") Cerebras推出WSE-3 AI芯片,比NVIDIA H100大56倍
Cerebras推出WSE-3 AI芯片,比NVIDIA H100大56倍
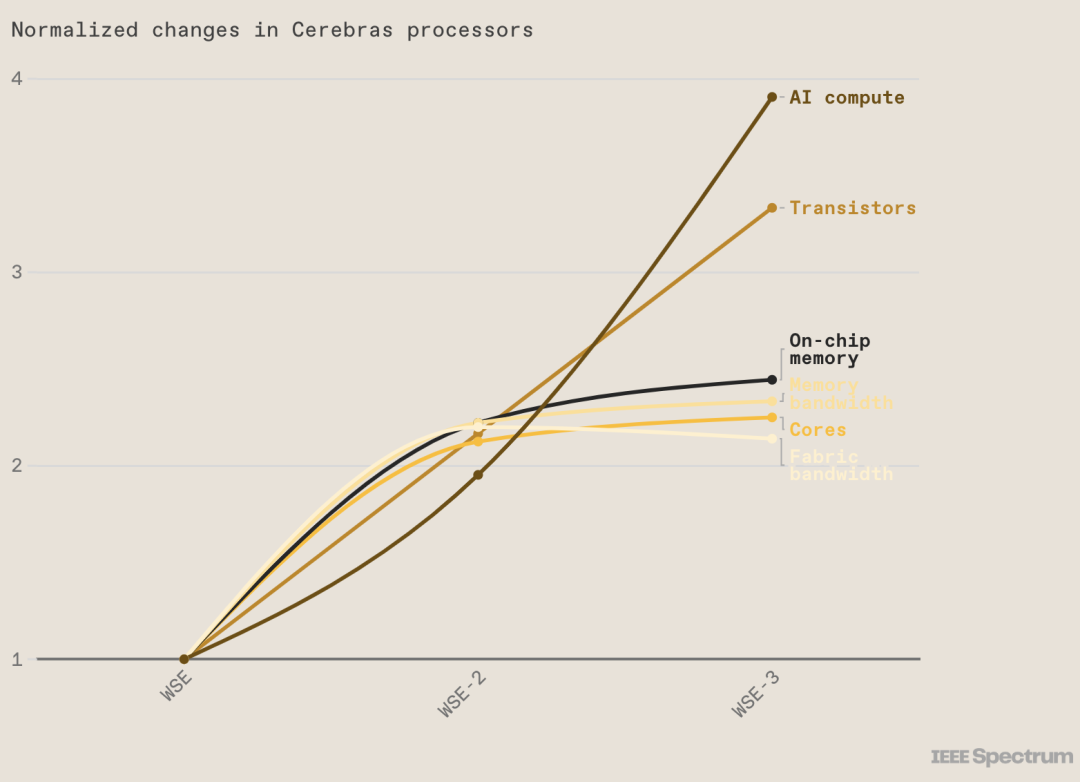
Cerebras 是一家位于美國加利福尼亞州的初創(chuàng)公司,2019 年進(jìn)入硬件市場,其首款超大人工智能芯片名為 Wafer Scale Engine (WSE) ,尺寸為 8 英寸 x 8 英寸,比最大的 GPU 大 56 倍,擁有 1.2 萬億個(gè)晶體管和 40 萬個(gè)計(jì)算核心,是當(dāng)時(shí)最快、最大的 AI 芯片。隨后在 2021 年,Cerebras 推出了 WSE-2,這是一款 7 納米芯片,其性能是原來的兩倍,擁有 2.6 萬億個(gè)晶體管和 85 萬個(gè)核心。
近日,Cerebras 宣布推出了第三代WSE-3,性能再次提高了近一倍。
01
Cerebras 推出 WSE-3 AI 芯片,比 NVIDIA H100 大 56 倍 WSE-3采用臺積電5nm工藝,擁有超過4萬億個(gè)晶體管和90 萬個(gè)核心,可提供 125 petaflops 的性能。這款芯片是臺積電可以制造的最大的方形芯片。WSE-3擁有44GB 片上 SRAM,而不是片外 HBM3E 或 DDR5。內(nèi)存與核心一起分布,目的是使數(shù)據(jù)和計(jì)算盡可能接近。
