") 詳解PCIe和NVLink兩種互聯(lián)技術
詳解PCIe和NVLink兩種互聯(lián)技術
計算機網(wǎng)絡通信中兩個重要的衡量指標是帶寬和延遲,AI 網(wǎng)絡也是如此。在向百億級及以上規(guī)模的發(fā)展過程中,影響AI計算集群性能的關鍵并不只在于單個芯片的處理速度,每個芯片之間的通信速度也尤為重要。
目前GPU卡間互聯(lián)的主要協(xié)議是PCIe和NVlink,服務器間互聯(lián)則是RDMA和以太網(wǎng)。之前我們有談過IB和RoCE(IB和RoCE,誰更適合AI數(shù)據(jù)中心網(wǎng)絡?),本文將主要介紹PCIe和NVLink兩種互聯(lián)技術。
01PCIe :高帶寬擴展總線
總線是服務器主板上不同硬件互相進行數(shù)據(jù)通信的管道,可以簡單理解為生活中的各種交通道路。總線對硬件間數(shù)據(jù)傳輸速度起著決定性的作用,目前最流行的總線協(xié)議為PCIe(PCI-Express),最早由Intel于2001年提出。
PCle主要用于連接CPU與各類高速外圍設備,如GPU、SSD、網(wǎng)卡、顯卡等。與傳統(tǒng)的PCI總線相比,PCIe采用點對點連接方式,具有更高的性能和可擴展性。伴隨著AI、自動駕駛、AR/VR等應用快速發(fā)展,計算要求愈來愈高,處理器I/O帶寬的需求每三年實現(xiàn)翻番,PCIe也大致按照3年一代的速度更新演進,每一代升級幾乎能夠實現(xiàn)傳輸速率的翻倍,并有著良好的向后兼容性。
2003 年PCIe 1.0 正式發(fā)布,可支持每通道傳輸速率為 250MB/s,總傳輸速率為 2.5 GT/s。
2007 年推出PCIe 2.0 規(guī)范。在 PCIe 1.0 的基礎上將總傳輸速率提高了一倍,達到 5 GT/s,每通道傳輸速率從 250 MB/s 上升至 500 MB/s。
2022 年 PCIe 6.0 規(guī)范正式發(fā)布,總帶寬提高至 64 GT/s。
2022年6月,PCI-SIG聯(lián)盟宣布PCIe 7.0版規(guī)范,單條通道(x1)單向可實現(xiàn)128GT/s傳輸速率,計劃于2025年推出最終版本。
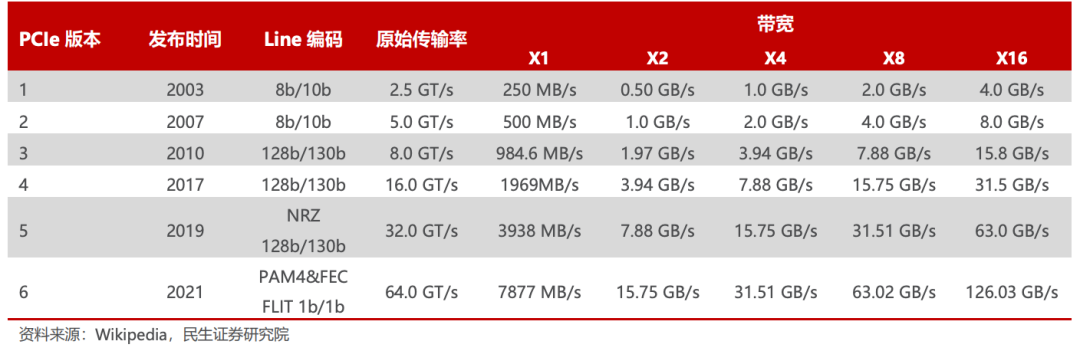
PCIe 1.0 到 6.0 不同 Lane 下的帶寬變化
Retimer
在PCIe標準的迭代過程中,隨著通信速率的逐步提高,信號質量也會受到影響,為應對愈演愈烈的信號衰減問題,PCIe從4.0時期開始引入信號調理芯片:
