 加速Python for循環的12種方法
加速Python for循環的12種方法
Python內建的一個常用功能是timeit模塊。下面幾節中我們將使用它來度量循環的當前性能和改進后的性能。
對于每種方法,我們通過運行測試來建立基線,該測試包括在10次測試運行中運行被測函數100K次(循環),然后計算每個循環的平均時間(以納秒為單位,ns)。
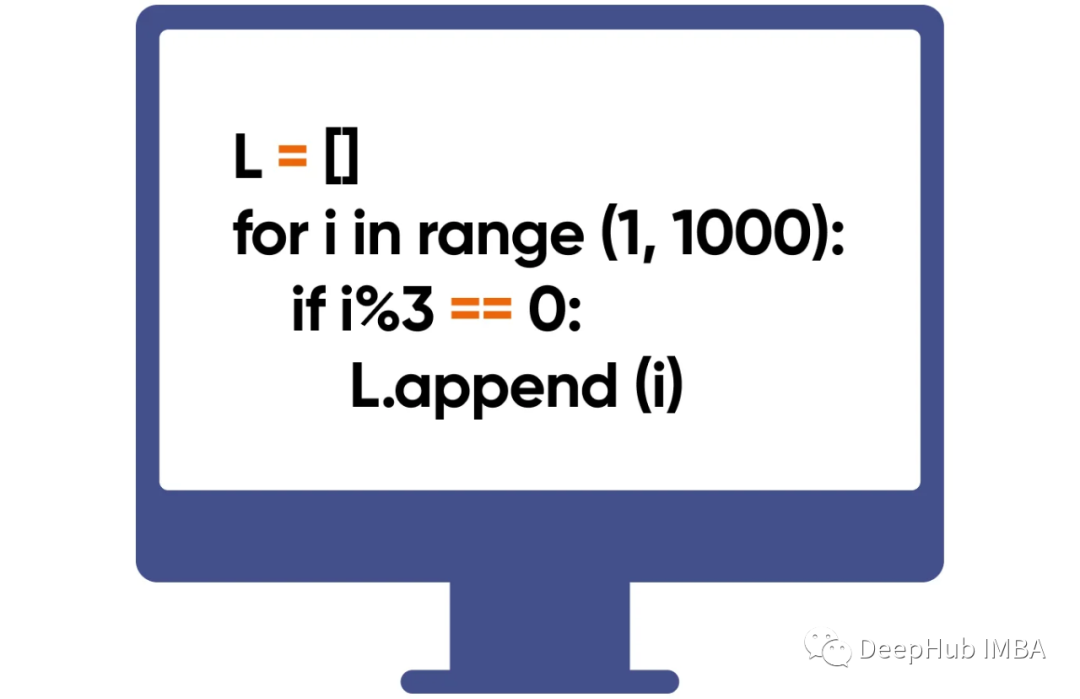
幾個簡單方法
1、列表推導式
# Baseline version (Inefficient way) # Calculating the power of numbers # Without using List Comprehension deftest_01_v0(numbers): output=[] forninnumbers: output.append(n**2.5) returnoutput # Improved version # (Using List Comprehension) deftest_01_v1(numbers): output=[n**2.5forninnumbers] returnoutput
結果如下:
# Summary Of Test Results Baseline: 32.158 ns per loop Improved: 16.040 ns per loop % Improvement: 50.1 % Speedup: 2.00x
可以看到使用列表推導式可以得到2倍速的提高
2、在外部計算長度
如果需要依靠列表的長度進行迭代,請在for循環之外進行計算。
# Baseline version (Inefficient way) # (Length calculation inside for loop) deftest_02_v0(numbers): output_list=[] foriinrange(len(numbers)): output_list.append(i*2) returnoutput_list # Improved version # (Length calculation outside for loop) deftest_02_v1(numbers): my_list_length=len(numbers) output_list=[] foriinrange(my_list_length): output_list.append(i*2) returnoutput_list
通過將列表長度計算移出for循環,加速1.6倍,這個方法可能很少有人知道吧。
# Summary Of Test Results Baseline: 112.135 ns per loop Improved: 68.304 ns per loop % Improvement: 39.1 % Speedup: 1.64x
3、使用Set
在使用for循環進行比較的情況下使用set。
# Use for loops for nested lookups
deftest_03_v0(list_1,list_2):
# Baseline version (Inefficient way)
# (nested lookups using for loop)
common_items=[]
foriteminlist_1:
ifiteminlist_2:
common_items.append(item)
returncommon_items
deftest_03_v1(list_1,list_2):
# Improved version
# (sets to replace nested lookups)
s_1=set(list_1)
s_2=set(list_2)
output_list=[]
common_items=s_1.intersection(s_2)
