 數據流式編程在硬件設計中的應用
數據流式編程在硬件設計中的應用
01、數據流式編程的思想
數據流式編程思想簡介
數據流式編程(Dataflow Programming)是一種存在已久的程序設計范式,可以追溯到19世紀60年代,由MIT的Jack Dennis教授開創。
圖1 信號處理領域的數據流框圖
數據流的前身是信號流,如上圖1所示,在信號與系統相關的領域中,使用信號流框圖來表示模擬信號在一個系統中的處理過程。隨著計算機技術的發展,越來越多的模擬系統被數字系統所取代,連續的信號也變為了離散的數據。
軟件開發中的數據流式編程思想
在介紹硬件中的數據流式編程思想之前,先來看一下軟件中的數據流式編程,并了解數據流式編程中的幾個基本元素的概念。

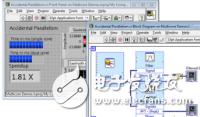
圖2 一段LabView編寫的流式數據處理軟件程序
在軟件開發領域,數據流式程序的開發已經得到了廣泛的應用。其中頗具代表性的是NI公司的LabView軟件以及Mathworks公司的Simulink。如上圖2所示,該圖為LabView可視化開發環境中,采用圖形化編程的方式編寫的一個簡易數據處理程序。觀察圖2,可以得到數據流式程序具有的一些要素:
- Node:數據處理節點,代表著實際的數據處理步驟(如上圖中骰子節點、節拍器節點、4輸入加法器節點、除法節點等)
- Port:分為In和Out兩種類型,一個Node可以具有多個In和Out端口(如除法器就是2輸入1輸出)
- Source:數據源,待處理輸入通過數據源進入到程序中(例如上述的骰子節點,會生成隨機數輸出,即為一個可以輸出動態數據的Source,而圖中藍色的500、綠色的布爾節點則可以視為產生靜態常量的Source)。
- Sink:數據出口,經過處理的數據經過出口輸出(例如上述節拍器節點、右下角的紅色停止條件節點,它們都只有輸入沒有輸出,即接收最終數據結果)。
- Edge:連接Port與Port的邊,代表數據流通的管道
同樣,通過觀察圖2,還可以發現流式程序的執行一些特點:
- 當一個Node的In端口滿足觸發條件(例如任意輸入端口有數據,或所有端口都有數據),并且其Out端口不阻塞時(下游Node可以可以接收數據),該Node開始執行自己的處理邏輯,并將輸出數據投遞到對應的輸出端口。
- 反壓的思想貫穿了整個程序的執行流程,當下游節點無法處理新數據時,上游節點的處理過程將被阻塞。
- 并發性:每個Node獨立處理自己的邏輯,Node之間是并發的
- 層次性:可以將多個Node組成的子系統看做一個黑箱,子系統的Sink和Source作為該黑箱的Port,這樣就可以把子系統看做上層系統的一個Node,從而形成層級結構。
圖3 帶有循環、條件分支結構的數據流式程序
近些年以來,為了實現敏捷化開發而逐步流行的圖形化拖拽編程、低代碼編程等敏捷開發方式中,通常都可以看到數據流式編程的影子。與DSP領域中的簡單數據流思想不同,在軟件開發領域的數據流程序中,通常可以看到條件分支結構和循環執行結構。因此,數據流的編程模式是圖靈完備的,不僅可以用于表示簡單的數據計算流程,還可以表達復雜的控制流。
如上圖3所示即為一款兒童編程軟件的示意圖,讀者可以嘗試在上面的圖中找出Source、Sink、Node、Port、Edge這些概念。
軟件數據流 vs 硬件數據流
軟件實現:
