 論AI的系統廠商vs系統廠商的AI
論AI的系統廠商vs系統廠商的AI
01
前 言
10月初Dell在Austin的一個event “Bring AI to Your Data”宣傳上,科技媒體65請了Dell 的一個VP來討論,在討論中一向比較直接的Patrick就問了一個所有系統廠商的靈魂問題:“Dell 在AI的軟件和算法上沒有投入,在AI加速的芯片上也沒有投入,你們在談AI到底在談啥?”。好在是VP比較機靈,先談“Dell是個大公司,客戶多,很多客戶不知道AI是個啥,Dell可以提供H100的GPU服務器,然后就是AI肯定要存儲的,因為大數據要靠AI,數據的保護和管理,bablbabl.。.“。說實在的,如果AI的數據真的很重要的話。Samsung和Seagate應該是世界上市值最高的AI公司了。關心股市的同學知道,在這個宇宙中并不是。
俺是正統的系統廠商出身,畢業實習的時候在華騰(就是那個天騰和華東計算機所合資)做系統集成,很巧的是在俺公司現址的樓下,一天被當年帶的新畢業生認出來,當年的畢業生已經是華騰的CTO了,在華騰工作了24年,從系統集成公司進化成上萬人外包的大公司了。其實,在X86興起的200X年代,互聯網還在融資,系統集成公司的日子還是不錯的,企業客戶都面臨這個信息化這個話題,系統集成公司是軟硬一體的,可以像Dell今天滿足客戶AI需求一樣滿足客戶的信息化需求。
當互聯網興起之后,系統集成公司的日子基本上到頭了,互聯網只要硬件,人家有的是軟件工程師。后面,隨著SSD出現,高速網絡出現, intel手下的系統公司基本上被臺廠,后面被互聯網的系統部全部踢出局了。當然,俺早早的跳出這個領域,向下做到了SSD部件廠商,以至于前一段一個哥們問我服務器還是啥搞頭,俺可是在聯想,Dell做了快10年的服務器的人,居然真的想不出來服務器還能有啥花頭。
02
緣 起
回到正題, AI從2012年開始,基本上起起伏伏快10年了,在Nvidia面臨游戲和加密貨幣的下滑的雙重打擊下,GPTx異軍突起,讓老黃放飛了自我。就像前面講的一樣,AI的投資基本上在AI的網絡算法和AI加速器兩個方向。為啥這次LLM只是火了AI算法,但是一票AI加速器公司反而悄無聲息?原因也很簡單,就像在Meta做AI Infra的Dr. Kim Hazelwood講的一樣,在AI的框架世界中,高效的框架是打不過好用的框架的,因為對算法工程來講,2小時和12小時沒有區別,反正下班前提交了,只要明天上班的時候能出來就行。
