 Adobe提出DMV3D:3D生成只需30秒!讓文本、圖像都動起來的新方法!
Adobe提出DMV3D:3D生成只需30秒!讓文本、圖像都動起來的新方法!
3D 生成是 AI 視覺領域的研究熱點之一。本文中,來自 Adobe 研究院和斯坦福大學等機構的研究者利用基于 transformer 的 3D 大型重建模型來對多視圖擴散進行去噪,并提出了一種新穎的 3D 生成方法 DMV3D,實現了新的 SOTA 結果。
2D 擴散模型極大地簡化了圖像內容的創作流程,2D 設計行業也因此發生了變革。近來,擴散模型已擴展到 3D 創作領域,減少了應用程序(如 VR、AR、機器人技術和游戲等)中的人工成本。有許多研究已經對使用預訓練的 2D 擴散模型,生成具有評分蒸餾采樣(SDS)損失的 NeRFs 方法進行了探索。然而,基于 SDS 的方法通常需要花費數小時來優化資源,并且經常引發圖形中的幾何問題,比如多面 Janus 問題。 另一方面,研究者對無需花費大量時間優化每個資源,也能夠實現多樣化生成的 3D 擴散模型也進行了多種嘗試。這些方法通常需要獲取包含真實數據的 3D 模型 / 點云用于訓練。然而,對于真實圖像來說,這種訓練數據難以獲得。由于目前的 3D 擴散方法通常基于兩階段訓練,這導致在不分類、高度多樣化的 3D 數據集上存在一個模糊且難以去噪的潛在空間,使得高質量渲染成為亟待解決的挑戰。
為了解決這個問題,已經有研究者提出了單階段模型,但這些模型大多數只針對特定的簡單類別,泛化性較差。
因此,本文研究者的目標是實現快速、逼真和通用的 3D 生成。為此,他們提出了 DMV3D。DMV3D 是一種全新的單階段的全類別擴散模型,能直接根據模型文字或單張圖片的輸入,生成 3D NeRF。在單個 A100 GPU 上,僅需 30 秒,DMV3D 就能生成各種高保真 3D 圖像。

具體來講,DMV3D 是一個 2D 多視圖圖像擴散模型,它將 3D NeRF 重建和渲染集成到其降噪器中,以端到端的方式進行訓練,而無需直接 3D 監督。這避免了單獨訓練用于潛在空間擴散的 3D NeRF 編碼器(如兩階段模型)和繁瑣的對每個對象進行優化的方法(如 SDS)中會出現的問題。
本質上,本文的方法是對 2D 多視圖擴散的框架進行 3D 重建。這種方法受到了 RenderDiffusion 的啟發,它是一種通過單視圖擴散實現 3D 生成的方法。然而,RenderDiffusion 的局限性在于,訓練數據需要特定類別的先驗知識,數據中的對象也需要特定的角度或姿勢,因此泛化性很差,無法對任意類型的對象進行 3D 生成。
相比之下,研究者認為一組稀疏的包含一個對象的四個多視角的投影,足以描述一個沒有被遮擋的 3D 物體。這種訓練數據的輸入源于人類的空間想象能力。他們可以根據幾個對象的周圍的平面視圖,想象出一個完整的 3D 物體。這種想象通常是非常確定和具像化的。
然而,利用這種輸入本質上仍需解決稀疏視圖下 3D 重建的任務。這是一個長期存在的問題,即使在輸入沒有噪聲的情況下,也是一個非常具有挑戰性的問題。
本文的方法能夠基于單個圖像 / 文本實現 3D 生成。對于圖像輸入,他們固定一個稀疏視圖作為無噪聲輸入,并對其他視圖進行類似于 2D 圖像修復的降噪。為了實現基于文本的 3D 生成,研究者使用了在 2D 擴散模型中通常會用到的、基于注意力的文本條件和不受類型限制的分類器。
他們只采用了圖像空間監督,在 Objaverse 合成的圖像和 MVImgNet 真實捕獲的圖像組成的大型數據集上進行了訓練。從結果來看,DMV3D 在單圖像 3D 重建方面取得了 SOTA,超越了先前基于 SDS 的方法和 3D 擴散模型。DMV3D 生成的基于文本的 3D 模型,也優于此前的方法。

論文地址:https://arxiv.org/pdf/2311.09217.pdf
官網地址:https://justimyhxu.github.io/projects/dmv3d/
我們來看一下生成的 3D 圖像效果。