數據流系統都需要一套調度框架,所有節點之間的并行執行都是軟件虛擬出來的,節點是否可以激活的判斷需要框架進行額外的計算,因此性能開銷不能忽略。
硬件實現:
硬件天然具有并發的特性。端口、連線、層級結構、反壓、并發執行這些概念與硬件設計有著完美的對應關系。事實上,Verilog、VHDL等語言本身也可以被算作是和LabView、Simulink一樣的數據流式程序的開發語言[1]。
數據流思想與狀態機思想的對比
在很多場景下,如果使用狀態機的思想對硬件行為進行建模,則需要考慮很多狀態之間的轉換關系,容易造成狀態爆炸。而是用數據流的編程思想,只需要考慮數據在兩個節點之間的傳輸關系以及各個節點自己要做的事情,每個節點各司其職,可以有效降低程序的復雜度。
下面以AXI4協議的寫通道握手為例,寫地址通道和寫數據通道之間沒有明確的先后依賴順序。
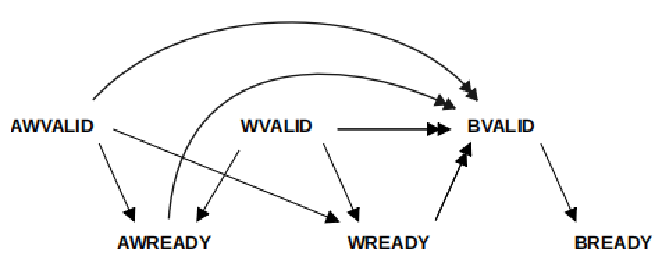
圖4 AXI握手協議的順序關系
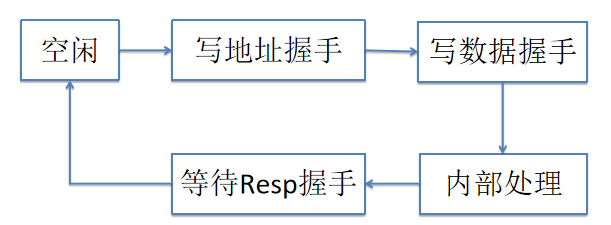
圖5 一個最簡單的狀態機握手模型,忽略了其他狀態
如果以狀態機的思路來實現,是上述圖5這樣的,它是一種順序化執行的思維模式,依次進行各個通道上的握手,難以描述并行發生的事件。如果強行使用狀態機來描述并發場景下各種可能的先后順序,則容易導致狀態爆炸,維護成本高,不夠敏捷。
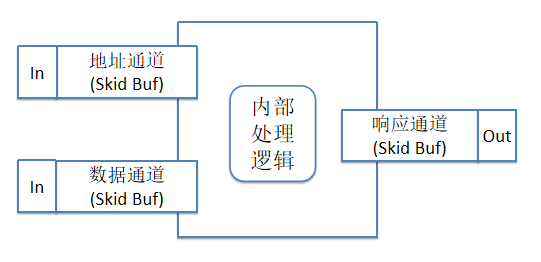
圖6 基于數據流思想的握手模型
如果以數據流的思想來實現,則如上述圖6所示,4個環節之間各自獨立運行,各司其職,兩個輸入通道以及一個輸出通道是獨立模塊,各自可以并行的完成自己的握手,模塊與模塊之間通過Skid Buf(FIFO)進行解耦。可以靈活應對各種握手信號到達的先后順序,可以寫出易于維護且吞吐量高的代碼。
02、Bluespec語言及其流式編程框架PAClib
Bluespec SystemVerilog(BSV)和PAClib簡介
Bluespec SystemVerilog是一種高級的函數式硬件描述語言,由MIT的Arvind教授開發,最初以商業授權形式發布,并于2020年正式開源。
該語言將硬件行為抽象成多個可以并發運行的Rule,Rule由觸發邏輯來控制其運行時機,Rule之間、Module之間可以通過FIFO進行通信建模,編譯器會自動生成Module之間的握手和反壓信號(即Rule的觸發邏輯),從而降低了描述復雜并行系統的難度,使得它非常適合使用數據流的思想進行開發。
PAClib是Pipelined Architecture Composers library的縮寫,是BSV提供的一個官方庫,可以方便的開發出基于數據流思想設計的硬件邏輯。
與DSP領域的流式處理相比,PAClib提供了諸如If-Else-Then、While Loop、For Loop、Fork、Join等操作,因此PAClib所提供的數據流式編程框架是圖靈完備的,不僅可以用于對復雜數據流邏輯的描述,也可以用于對復雜控制流的描述。
PAClib中的基礎開發組件
PACLib中的基礎組件可以看做是流式編程中的各個節點,為了使用流式編程,需要首先了解各個節點的功能,然后才能將這些節點連接起來,從而形成完整的程序。下面首先介紹這些節點的通用形式,即PAClib中定義的PipeOut接口以及Pipe類型,其定義如下:
interface PipeOut #(type a);