PCIe Retimer
Retimer是一種數(shù)模信號混合芯片,功能主要為重新生成信號。Retimer 先恢復抖動的時鐘信號,再生成新信號并重新發(fā)送,從而有效解決信號衰減問題,為服務器、存儲設備及硬件加速器等應用場景提供可擴展的高性能PCIe互聯(lián)解決方案。
PCIe Redriver
Redriver是一種信號放大器,通過發(fā)射端的驅動器和接收端的濾波器提升信號強度,從而實現(xiàn)對信號損耗的補償。
從工作原理來看,Redriver通過放大信號來恢復數(shù)據(jù),而Retimer 則重新建立一個傳輸信號的新副本。與 Redriver 相比,Retimer 恢復信號的效果更好,能夠實現(xiàn)比Redriver更優(yōu)的降低信道損耗效果,但由于增加了數(shù)據(jù)處理過程,時延有所增加。
PCIe Switch
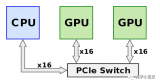
PCIe 的鏈路通信是一種端對端的數(shù)據(jù)傳輸,每一條PCIe鏈路兩端只能各連接一個設備,在需要高速數(shù)據(jù)傳輸和大量設備連接的場景中連接數(shù)量和速度受限。因此需要PCIe Switch提供擴展或聚合能力,從而允許更多的設備連接到一個 PCle 端口,以解決 PCIe 通道數(shù)量不夠的問題。
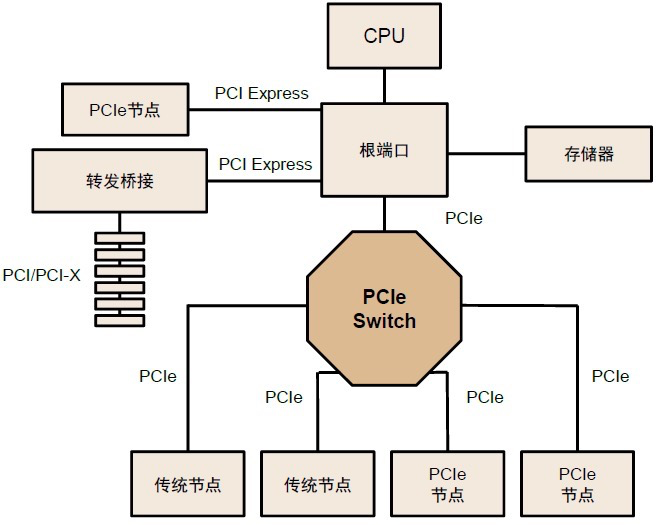
PCIe Switch連接多條PCIe總線
PCIe Switch兼具連接、交換功能,具有低功耗、低延遲、高可靠性、高靈活性等優(yōu)勢,能夠將多條PCIe總線連接在一起,形成一個高速的PCIe互聯(lián)網(wǎng)絡,從而實現(xiàn)多設備通信。從PCIe Switch內部結構看,其由多個PCI-PCI橋接構成,實現(xiàn)從單條線到多條線的發(fā)散。PCIe Switch 芯片與其設備的通信協(xié)議都是 PCIe。
02NVLink:高速 GPU 互連
算力的提升不僅依靠單張GPU卡的性能提升,往往還需要多GPU卡組合。在多GPU系統(tǒng)內部,GPU間通信的帶寬通常在數(shù)百GB/s以上,PCIe總線的數(shù)據(jù)傳輸速率容易成為瓶頸,且PCIe鏈路接口的串并轉換會產(chǎn)生較大延時,影響GPU并行計算的效率和性能。
GPU發(fā)出的信號需要先傳遞到PCIe Switch, PCIe Switch中涉及到數(shù)據(jù)的處理,CPU會對數(shù)據(jù)進行分發(fā)調度,這些都會引入額外的網(wǎng)絡延遲,限制了系統(tǒng)性能。