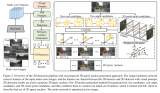
方法概覽 單階段 3D 擴散模型是如何訓練并推理的呢? 研究者首先引入了一種新的擴散框架,該框架使用基于重建的降噪器來對有噪聲的多視圖圖像去噪以進行 3D 生成;其次他們提出了一種新的、以擴散時間步為條件的、基于 LRM 的多視圖降噪器,從而通過 3D NeRF 重建和渲染來漸進地對多視圖圖像進行去噪;最后進一步對模型進行擴散,支持文本和圖像調節,實現可控生成。
多視圖擴散和去噪
多視圖擴散。2D擴散模型中處理的原始 x_0 分布在數據集中是單個圖像分布。相反,研究者考慮的是多視圖圖像
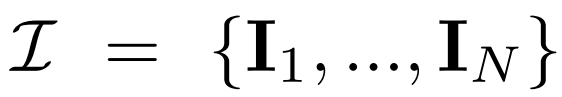
的聯合分布,其中每組
都是從視點 C = {c_1, .. ., c_N} 中相同 3D 場景(資產)的圖像觀察結果。擴散過程相當于使用相同的噪聲調度獨立地對每個圖像進行擴散操作,如下公式(1) 所示。
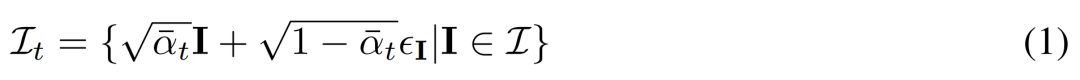
基于重建的去噪。2D 擴散過程的逆過程本質上是去噪。本文中,研究者提出利用 3D 重建和渲染來實現 2D 多視圖圖像去噪,同時輸出干凈的、用于 3D 生成的 3D 模型。具體來講,他們使用 3D 重建模塊 E (?) 來從有噪聲的多視圖圖像
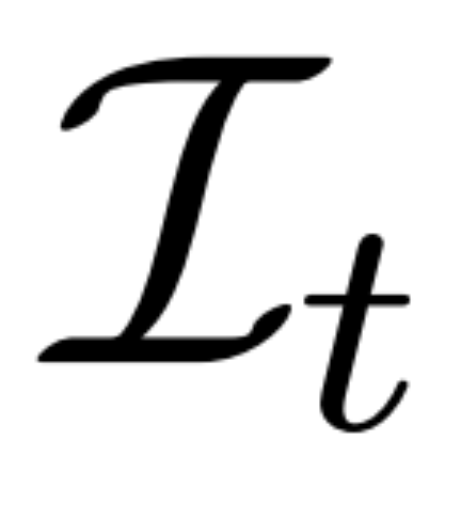
中重建 3D 表示 S,并使用可微渲染模塊 R (?) 對去噪圖像進行渲染,如下公式 (2) 所示。
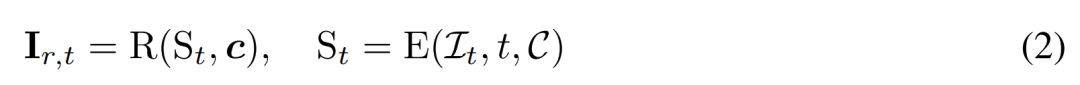
基于重建的多視圖降噪器
研究者基于 LRM 構建了多視圖降噪器,并使用大型 transformer 模型從有噪聲的稀疏視圖姿態圖像中重建了一個干凈的三平面 NeRF,然后將重建后的三平面 NeRF 的渲染用作去噪輸出。
重建和渲染。如下圖 3 所示,研究者使用一個 Vision Transformer(DINO)來將輸入圖像
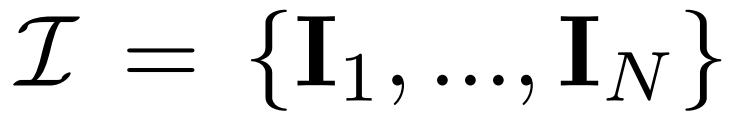
轉化為 2D token,然后使用 transformer 將學得的三平面位置嵌入映射到最后的三平面,以表示資產的 3D 形狀和外觀。接下來將預測到的三平面用來通過一個 MLP 來解碼體積密度和顏色,以進行可微體積渲染。
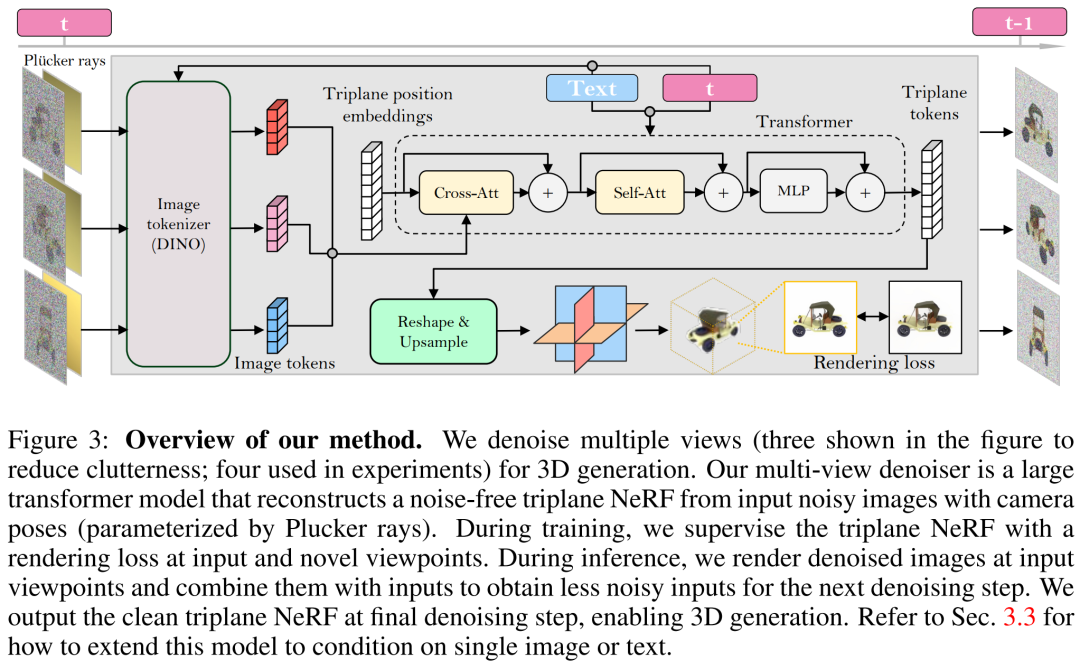
時間調節。與基于 CNN 的 DDPM(去噪擴散概率模型)相比,本文基于 transformer 的模型需要不同的時間調節設計。
相機調節。在具有高度多樣化的相機內參和外參的數據集(如 MVImgNet)上訓練本文的模型時,研究者表示需要對輸入相機調節進行有效的設計,以促使模型理解相機并實現 3D 推理。
在單個圖像或文本上調節
以上方法使研究者提出的模型可以充當一個無條件生成模型。他們介紹了如何利用條件降噪器
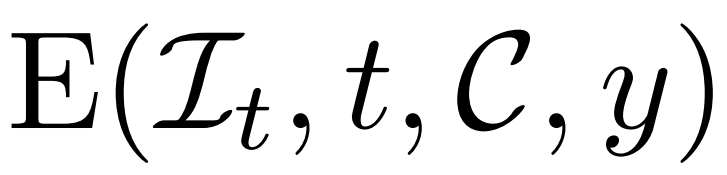
來對條件概率分布進行建模,其中 y 表示文本或圖像,以實現可控 3D 生成。
圖像調節。研究者提出了一種簡單但有效的圖像調節策略,其中不需要改變模型的架構。
文本調節。為了將文本調節添加到自己的模型中,研究者采用了類似于 Stable Diffusion 的策略。他們使用 CLIP 文本編碼器生成文本嵌入,并使用交叉注意力將它們注入到降噪器中。
訓練和推理
訓練。在訓練階段,研究者在范圍 [1, T] 內均勻地采樣時間步 t,并根據余弦調度來添加噪聲。他們使用隨機相機姿態對輸入圖像進行采樣,還隨機采樣額外的新視點來監督渲染以獲得更好的質量。
研究者使用條件信號 y 來最小化以下訓練目標。
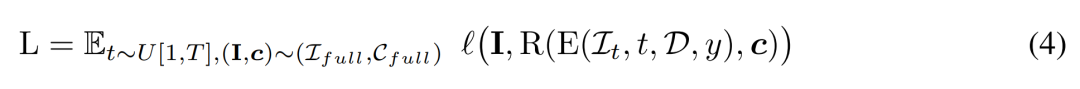
推理。在推理階段,研究者選擇了以圓圈均勻圍繞對象的視點,以確保很好地覆蓋生成的 3D 資產。他們將四個視圖的相機市場角固定為 50 度。
實驗結果
在實驗環節,研究者使用了 AdamW 優化器來訓練自己的模型,其中初始學習率為 4e^-4。他們針對該學習率使用了 3K 步的預熱和余弦衰減,使用 256 × 256 輸入圖像來訓練降噪器,對 128 × 128 的裁剪圖像進行渲染以進行監督。
關于數據集,研究者的模型只需多視圖姿態圖像來訓練,因而使用來自 Objaverse 數據集的約 730k 個對象的渲染后多視圖圖像。對于每個對象,他們按照 LRM 的設置,在對固定 50 度 FOV 的隨機視點均勻照明下,渲染了 32 張圖像。
首先是單圖像重建。研究者將自己的圖像 - 調節模型與 Point-E、Shap-E、Zero-1-to-3 和 Magic123 等以往方法在單圖像重建任務上進行了比較。他們使用到的指標有 PSNR、LPIPS、CLIP 相似性得分和 FID,以評估所有方法的新視圖渲染質量。
下表 1 分別展示了 GSO 和 ABO 測試集上的定量結果。研究者的模型優于所有基線方法,并在兩個數據集上實現所有指標的新 SOTA。
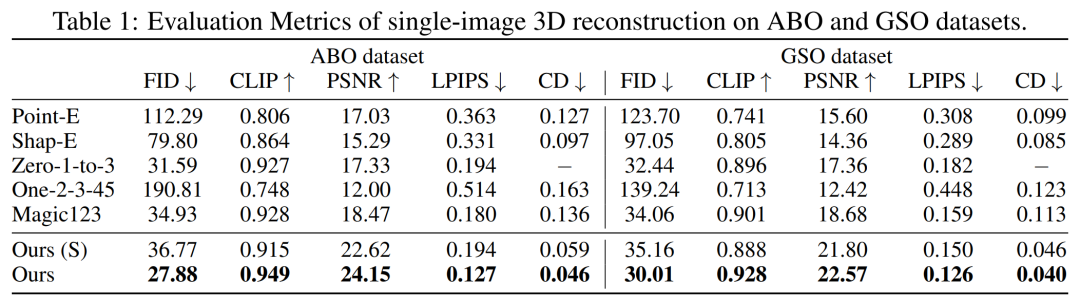
圖 4 為定性結果,相比基線,本文模型生成的結果具有更高質量的幾何和更清晰的外觀細節。
相比之下,DMV3D 是一個以 2D 圖像為訓練目標的單階段模型,無需對每個資產單獨優化,在消除多視圖擴散噪聲的同時,直接生成 3D NeRF 的模型。總的來說,DMV3D 可以快速生成 3D 圖像,并獲得最優的單圖像 3D 重建結果。