method a first ();
method Action deq ();
method Bool notEmpty ();
endinterface
typedef (function Module #(PipeOut #(b)) mkPipeComponent (PipeOut #(a) ifc))
Pipe#(type a, type b);
上述PipeOut接口的形式類似于一個FIFO,即為一條數據通道的出口端。Pipe類型本質是一個函數,用來把一個PipeOut類型的輸入轉換為另一個PipeOut類型的輸出模塊,因此Pipe類型表示了一個連接并轉換的概念。

圖7 Pipe類型的圖形化示意
上述圖7可以幫助大家更形象的理解Pipe類型和PipeOut接口,其中整個節點可以看做是一個Pipe,數據從左側流入,從右側流出,并在流經節點的過程中被處理(處理的過程在下文介紹)。其中右側突出的部分是用于和下一個節點(也就是下一段Pipe)連接的接口,即PipeOut。Pipe和PipeOut類型提供了數據流程序中各個節點的統一接口規范,所有基于PAClib開發的處理邏輯都要用這兩個概念進行包裝,從而使得各個節點之間具有一定的互換性,為架構提供了很強的靈活性。
將函數包裝為Pipe
Pipe類型只是定義了數據流經過一個節點前后的數據類型,因此還需要具體的邏輯來實現從類型A到類型B的轉換。由于函數的本質就是做映射,因此使用函數來表達對數據的加工過程再合適不過了。mkFn_to_Pipe_buffered是一個工具函數,提供了將一個函數封裝為一個Pipe的能力,其定義如下:
function Pipe #(ta, tb) mkFn_to_Pipe_buffered (Bool paramPre,
tb fn (ta x),
Bool paramPost);
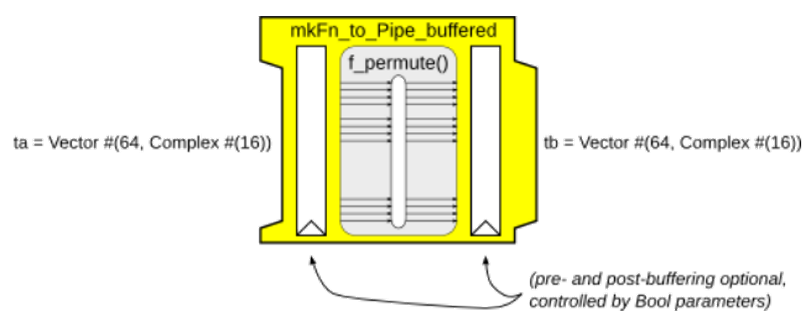
圖8 mkFn_to_Pipe_buffered工具函數所生成的Pipe節點示意圖
這里的用法也體現出了BSV函數式編程語言的特性,函數是語言中的一等公民。事實上,PAClib中對數據流模式中各個節點之間的“連線”也是通過高階函數的嵌套來實現的。
兩個Bool類型的參數可以選擇是否在函數的前后加入FIFO隊列進行緩沖。如果前后兩個FIFO都不開啟,則該節點表現出組合邏輯的性質。開啟FIFO后,則表現出了流水線的性質。通過FIFO實現前后級節點之間的反壓邏輯,自動適應不同的數據流速。
Map操作
map是函數式編程中必不可少的一個功能,PAClib中也提供了不同形式的map功能:
mkMap用于將Vector中的每一個元素并行地進行處理。mkMap_indexed則在mkMap的基礎之上,額外提供了元素對應的索引信息,從而使得用于map的函數可以獲得關于被處理數據的位置信息。這兩個函數的定義如下:
function Pipe #(Vector #(n, a),
Vector #(n, b))
mkMap (Pipe #(a, b) mkP);
function Pipe #(Vector #(n, a),
Vector #(n, b))
mkMap_indexed (Pipe #(Tuple2 #(a, UInt #(logn)), b) mkP);
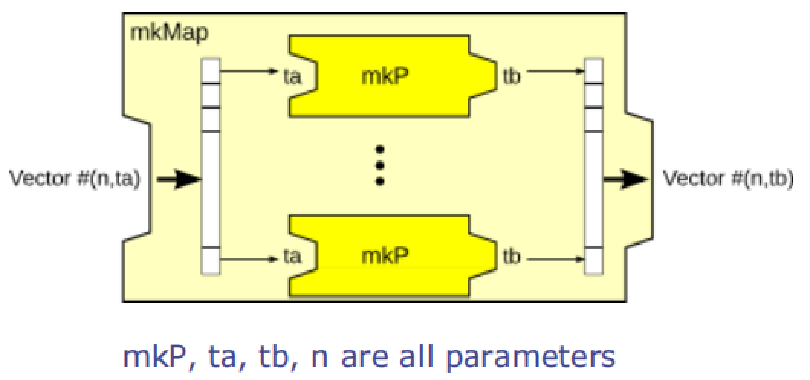