自推出以來,Cerebras 就將自己定位為英偉達(dá)GPU 驅(qū)動的人工智能系統(tǒng)的替代品。這家初創(chuàng)公司的宣傳是:他們可以使用更少的芯片在 Cerebras 硬件上進(jìn)行 AI訓(xùn)練,而不是使用數(shù)千個(gè) GPU。據(jù)稱,一臺Cerebras服務(wù)器可以完成與 10 個(gè) GPU 機(jī)架相同的工作。
下圖是Cerebras WSE-3和英偉達(dá) H100的對比。 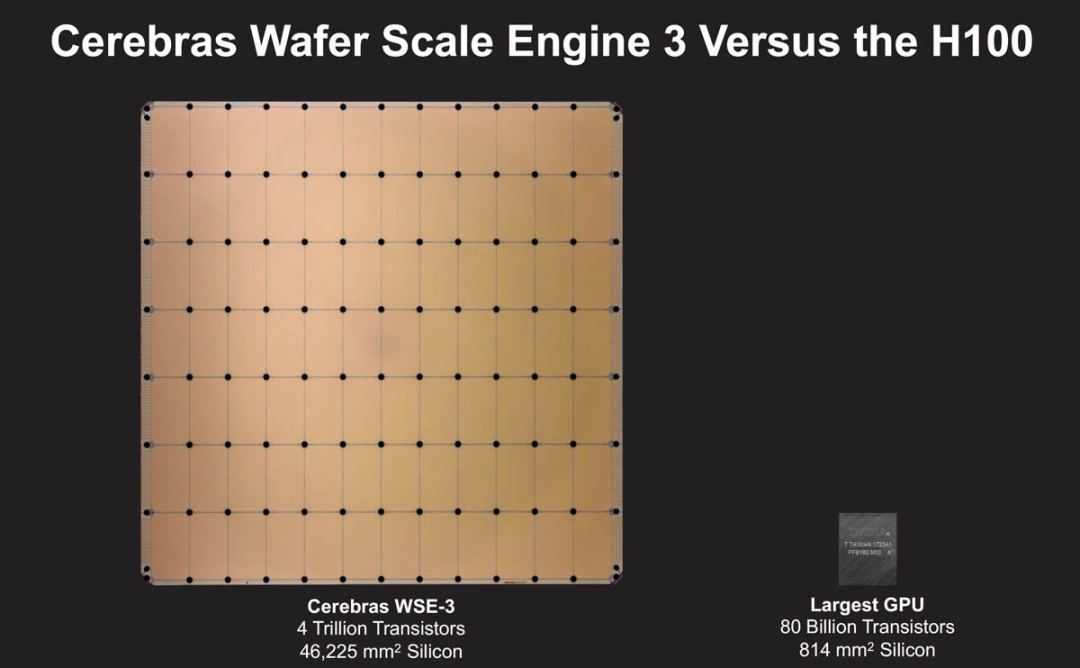
Cerebras 的獨(dú)特優(yōu)勢是將整個(gè)硅片直接轉(zhuǎn)化為單一巨大的處理器,從而大幅提升計(jì)算性能和效率。英偉達(dá)、AMD、英特爾等公司往往會把一塊大晶圓切成多個(gè)小的部分來制造芯片,在充斥著 Infiniband、以太網(wǎng)、PCIe 和 NVLink 交換機(jī)的英偉達(dá)GPU 集群中,大量的功率和成本花費(fèi)在重新鏈接芯片上,Cerebras的方法極大地減少了芯片之間的數(shù)據(jù)傳輸延遲,提高了能效比,并且在AI和ML任務(wù)中實(shí)現(xiàn)了前所未有的計(jì)算速度。
02
Cerebras CS-3 系統(tǒng)
Cerebras CS-3 是第三代 Wafer Scale 系統(tǒng)。其頂部具有 MTP/MPO 光纖連接,以及用于冷卻的電源、風(fēng)扇和冗余泵。該系統(tǒng)及其新芯片在相同的功耗和價(jià)格下實(shí)現(xiàn)了大約 2 倍的性能飛躍。 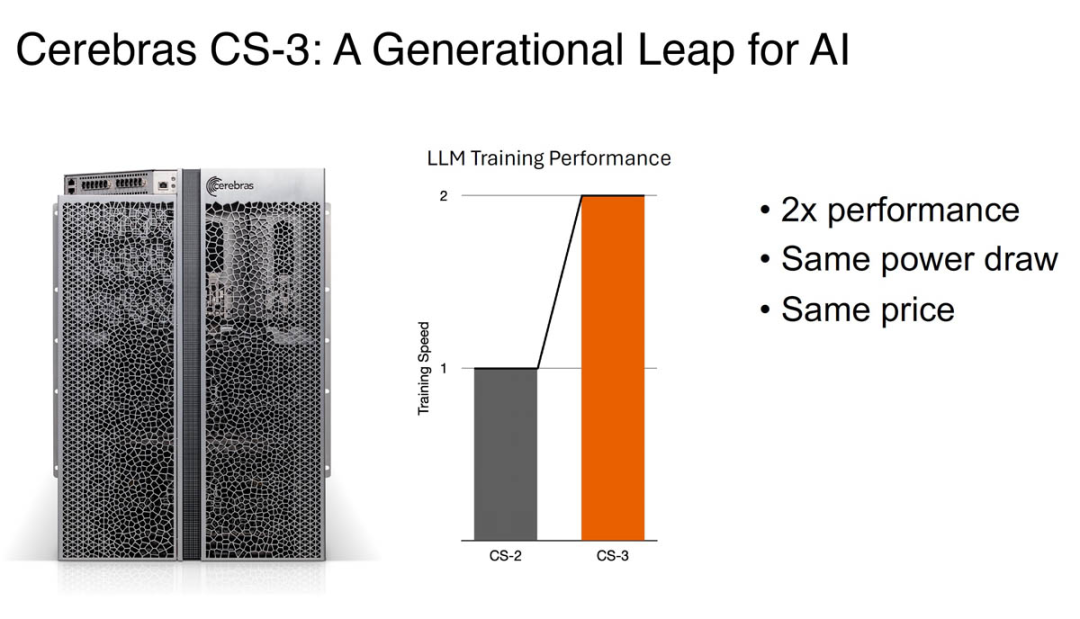
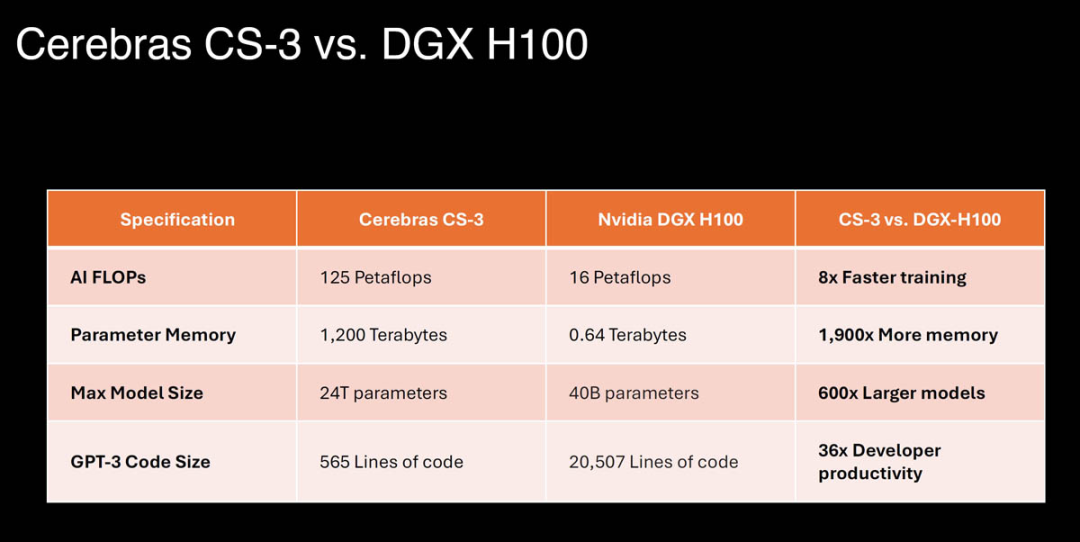
