 CPU Cache是如何保證緩存一致性的?
CPU Cache是如何保證緩存一致性的?
單核CPU
我們介紹CPU Cache的組織架構及其進行讀操作時的尋址方式,但是緩存不僅僅只有讀操作,還有 寫操作 ,這會帶來一個新的問題:
當CPU是單核的情況下,CPU執行寫入數據操作,當數據寫入CPU Cache之后,此時CPU Cache數據會和內存數據就不一致了(這里前提條件:CPU Cache數據和內存數據原本是一致的),那么如何保證Cache和內存保持數據一致?
主要有兩種寫入數據的策略:
Write Through寫直達
Write Through寫直達是一個比較簡單的寫入策略,顧名思義就是每次CPU執行寫操作,如果 緩存命中 ,將數據更新到緩存,同時將數據更新到內存中,來保證Cache 數據和內存數據一致;如果緩存沒有命中,就直接更新內存
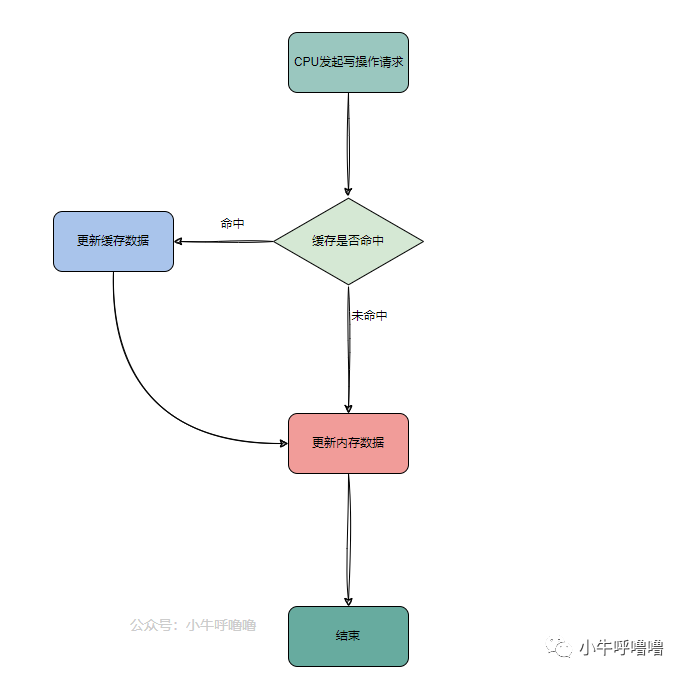
這個策略優點是簡單可靠,但是速度較慢,可以從上圖看出,每次寫操作都需要與內存接觸,此時緩存失去意義了,當然讀操作時緩存還是能起作用的
Write Back寫回
Write Back寫回,也被稱為 延遲寫入 ,相比于Write Through寫直達策略每次寫操作都需要內存參與;而Write Back策略則是,CPU向緩存寫入數據時,只是把 更新的cache區標記為dirty臟 (即Cache Line增加 dirty臟 的標記位 ** ),即來表示該Cache Line的數據,和內存中的數據是不一致的, 并不同步寫入內存**
也就是說對內存的寫入操作會被 推遲 ,直到當這個Cache Line要被刷入新的數據時,才將Cache Line的數據回寫到內存中
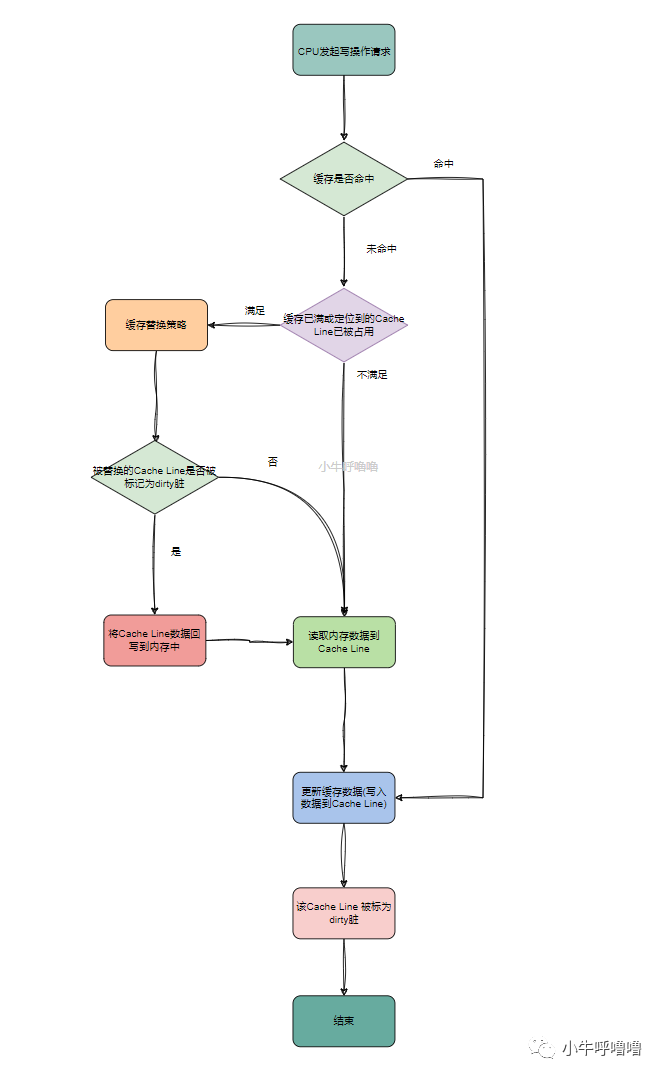
如今CPU Cache更多地采用write back寫回的方式,寫回的核心就是盡可能減少回寫內存的次數,來提升CPU性能,缺點就是實現起來比較復雜
我們來看下它的具體流程是:當CPU發起寫入操作請求時,如果緩存命中,就直接更新 CPU Cache 里面的數據,并把更新的Cache區標記為dirty臟