圖9 mkMap節點的圖形化示意
如上圖9所示,展示了mkMap節點的示意圖,可以看到圖中用深淺兩種顏色表示了嵌套的Pipe類型,圖中不同Pipe類型的嵌套表示了Node之間的層級關系,本質上是通過高階函數實現了簡單邏輯的組合。
由于BSV靜態展開的原因,如果Vector長度較大,則會產生出很多個mkP的實例(mkP實例的數量與輸入向量的長度相同),占用大量面積。為了減少面積占同,用時間換空間,則可以使用接下來要介紹的節點。
分批Map操作
PAClib中提供了mkMap_with_funnel_indexed函數來創建支持分批Map操作的處理節點,從而可以在面積和吞吐率之間進行取舍,其定定義如下:
function Pipe #(Vector #(nm, a),
Vector #(nm, b))
mkMap_with_funnel_indexed (UInt #(m) dummy_m,
Pipe #(Tuple2 #(a, UInt #(lognm)), b) mkP,
Bool param_buf_unfunnel)
provisos (...);
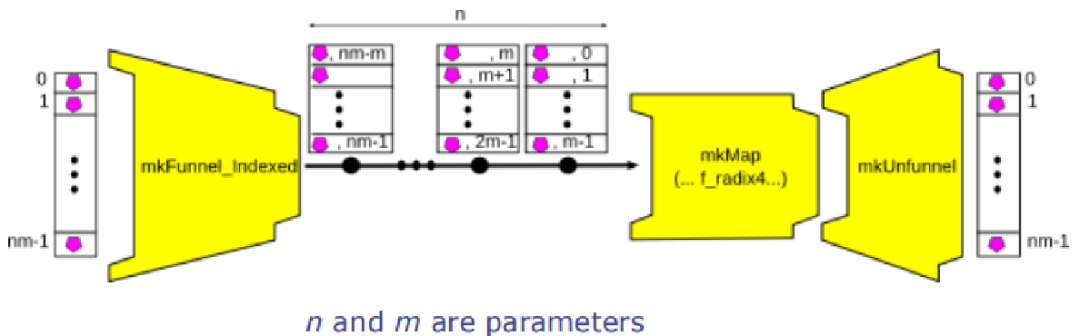
圖10 mkMap_with_funnel_indexed工具函數所創建的處理流程
mkMap_with_funnel_indexed函數實際上是一個工具函數,該工具函數幫助用戶創建了3個Pipe的組合,其中mkMap節點已經介紹過了,另外兩個節點分別是mkFunnel_Indexed和mkUnfunnel,其定義如下:
function Pipe #(Vector #(nm, a),
Vector #(m, Tuple2 #(a, UInt #(lognm))))
mkFunnel_Indexed
provisos (...);
function Pipe #(Vector #(m, a),
Vector #(nm, a))
mkUnfunnel (Bool state_if_k_is_1)
provisos (...);
上述兩個節點的作用,第一個是將一個較長的向量輸入以指定的長度進行切分,從而產生多個批次的輸出。而第二個是接收多個批次較短的輸入,然后產生一個較長的輸出,即把之前切分的批次重新拼接回來。mkMap_with_funnel_indexed函數通過上述3個節點的組合,其實現的最終功能為:
- 指定一個參數m,輸入的Vector會被自動切分為多段,每段的長度為m,然后以m長度的切片為單位進行map操作。
- 在實際設計中,只需要調整參數m的值就可以很方便的在面積和吞吐率之間進行平衡。串并轉換功能由框架自動完成,開發者只需要把精力放在核心的mkP 節點即可。
節點的串聯
上述的mkMap_with_funnel_indexed函數將3個特定的節點進行了串聯,從而實現了更加復雜的邏輯。將簡單節點進行串聯是流式編程中必不可少的操作,為了將任意節點進行串聯,可以使用mkCompose和mkLinearPipe這兩個函數實現,其定義如下:
function Pipe #(a, c) mkCompose (Pipe #(a, b) mkP,
Pipe #(b, c) mkQ);
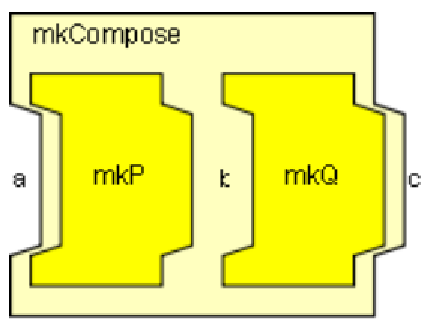
圖11 mkCompose節點示意圖
function Pipe #(a, a)