Cerebras WSE-3 的核心數(shù)量是英偉達(dá)的 H100 Tensor Core 的 52 倍。與 Nvidia DGX H100 系統(tǒng)相比,由 WSE-3 芯片驅(qū)動的 Cerebras CS-3 系統(tǒng)的訓(xùn)練速度提高了 8 倍,內(nèi)存增加了 1,900 倍,并且可以訓(xùn)練多達(dá) 24 萬億個(gè)參數(shù)的 AI 模型,這是其 600 倍。Cerebras 高管表示,CS-3的能力比 DGX H100 的能力還要大。在 GPU 上訓(xùn)練需要 30 天的 Llama 700 億參數(shù)模型,使用CS-3 集群進(jìn)行訓(xùn)練只需要一天。 
CS-3可以配置為多達(dá)2048個(gè)系統(tǒng)的集群,可實(shí)現(xiàn)高達(dá) 256 exaFLOPs 的 AI 計(jì)算,專為快速訓(xùn)練 GPT-5 規(guī)模的模型而設(shè)計(jì)。 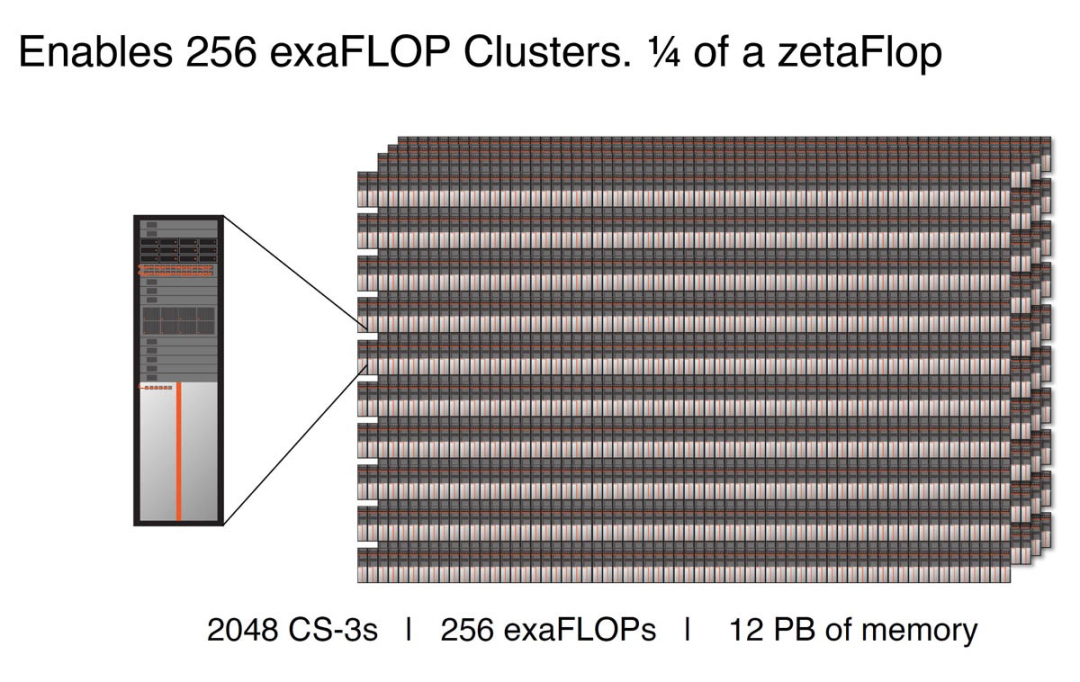
Cerebras CS-3 適用于 2048 節(jié)點(diǎn) 256EF 集群 
適用于 GPT 5 規(guī)模的 Cerebras CS-3 集群
03
Cerebras AI編程
Cerebras 聲稱其平臺比英偉達(dá)的平臺更易于使用,原因在于 Cerebras 存儲權(quán)重和激活的方式,Cerebras 不必?cái)U(kuò)展到系統(tǒng)中的多個(gè) GPU,然后擴(kuò)展到集群中的多個(gè) GPU 服務(wù)器。 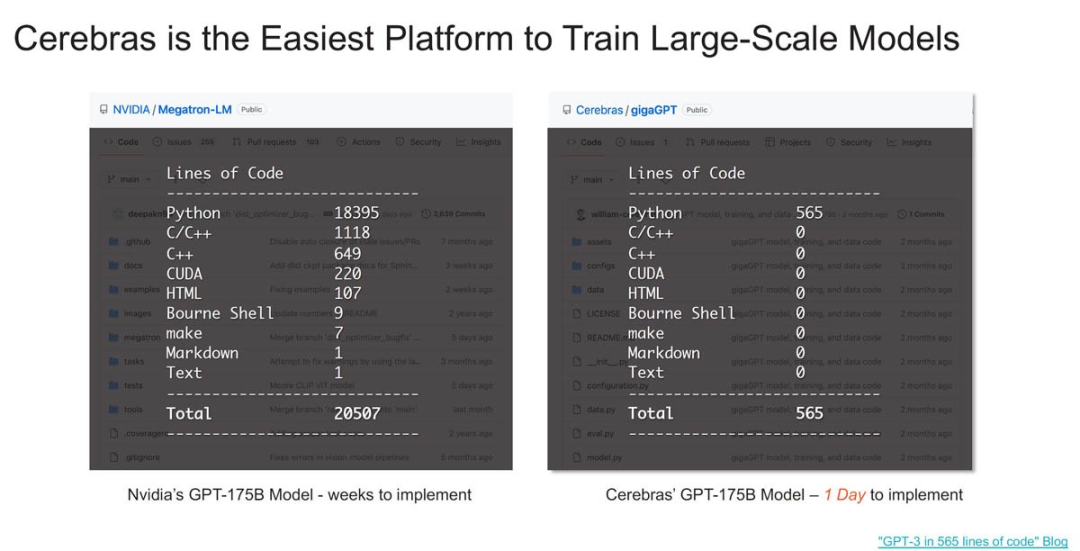 ?
