 500篇論文!最全代碼大模型綜述
500篇論文!最全代碼大模型綜述
11月14日,螞蟻集團聯合上海交通大學發布55頁代碼大模型綜述,覆蓋超過50個模型、30個下游任務、500篇參考文獻,全方位總結大語言模型在代碼相關應用中的最新進展與挑戰。
引言 隨著大語言模型遍地開花式的涌現,如何將他們與實際應用,尤其是軟件工程相關應用進行有效結合成為了學界與工業界都日益關注的問題。然而,目前這些應用仍非常有限:以 HumanEval、MBPP 為代表的代碼生成任務在 NLP 與大模型社區中一枝獨秀,但這些經典數據集上的性能已接近飽和,而其他諸如代碼翻譯、代碼注釋、單元測試生成等任務則鮮有人問津。另一方面,在軟件工程社區中,語言模型的應用則仍以CodeBERT為代表的 encoder-only 模型和 CodeT5 為代表的 encoder-decoder 模型為主,而 GPT 系列大模型的工業級應用方興未艾。
與此前已有的多篇綜述不同,本文從跨學科視角出發,全面調研 NLP 與軟件工程(SE)兩個學科社區的工作,既覆蓋以 OpenAI GPT 系列與 Meta LLaMA 系列為代表的生成式大模型與代碼生成任務,也覆蓋 CodeBERT 等專業代碼小模型及代碼翻譯等其他下游任務,并重點關注 NLP 與 SE 的融合發展趨勢。
本文分為技術背景、代碼模型、下游任務、機遇挑戰四部分。第一部分介紹語言模型的基本原理與常見訓練目標,以及對 Transformer 基本架構的最新改進。第二部分介紹 Codex、PaLM 等通用大模型及 CodeGen、StarCoder 等專業代碼模型,并包括指令微調、強化學習等 NLP 技術以及 AST、DFG、IR 等程序特征在代碼模型中的應用。第三部分簡單介紹 30+ 個代碼下游任務,并列出常見數據集。第四部分給出當下代碼大模型的機遇與挑戰。
技術背景 雖然如今的生成式大模型大都基于 Transformer decoder,但其架構并不是自從2017年提出以來就一塵不變。本節簡單介紹前置層正則化(pre-norm),并行注意力(parallel attention),旋轉位置編碼(RoPE),多檢索注意力和群檢索注意力(MQA、GQA),以及針對注意力的硬件IO優化(FlashAttention),熟悉的朋友可以略過~ 01經典多頭自注意力