因此,在AI框架的競爭中,Pytorch戰勝了TensorFlow【1】。
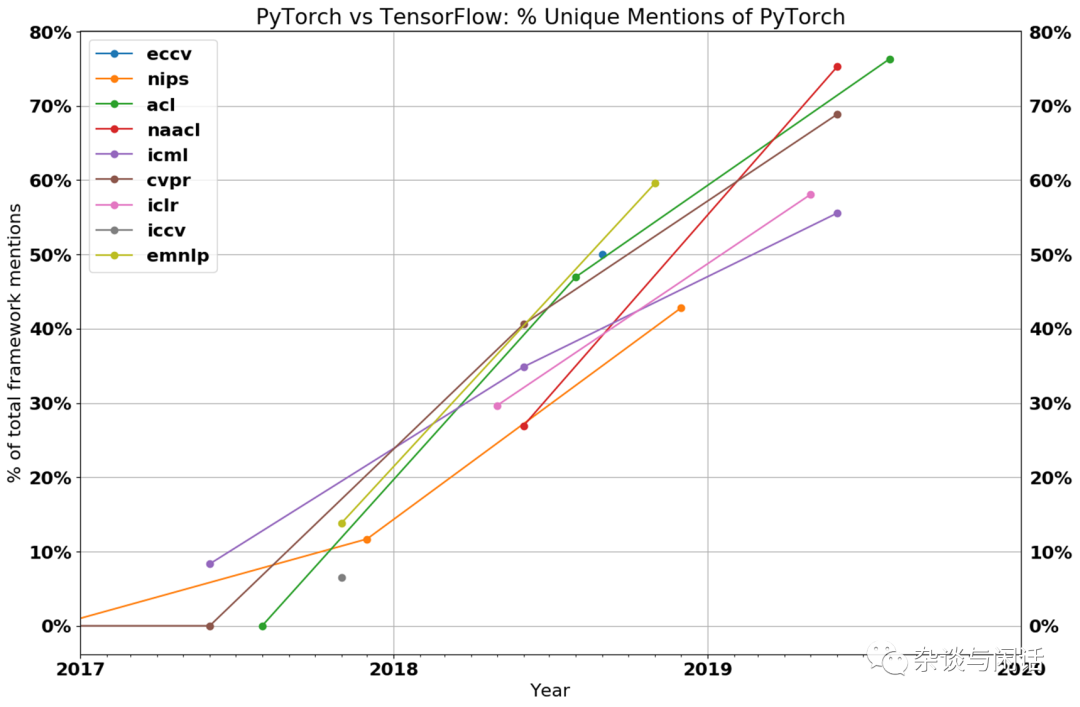
對了,Pytorch就是Meta的,前面的計算機科學家Kim的評論(2020)圓滿了。而Pytorch的特點就是好用,有2000+ 算子,這個對于AI加速器來講就是滅頂之災。之前那些學Google TPU做脈動整列的,做Tensor/Vector加速的startup基本上被強大的CUDA打趴下了。
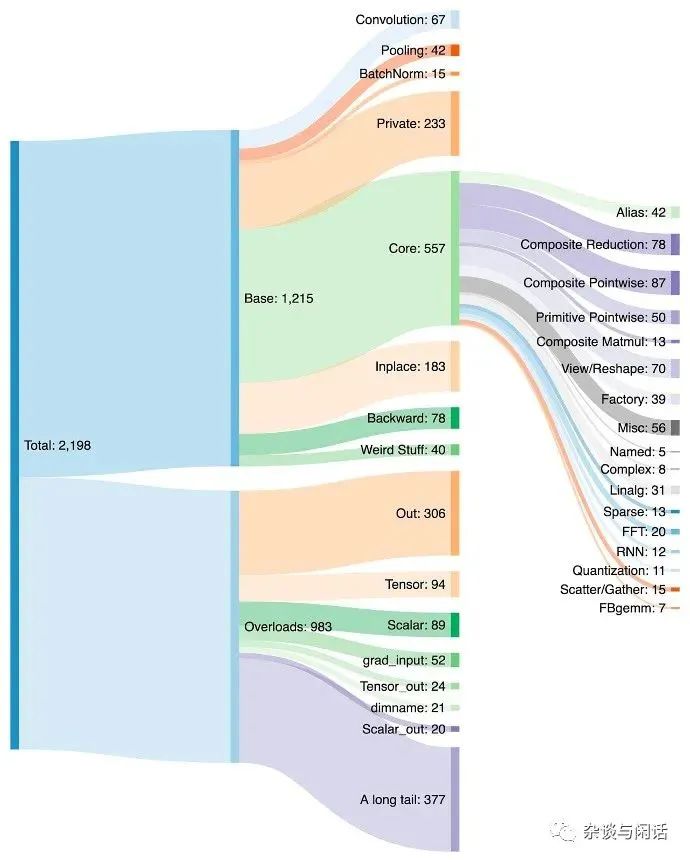
但是,如果是這樣的話,就沒有本文的標題了,在硅谷走老黃的路的公司基本都沒有了,只有中國還在和A股互動炒作GPU的概念,而真正可以對標老黃的公司都不是走GPU的路線。反而是兩家做可編程DataFlow的公司成為了熱點,而且都是AI的系統公司。
03
Sambanova
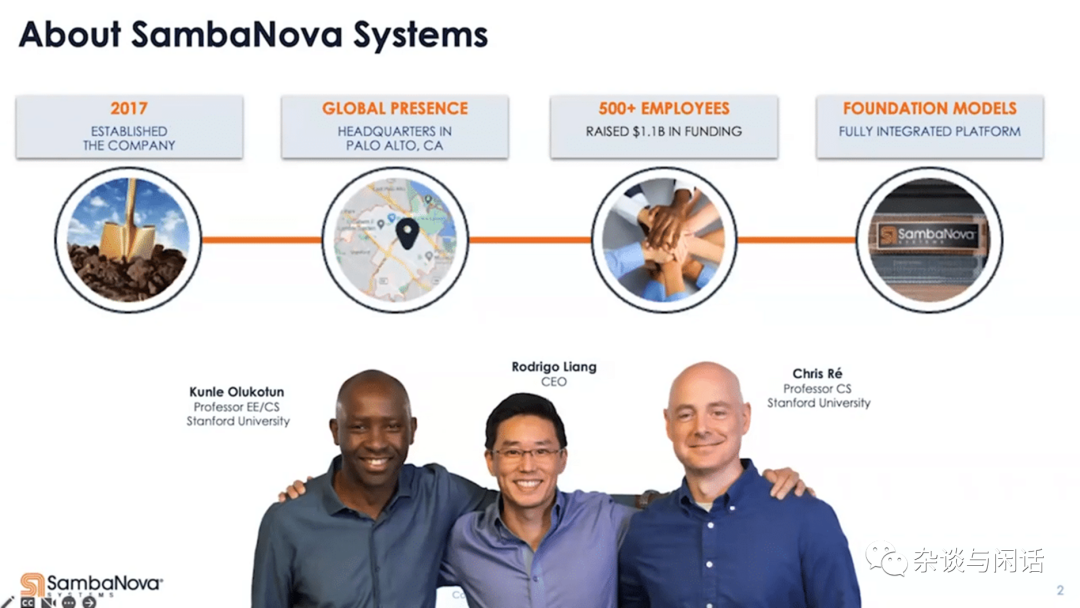