?
除了代碼更改很容易之外,Cerebras 表示它的訓(xùn)練速度比 Meta GPU 集群更快。當(dāng)然,這只是理論上數(shù)據(jù),當(dāng)前還沒有任何 2048 個(gè) CS-3 集群已經(jīng)投入運(yùn)行,而 Meta 已經(jīng)有了 AI GPU 集群。 
Llama 70B Meta VS Cerebras CS-3 集群
04
Cerebras 與高通合作開發(fā)人工智能推理
Cerebras 和高通建立了合作伙伴關(guān)系,目標(biāo)是將推理成本降低 10 倍。Cerebras 表示,他們的解決方案將涉及應(yīng)用神經(jīng)網(wǎng)絡(luò)技術(shù),例如權(quán)重?cái)?shù)據(jù)壓縮等。該公司表示,經(jīng)過 Cerebras 訓(xùn)練的網(wǎng)絡(luò)將在高通公司的新型推理芯片AI 100 Ultra上高效運(yùn)行。
這項(xiàng)工作使用了四種主要技術(shù)來定制 Cerebras 訓(xùn)練的模型:
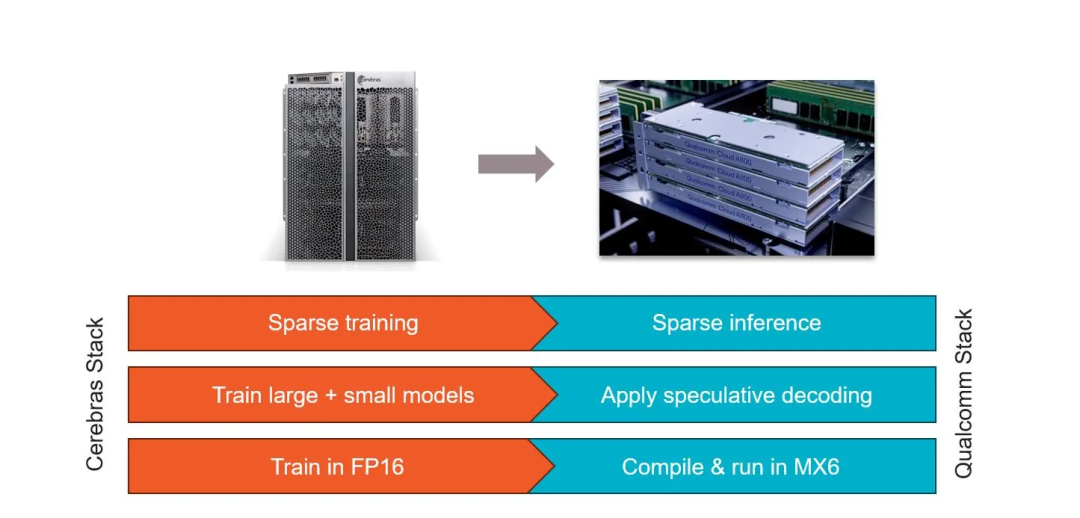
稀疏性是 Cerebras 的秘密武器之一,Cerebras 能夠在訓(xùn)練過程中利用動態(tài)、非結(jié)構(gòu)化的稀疏性。高通的 Cloud AI100 具有對非結(jié)構(gòu)化稀疏性的硬件支持,這種稀疏協(xié)同可以使性能提高2.5倍。
