 如何處理SoC中的性能瓶頸呢?
如何處理SoC中的性能瓶頸呢?
SoC 中不斷添加處理核心,但它們不會都得到充分利用,因為真正的瓶頸沒有得到解決。
SoC 需要處理的數據量激增,雖然處理核心本身可以處理這些數據,但內存和通信帶寬成為瓶頸。現在的問題是可以采取什么措施解決這個問題。
內存和 CPU 帶寬之間的差距(即所謂的內存墻)不是一個新問題,還在繼續惡化。
早在 2016 年,德克薩斯州高級計算中心的研究科學家 John McCalpin 就發表了一次演講,研究了高性能計算 (HPC) 的內存帶寬和系統資源之間的平衡。他分析了當時排名前 500 的機器,并剖析了它們的核心性能、內存帶寬、內存延遲、互連帶寬和互連延遲。他的分析表明,每個插槽的峰值 FLOPS 每年增加 50% 到 60%,而內存帶寬每年僅增加約 23%。此外,內存延遲每年減少約 4%,互連帶寬和延遲每年增加約 20%。這些表明數據移動方面存在持續且不斷擴大的不平衡。
這意味著,如果我們傳輸數據,則每次內存傳輸所花費的時間相當于 100 次浮點算術運算。也就是說,如果無法預取并且錯過了cache,你就失去了執行超過 4,000 次浮點運算的機會。
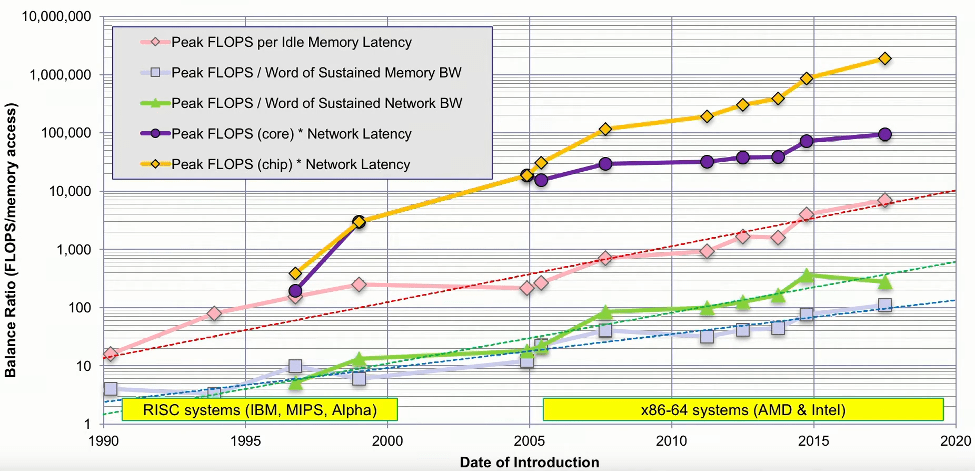
系統性能要素的不平衡。
一個設計良好的系統是平衡的。大多數人想要的是更有效地使用晶體管,目標每美元的吞吐量和每瓦特的吞吐量將會更高,總之利用率越高越好。
在考慮系統性能時,要么受計算限制,要么受內存限制,要么受 I/O 限制。隨著計算速度的加快,需要更加重視內存是否能夠跟上計算速度,并且還需要更高的帶寬接口來將傳輸數據。
但業界對處理性能非常著迷。實際上,計算單元很重要,但它們通常不是實際系統速度的限制因素。系統速度和工作負載強相關,它取決于數據從某個地方來、以某種方式處理并發送到數據被需要的地方有多快,并受到沿途亂七八糟事情的干擾。
這意味著不可能構建一個適合所有任務的最佳系統。關鍵是要確保其均衡性良好,并且在任何區域都不會過度配置。
移動數據
移動數據肯定會影響系統性能,也與功耗有關,因為移動一段數據比對其執行計算消耗的功耗高幾個數量級。完成一項任務,一般意味著將數據通過外部接口移入內存,從內存到CPU,中間結果在內存和CPU之間來回切換,最后結果通過外部接口推回。
無論你的計算速度有多快,或者你的內存陣列有多大,最終決定芯片和系統性能的是連接兩者的總線帶寬。這就是最大的瓶頸所在,不僅僅是總線,還有高速接口,它們都為解決數據訪問瓶頸做出了自己的努力。
有效的內存帶寬的提升是cache的采用。假設大多數內存訪問來自cache而不是主存,這有效地使數據更接近處理器,并減少延遲。處理器性能的提高如此之快,主要是通過核心數量的快速增加。然而,cache性能一直在下降,這是導致延遲增加的主要原因之一。即使 HBM 的引入也未能扭轉這一趨勢。cache性能的降低是因為cache設計變得越來越復雜,特別是隨著更多核心保持cache coherent,并且多級cache串行lookup以節省功耗。
另一種選擇是將計算移至更靠近內存的位置。in-memory computing的時代才剛剛開始,這可以通過三種方式實現。
1、通常,由于 DRAM 制造的經濟性,我們不會在 DRAM 芯片上看到很多復雜的邏輯。我們可能會看到少量非常具體的函數被添加到這些芯片中,例如累加或乘累加函數,這在許多 DSP 和 AI 算法中很常見。
2、第二種可能是像 CXL.mem 這樣的技術,在這種技術中,將計算功能添加到控制內存陣列的邏輯芯片中是非常可行的。從技術上講,這是在內存附近處理而不是在內存中處理。