returncommon_items
在使用嵌套for循環進行比較的情況下,使用set加速498x
# Summary Of Test Results Baseline: 9047.078 ns per loop Improved: 18.161 ns per loop % Improvement: 99.8 % Speedup: 498.17x
4、跳過不相關的迭代
避免冗余計算,即跳過不相關的迭代。
# Example of inefficient code used to find # the first even square in a list of numbers deffunction_do_something(numbers): forninnumbers: square=n*n ifsquare%2==0: returnsquare returnNone# No even square found # Example of improved code that # finds result without redundant computations deffunction_do_something_v1(numbers): even_numbers=[iforninnumbersifn%2==0] fornineven_numbers: square=n*n returnsquare returnNone# No even square found
這個方法要在設計for循環內容的時候進行代碼設計,具體能提升多少可能根據實際情況不同:
# Summary Of Test Results Baseline: 16.912 ns per loop Improved: 8.697 ns per loop % Improvement: 48.6 % Speedup: 1.94x
5、代碼合并
在某些情況下,直接將簡單函數的代碼合并到循環中可以提高代碼的緊湊性和執行速度。
# Example of inefficient code # Loop that calls the is_prime function n times. defis_prime(n): ifn<=?1: ??? ?return?False ???for?i?in?range(2,?int(n**0.5)?+?1): ??? ?if?n?%?i?==?0: ??? ? ?return?False ? ???return?True ? ?def?test_05_v0(n): ???# Baseline version (Inefficient way) ???# (calls the is_prime function n times) ???count?=?0 ???for?i?in?range(2,?n?+?1): ??? ?if?is_prime(i): ??? ? ?count?+=?1 ???return?count ? ?def?test_05_v1(n): ???# Improved version ???# (inlines the logic of the is_prime function) ???count?=?0 ???for?i?in?range(2,?n?+?1): ??? ?if?i?<=?1: ??? ? ?continue ??? ?for?j?in?range(2,?int(i**0.5)?+?1): ??? ? ?if?i?%?j?==?0: ??? ? ? ?break ??? ?else: ??? ? ?count?+=?1 ???return?count
這樣也可以提高1.3倍
# Summary Of Test Results Baseline: 1271.188 ns per loop Improved: 939.603 ns per loop % Improvement: 26.1 % Speedup: 1.35x
這是為什么呢?