從文本到 3D。研究者還評估了 DMV3D 基于文本的 3D 生成結果。研究者將 DMV3D 和同樣能夠支持全類別的快速推理的 Shap-E 和 Point-E 進行了比較。研究者讓三個模型根據 Shap-E 的 50 個文本提示進行生成,并使用了兩個不同的 ViT 模型的 CLIP 精度和平均精度來評估生成結果,如表 2 所示。
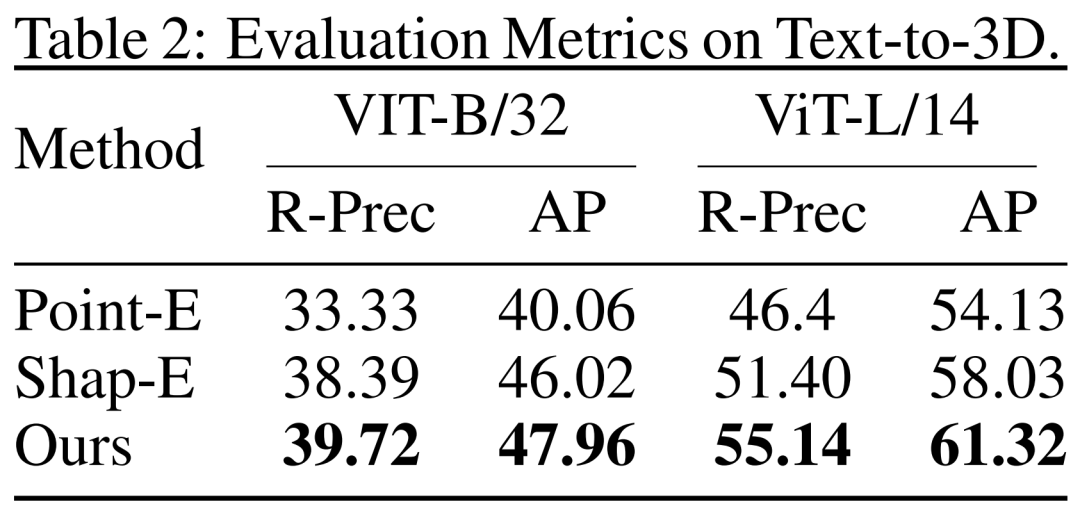
從表中可以看出,DMV3D 表現出了最佳的精度。圖 5 中是定性結果,相比于其他模型的生成結果,DMV3D 生成的圖形明顯包含更豐富的幾何和外觀細節,結果也更逼真。