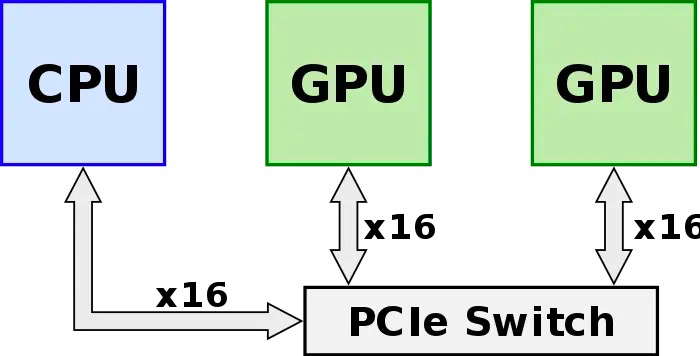
為此,NVIDIA推出了能夠提升GPU通信性能的技術——GPUDirect P2P技術,使GPU可以通過PCI Express直接訪問目標GPU的顯存,避免了通過拷貝到CPU host memory作為中轉,大大降低了數(shù)據(jù)交換的延遲,但受限于PCI Express總線協(xié)議以及拓撲結構的一些限制,無法做到更高的帶寬。此后,NVIDIA提出了NVLink總線協(xié)議。
NVLink的演進
NVLink 是一種高速互連技術,旨在加快 CPU 與 GPU、GPU 與 GPU 之間的數(shù)據(jù)傳輸速度,提高系統(tǒng)性能。NVLink通過GPU之間的直接互聯(lián),可擴展服務器內的多GPU I/O,相較于傳統(tǒng)PCIe總線可提供更高效、低延遲的互聯(lián)解決方案。
NVLink的首個版本于2014年發(fā)布,首次引入了高速GPU互連。2016年發(fā)布的P100搭載了第一代NVLink,提供 160GB/s 的帶寬,相當于當時 PCIe 3.0 x16 帶寬的 5 倍。V100搭載的NVLink2將帶寬提升到300GB/s ,A100搭載了NVLink3帶寬為600GB/s。目前NVLink已迭代至第四代,可為多GPU系統(tǒng)配置提供高于以往1.5倍的帶寬以及更強的可擴展性,H100中包含18條第四代NVLink鏈路,總帶寬達到900 GB/s,是PCIe 5.0帶寬的7倍。

四代 NVLink 對比
目前已知的NVLink分兩種,一種是橋接器的形式實現(xiàn)NVLink高速互聯(lián)技術,另一種是在主板上集成了NVLink接口。
NVSwitch
為了解決GPU之間通訊不均衡問題,NVIDIA引入NVSwitch。NVSwitch芯片是一種類似交換機ASIC的物理芯片,通過NVLink接口可以將多個GPU高速互聯(lián)到一起,可創(chuàng)建無縫、高帶寬的多節(jié)點GPU集群,實現(xiàn)所有GPU在一個具有全帶寬連接的集群中協(xié)同工作,從而提升服務器內部多個GPU之間的通訊效率和帶寬。NVLink和NVSwitch的結合使NVIDIA得以高效地將AI性能擴展到多個GPU。
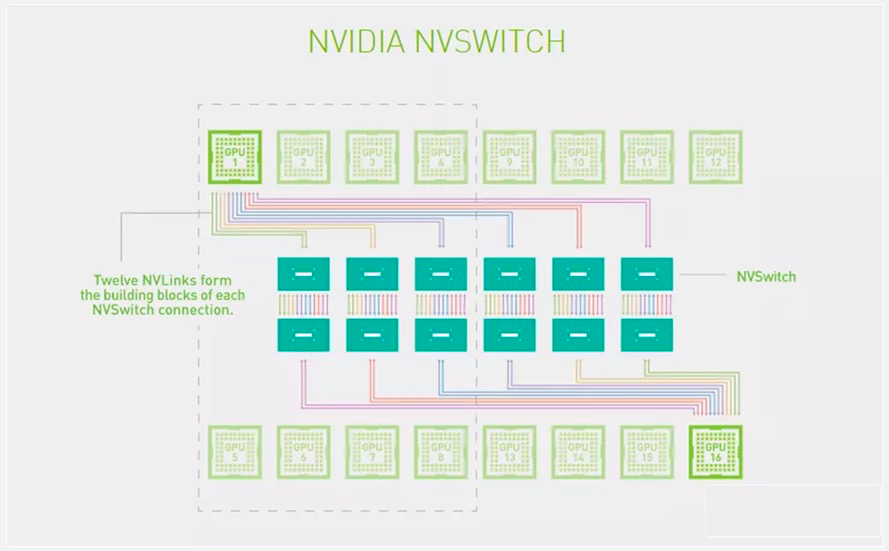
NVSwitch 拓撲圖
