 一個用于6D姿態估計和跟蹤的統一基礎模型
一個用于6D姿態估計和跟蹤的統一基礎模型
0. 筆者個人體會
今天筆者將為大家分享NVIDIA的最新開源方案FoundationPose,是一個用于 6D 姿態估計和跟蹤的統一基礎模型。只要給出CAD模型或少量參考圖像,FoundationPose就可以在測試時立即應用于新物體,無需任何微調,關鍵是各項指標明顯優于專為每個任務設計的SOTA方案。
下面一起來閱讀一下這項工作,文末附論文和代碼鏈接~
1. 效果展示
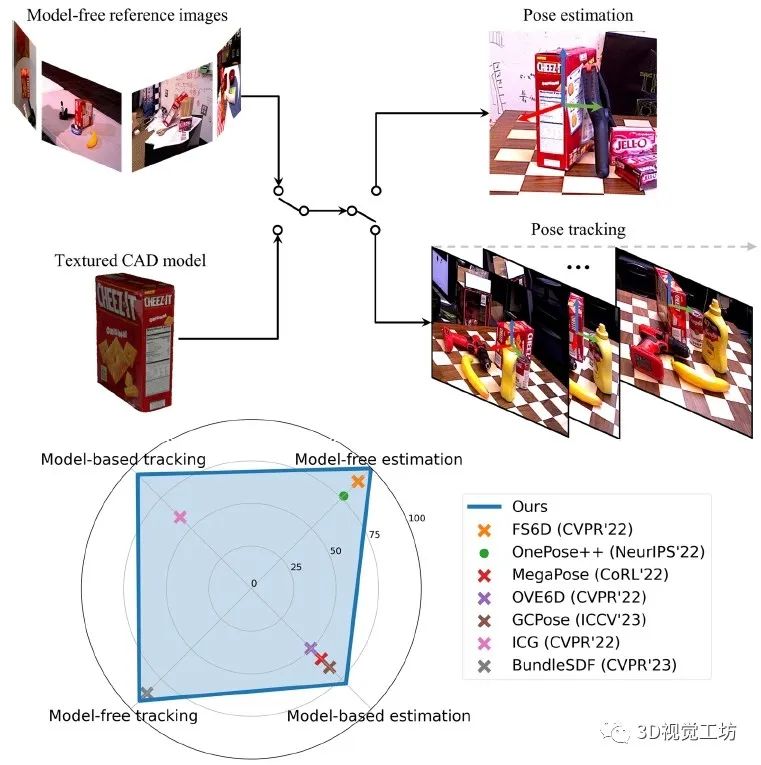
FoundationPose實現了新物體的6D姿態估計和跟蹤,支持基于模型和無模型設置。在這四個任務中的每一個上,FoundationPose都優于專用任務的SOTA方案。(·表示僅RGB,×表示RGBD)。這里也推薦工坊推出的新課程《單目深度估計方法:算法梳理與代碼實現》。
2. 具體原理是什么?