在2017年的論文 Attention Is All You Need 中,Transformer 的每一層定義如下:

其中LN為層正則化(Layer Normalization),Attention為多頭自注意力(MHA)子層,FFN為全連接(Feed-Forward Network)子層。
02前置層正則化
2019年,GPT-2將層正則化移到了每一子層的輸入:
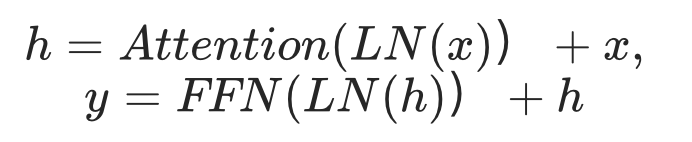
后續 decoder-only 工作基本效仿了這一架構讓訓練更加穩定,在encoder-decoder模型方面,T5系列也采用了這一架構。
03并行注意力
2021年,GPT-J 將自注意力與全連接層的順序計算改為了并行以提高訓練效率:
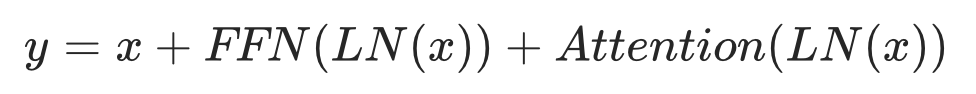
PaLM論文實驗中發現使用此架構可以提高15%訓練速度,在8B模型上對性能稍有損害,在62B模型上則基本沒有影響。 04位置編碼
由于自注意力無法區分輸入詞元間的位置關系,位置編碼是 Transformer 架構的重要組成部分,其外推能力也決定了模型能處理的序列長度。
經典 Transformer 使用不可學習的余弦編碼,加在模型底層的詞向量輸入上。GPT、BERT將其改為可學習的絕對位置編碼,并沿用到了RoBERTa、BART、GPT-2、GPT-3等經典模型。Transformer-XL 與 XLNet 使用相對位置編碼,根據自注意力中 k 與 q 的相對位置關系將對應可學習的向量加在 k 上,而 T5 則對此做了簡化,將每個相對位置的編碼作為可學習的標量加在 k 與 q 的點積結果上。
RoPE(Rotary Position Embedding)與 ALiBi(Attention with Linear Biases)是兩種最新的位置編碼技術。RoPE 將 q 與 k 乘以分塊對角旋轉矩陣來注入位置信息:
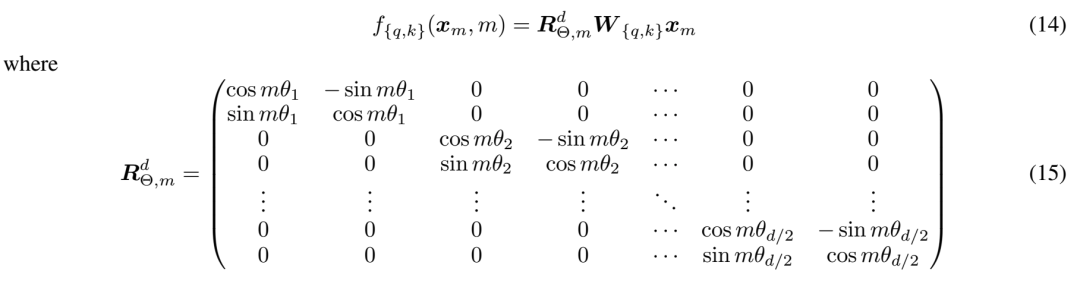
圖源 RoPE 論文,圖中 m 為位置下標。PaLM、LLaMA 等主流大模型都采用了 RoPE。
而 ALiBi 直接對注意力矩陣進行先行衰減:
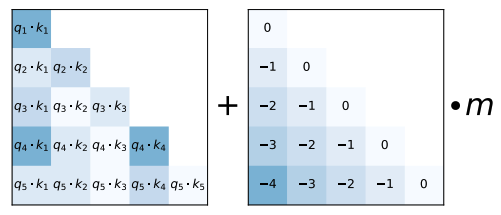
圖源 ALiBi 論文。BLOOM 使用 ALiBi 作為位置編碼。
05MQA、GQA、FlashAttention
Transformer 架構的一大挑戰是自注意力關于輸入序列長度的平方復雜度。許多工作通過近似方法來模擬自注意力并同時降低復雜度,如 Sparse Transformer, Reformer, Longformer, Linformer, Performer, Sinkformer, cosFormer, Sliceformer 等,但這些方法都沒有在大模型上得到測試。另外,這些方法有很多的出發點是序列長度與隱藏層緯度的關系 n<
因此,大模型中針對自注意力的加速優化通常出發點并不是注意力的計算過程,而是硬件的讀寫。MQA 就是基于此思想,在多頭自注意力中讓不同頭之間共享 K 與 V,而每個頭保留自己的 Q。此優化對訓練速度幾乎無影響,而對推理速度則直接提升 h 倍(h為注意力頭數,如 BERT-large 為 16,GPT-3 175B為96)。此加速的來源是推理階段所有詞元需要自回歸生成,而在生成過程中每一步的計算都涉及此前所有詞元的 q 與 k。將這些 q 與 k從顯存加載到GPU計算核心的過程構成了性能瓶頸。
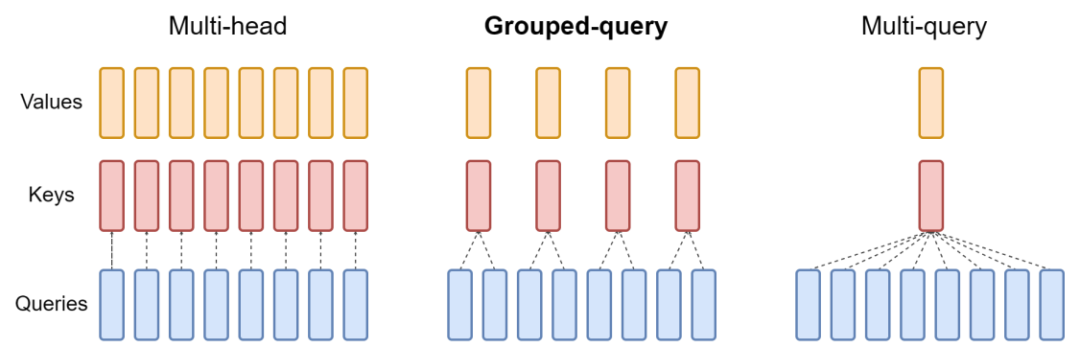
至于GQA則顧名思義,是MHA與MQA的中間產品:
圖源GQA論文。
在主流大模型中,PaLM 使用 MQA,而 LLaMA 2 及其變體 Code LLaMA 使用 GQA。
另一相關技術是FlashAttention。該技術通過分布式計算中的 tiling 技術對注意力矩陣的計算進行優化。值得注意的是,與其他優化技術不同,FlashAttention 并不是近似方法,不會改變計算結果。