Kunle Olukotun的名號是“Father of The Mutil-Core Processor”,之前的公司是Afara Websystem,做最早的多核系統。

從這一頁,看不懂Niagara的同學可以勸退了。看懂的童鞋可以點贊了。這么老的古董,現在散落在不同的公司的Sun可以緬懷一分鐘。
另一個大佬是Chris,主要是做軟件的,公司被Apple收購。

做多核CPU和做大數據管理的在一起,故事很直接。ML Application就是Software 2.0呀。

2019年回來的芯片很大很大,比GPU還大,725mm2。4個DDR4 controller支持1.5T。64Lane PCIe Gen4.0 做單機8卡互聯。(不錯,我們是I/O控)。

這張圖說明了,2019年已經tapeout的片子,現在剛剛熱起來。編譯器的能力,特別是可編程的并行能力,需要時間呀。
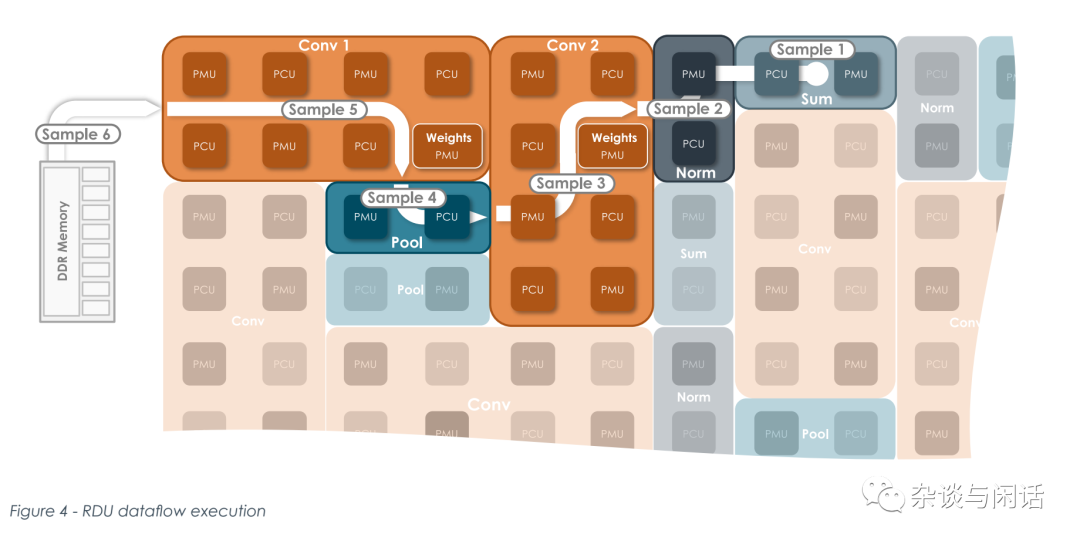
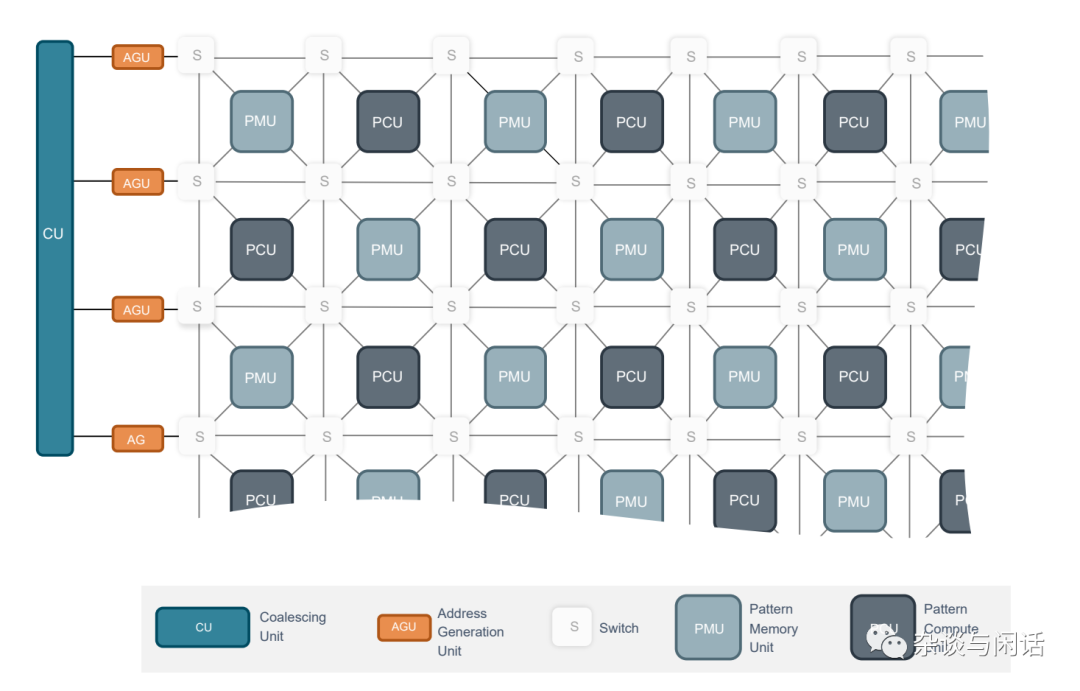
芯片上的主要部分,和大部分AI加速器類似,計算單元,SRAM做weight/gradient的保存, AGU和SU做數據路由,CU就是控制了。