mkLinearPipe_S (Integer n,
function Pipe #(a,a) mkStage (UInt #(logn) j));
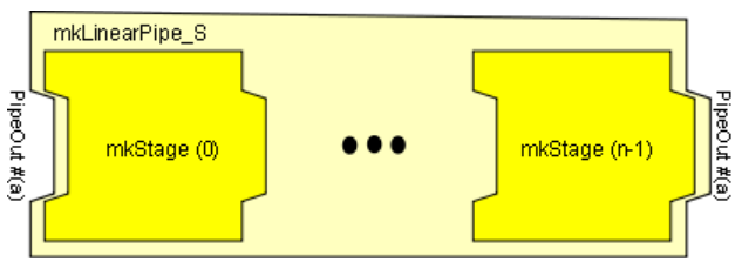
圖12 mkLinearPipe節點示意圖
可以看到,mkCompose的作用是將兩個不同的Pipe進行串接,多個mkCompose嵌套使用則可以實現多級的串接。而mkLinearPipe_S是將同一個函數進行多次調用,但每次調用時會傳入不同的參數,從而使得這個函數可以在不同的調用位置上表現出不同的行為。
Fork和Join操作
上述介紹的節點都是對數據進行線性操作的節點,如果只有這樣的節點是無法實現圖靈完備的數據流式程序的,接下來介紹的幾個非線性操作節點可以使得程序變得圖靈完備。下面從mkFork和mkJoin兩個函數開始介紹:
module mkFork #(function Tuple2 #(b, c) fork_fn (a va),
PipeOut #(a) poa)
(Tuple2 #(PipeOut #(b), PipeOut #(c)));
module mkJoin #(function c join_fn (a va, b vb),
PipeOut #(a) poa,
PipeOut #(b) pob )
(PipeOut #(c));

圖13 mkFork與mkJoin節點的示意圖
mkFork和mkJoin可以創建簡單的并行結構,通過用戶自己提供的函數fork_fn和join_fn,由用戶決定如何將一個輸入數據流拆分成2個輸出數據流,以及如何把兩個輸入數據流合并為一個輸出數據流。
對于Join操作而言,要求兩個輸入端口上均存在數據時,該Node才可以執行操作,如果兩條路徑上處理數據所需的時鐘周期數不一致,則Join節點會進行等待,直到兩個輸入都有數據為止。此外,PAClib中還提供了多種Fork節點的變種實現,可以自行了解。
條件分支操作
使用mkIfThenElse可以創建條件分支,其定義及示意圖如下:
module [Module] mkIfThenElse #(Integer latency,
Pipe #(a,b) pipeT,
Pipe #(a,b) pipeF,
PipeOut #(Tuple2 #(a, Bool)) poa)
(PipeOut #(b));
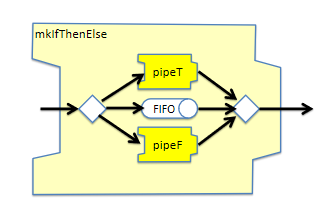
圖14 mkIfThenElse節點示意圖
mkIfThenElse可以實現分支邏輯。輸入數據是一個Tuple2#(a, Bool)類型,該節點會根據Bool類型的取值將數據包路由到pipeT或者pipeF子節點。其內部具有一個FIFO結構用于存儲Token,從而實現在pipeT和pipeF兩個節點所需處理周期不一致時起到保序的作用。
此外,PAClib中還提供了mkIfThenElse_unordered變種實現,當對輸入和輸出之間的數據沒有嚴格的順序要求時,可以使用這個變種來簡化設計。For循環 使用mkForLoop可以創建條件分支,其定義及示意圖如下:
module [Module] mkForLoop #(Integer n_iters,
Pipe #(Tuple2 #(a, UInt #(wj)),
Tuple2 #(a, UInt #(wj))) mkLoopBody,