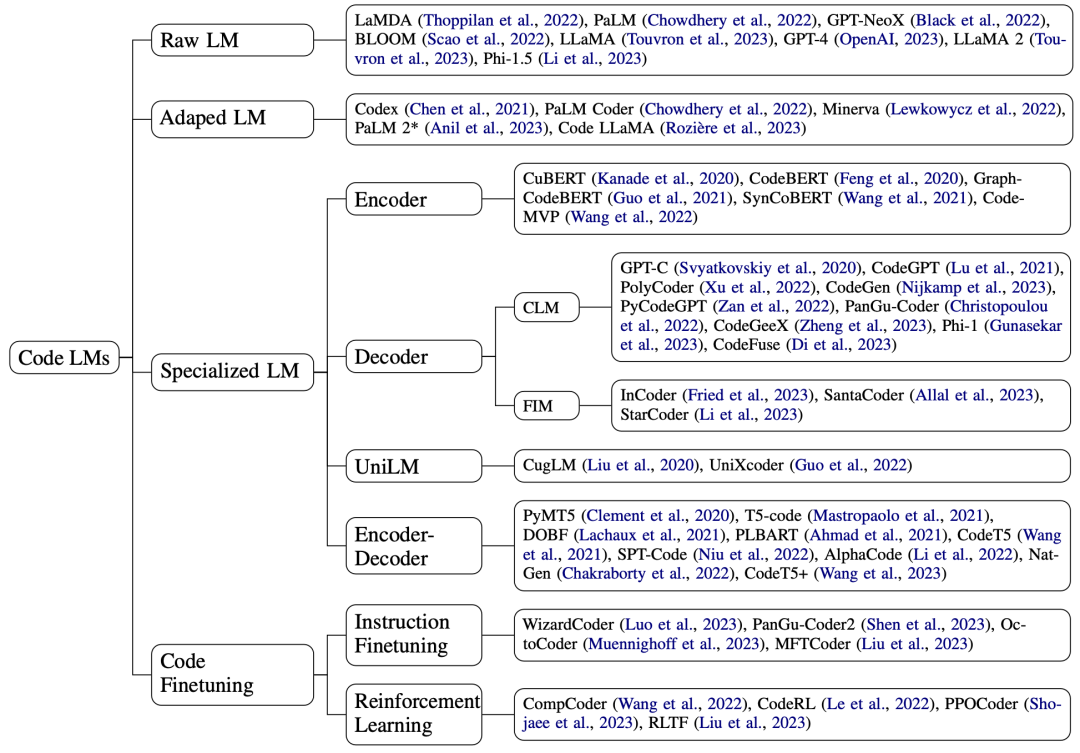
代碼模型 我們將代碼模型按預訓練領域分為通用大模型、代碼加訓大模型及在代碼上從零開始預訓練的專業模型,并將最后一類按模型架構分為 Transformer encoder、decoder、encoder-decoder以及 UniLM,同時也特別關注了今年出現的在代碼上進行指令微調、利用編譯器反饋進行強化學習的工作,以及將語法樹、數據流等程序特有特征融入模型中的工作:
01通用大模型與加訓大模型
提起代碼大模型,大部分人最熟悉的就當數 Codex 了。Codex 是基于 GPT-3 在 Python 數據上進行了 100B 詞元自監督加訓獲得的模型。與 Codex 類似的還有對 PaLM 做了 39B 詞元加訓的 PaLM Coder,以及對 LLaMA 2做了超過 500B 詞元加訓的 Code LLaMA。
當然,大模型并不一定需要加訓才能處理代碼。如今的大模型預訓練數據量動輒數萬億詞元,其中就經常包括代碼。例如,最常用的公開預訓練數據集之一Pile就包括了95GB的代碼,而BLOOM的預訓練數據集ROOTS也包括了163GB、13種編程語言的代碼。
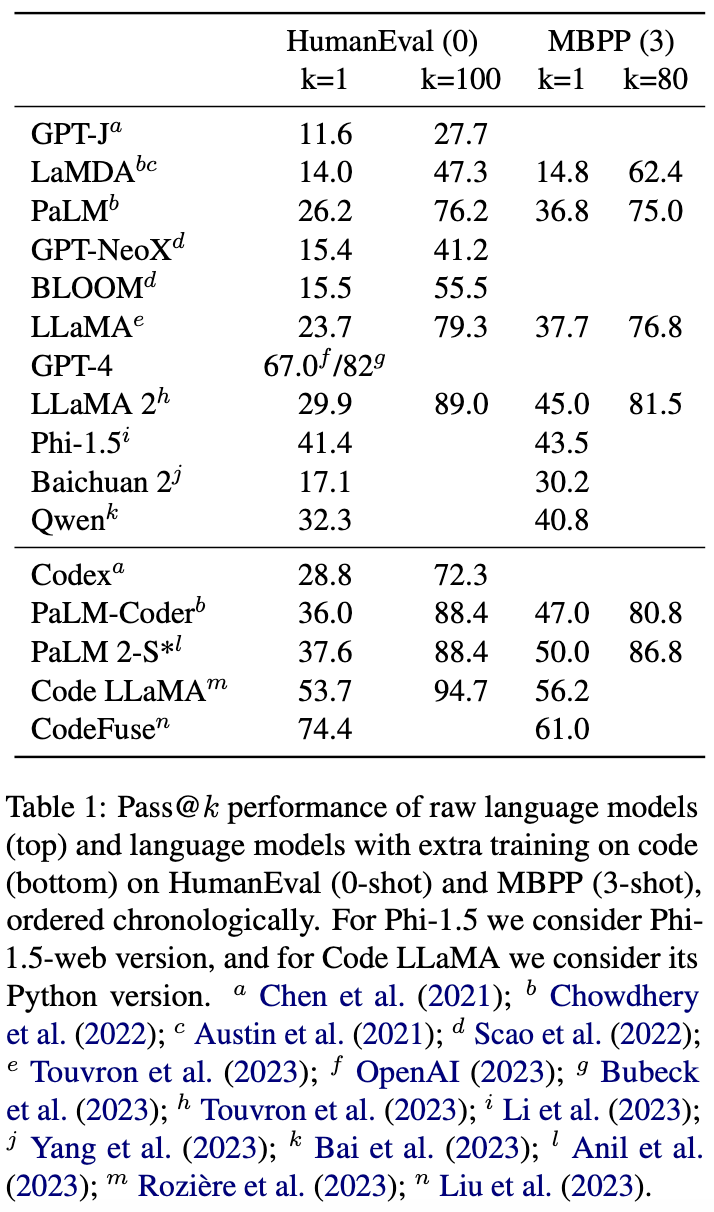
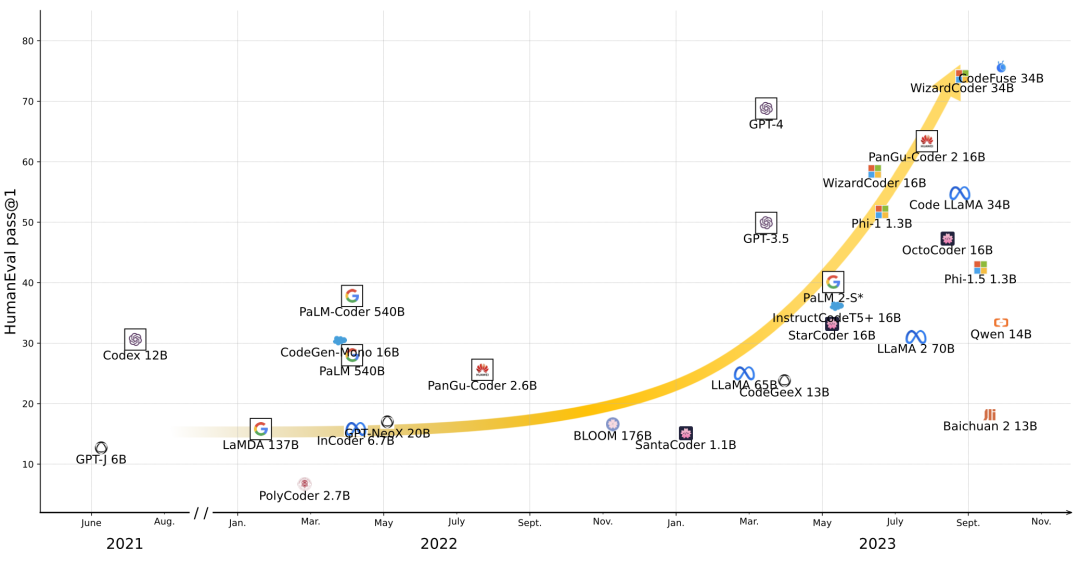
通用大模型在HumanEval與MBPP上的性能:
02代碼專用模型
自從GPT、BERT掀起預訓練模型熱潮后,軟件工程領域就已有不少工作在代碼上復現了這些模型。
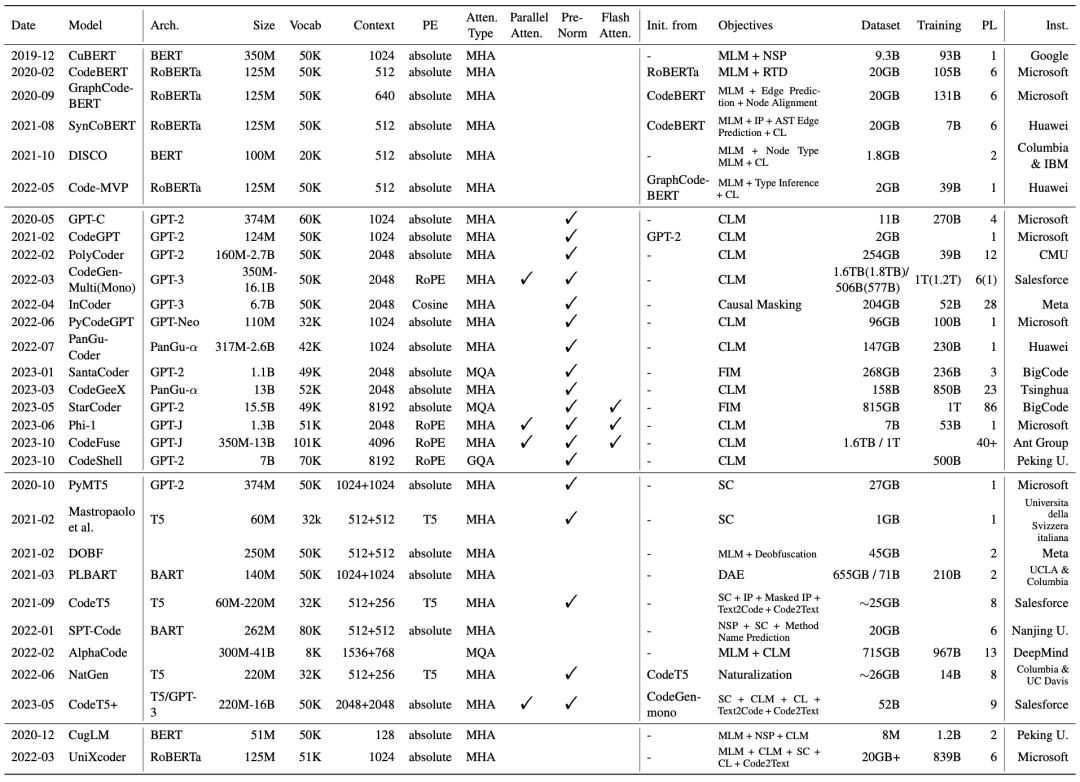
與此前綜述不同,我們不僅關注各模型的訓練目標與數據等高層設計,也詳細討論了包括位置編碼、注意力實現在內的技術細節,并總結進一圖概覽供大家查閱:
Encoder
CodeBERT 是軟工領域最有影響力的模型之一。它從 RoBERTa 初始化,用 MLM+RTD(RTD 是 ELECTRA 的預訓練目標 Replaced Token Detection)的目標在代碼上進行了訓練。從上表可以看出,此后的多個 encoder 代碼模型,包括 GraphCodeBERT, SynCoBERT, Code-MVP,都是基于 CodeBERT 開發。