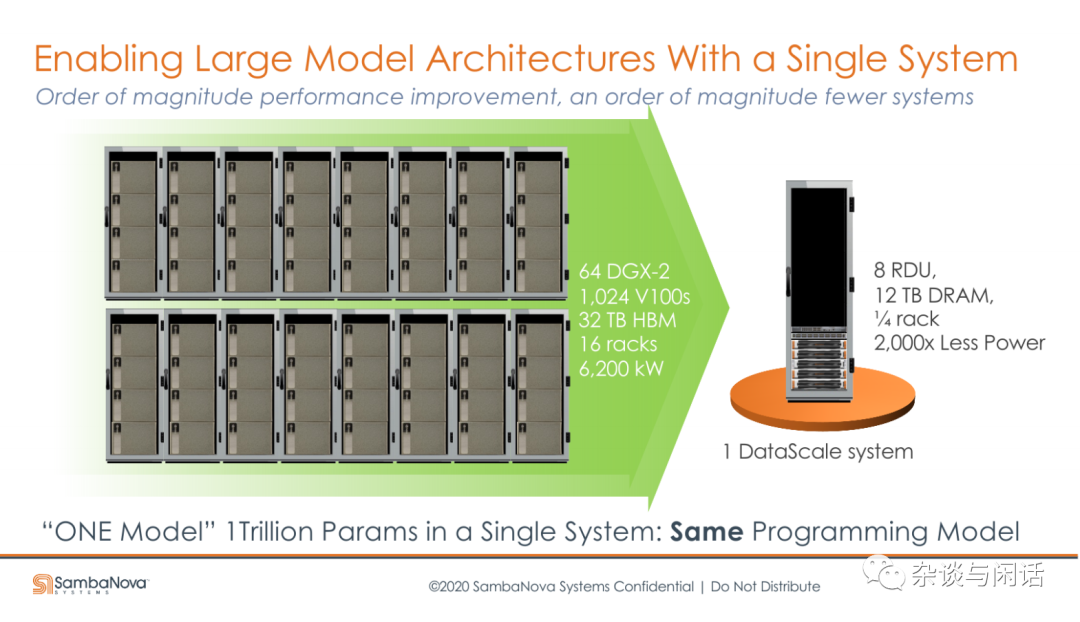
單機8卡,和老黃對標。

產品文檔很全面,有自己的編譯器和開發環境。硬件也是用AMD的PCIe的標準服務器帶8個加速器。其中的HCI就是自己互聯的方案,基于PCIe Gen4,從接口的形態看應該是4口一組的PCIe HBA類似。
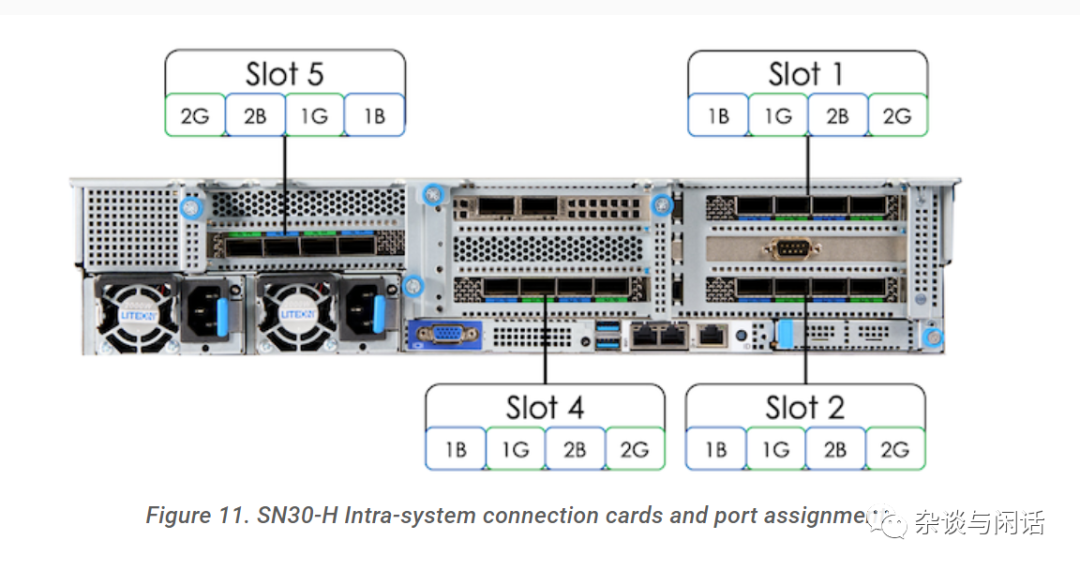

HCI組網方式基本上就是full mesh,4個計算節點互聯和頭節點互聯。 節點之間的連接還有用RoCEv2的Ethernet以及junper的交換機。只是HCI沒有用PCIe switch,看cable做pointer to pointer的互聯,可能和NVLinkv1一樣,沒有做NVSwitch。
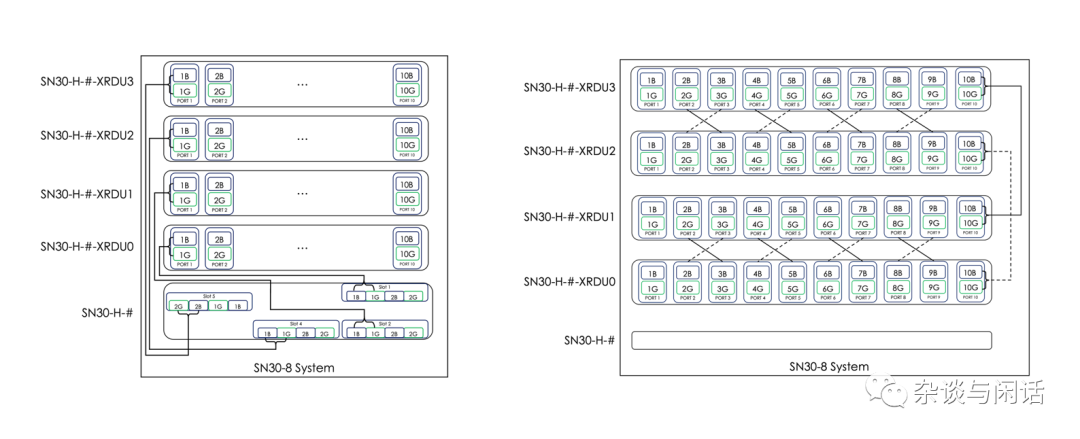
作為AI的系統廠商來講,Sambanova還是很不錯的,除了一些美國的國家實驗室以外,還有一些做金融和文本處理的公司。而且關鍵是2代的芯片也回來了,支持HBM, 支持5T的LLMs【2】。