推測解碼是一種前景廣闊但迄今為止難以有效實(shí)施的行業(yè)技術(shù),也被用來加快速度。這種技術(shù)使用一個(gè)大型LLM和一個(gè)小型LLM的組合來完成一個(gè)大型LLM的工作。小模型不太精確,但效率較高。大模型用于檢查小模型的合理性。總體而言,組合效率更高,由于該技術(shù)總體上使用的計(jì)算量較少,因此速度可以提高 1.8 倍。
權(quán)重壓縮為 MxFP6,這是一種行業(yè) 6 位微指數(shù)格式,與 FP16 相比,可節(jié)省 39% 的 DRAM 空間。高通的編譯器將權(quán)重從 FP32 或 FP16 壓縮為 MxFP6,Cloud AI100 的矢量引擎在軟件中執(zhí)行即時(shí)解壓縮到 FP16。該技術(shù)可以將推理速度提高 2.2 倍。
神經(jīng)架構(gòu)搜索(NAS)是一種推理優(yōu)化技術(shù)。該技術(shù)在訓(xùn)練期間考慮了目標(biāo)硬件(Qualcomm Cloud AI 100)的優(yōu)點(diǎn)和缺點(diǎn),以支持在該硬件上高效運(yùn)行的層類型、操作和激活函數(shù)。Cerebras 和 Qualcomm 在 NAS 方面的工作使推理速度提高了一倍。
審核編輯:劉清
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5076瀏覽量
103728 -
晶體管
+關(guān)注
關(guān)注
77文章
9746瀏覽量
138911 -
AI芯片