在 NLP 中,BERT 預訓練時還使用了 NSP(Next-Sentence Prediction)任務。雖然以 RoBERTa 為代表的后期工作大都認為該任務并沒有幫助,但該任務的格式也為 encoder 預訓練開拓了思路,在代碼模型中催生出了很多變種。由于代碼不同于自然語言,可以通過自動化方法抽取抽象語法樹(AST)及注釋等伴隨特征,以 NSP 的格式進行對比學習成了一種常見方法。SynCoBERT 在代碼-AST,注釋-代碼-AST等不同特征之間進行對比學習,DISCO則分別使用bug注入和保持語義的變換來構建正負樣本,而Code-MVP則還額外加入了控制流(CFG)信息。
Decoder
說起 decoder,大家第一個想到的當然就是 GPT 模式的自回歸預訓練了。確實,自從2020年以來已經出現了包括 GPT-C, CodeGPT, PolyCoder, CodeGen, PyCodeGPT, PanGu-Coder, CodeGeeX, Phi-1, CodeFuse, CodeShell, DeepSeek Coder 在內的眾多自回歸 decoder,大小從 100M 到 16B 不等。
但是,以 InCoder、FIM、SantaCoder、StarCoder 為代表的部分工作也探索了使用非傳統自回歸目標來訓練 decoder 的可能。這些工作首先將輸入數據轉換為填空的形式:將整段輸入隨機切分為前綴-中部-后綴三段,并將其重新排序為前綴-后綴-中部(PSM 格式)或后綴-前綴-中部(SPM 格式),然后再將數據送進模型進行自回歸訓練。需要注意的是,在數據轉換之后三段都參與自回歸預訓練。
Encoder-Decoder
在 NLP 中,以 BART 與 T5 為代表的 encoder-decoder 模型即使在如今的大模型時代也仍占據著一席之地,代碼處理自然也少不了它們的身影。