第一代 NVSwitch于2018年發(fā)布,采用臺積電 12nmFinFET 工藝制造,共有 18 個 NVLink 2.0 接口。目前 NVSwitch 已經(jīng)迭代至第三代。第三代 NVSwitch 采用 TSMC 4N 工藝構建,每個 NVSwitch 芯片上擁有 64 個 NVLink 4.0 端口,GPU 間通信速率可達 900GB/s。

三代 NVSwitch 性能對比
2023 年 5 月 29 日,NVIDIA推出的DGX GH200 AI超級計算機,采用NVLink以及 NVLink Switch System 將256個GH200 超級芯片相連,把所有GPU作為一個整體協(xié)同運行。DGX GH200 是第一臺突破 NVLink 上 GPU 可訪問內存 100 TB 障礙的超級計算機。
03AI時代下的網(wǎng)絡互聯(lián)
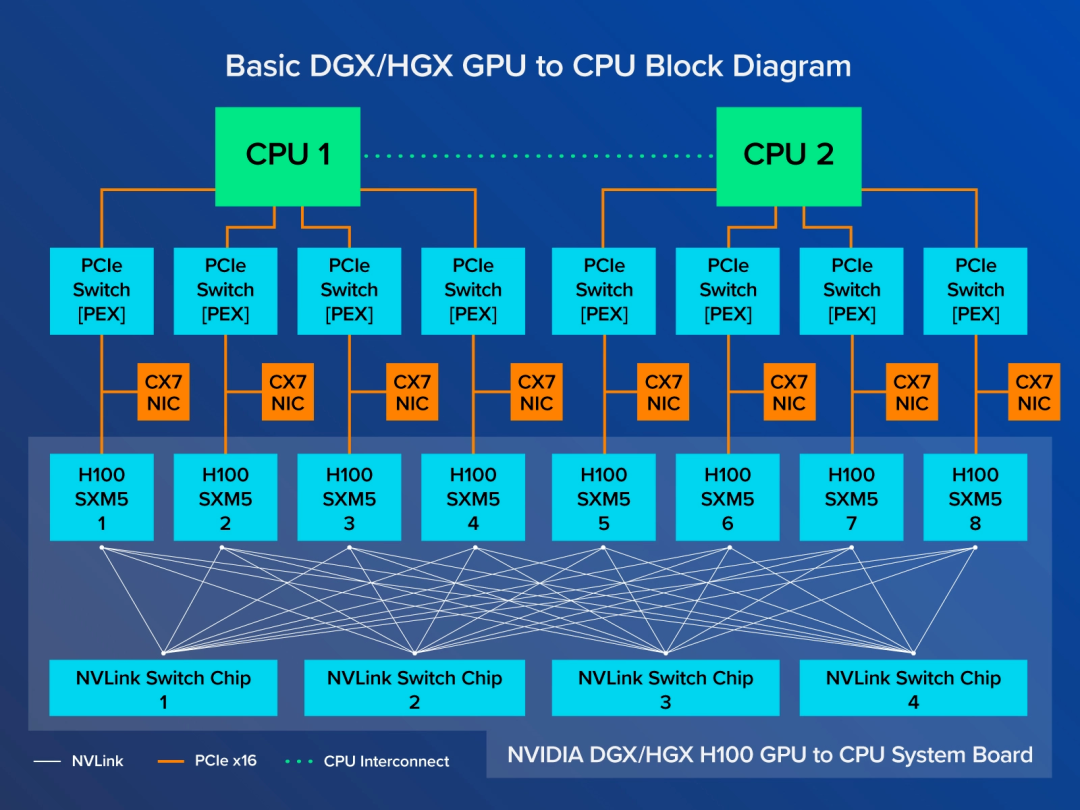
在逐步邁向AI時代網(wǎng)絡互聯(lián)的過程中,該選擇PCIe還是NVLink?我們可以先看下NVIDIA 的NVLink版(SXM版)與PCIe版GPU的區(qū)別。
SXM架構是一種高帶寬插座式解決方案,用于將 GPU連接到NVIDIA 專有的 DGX 和 HGX 系統(tǒng)。SXM 版GPU通過 NVSwitch 芯片互聯(lián),GPU 之間交換數(shù)據(jù)采用NVLink,未閹割的A100是600GB/s、H100是900GB/s,閹割過的A800、H800為400GB/s。PCIe版只有成對的 GPU 通過 NVLink Bridge 連接,通過 PCIe 通道進行數(shù)據(jù)通信。最新的PCIe只有128GB/s。
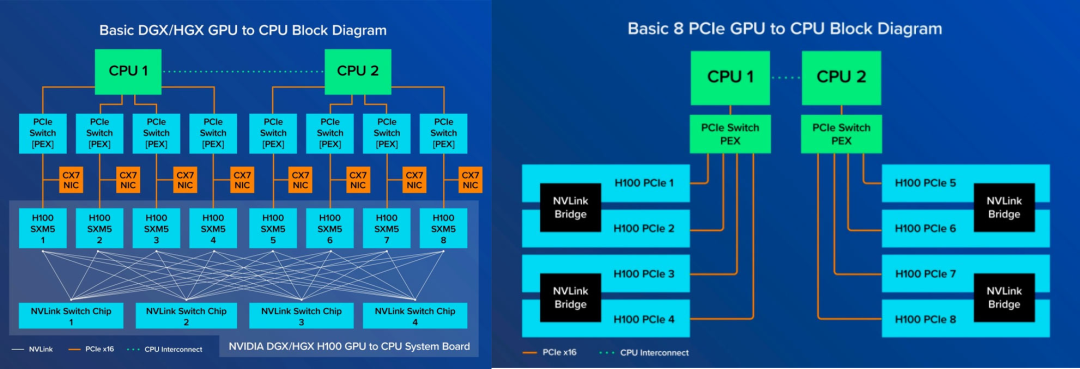
AI /HPC的計算需求不斷增長,因此越來越需要在 GPU 之間提供更大的互聯(lián)帶寬。總的來說,NVLink的傳輸速度與時延都要優(yōu)于PCIe,PCIe的帶寬已逐漸無法滿足AI時代數(shù)據(jù)互聯(lián)的需求。但PCIe作為通用標準的互聯(lián)技術,可廣泛應用于各種場景,而NVLink為NVIDIA專有,是NVIDIA AI帝國的護城河,其他企業(yè)只能采用PCIe或者別的互聯(lián)協(xié)議。
像谷歌是通過自研的OCS(Optical Circuit Switch)技術實現(xiàn)TPU之間的互聯(lián),解決TPU的擴展性問題。谷歌還自研了一款光路開關芯片Palomar,通過該芯片可實現(xiàn)光互聯(lián)拓撲的靈活配置。也就是說,TPU芯片之間的互聯(lián)拓撲并非一成不變,可以根據(jù)機器學習的具體模型來改變拓撲,提升計算性能及可靠性。借助OCS技術,可以將4096個TPU v4組成一臺超級計算機。