04
Cerebras
說到這家,必須講它的出處 SeaMicro. 對,下圖就是8個server在一個5X11英寸的PCB上。它是ARM進軍數據中心的先烈,被AMD收購了,被Lisa SU殺死了。這種類型的板子,我當年在DCS的時候也搞過類似的低功耗MicroServer。

Cerebras的核心人物都是SeaMicro的背景。

關于Cerebas,正好之前有材料,這里就快速總結了。

通過RoCEv2的RDMA進行系統擴展。weight的存儲和計算節點通過ethernet互聯。
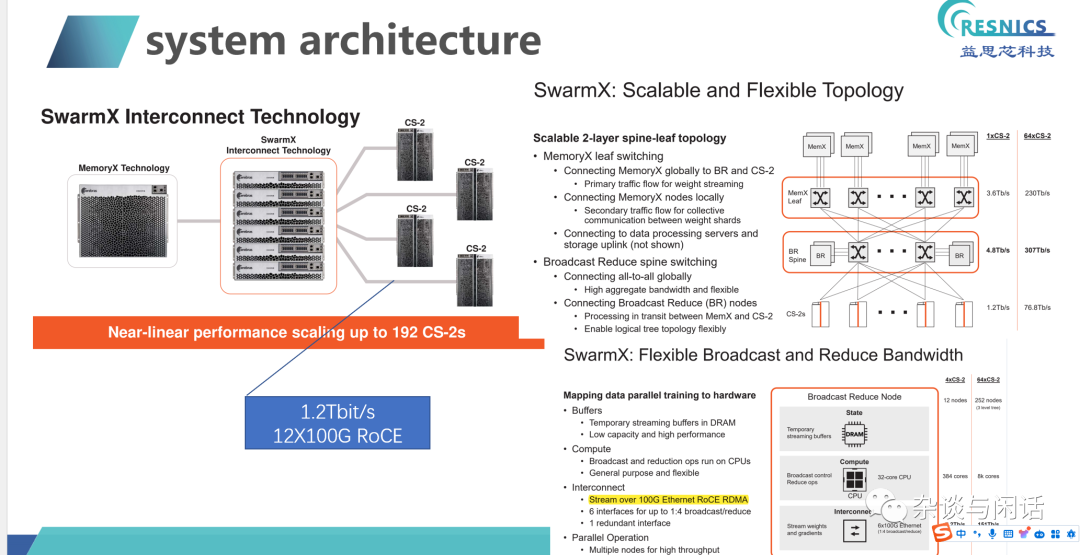
對于Weight節點獨立,很好地解決了GPU因為內存不夠出現的data 并行的問題,在大模型時代成了殺手锏。通過On-Chip Memory和MemoryX的流水線處理,很好地解決了之前GPU training中參數服務器的問題。

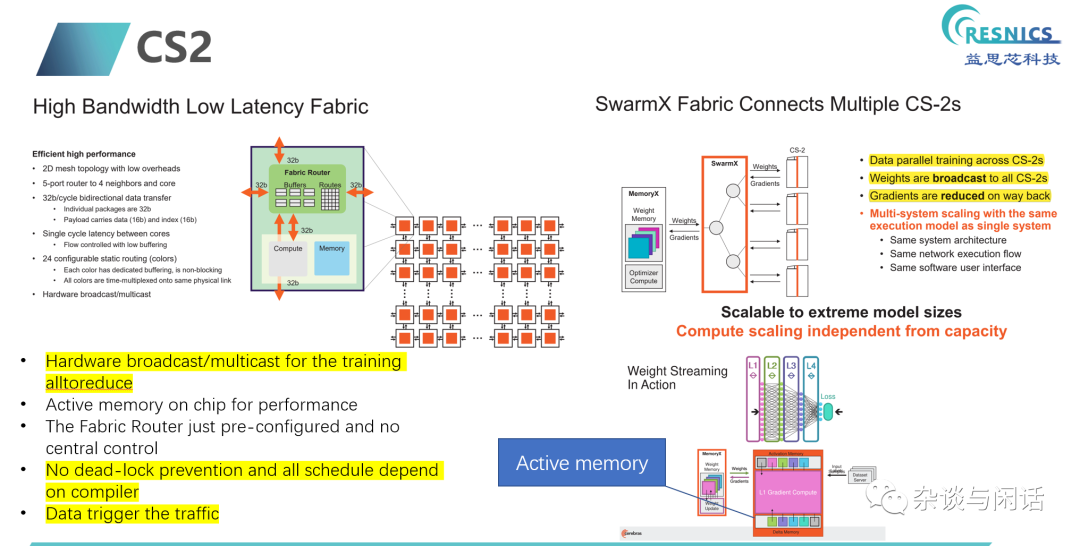
計算單元的設計還是軟硬結合,編譯器做調度編排,整個片子上網絡沒有中心的控制。