其他結果
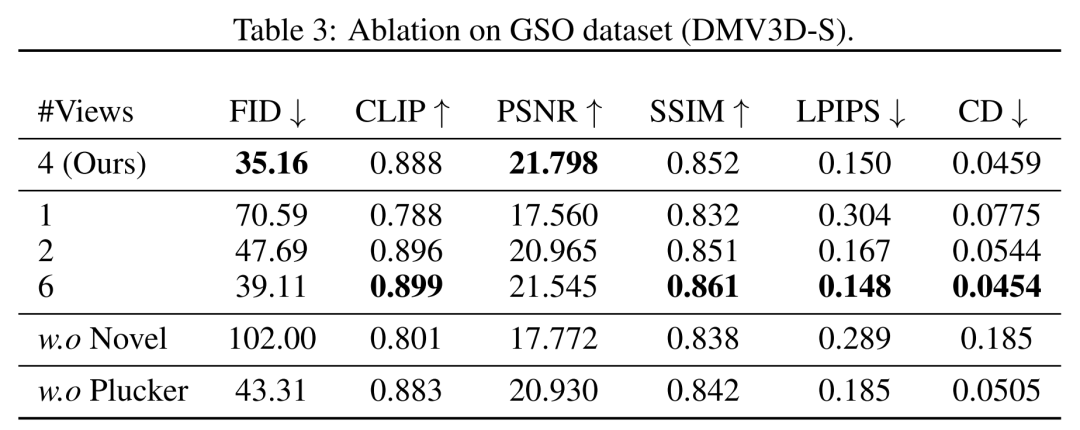
在視角方面,研究者在表 3 和圖 8 中顯示了用不同數量(1、2、4、6)的輸入視圖訓練的模型的定量和定性比較。