調用函數涉及開銷,例如在堆棧上推入和彈出變量、函數查找和參數傳遞。當一個簡單的函數在循環中被重復調用時,函數調用的開銷會增加并影響性能。所以將函數的代碼直接內聯到循環中可以消除這種開銷,從而可能顯著提高速度。
但是這里需要注意,平衡代碼可讀性和函數調用的頻率是一個要考慮的問題。
一些小技巧
6 .避免重復
考慮避免重復計算,其中一些計算可能是多余的,并且會減慢代碼的速度。相反,在適用的情況下考慮預計算。
deftest_07_v0(n): # Example of inefficient code # Repetitive calculation within nested loop result=0 foriinrange(n): forjinrange(n): result+=i*j returnresult deftest_07_v1(n): # Example of improved code # Utilize precomputed values to help speedup pv=[[i*jforjinrange(n)]foriinrange(n)] result=0 foriinrange(n): result+=sum(pv[i][:i+1]) returnresult
結果如下
# Summary Of Test Results Baseline: 139.146 ns per loop Improved: 92.325 ns per loop % Improvement: 33.6 % Speedup: 1.51x
7、使用Generators
生成器支持延遲求值,也就是說,只有當你向它請求下一個值時,里面的表達式才會被求值,動態處理數據有助于減少內存使用并提高性能。尤其是大型數據集中
deftest_08_v0(n): # Baseline version (Inefficient way) # (Inefficiently calculates the nth Fibonacci # number using a list) ifn<=?1: ??? ?return?n ???f_list?=?[0,?1] ???for?i?in?range(2,?n?+?1): ??? ?f_list.append(f_list[i?-?1]?+?f_list[i?-?2]) ???return?f_list[n] ? ?def?test_08_v1(n): ???# Improved version ???# (Efficiently calculates the nth Fibonacci ???# number using a generator) ???a,?b?=?0,?1 ???for?_?in?range(n): ??? ?yield?a ??? ?a,?b?=?b,?a?+?b
可以看到提升很明顯:
# Summary Of Test Results Baseline: 0.083 ns per loop Improved: 0.004 ns per loop % Improvement: 95.5 % Speedup: 22.06x
8、map()函數
使用Python內置的map()函數。它允許在不使用顯式for循環的情況下處理和轉換可迭代對象中的所有項。
defsome_function_X(x): # This would normally be a function containing application logic # which required it to be made into a separate function # (for the purpose of this test, just calculate and return the square) returnx**2 deftest_09_v0(numbers): # Baseline version (Inefficient way) output=[] foriinnumbers: output.append(some_function_X(i)) returnoutput deftest_09_v1(numbers): # Improved version # (Using Python's built-in map() function) output=map(some_function_X,numbers) returnoutput
使用Python內置的map()函數代替顯式的for循環加速了970x。
# Summary Of Test Results Baseline: 4.402 ns per loop Improved: 0.005 ns per loop % Improvement: 99.9 % Speedup: 970.69x
這是為什么呢?
map()函數是用C語言編寫的,并且經過了高度優化,因此它的內部隱含循環比常規的Python for循環要高效得多。因此速度加快了,或者可以說Python還是太慢,哈。
9、使用Memoization
記憶優化算法的思想是緩存(或“記憶”)昂貴的函數調用的結果,并在出現相同的輸入時返回它們。它可以減少冗余計算,加快程序速度。
首先是低效的版本。
# Example of inefficient code deffibonacci(n): ifn==0: return0 elifn==1: return1 returnfibonacci(n-1)+fibonacci(n-2) deftest_10_v0(list_of_numbers): output=[] foriinnumbers: output.append(fibonacci(i)) returnoutput
然后我們使用Python的內置functools的lru_cache函數。
# Example of efficient code # Using Python's functools' lru_cache function importfunctools @functools.lru_cache() deffibonacci_v2(n): ifn==0: return0 elifn==1: return1 returnfibonacci_v2(n-1)+fibonacci_v2(n-2) def_test_10_v1(numbers): output=[] foriinnumbers: output.append(fibonacci_v2(i)) returnoutput
結果如下:
# Summary Of Test Results Baseline: 63.664 ns per loop Improved: 1.104 ns per loop % Improvement: 98.3 % Speedup: 57.69x
使用Python的內置functools的lru_cache函數使用Memoization加速57x。
lru_cache函數是如何實現的?