若緩存未命中的話,再判斷緩存區已滿或者定位到的Cache Line已被占用,緩存就會執行 替換策略 ,常見的策略有:隨機替換RR、先進先出FIFO、最近最少使用LRU等,我們后文再詳細介紹;
當被替換的Cache Line被標記為臟,也就是該Cache Line的數據,和內存中的數據是不一致的,此時會觸發操作: 將Cache Line中的數據回寫到內存中 ;然后,再把當前要寫入的數據,寫入到 Cache里,同時把Cache Line標記成臟
如果Cache Line的數據沒有被標記成臟的、緩存區未滿、定位到的Cache Line未被占用,那么直接把數據寫入到 Cache 里面,同時把Cache Line標記成臟
結束或者可以說是等待下一次CPU請求
常見的內存替換策略
RR
隨機替換 (Random Replacement,RR) ,顧名思義就是隨機選擇被替換的緩存塊
實現簡單,在緩存大小較大時表現良好,能夠減少緩存替換的次數,提高緩存命中率
但是沒有利用 “局部性原理”,無法提高緩存命中率;且算法性能不穩定,在緩存大小較小時,隨機替換可能導致頻繁的緩存替換,降低了緩存的命中率
FIFO
先進先出(First-In-First-Out, FIFO),根據數據進入緩存的順序,每次將最早進入緩存的數據先出去,也就是先進入緩存的數據先被淘汰。
實現簡單,適合短期的緩存數據;但不合適長期存儲數據的場景,緩存中的數據可能早已經過時;當緩存大小不足時,容易產生替換過多的情況,從而降低了緩存的效率
FIFO 算法 存在Belady貝萊迪現象 : 在某些情況下,緩存容量增大,命中率反而降低 。概率比較小,但是危害是無限的
貝萊迪在1969年研究FIFO算法時,發現了一個反例,使用4個頁框時的缺頁次數比3個頁框時的缺頁多,由于在同一時刻,使用4個頁框時緩存中保存的頁面并不完全包含使用3個頁框時保存的頁面,二者不是超集子集關系,造成都某些特殊的頁面請求序列,4個頁框命中率反而低
下圖引用于:Memory management and Virtual memory