+關(guān)注
關(guān)注
17文章
1906瀏覽量
35217 -
人工智能芯片
+關(guān)注
關(guān)注
1文章
121瀏覽量
29170 -
DDR5
+關(guān)注
關(guān)注
1文章
430瀏覽量
24211
原文標(biāo)題:初創(chuàng)公司Cerebras 推出 WSE-3 AI 芯片,聲稱“吊打”英偉達(dá) H100
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
英偉達(dá)H100芯片市場降溫
馬斯克自曝訓(xùn)練Grok 3用了10萬塊NVIDIA H100
AI初出企業(yè)Cerebras已申請IPO!稱發(fā)布的AI芯片比GPU更適合大模型訓(xùn)練
Supermicro推出適配NVIDIA Blackwell和NVIDIA HGX H100/H200的機(jī)柜級即插即用液冷AI SuperCluster

英特爾的最強(qiáng)AI芯片要來了,聲稱性能完勝英偉達(dá)H100
英特爾發(fā)布人工智能芯片新版,對標(biāo)Nvidia
世界第一AI芯片發(fā)布!世界紀(jì)錄直接翻倍 晶體管達(dá)4萬億個(gè)
Cerebras推出性能翻倍的WSE-3 AI芯片
Cerebras Systems推出迄今最快AI芯片,搭載4萬億晶體管
最強(qiáng)AI芯片發(fā)布,Cerebras推出性能翻倍的WSE-3 AI芯片






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論