Pipe #(a,b) mkFinal,
PipeOut #(a) po_in)
(PipeOut #(b))
provisos (Bits #(a, sa));
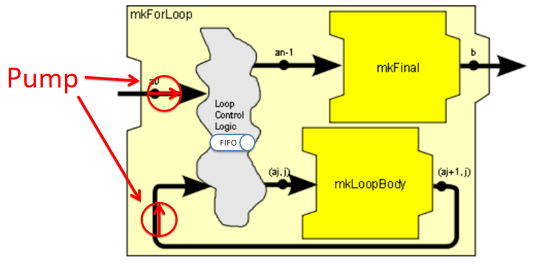
圖15 mkForLoop節點示意圖
mkForLoop需要通過n_iters參數傳入循環次數。在實現邏輯上,Loop Control Logic內部有一個共享隊列,外部進入的新數據和經過循環體執行過一次處理的數據,都會被放到這個隊列中。
每個新進入的數據都會被打上一個Tag,Tag的值為循環次數,這個Tag伴隨著數據在循環中流動,每流動一次,Tag減一,Loop Control Logic在從共享隊列中取出數據時,會根據Tag的計數值決定將其送入mkLoopBody節點還是mkFinal節點。內部有兩條Rule,分別獨立負責把新數據和正在循環的數據放入FIFO中,為循環提供了內在動力(圖中Pump標注路徑)。
注意,由于mkLoopBody也可能是一個需要多拍才能完成的節點,因此可以有多個數據包同時在流水線中進行循環。
While循環
在理解了For循環的實現原理之后,理解While循環的實現就沒有太大困難了。其定義和示意圖如下:
module [Module] mkWhileLoop #(Pipe #(a,Tuple2 #(b, Bool)) mkPreTest,
Pipe #(b,a) mkPostTest,
Pipe #(b,c) mkFinal,
PipeOut #(a) po_in)
(PipeOut #(c))
provisos (Bits #(a, sa));
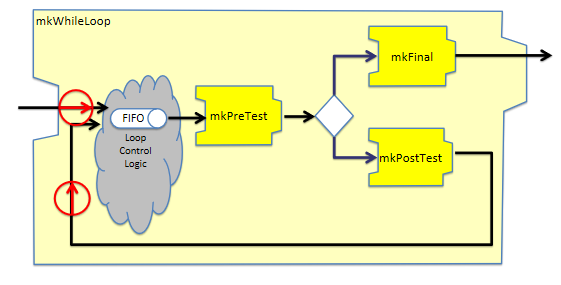
圖16 mkWhileLoop節點示意圖
while循環的實現需要用戶提供3個處理節點:
mkPreTest子節點用于執行循環終止條件的判斷mkPostTest子節點是循環體要做的處理邏輯mkFinal子節點是循環體退出前對數據再進行一次修改的機會 其實現邏輯與For循環類似,都是通過內部共享一個隊列來實現的,同時通過兩條Rule來為循環提供動力。
03、IFFT應用實例
需求背景
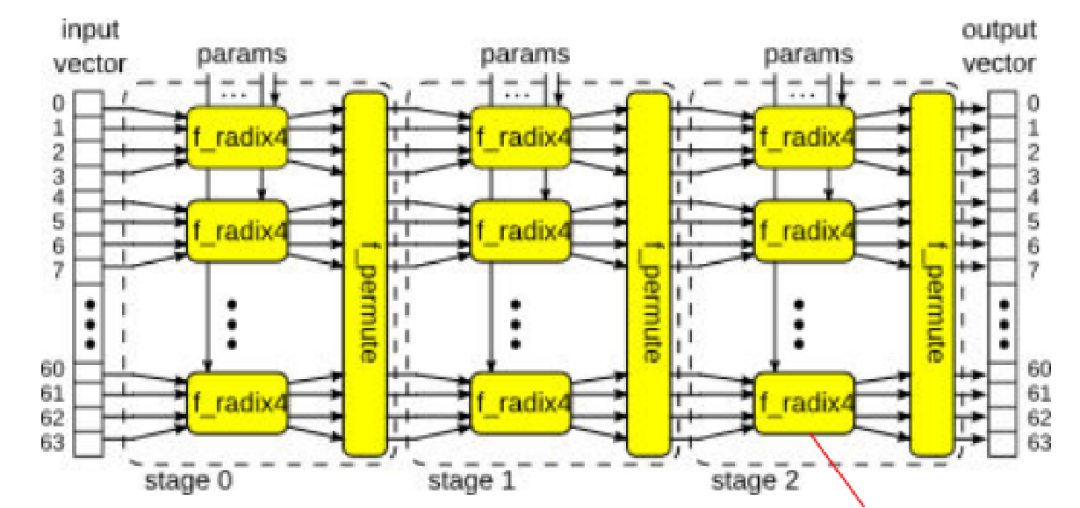
圖17 一個IFFT數據處理流程
以上述圖17中的IFFT變換為例,該流程中有很多平鋪重復的結構,對于不同的應用場景,需要在面積、吞吐量之間進行平衡,例如:
- 組合邏輯實現?還是流水線實現?
- 幾個不同的stage之間是否可以fold以減少面積?
- 每個stage內部的f_radix4實例是否可以減少?
代碼實現
使用PAClib提供的數據流式開發框架,只需要調整少量參數就可以快速調整系統的計算結構。下面先給出整體代碼,再對其中的各個部分進行解析,可以看到,整體框架的代碼量小于40行(僅包含用于調度數據流的框架代碼,不包含具體的運算邏輯以及注釋):
module [Module] mkIFFT (Server#(IFFTData, IFFTData));
Bool param_linear_not_looped = False;
Integer jmax = 2;
FIFO#(IFFTData) tf < - mkFIFO;
function Tuple2#(IFFTData, UInt#(6)) stage_d(Tuple2#(IFFTData, UInt#(6)) a);