由于編碼器-解碼器架構能夠天然處理序列到序列建模問題,因此在代碼模型的訓練過程中除了 BART 的 DAE(Denoising Auto-Encoding)與 T5 的 Span Corruption 這兩個標準任務,許多代碼特有的特征也被用來進行序列到序列的預訓練學習。例如 DOBF 就是用反混淆任務,來訓練模型將混淆后的代碼轉換為原始代碼。類似的,NatGen 提出了“自然化”任務,從人工轉換產生的非自然代碼來復原原始代碼。
標識符預測也是代碼預訓練中的另一常見的任務。CodeT5 以序列標注的形式來在預訓練過程中學習每個詞元是否為標識符,而 SPT-Code 則直接以序列到序列生成的形式來預測方法名。
此外,隨著 NLP 中 UL2 將自回歸預訓練與去噪預訓練統一到了 encoder-decoder 架構下,最新的 encoder-decoder 代碼模型 CodeT5+ 也采用了類似的預訓練方式。
03指令微調與強化學習
在 NLP 中,指令微調(instruction finetuning)與人類反饋強化學習(RLHF)在 ChatGPT 等對話模型的人類對齊過程中起到了必不可少的作用。指令微調通過在多樣的指令數據集上訓練模型來解鎖跨任務泛化的能力,而強化學習則通過獎勵模型的自動化反饋來訓練模型向人類的偏好(如幫助性 Helpfulness,以及安全性 Safety 等)對齊。
這兩項技術也在代碼處理中得到了應用。WizardCoder 與 PanGu-Coder 2 都使用 NLP 中 WizardLM 模型提出的 Evol-Instruct 方法,用 ChatGPT 等模型來從現有的指令數據中進化出更多樣的指令集,并用生成的指令來微調 StarCoder。OctoCoder 與 OctoGeeX 則沒有使用大模型生成的指令,而是使用了 GitHub 上的 commit 記錄及前后代碼來作為指令微調 StarCoder 與 CodeGeeX。最近,螞蟻集團開源的 MFTCoder 框架還在指令數據中顯式加入了多種下游任務,來定點提升微調模型在這些任務上的性能。