LRU
最近最少使用 (Least-Recently-Used,LRU),記錄各個 Cache 塊的歷史訪問記錄, 最近最少使用的塊最先被替換 。LRU 策略利用了局部性原理,來提高緩存命中率:如果一個數據在最近一段時間內沒有被訪問,那么它在未來被訪問的概率也相對較低,可以考慮將其替換出緩存,以便為后續可能訪問的數據騰出緩存空間
實現簡單,適用于大多數場景,盡可能地保留最常用的數據,提高緩存的命中率;但是當緩存大小達到一定閾值時,需要清除舊數據,如果清除不當可能會導致性能下降;且無法保證最佳性能,可能會出現緩存命中率不高的情況
LRU 不會出現 Belady 現象,因為容量更小緩存中的數據集合始終是容量更大緩存中數據集合的子集
下圖來源于:LRU and LFU Cache Algorithms

當然還有許多其他算法,比如LFU、2Q、MQ、ARC等等,大家感興趣地可以自行去了解
多核CPU
上述都是單核CPU的情況,但如今CPU都是多核的,由于每個核心都獨占的 Cache(L1,L2),就會存在當一個核心修改數據后,另外核心Cache中數據不一致的問題,那又該如何保證緩存一致性呢?
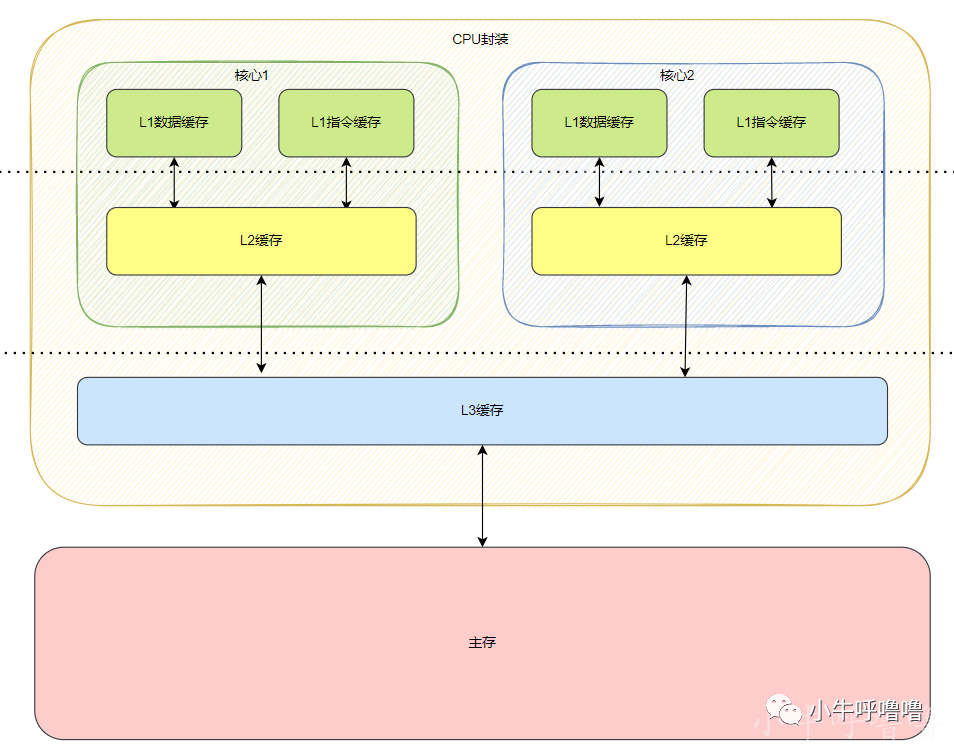
這個時候,單核情況下的寫直達策略還是寫回策略都無法解決一致性的問題,那么我們需要一種全新的機制來保證緩存一致性
多核CPU緩存一致性主要有2種策略:基于總線監聽的一致性策略 和 基于目錄的一致性策略
基于總線監聽的一致性策略
基于總線監聽的一致性策略,也叫 總線嗅探 (Bus Snooping),它的工作原理是:
- 當有一個CPU核心修改了Cache中的值,會通過總線把這個事件廣播給其他所有的核心;
- 而每個CPU核心都會去監聽總線中的數據廣播,并檢測是否有相同數據的副本,在本核心的Cache中;如果有副本,就執行相應操作來確保多核心的緩存一致性
其中將相應操作傳播到所有擁有該Cache副本的核心中時,一般有2種處理辦法:
- write-update寫更新協議:某個Cache發生寫操作,就傳播所有核心中Cache都更新該數據副本,由于需要把對應的數據傳輸給其他CPU核心,所以該策略成本較高
- write-invalidate寫失效協議:某個Cache發生寫操作,就把其他Cache中的該數據副本置為 無效 ,這樣CPU 只需也只能讀取和寫入數據的其中一個副本 ,因為其他核心的緩存中該數據副本都已經無效的。這也是最常用的監聽協議
基于目錄的一致性策略
基于目錄的一致性策略會維護一個數據結構,叫做 目錄 (directory-based),保存著緩存中不同數據副本寫入哪些Cache及其對應的狀態等相關信息;
當CPU執行寫操作時,不會再向所有核心的Cache進行廣播,而是是通過此目錄來跟蹤所有緩存中數據副本的狀態,來僅將其發送到指定的數據副本中;這樣相比總線嗅探節省大量總線流量,更具有擴展性
它又分為SI,MSI,MESI策略,我們這里主要介紹MESI協議
MESI協議
MESI協議是一個基于失效的緩存?致性協議,通過總線嗅探來處理多個核心之間的數據傳播,同時也用 目錄狀態機制 ,來降低了總線帶寬壓力。
所謂緩存一致性是指:通過在緩存之間做同步,達到仿佛系統不存在緩存時的行為。一般有 如下要求:
- Write Propagation寫傳播:在一個CPU核心里,Cache Line數據更新,能夠傳播到其他核心的對應的Cache Line里
- Transaction Serialization事務順序化:在一個CPU核心里面的讀寫操作,不管這些指令最終的先后順序如何,但在其他的核心看起來,順序要一樣的。
這也對應我們常說的并發可見性和順序性~
四大狀態
MESI名字中,"M", "E", "S", "I"這4個字母分別代表了Cache Line的四種狀態(存放再Cache Line),分別是:
- M:代表已修改(Modified),表明
Cache Line被修改過,但未同步回內存(就是上面我們說的臟數據) - E:代表獨占(Exclusive),表明
Cache Line被當前核心獨占,和內存中的數據一致(數據是干凈的) - S:代表共享(Shared),表明
Cache Line被多個核心共享,且數據是干凈的 - I:代表已失效(Invalidated),表明
Cache Line的數據是失效的,數據未加載或緩存已失效
下圖來源于:https://en.wikipedia.org/wiki/MESI_protocol