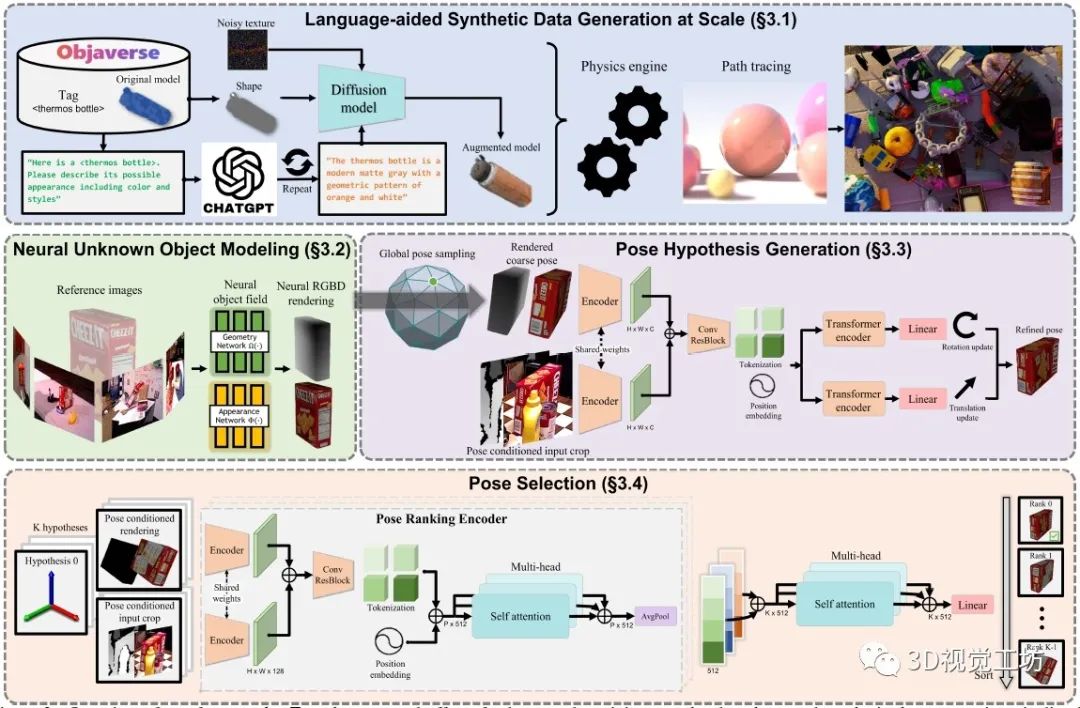
為減少大規模訓練的人工工作,FoundationPose利用3D模型數據庫、大型語言模型和擴散模型等新技術,開發了一種新的合成數據生成Pipeline。為了彌補無模型和基于模型的設置之間的差距,FoundationPose利用以對象為中心的神經場來進行隨后的渲染和新視圖RGBD渲染。
對于姿態估計,首先在物體周圍均勻地初始化全局姿態,然后通過細化網絡對其進行細化。最后將改進的位姿轉發給姿態選擇模塊,預測位姿的分數,輸出得分最高的位姿。
3. 和其他SOTA方法對比如何?
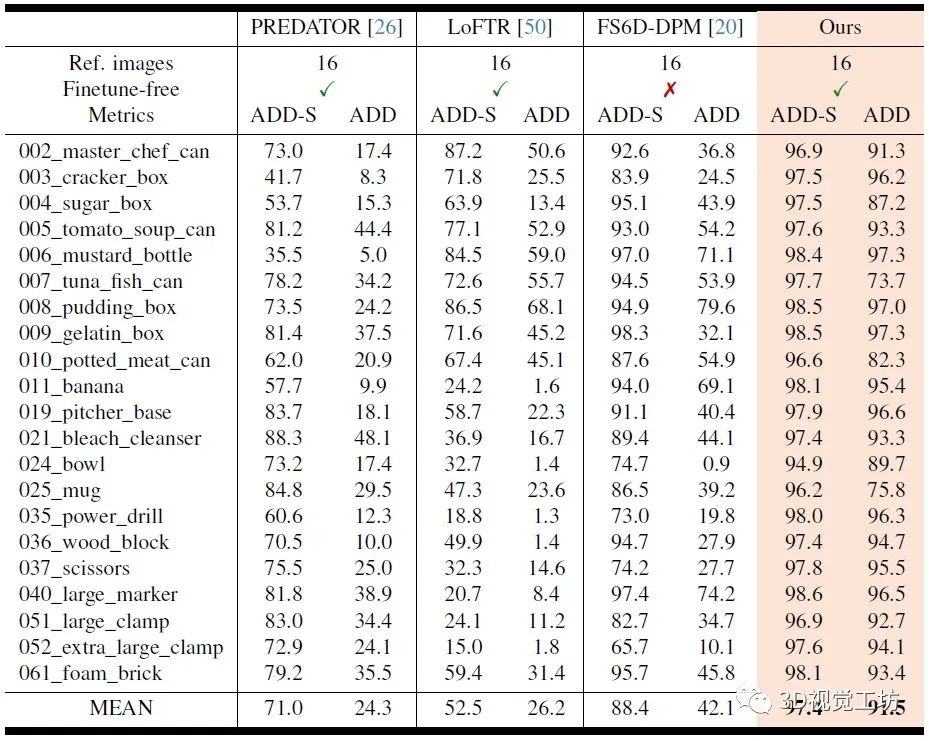
YCB-Video數據集上Model-free方案的位姿估計定量結果對比。
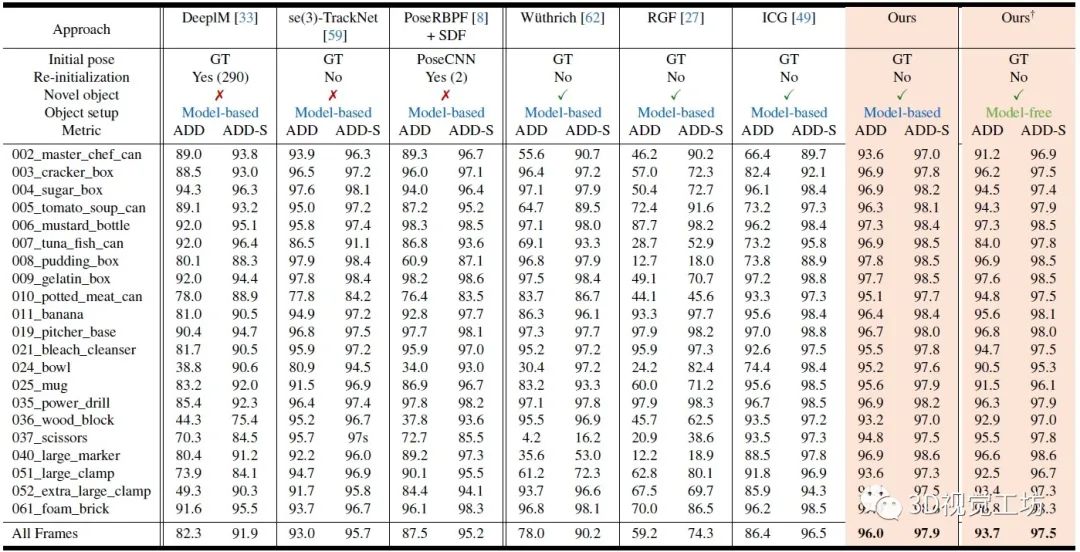
YCB-Video數據集上位姿跟蹤的定量對比。這里也推薦工坊推出的新課程《單目深度估計方法:算法梳理與代碼實現》。
對更多實驗結果和文章細節感興趣的讀者,可以閱讀一下論文原文~
4. 論文信息
標題:FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects
作者:Bowen Wen, Wei Yang, Jan Kautz, Stan Birchfield
機構:NVIDIA
原文鏈接:https://arxiv.org/abs/2312.08344