“LRU”是“Least Recently Used”的縮寫。lru_cache是一個裝飾器,可以應用于函數以啟用memoization。它將最近函數調用的結果存儲在緩存中,當再次出現相同的輸入時,可以提供緩存的結果,從而節省了計算時間。lru_cache函數,當作為裝飾器應用時,允許一個可選的maxsize參數,maxsize參數決定了緩存的最大大小(即,它為多少個不同的輸入值存儲結果)。如果maxsize參數設置為None,則禁用LRU特性,緩存可以不受約束地增長,這會消耗很多的內存。這是最簡單的空間換時間的優化方法。
10、向量化
importnumpyasnp deftest_11_v0(n): # Baseline version # (Inefficient way of summing numbers in a range) output=0 foriinrange(0,n): output=output+i returnoutput deftest_11_v1(n): # Improved version # (# Efficient way of summing numbers in a range) output=np.sum(np.arange(n)) returnoutput
向量化一般用于機器學習的數據處理庫numpy和pandas
# Summary Of Test Results Baseline: 32.936 ns per loop Improved: 1.171 ns per loop % Improvement: 96.4 % Speedup: 28.13x
11、避免創建中間列表
使用filterfalse可以避免創建中間列表。它有助于使用更少的內存。
deftest_12_v0(numbers):
# Baseline version (Inefficient way)
filtered_data=[]
foriinnumbers:
filtered_data.extend(list(
filter(lambdax:x%5==0,
range(1,i**2))))
returnfiltered_data
使用Python的內置itertools的filterfalse函數實現相同功能的改進版本。
fromitertoolsimportfilterfalse deftest_12_v1(numbers): # Improved version # (using filterfalse) filtered_data=[] foriinnumbers: filtered_data.extend(list( filterfalse(lambdax:x%5!=0, range(1,i**2)))) returnfiltered_data
這個方法根據用例的不同,執行速度可能沒有顯著提高,但通過避免創建中間列表可以降低內存使用。我們這里獲得了131倍的提高
# Summary Of Test Results Baseline: 333167.790 ns per loop Improved: 2541.850 ns per loop % Improvement: 99.2 % Speedup: 131.07x
12、高效連接字符串
任何使用+操作符的字符串連接操作都會很慢,并且會消耗更多內存。使用join代替。
deftest_13_v0(l_strings): # Baseline version (Inefficient way) # (concatenation using the += operator) output="" fora_strinl_strings: output+=a_str returnoutput deftest_13_v1(numbers): # Improved version # (using join) output_list=[] fora_strinl_strings: output_list.append(a_str) return"".join(output_list)
該測試需要一種簡單的方法來生成一個較大的字符串列表,所以寫了一個簡單的輔助函數來生成運行測試所需的字符串列表。
fromfakerimportFaker defgenerate_fake_names(count:int=10000): # Helper function used to generate a # large-ish list of names fake=Faker() output_list=[] for_inrange(count): output_list.append(fake.name()) returnoutput_list l_strings=generate_fake_names(count=50000)
結果如下:
# Summary Of Test Results Baseline: 32.423 ns per loop Improved: 21.051 ns per loop % Improvement: 35.1 % Speedup: 1.54x
使用連接函數而不是使用+運算符加速1.5倍。為什么連接函數更快?
使用+操作符的字符串連接操作的時間復雜度為O(n2),而使用join函數的字符串連接操作的時間復雜度為O(n)。
總結
本文介紹了一些簡單的方法,將Python for循環的提升了1.3到970x。
使用Python內置的map()函數代替顯式的for循環加速970x
使用set代替嵌套的for循環加速498x[技巧#3]
使用itertools的filterfalse函數加速131x
使用lru_cache函數使用Memoization加速57x
審核編輯:劉清
-
生成器
+關注
關注
7文章
319瀏覽量
21128 -
python
+關注
關注
56文章
4807瀏覽量
85039 -
for循環
+關注
關注
0文章
61瀏覽量
2537
原文標題:加速Python循環的12種方法,最高可以提速900倍
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用CUDA并行化矩陣乘法加速Blender Python

1.3 兩種運行 Python 程序方法
python花式導包的八種方法
python執行函數的九種方法
python判斷是否包含子串的7種方法
Python 轉義字符的5種表示方法
調試Python程序代碼的幾種方法總結





 工商網監
工商網監
評論