 Whisper語音轉文字教程
Whisper語音轉文字教程
語音轉文字在許多不同領域都有著廣泛的應用。以下是一些例子:
1.字幕制作:語音轉文字可以幫助視頻制作者快速制作字幕,這在影視行業和網絡視頻領域非常重要。通過使用語音轉文字工具,字幕制作者可以更快地生成字幕,從而縮短制作時間,節省人工成本,并提高制作效率。
2.法律文書:在法律領域,語音轉文字可以幫助律師和律所將聽證會、辯論和其他法律活動的錄音轉化為文字文檔。這些文檔可以用于研究、起草文件和法律分析等目的,從而提高工作效率。
3.醫療文檔:醫療專業人員可以使用語音轉文字技術來記錄病人的醫療記錄、手術記錄和其他相關信息。這可以減少錯誤和遺漏,提高記錄的準確性和完整性,為患者提供更好的醫療服務。
4.市場調查和分析:語音轉文字可以幫助企業快速收集和分析消費者反饋、電話調查和市場研究結果等數據。這可以幫助企業更好地了解其目標受眾和市場趨勢,從而制定更有效的營銷策略和商業計劃。
總之,語音轉文字技術在許多不同的行業和場景中都有著廣泛的應用,可以提高工作效率、減少成本和錯誤,并為企業和個人帶來更多商業價值。
語音轉文字是一項重要的技術,但市場上大部分語音轉文字工具存在諸多問題,效果非常差。如果你需要高效而準確的語音轉文字解決方案,你應該考慮使用Whisper。下面是whisper的一段轉換示例:
", ".join([i["text"] for i in result["segments"] if i is not None])
# Out[12]: '我贏了啊你說你看到沒有沒有這樣沒有減息啊我們后面是降息, 你不要去博這個東西, 我真是害怕你啊, 你不要去博不確定性, 是不是不確定性是我們的敵人, 聽到沒有朋友們, 好吧, 來朋友們, 你們的預約點好了啊, 朋友們, 你們的預約一定要給我點好了吧, 晚上八點鐘是準時開播的, 朋友們關注點好了, 我們盤中視頻見啊, 朋友們大家再見'