3、第三個介于兩者之間。對于某些堆疊式存儲器(例如 HBM),通常有一個邏輯芯片與 DRAM 共同封裝在同一堆疊中,并且該邏輯芯片是面向 CPU 和 DRAM 設備的總線之間的接口。該邏輯芯片為邏輯芯片上的中低復雜度處理元件提供了空間。
HBM 的成功無疑幫助普及了chiplets的概念,曾經受到光罩限制或產量限制的芯片現在可以在多個chiplets上制造并集成到一個封裝中。然而,現在需要的芯片間連接解決方案可能比單個芯片上的連接解決方案慢。當公司將芯片分割成多個同質芯片時,希望在分割芯片上執行相同的操作,又不會降低性能或準確性。
實際上,這些chiplets是在系統環境中設計的,不僅僅是之前那樣的存儲器或控制器設計。封裝中的 IC 會引入其自身的寄生效應,因此你需要將其視為一個系統,并查看眼圖,看看如何根據系統的運行條件,信號的來源和接收方,對其進行優化,從而大幅增加帶寬并減少延遲。這些目的決定了接口和協議。USB、SATA、PCIe、CXL、DDR、HMC、AXUI、MIPI,這些不勝枚舉的協議都需要接口,業內正在創建更新的協議,并且需要新的接收器來實現這些芯片到芯片的連接。
multi-die系統的一大優勢是可用連接的數量變得更多。從 I/O 的角度來看,我們曾經擁有 1,024 位總線,然后我們轉向串行接口。但最近發生的情況是,那些串行接口現在已經變成并行接口,例如 x32 PCIe,它由 32 通道超高速串行連接組成。
工作負載
如前所述,系統性能和工作負載強相關。不可能制造針對所有情況優化的通用機器。找到PPA平衡迫使人們重新思考和定制芯片。
像人工智能這樣的任務也存在著不同的工作負載。如果你觀察人工智能,就會發現它有兩個方面。一個是訓練,在訓練中你需要不斷地訪問內存,因為權重就在那里。而且你會不斷改變權重,此時內存訪問是關鍵。然而,如果你看推理,模型已經訓練好了,你所要做的就是 MAC 操作,沒有訪問內存去改變權重。
尋找適當的平衡需要采用協同設計方法。在架構階段,需要評估芯片的各種場景,關注芯片內以及芯片外的吞吐量和帶寬。另一方面,物理設計團隊必須找出芯片的最佳尺寸。由于產量和功率的原因,它不能太大,更不能太小。然后設計團隊必須為他們構建接口和協議。架構團隊、物理設計團隊和設計團隊不斷地進行三方戰斗,以找到讓每個人都滿意的最佳點。當然,少不了驗證這個守門員。
計算范式
對于某些問題,使用傳統軟件可能會導致解決方案效率低下。這發生在從單核到多核的過渡以及 GPGPU 的采用期間。業界正在等待新一代人工智能硬件的實現。GPU 可以進行大規模并行計算,除了渲染形狀之外還可以做各種事情。
結論
添加更多或更快的處理核心固然很棒,但除非你能讓它們保持忙碌,否則就是在浪費時間、金錢和電力。
隨著 DRAM 遷移到封裝中,預計潛在帶寬將持續增加,但 DRAM 性能在過去 20 年里始終沒有跟上處理器,那么業界將不得不通過自身架構來解決這個問題。
-
處理器
+關注
關注
68文章
19407瀏覽量
231179 -
DRAM
+關注
關注
40文章
2325瀏覽量
183865 -
SoC芯片
+關注
關注
1文章
617瀏覽量
35040 -
Cache
+關注
關注
0文章
129瀏覽量
28431 -
HPC
+關注
關注
0文章
324瀏覽量
23853
原文標題:處理 SoC 中的性能瓶頸
文章出處:【微信號:數字芯片實驗室,微信公眾號:數字芯片實驗室】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SoC中語音處理系統有什么功能?
NANO芯片系統中,其對應的AVDD,VREF等引腳該如何處理呢?
SoC中的處理單元性能分析

如何處理電子污染
處理DS2155中的性能報告消息

如何處理HTTP 503故障問題?
ttl與非門中不用的輸入端如何處理?
廣播系統出現噪音、嘯叫如何處理?






 工商網監
工商網監
評論