上圖圖中,紅色表示總線初始化事件,黑色表示處理器初始化事件, MESI其實是一個有限狀態機 ,狀態轉換主要有2種場景,緩存所在處理器的讀寫、其他處理器的讀寫。
下面我們一起來看看這2種場景分別有哪些事件:
事件
處理器CPU對緩存的請求,也就是讀寫操作:
- PrRd: 處理器請求讀一個緩存塊
- PrWr: 處理器請求寫一個緩存塊
同步的信息通過總線傳遞,同步信號(總線對緩存的請求)有下面5種:
- BusRd: 總線窺探器收到其他處理器請求讀一個緩存塊(總線的請求被總線窺探器監視)
- BusRdX: 窺探器請求指出其他處理器請求寫一個該處理器不擁有的緩存塊
- BusUpgr: 窺探器請求指出其他處理器請求寫一個該處理器擁有的緩存塊
- Flush: 窺探器請求指出請求回寫整個緩存到主存
- FlushOpt: 窺探器請求指出整個緩存塊被發到總線以發送給另外一個處理器(和 Flush 類似,但是緩存到緩存的復制)
狀態標記關系
下圖是mesi的狀態標記圖,表示當一個Cache Line的調整的狀態的時候,另外一個Cache Line能夠調整的對應狀態
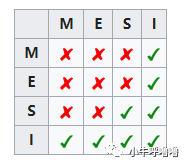
舉個例子,假如Cache 1 中存放變量x = 0的Cache Line處于S狀態(共享);那么其他擁有x變量的Cache 2、Cache 3等Cache x的Cache line只能調整為S狀態(共享)或調整為 I 狀態(無效)
狀態轉化過程
結合上面MESI各個狀態含義以及事件,我們再來詳細看看狀態流轉與事件的關系:

Store buffer
如果嚴格按照MESI協議,某一個核心A在寫入Invalid狀態的緩存時,需要向其他核心廣播RFO獲得獨占權;當其它 CPU 的Cache Line收到消息后,使他們對應的緩存副本失效,并返回 Invalid acknowledgement 消息;直到這個核心A收到消息才能修改緩存,期間當前核心只能空等待,這對于CPU來說很浪費
整個過程有較長的延時,比較緩慢,一般緩存會通過 Store Buffer寫緩沖區和 Invalidate Queue失效隊列機制來進一步優化
引入Store Buffer后,當核心寫入緩存時,直接寫入Store Buffer,當前核心無需等待,繼續處理其他事情; 由Store Buffer接手后續工作 ,由Store Buffer向其他核心廣播RFO獲得獨占權,等收到 ACK 后再將修改緩存上。
但是它會導致,雖然核心A以為某個修改寫入緩存了,但其實還在Store buffer里。此時如果要讀數據,則需要先掃描 Store buffer,另外其它核心在數據真正寫入緩存之前是看不到這次寫入的
Invalidate Queue
對于其它的CPU核心而言,在其收到RFO請求時,需要更新本地的Cache Line狀態,并回復Invalid acknowledgement消息。然而在收到RFO請求時,CPU核心可能在處理其它的事情,無法及時回復。這就會導致當前核心A在等待回復過來的Invalid acknowledgement消息
引入Invalidate Queue后,收到Invalid消息的核心會立刻返回Invalid acknowledgement消息,然后把 Invalid 消息加入 Invalidate Queue ,等到空閑的時候再去處理 Invalid 消息
但是它也會導致,此時核心A可能以為其他核心的緩存已經失效,但真的嘗試讀取時,緩存還沒有置為Invalid狀態,于是有可能讀到舊的數據

內存屏障
Store Buffer是對MESI發生寫操作命令的優化,而Invalidate Queue則是對接受寫操作命令時的優化
這些優化,雖然提高了CPU的緩存利用率,但也會帶來各自的問題,所以引入了 內存屏障 ,筆者之前在寫Java關鍵字volatile也提及過
內存屏障又可以細分為:寫屏障和讀屏障
- 這里插入
store buffer寫屏障,內存屏障會強制將store buffer的數據寫到緩存中,這樣保證數據寫到了所有的緩存里; - 插入
read barrier讀屏障會保證invalidate queue的請求都已經被處理,這樣其它 CPU 的修改都已經對當前 CPU可見
-
處理器
+關注
關注
68文章
19409瀏覽量
231187 -
Cache
+關注
關注
0文章
129瀏覽量
28433 -
狀態機
+關注
關注
2文章
492瀏覽量
27649 -
緩存器
+關注
關注
0文章
63瀏覽量
11692 -
FIFO電路
+關注
關注
1文章
4瀏覽量
4929
發布評論請先 登錄
相關推薦
介紹ARM存儲一致性模型的相關知識
如何解決數據庫與緩存一致性

6678多核之間的L1 CACHE一致性是由硬件實現的嗎
改進的基于目錄的Cache一致性協議
CMP中Cache一致性協議的驗證
C64x+ DSP高速緩存一致性分析與維護
Cache一致性協議優化研究
自主駕駛系統將使用緩存一致性互連IP和非一致性互連IP

介紹下cpu緩存一致性(MESI協議)

Redis緩存與Mysql如何保證一致性?

異構計算下緩存一致性的重要性





 工商網監
工商網監
評論