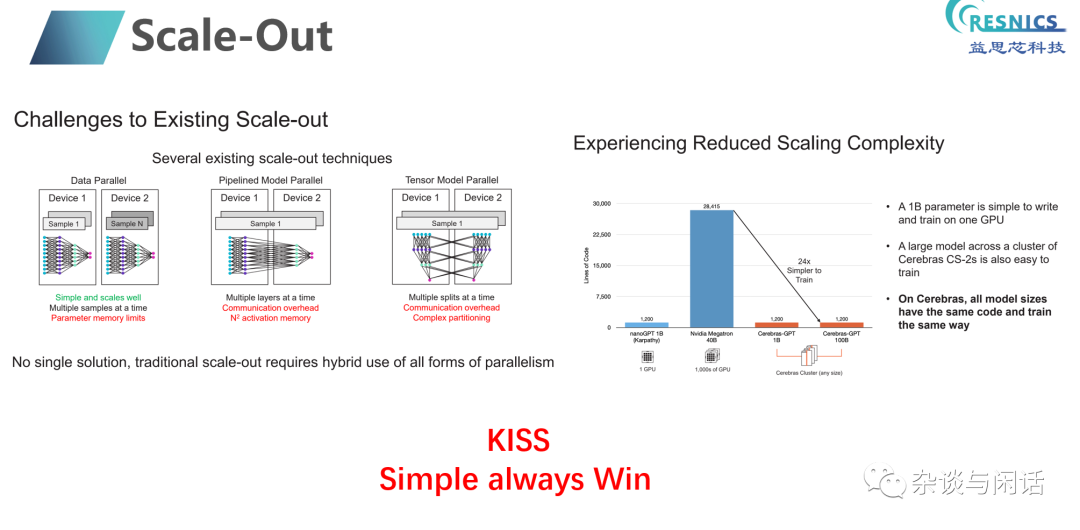
最后,在LLMs時代,Pytorch的勝利邏輯會繼續。
相對于Sambanova, 因為Cerebras的步子更大,不僅在國家實驗室有落地,更加在LLMs時代找到了方向。
05
尾 聲
在過去2016年AI的創業風潮起來之后,GPU的顛覆者到現在還沒有出現,的確讓人比較遺憾。后面的路會怎么走,我還是比較認可Andrej Karpathy的判斷, Transformers可能會走上模型的統一。
模型+數據+算力=ML Application, Chris指出的方向也許是AI創業公司盈利的方向???
回到正題,也許下一波就是AI公司成為AI系統廠商,或者系統廠商收購AI公司成為AI系統廠商的時代了。

-
互聯網
+關注
關注
54文章
11187瀏覽量
103875 -
AI
+關注
關注
87文章
31536瀏覽量
270353 -
pytorch
+關注
關注
2文章
808瀏覽量
13366
原文標題:論AI的系統廠商 vs.系統廠商的AI
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論