代碼鏈接:https://github.com/NVlabs/FoundationPose
審核編輯:劉清
-
NVIDIA
+關注
關注
14文章
5076瀏覽量
103724 -
RGB
+關注
關注
4文章
801瀏覽量
58716
原文標題:通用性超強!同時實現6D位姿估計和跟蹤!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
M1攜手6D Technologies云原生BSS平臺實現轉型
Todoist一鍵時間跟蹤
KerasHub統一、全面的預訓練模型庫
CNN, RNN, GNN和Transformer模型的統一表示和泛化誤差理論分析
ov華米聯手打造OneLink統一鏈接平臺
常見人體姿態評估顯示方式的兩種方式
如何利用TPA2012D2的輸出端和阻抗值4OHM的喇叭建一個cadence仿真模型?

光學跟蹤測量系統如何工作的
統一多云管理平臺怎么用?
意法半導體新款MEMS IMU LSM6DSV32X實現精確姿態識別應用
在PyTorch中搭建一個最簡單的模型
使用CYW43439連接藍牙設備時,每次連接到一個通過掃描找到的bt mac地址時,都會返回 \"未找到設備\",為什么?
包含具有多種類型信息的3D模型
Franka Robotics推出“Franka AI Companion”助力機器人領域研究創新






 工商網監
工商網監
評論