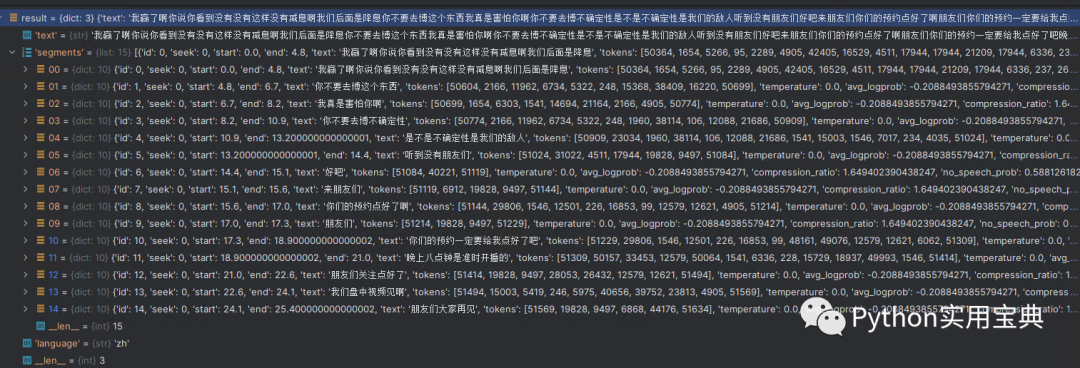
可以看到,即便是語速這么快的情況下,Whisper 依然實現了近乎完美的轉換。
在接下來的教程中,我們將介紹如何使用Whisper來輕松地完成語音轉文字任務。
1.準備
開始之前,你要確保Python和pip已經成功安裝在電腦上,如果沒有,可以訪問這篇文章:超詳細Python安裝指南 進行安裝。
**(可選1) **如果你用Python的目的是數據分析,可以直接安裝Anaconda:Python數據分析與挖掘好幫手—Anaconda,它內置了Python和pip.
**(可選2) **此外,推薦大家用VSCode編輯器,它有許多的優點:Python 編程的最好搭檔—VSCode 詳細指南。
請選擇以下任一種方式輸入命令安裝依賴 :
- Windows 環境 打開 Cmd (開始-運行-CMD)。
- MacOS 環境 打開 Terminal (command+空格輸入Terminal)。
- 如果你用的是 VSCode編輯器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install openai-whisper
此外你還需要安裝ffmpeg。
安裝ffmpeg
Windows:
- 進入 http://ffmpeg.org/download.html#build-windows,點擊 windows 對應的圖標,進入下載界面點擊 download 下載按鈕,
- 解壓下載好的zip文件到指定目錄
- 將解壓后的文件目錄中 bin 目錄(包含 ffmpeg.exe )添加進 path 環境變量中
- DOS 命令行輸入 ffmpeg -version, 出現以下界面說明安裝完成:

**Mac ** (打開終端(Terminal), 用 homebrew 安裝):
brew install ffmpeg --with-libvorbis --with-sdl2 --with-theora
apt-get install ffmpeg libavcodec-extra
2.使用Whisper進行語音轉文字
簡單的使用例子:
import whisper
whisper_model = whisper.load_model("large")
result = whisper_model.transcribe(r"C:Userswin10Downloadstest.wav")
print(", ".join([i["text"] for i in result["segments"] if i is not None]))
首先,我們建議使用Whisper的large-v2模型。根據我的實測結果,這個模型的表現非常優秀,它可以識別多種語言,包括中文,而且中文識別效果非常出色。在某些文字轉換的場景中,它的表現甚至優于騰訊云、阿里云。
如果你無法下載到模型,可以用我們的模型鏡像下載地址:https://pythondict.com/download/openai-whisper-large-v2/
使用前將模型文件放到指定位置:
Windows: C:Users你的用戶名.cachewhisper/large-v2.pt
Linux/MacOS: ~/.cache/whisper/large-v2.pt
然后重新運行程序即可得到轉換結果。比如我們轉換下面這個音頻:
whisper素材 **, Python實用寶典 ,**29秒
效果如下:
# 公眾號:Python實用寶典
# 轉載請附帶注釋
import whisper
whisper_model = whisper.load_model("large")
result = whisper_model.transcribe(r"C:Userswin10Downloadstest.wav")
print(", ".join([i["text"] for i in result["segments"] if i is not None]))
# 我贏了啊你說你看到沒有沒有這樣沒有減息啊我們后面是降息, 你不要去博這個東西, 我真是害怕你啊, 你不要去博不確定性, 是不是不確定性是我們的敵人, 聽到沒有朋友們, 好吧, 來朋友們, 你們的預約點好了啊, 朋友們, 你們的預約一定要給我點好了吧, 晚上八點鐘是準時開播的, 朋友們關注點好了, 我們盤中視頻見啊, 朋友們大家再見
此外,不建議一次性轉換長音頻。如果你要轉換長度很長的音頻,建議先做切割并降低碼率。參考我們以前moviepy的文章:
3.Whisper轉換結果分析
Whisper的生成結果是一個字典:
{'text': '我贏了啊你說你看到沒有沒有這樣沒有減息啊我們后面是降息你不要去博這個東西我真是害怕你啊你不要去博不確定性是不是不確定性是我們的敵人聽到沒有朋友們好吧來朋友們你們的預約點好了啊朋友們你們的預約一定要給我點好了吧晚上八點鐘是準時開播的朋友們關注點好了我們盤中視頻見啊朋友們大家再見', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 4.8, 'text': '我贏了啊你說你看到沒有沒有這樣沒有減息啊我們后面是降息', 'tokens': [50364, 1654, 5266, 95, 2289, 4905, 42405, 16529, 4511, 17944, 17944, 21209, 17944, 6336, 237, 26460, 4905, 15003, 13547, 8833, 1541, 47421, 26460, 50604], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 1, 'seek': 0, 'start': 4.8, 'end': 6.7, 'text': '你不要去博這個東西', 'tokens': [50604, 2166, 11962, 6734, 5322, 248, 15368, 38409, 16220, 50699], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 2, 'seek': 0, 'start': 6.7, 'end': 8.2, 'text': '我真是害怕你啊', 'tokens': [50699, 1654, 6303, 1541, 14694, 21164, 2166, 4905, 50774], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 3, 'seek': 0, 'start': 8.2, 'end': 10.9, 'text': '你不要去博不確定性', 'tokens': [50774, 2166, 11962, 6734, 5322, 248, 1960, 38114, 106, 12088, 21686, 