而在強化學習方面,代碼處理相較自然語言處理存在著天然優勢 - 編譯器可以代替人類來自動化地生成精準的反饋。CompCoder、CodeRL、PPOCoder、RLTF 等工作就利用了這一特性來微調 CodeGPT 或 CodeT5,PanGu-Coder 2 也將強化學習應用在了更大的 StarCoder 中。
下游任務 隨著以 Codex 為代表的代碼大模型的興起,根據自然語言描述生成相應代碼的代碼生成任務成了大模型關注的重點,HumanEval 也成為了最新大模型必測的基準:
但除了代碼生成,我們也整理了其他30個 SE 下游任務:
SQL 生成:從自然語言查詢生成 SQL 語句
數學編程:通過生成代碼來解決 GSM8K 等數學任務
代碼檢索:從現有代碼池中匹配與自然語言查詢最匹配的代碼
代碼搜索:從現有代碼池中匹配與輸入代碼具有相同或相似功能的代碼
代碼補全:根據代碼片段補全其余部分,常用于 IDE 插件
代碼翻譯:將代碼從一種編程語言翻譯到另一種編程語言
代碼修復:修復代碼中的bug
代碼填充:類似代碼補全,但可以參考兩邊而不僅是單邊的上下文
代碼去混淆:從混淆(即改變了標識符名稱)的代碼中復原出原始代碼
軟件測試相關任務:單元測試生成,斷言生成,變種生成,測試輸入生成,代碼評估
類預測:預測動態編程語言(如Python)代碼中變量類型或函數參數、返回值的類型
代碼摘要:為代碼生成相應的自然語言解釋或文檔
標識符預測:預測代碼中有意義的標識符(變量、函數、類等)名字
缺陷檢測:檢測輸入代碼是否存在缺陷或漏洞
克隆檢測:檢測兩段輸入代碼是否語義相等
代碼推理:以問答的形式評估大模型對代碼相關知識(如代碼功能、概念、算法等)的掌握
代碼分類:在事先定義好的類別中判斷代碼的功能,也可以是判斷代碼的作者
文檔翻譯:將代碼相關文檔從一種自然語言翻譯到另一種自然語言
記錄分析:對軟件系統運行過程中產生的記錄進行分析,輸出形式化的表格或自動檢測問題所在
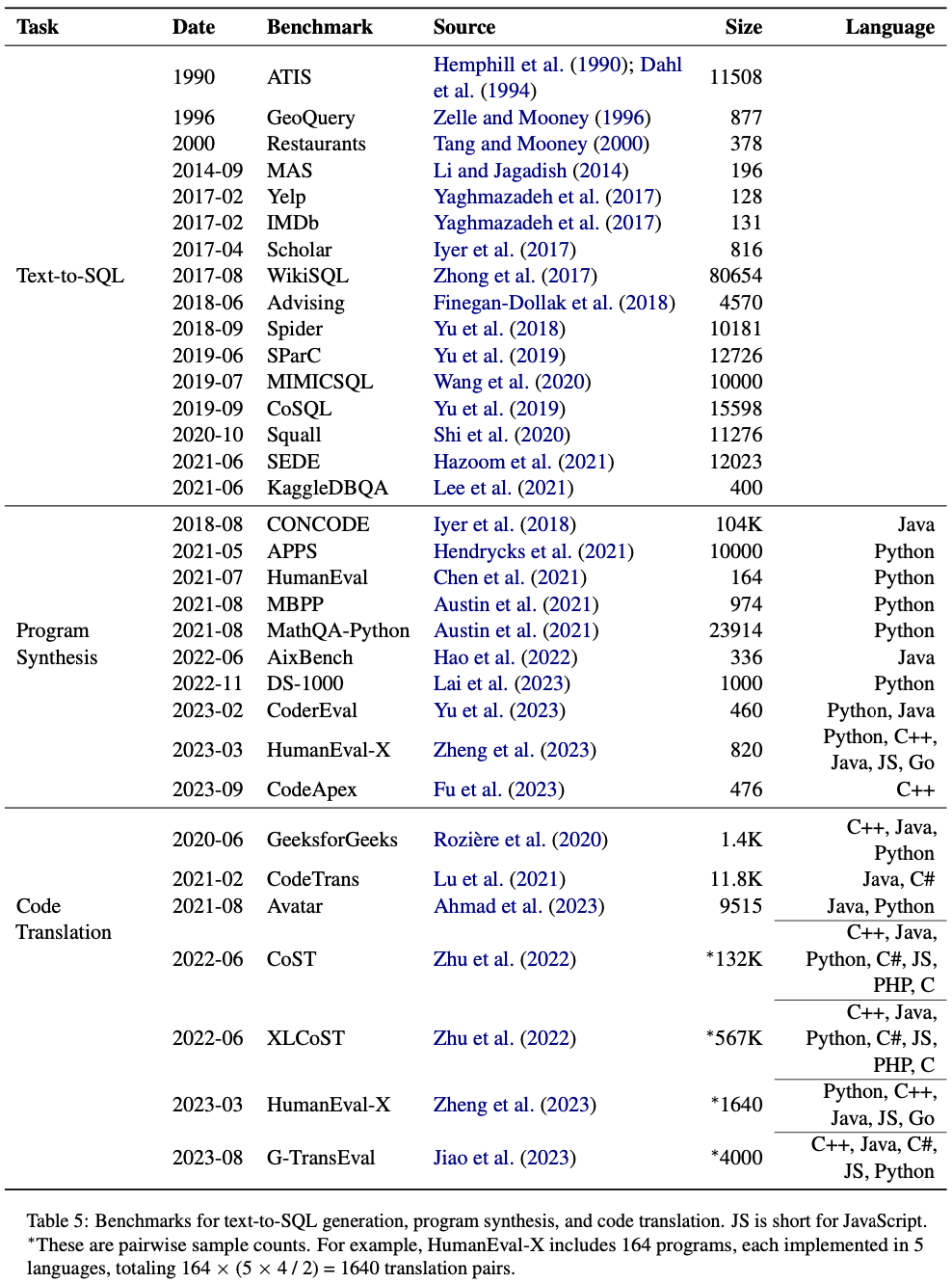
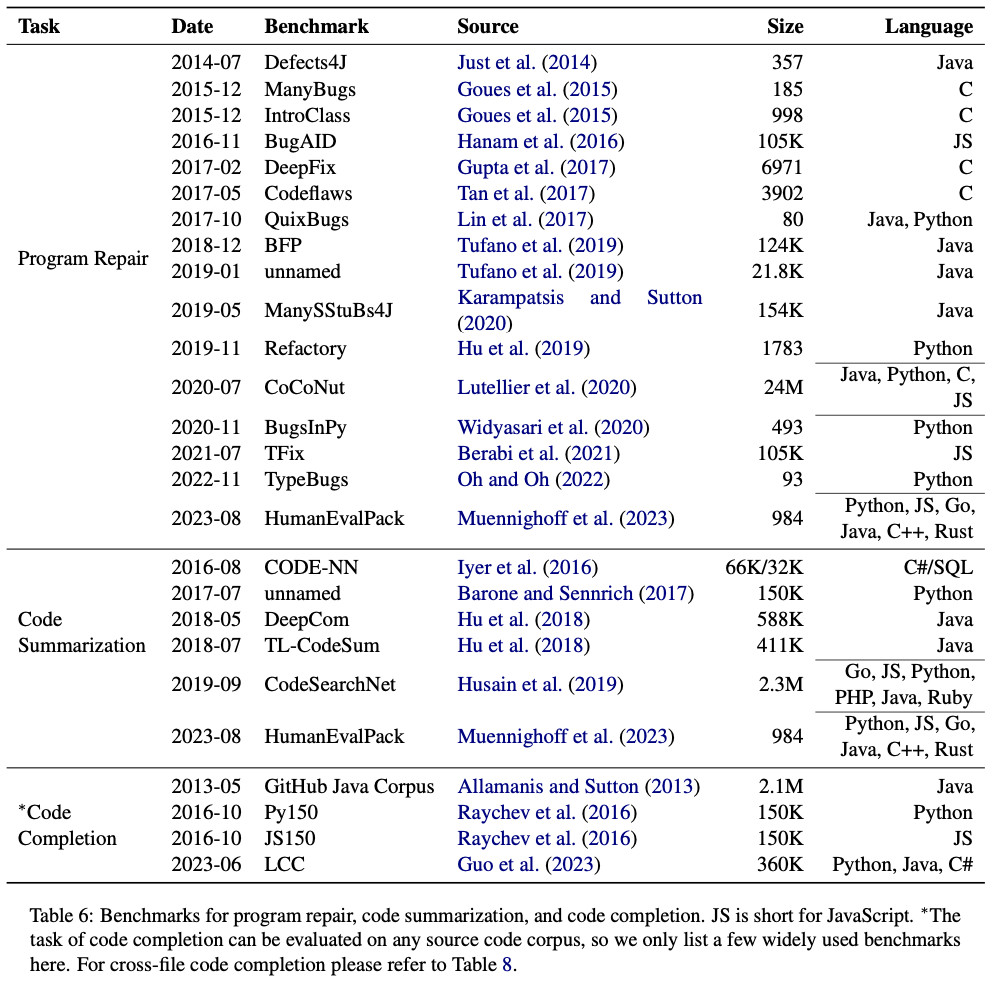
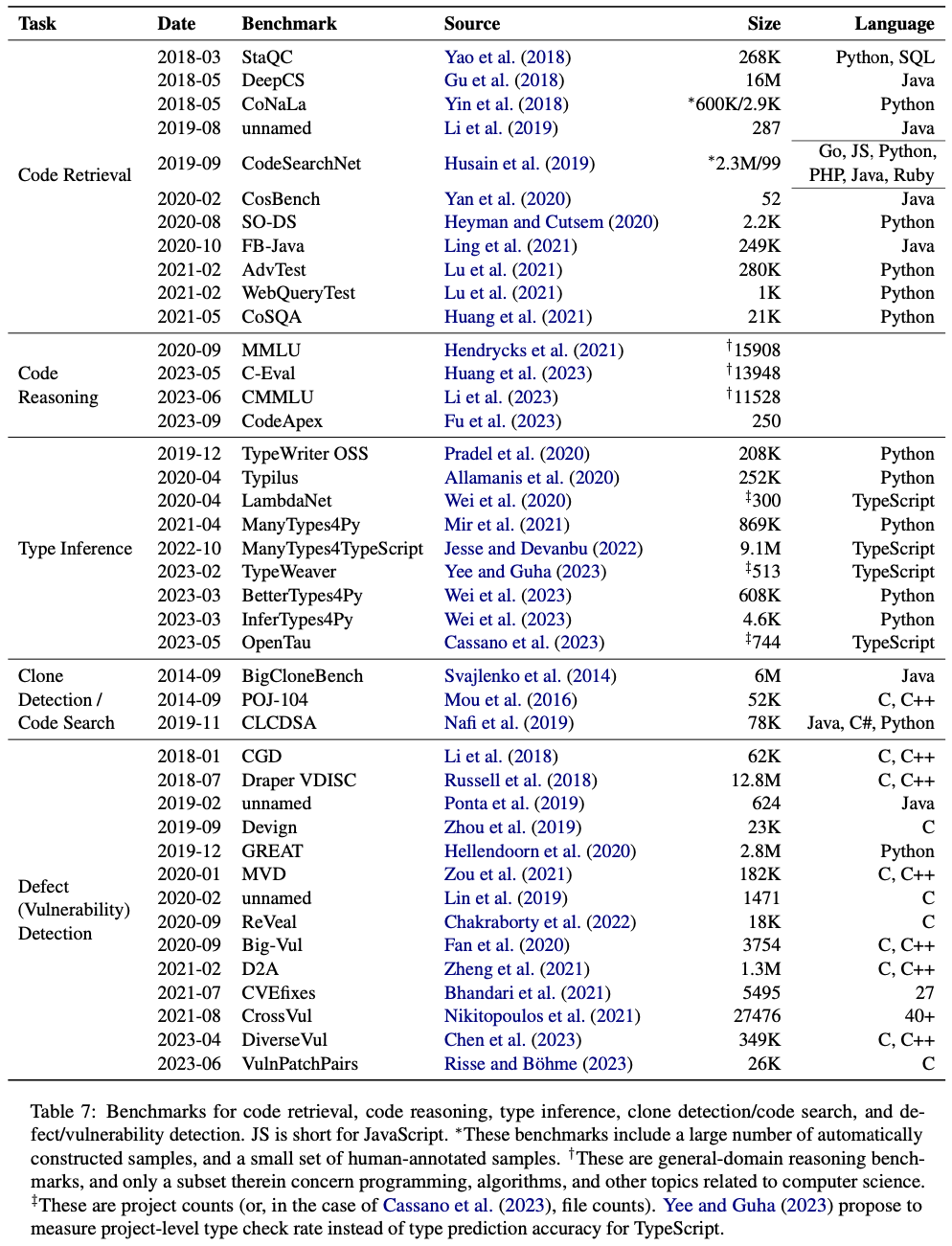
在論文中,我們也羅列了部分任務的現有標準數據集:
這些數據集的網址鏈接都在 GitHub repo 中給出,而其他任務,尤其是單元測試生成、斷言生成、代碼反混淆等軟件測試相關任務,目前還沒有大規模的標準數據集,大語言模型在其中的應用也較少,是 NLP 與 SE 未來工作可以重點考慮的方向。
機遇挑戰 不久之前,Github Universe 2023上,微軟發布了一些 GitHub Copilot 的更新,包括 Copilot Workspace 這種引領業界前沿的工作:從一個 Issue 開始,在軟件研發的整個生命周期做到倉庫級別的需求實現、測試、構建等迭代。這也給了我們很大的啟發。基于前面的分析和相關先驅探索的啟發,本文的最后也總結了在軟件工程中應用語言模型的當下挑戰:
構建更真實的評估基準,來替代以幾乎被刷爆的 HumanEval
獲取更高質量的數據,以及對 Phi-1 等模型“用 AI 數據訓練 AI”的理解與反思
將抽象語法樹、數據流、控制流等代碼獨有且可以自動獲取的特征無縫銜接進大語言模型
在更多 SE 下游任務,尤其是軟件測試相關任務中應用大語言模型
非傳統的模型架構及訓練目標,如在以微軟 CodeFusion 為代表的 Diffusion 模型等
圍繞大語言模型為軟件開發全過程構建生態系統,打破當下大模型大都作為 IDE 插件的局限
對大模型生成代碼進行更好的監控與管理,規避相關風險 ?
-
編碼
+關注
關注
6文章
957瀏覽量
54951 -
語言模型
+關注
關注
0文章
538瀏覽量
10341 -
大模型
+關注
關注
2文章
2548瀏覽量
3169
原文標題:500篇論文!最全代碼大模型綜述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
圖神經網絡概述第三彈:來自IEEE Fellow的GNN綜述
史上最新最全最經典單片機課程設計論文資料
基于模型設計的HDL代碼自動生成技術綜述
啃論文俱樂部 | 壓縮算法團隊:我們是如何開展對壓縮算法的學習
NAS:一篇完整講述AutoML整個流程的綜述
人大發表迄今為止最大最全的大模型綜述






 工商網監
工商網監
評論