據(jù)稱,目前國外AI芯片初創(chuàng)公司Enfabrica和國內某些企業(yè)正沿著PCIe/CXL Switch方向在努力,結合CXL協(xié)議規(guī)范和PCIe接口的通用性,打造CPU-CPU直連交換芯片和系統(tǒng)方案。近期,NVIDIA還對Enfabrica進行了投資。有分析師表示,Enfabrica完全具備作為NVIDIA競爭對手的潛力,未來NVIDIA可能會考慮收購這家初創(chuàng)公司。
市場發(fā)展瞬息萬變,未來具體將如何演變不僅取決于技術創(chuàng)新,也取決于市場需求和行業(yè)合作。在這個不斷演變的AI網(wǎng)絡互聯(lián)時代,企業(yè)如何抉擇將取決于自身對性能、成本、應用場景和未來發(fā)展趨勢等多重因素的考量。
審核編輯:湯梓紅
-
服務器
+關注
關注
12文章
9303瀏覽量
86061 -
總線
+關注
關注
10文章
2903瀏覽量
88389 -
數(shù)據(jù)中心
+關注
關注
16文章
4858瀏覽量
72380 -
AI
+關注
關注
87文章
31513瀏覽量
270328 -
PCIe
+關注
關注
15文章
1260瀏覽量
83186
原文標題:AI網(wǎng)絡互聯(lián),PCIe還是NVLink?
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
詳解Zynq的兩種啟動模式

兩種典型的ADRC算法介紹
SQL語言的兩種使用方式
英偉達GPU卡多卡互聯(lián)NVLink,系統(tǒng)累積的公差,是怎么解決的?是連接器吸收的?
PCIe兩種中斷傳遞方式
PCIe總線的兩種復位方式
關于兩種無線傳輸技術WIHD和WIDI
PCIe錯誤報告的兩種機制詳解
FORESEE SSD研發(fā)團隊推出支持兩種加密功能的P709 PCIe SSD
詳解PMSM中常用的兩種坐標變換
NVLink的演進
Micro OLED和Micro LED兩種顯示技術有哪些不同?
英偉達AI服務器NVLink版與PCIe版有何區(qū)別?又如何選擇呢?
NVLink的演進:從內部互聯(lián)到超級網(wǎng)絡

全面解讀英偉達NVLink技術






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論