,Google此前發(fā)布的Gemini Ultra訓(xùn)練成本高達近2億美元,OpenAI 的 GPT-4訓(xùn)練成本也預(yù)計高達7800萬美元,并且隨著時間的推移,新推出的大模型訓(xùn)練成本還在不斷提高。
而在C端應(yīng)用中,用戶留存和活躍度也正在面臨很大挑戰(zhàn),即使是ChatGPT, 自從去年六月開始流量就開始出現(xiàn)下降,大多數(shù)用戶使用ChatGPT還是基于嘗鮮的性質(zhì),而無法成為一個日常應(yīng)用。
根據(jù)QuestMobile的數(shù)據(jù),AICG的運營數(shù)據(jù)活躍率均在20%以下,3日留存均在50%以下,卸載率更是在50%以上。
所以,這也反映出目前類ChatGPT的大模型應(yīng)用,并不是目前大模型的最終表現(xiàn)形式。
而面向B端的API降價,則能夠推動AI應(yīng)用的開發(fā)。近一年里,大模型的技術(shù)能力提升速度極快,尤其是國內(nèi)的眾多玩家入局后,大模型的能力突飛猛進。
5月21日李開復(fù)公布了零一萬物團隊在國際測評榜單中的新成績, Yi-Large在 LMSYS 盲測競技場總榜排名世界第七,中國大模型中第一;其中在中文分榜中與GPT-4o并列世界第一。
他也表示在近一年時間里,中美大模型的差距從7到10年,已經(jīng)縮短到6個月左右。
因此,在當(dāng)前大模型技術(shù)發(fā)展迅速的時間節(jié)點,在投入大量資本去創(chuàng)造大模型的同時,如何讓大模型商業(yè)落地是整個行業(yè)共同希望解決的難題。畢竟只有將大模型商業(yè)化變現(xiàn),才能回收訓(xùn)練支出的高昂成本。
所以大模型降價,一定程度上能夠吸引更多的企業(yè)嘗試使用大模型開發(fā)AI應(yīng)用,通過AI應(yīng)用去創(chuàng)造更廣泛的使用場景,以實現(xiàn)“AI普及”。
當(dāng)然,大模型降價也不是盲目的。火山引擎在發(fā)布會上表示,其在技術(shù)上有很多優(yōu)化手段可以降低大模型訓(xùn)練成本,而在工程上可通過分布式推理的形式提高算力利用率等。
另一方面,大模型價格戰(zhàn),對于背靠互聯(lián)網(wǎng)業(yè)務(wù)的大廠來說,由于資金壓力較小,在市場推廣上更有優(yōu)勢。但對于一些大模型初創(chuàng)公司,市場的價格戰(zhàn)毫無疑問是加速了優(yōu)勝劣汰的節(jié)奏。
小結(jié):
對于當(dāng)前商業(yè)模式還未走通的大模型行業(yè)來說,嘗試總是好事。但重走互聯(lián)網(wǎng)時代的“零和博弈”路線,到底能否復(fù)現(xiàn)過去的成功,還要看后續(xù)的發(fā)展。
-
AI
+關(guān)注
關(guān)注
87文章
31513瀏覽量
270314 -
大模型
+關(guān)注
關(guān)注
2文章
2545瀏覽量
3163
發(fā)布評論請先 登錄
相關(guān)推薦
AI大模型的商業(yè)應(yīng)用案例分析
中軟國際大模型運營管理系統(tǒng)推動AI商業(yè)化

大模型時代的算力需求
蘿卜快跑爆火的背后,美格智能如何助力無人車商業(yè)化?
蘿卜快跑爆火的背后,美格智能如何助力無人車商業(yè)化?

不要被價格戰(zhàn)迷亂雙眼,大模型競爭的關(guān)鍵在于生態(tài)

大模型應(yīng)用商業(yè)化落地關(guān)鍵:給企業(yè)帶來真實的業(yè)務(wù)價值

英偉達GB200芯片引領(lǐng)銅纜高速連接熱潮!
數(shù)勢科技攜手書亦燒仙草,引領(lǐng)大模型商業(yè)化落地






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論