return a;
endfunction
let mkStage_D = mkFn_to_Pipe (stage_d);
let s < - mkPipe_to_Server
( param_linear_not_looped
? mkLinearPipe_S (3, mkStage_S)
: mkForLoop (jmax, mkStage_D, mkFn_to_Pipe (id)));
return s;
endmodule
function Pipe #(IFFTData, IFFTData) mkStage_S (UInt#(2) stagenum);
UInt#(1) param_dummy_m = ?;
Bool param_buf_permuter_output = True;
Bool param_buf_unfunnel = True;
function f_radix4(UInt#(2) stagenum,
Tuple2#(Vector#(4, ComplexSample), UInt#(4)) element);
return tpl_1(element);
endfunction
// ---- Group 64-vector into 16-vector of 4-vectors
let grouper = mkFn_to_Pipe (group);
// ---- Map f_radix4 over the 16-vec
let mapper = mkMap_fn_with_funnel_indexed ( param_dummy_m,
f_radix4 (stagenum),
param_buf_unfunnel);
// ---- Ungroup 16-vector of 4-vectors into a 64-vector
let ungrouper = mkFn_to_Pipe (ungroup);
// ---- Permute it
let permuter = mkFn_to_Pipe_Buffered (False, f_permute,
param_buf_permuter_output);
return mkCompose (grouper,
mkCompose (mapper,
mkCompose (ungrouper, permuter)));
endfunction
下面來依次解析代碼,首先下面看這一段:
let s < - mkPipe_to_Server
( param_linear_not_looped
? mkLinearPipe_S (3, mkStage_S)
: mkForLoop (jmax, mkStage_D, mkFn_to_Pipe (id)));
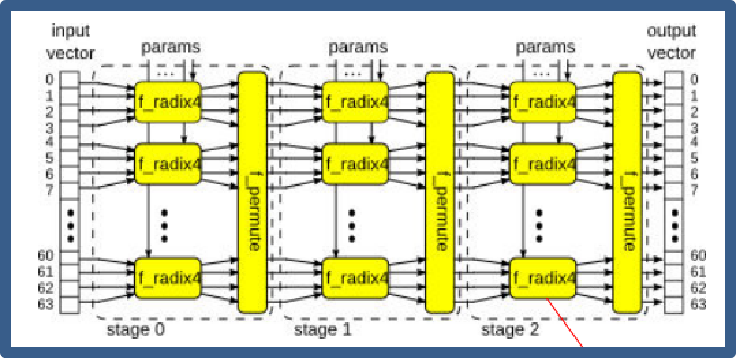
圖18 平鋪結構的IFFT計算架構
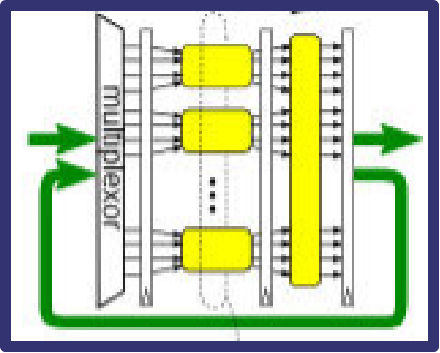
圖19 折疊結構的IFFT計算架構
如上圖18和19所示,只需要修改代碼中的param_linear_not_looped變量,即可以在兩種截然不同的計算架構之間進行切換。通過選擇mkLinerPipe_S或者mkForLoop來選擇stage之間是流水線平鋪的方式來實現,還是通過Fold的方式來實現。