在多實例生成方面,與其他擴散模型類似,本文提出的模型可以根據隨機輸入生成多種示例,如圖 1 所示,展示了該模型生成結果的泛化性。

在應用方面,DMV3D 具備廣泛的靈活性和通用性,在 3D 生成應用領域具備較強的發展潛力。如圖 1 和圖 2 所示,本文方法能夠在圖像編輯應用程序中通過分割(如 SAM)等方法將 2D 照片中的任意對象提升到 3D 的維度。
更多技術細節和實驗結果請查閱原論文。

-
編碼器
+關注
關注
45文章
3669瀏覽量
135258 -
3D
+關注
關注
9文章
2912瀏覽量
108010 -
Transformer
+關注
關注
0文章
146瀏覽量
6048
原文標題:ICLR 2024 | Adobe提出DMV3D:3D生成只需30秒!讓文本、圖像都動起來的新方法!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
騰訊混元3D AI創作引擎正式發布
騰訊混元3D AI創作引擎正式上線
歡創播報 騰訊元寶首發3D生成應用

裸眼3D筆記本電腦——先進的光場裸眼3D技術
奧比中光3D相機打造高質量、低成本的3D動作捕捉與3D動畫內容生成方案
什么是光場裸眼3D?

讓PMSM簡單的動起來的話,需要調用哪些頭文件?
步進電機如何讓動起來?步進電機轉動原理

NVIDIA生成式AI研究實現在1秒內生成3D形狀

Stability AI推出全新Stable Video 3D模型
Stability AI推出Stable Video 3D模型,可制作多視角3D視頻
Adobe Substance 3D整合AI功能:基于文本生成紋理、背景

2張圖2秒鐘完成3D建模!3D內容生成工具DUSt3R爆火,國產廠商有哪些機會?

Nullmax提出多相機3D目標檢測新方法QAF2D





 工商網監
工商網監
評論