let mapper = mkMap_fn_with_funnel_indexed ( param_dummy_m,
f_radix4 (stagenum),
param_buf_unfunnel);
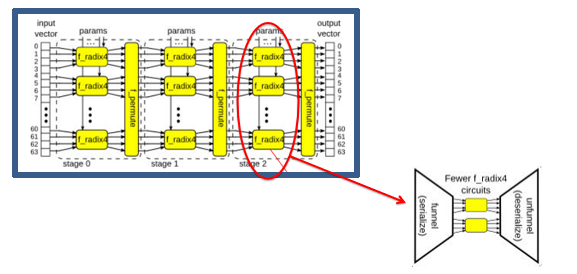
圖20 通過參數調整計算的并發度
如上述代碼片段和圖20所示,通過mkMap_fn_with_funnel_indexed函數的第一個參數來決定實例化多少個f_radix4計算單元,從而改變計算的并行度。
let permuter = mkFn_to_Pipe_Buffered (False, f_permute,
param_buf_permuter_output);
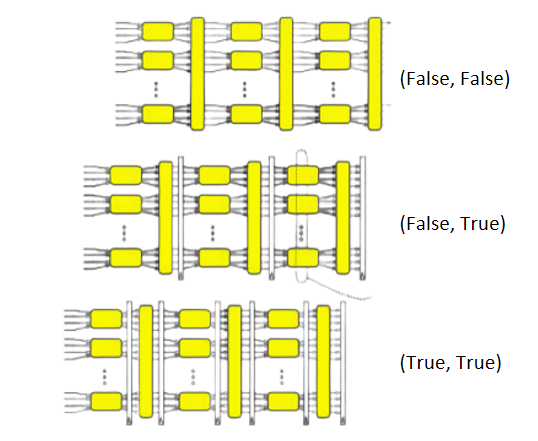
圖21 在不同位置插入流水線寄存器
如上述代碼片段和圖21所示,通過mkFn_to_Pipe_Buffered函數的兩個輸入參數來控制是否加入FIFO,從而實現在流水線或組合邏輯之間的切換,使得程序可以在時序上做出簡單的調整。
return mkCompose (grouper,
mkCompose (mapper,
mkCompose (ungrouper, permuter)));
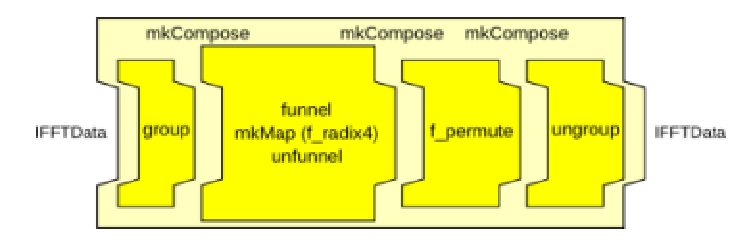
圖22 節點的串聯
如上述代碼片段和圖22所示,通過mkCompose可以實現多個Node之間的順序連接。
最終效果
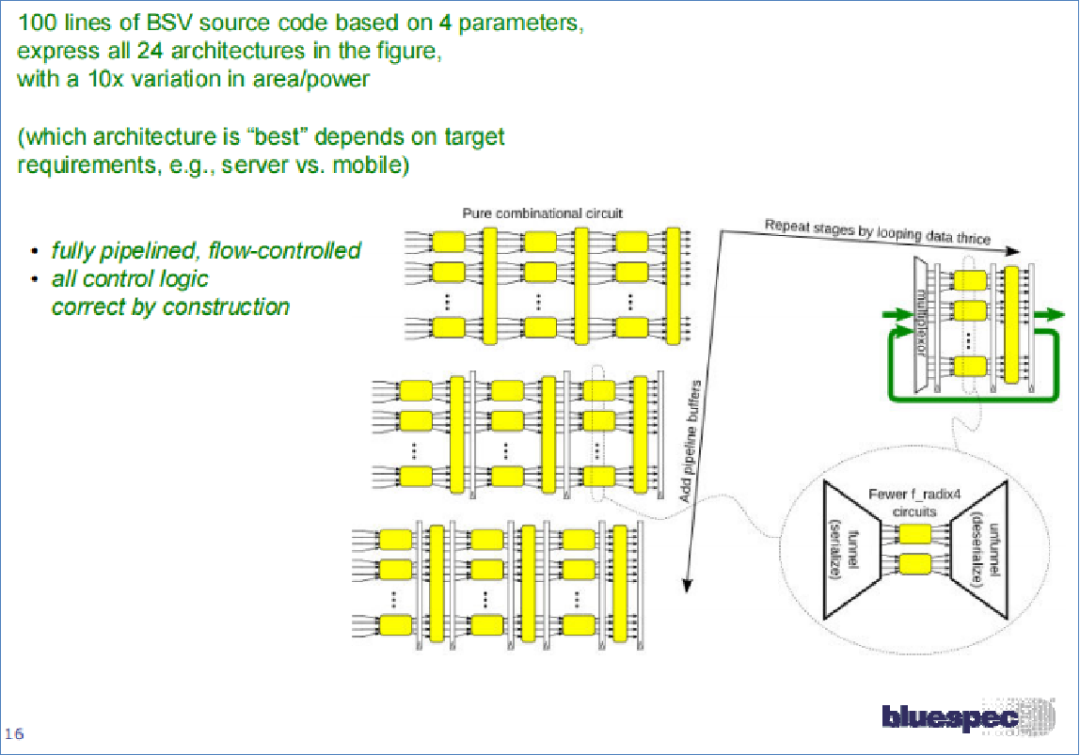
圖23 使用PAClib實現的各種IFFT計算架構
在最終效果部分,直接引用Bluespec原始介紹PPT[2]中的一個頁面來進行說明,使用不超過100行代碼,僅需要調整4個參數,即可實現在24種不同的計算架構之間進行切換,這24中計算架構在面積和功耗上的差異可以達到10倍以上,用戶可以根據自己的使用場景靈活的選擇實現方案。
04、寫在最后
從上述示例可以看到數據流式的編程思想可以為硬件設計引入極大的靈活性和可維護性。同時,由于分支節點、條件節點、循環節點的存在,這種數據流式的編程模式是圖靈完備的,因此數據流的開發思想可以用于簡化復雜的控制通路設計。
-
DSP技術
+關注
關注
2文章
58瀏覽量
28123 -
LabVIEW
+關注
關注
1977文章
3657瀏覽量
325654 -
接收機
+關注
關注
8文章
1184瀏覽量
53637 -
VHDL語言
+關注
關注
1文章
113瀏覽量
18090 -
狀態機
+關注
關注
2文章
492瀏覽量
27649
發布評論請先 登錄
相關推薦
LabVIEW中的數據流編程基礎
怎么將數據流式傳輸到E4438C
怎么通過USB將SPI數據流式傳輸到PC
通過Virtex5 FPGA上的SATA連接將數據流式傳輸到HDD或SSD的可行性
LabVIEW用NI-DAQmx高速數據流盤
多數據流采集處理中的軟硬件接口設計
數據流編程以及LabVIEW多核編程
基于大數據的流式計算
數據流編程模型優化
基于實時車牌識別數據流的套牌車流式并行檢測方法
數據流是什么
使用Edison、Pi等將傳感器數據流式傳輸到Octoblu

流式圖計算TuGraph-Analytics技術背后的故事和技術特性





 工商網監
工商網監
評論