50909], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 4, 'seek': 0, 'start': 10.9, 'end': 13.200000000000001, 'text': '是不是不確定性是我們的敵人', 'tokens': [50909, 23034, 1960, 38114, 106, 12088, 21686, 1541, 15003, 1546, 7017, 234, 4035, 51024], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 5, 'seek': 0, 'start': 13.200000000000001, 'end': 14.4, 'text': '聽到沒有朋友們', 'tokens': [51024, 31022, 4511, 17944, 19828, 9497, 51084], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 6, 'seek': 0, 'start': 14.4, 'end': 15.1, 'text': '好吧', 'tokens': [51084, 40221, 51119], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 7, 'seek': 0, 'start': 15.1, 'end': 15.6, 'text': '來朋友們', 'tokens': [51119, 6912, 19828, 9497, 51144], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 8, 'seek': 0, 'start': 15.6, 'end': 17.0, 'text': '你們的預約點好了啊', 'tokens': [51144, 29806, 1546, 12501, 226, 16853, 99, 12579, 12621, 4905, 51214], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 9, 'seek': 0, 'start': 17.0, 'end': 17.3, 'text': '朋友們', 'tokens': [51214, 19828, 9497, 51229], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 10, 'seek': 0, 'start': 17.3, 'end': 18.900000000000002, 'text': '你們的預約一定要給我點好了吧', 'tokens': [51229, 29806, 1546, 12501, 226, 16853, 99, 48161, 49076, 12579, 12621, 6062, 51309], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 11, 'seek': 0, 'start': 18.900000000000002, 'end': 21.0, 'text': '晚上八點鐘是準時開播的', 'tokens': [51309, 50157, 33453, 12579, 50064, 1541, 6336, 228, 15729, 18937, 49993, 1546, 51414], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 12, 'seek': 0, 'start': 21.0, 'end': 22.6, 'text': '朋友們關注點好了', 'tokens': [51414, 19828, 9497, 28053, 26432, 12579, 12621, 51494], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 13, 'seek': 0, 'start': 22.6, 'end': 24.1, 'text': '我們盤中視頻見啊', 'tokens': [51494, 15003, 5419, 246, 5975, 40656, 39752, 23813, 4905, 51569], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 14, 'seek': 0, 'start': 24.1, 'end': 25.400000000000002, 'text': '朋友們大家再見', 'tokens': [51569, 19828, 9497, 6868, 44176, 51634], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}], 'language': 'zh'}
text參數是沒有做任何分詞處理的純語音原文本。
我們要重點關注的是segments參數。segments參數對音頻內人物語言做了"分段"操作,比如這一段話:
{
'id': 1,
'seek': 0,
'start': 4.8,
'end': 6.7,
'text': '你不要去博這個東西',
'tokens': [50604, 2166, 11962, 6734, 5322, 248, 15368, 38409, 16220, 50699],
'temperature': 0.0,
'avg_logprob': -0.2088493855794271,
'compression_ratio': 1.649402390438247,
'no_speech_prob': 0.5881261825561523
}
它就相當于人一樣,去一幀幀校對每個詞說話的時間:start是起始時間,end是結束時間。即"你不要去博這個東西"發生在音頻的4.8秒到6.7秒之間。其他參數:
temperature 是指在語音轉文本模型生成結果時,控制輸出隨機性和多樣性的參數。
avg_logprob參數是語音轉文字模型預測的置信度評分的平均值。
compression_ratio參數是指音頻信號壓縮的比率。
no_speech_prob參數是指模型在某段時間內檢測到沒有語音信號的概率。
重點在于如何應用。start和end參數你可以用來直接生成視頻的字幕。大大提高生產效率。
置信度參數你可以用來提高識別準確率,如果說置信度一直不高,可以單獨拎出來人工優化。
總之,Whisper的Large-v2模型絕對是目前中文語音轉文字的頂級存在,有興趣的朋友趕緊試試吧。
-
語音
+關注
關注
3文章
385瀏覽量
38134 -
編輯器
+關注
關注
1文章
806瀏覽量
31293 -
數據分析
+關注
關注
2文章
1461瀏覽量
34166 -
Whisper
+關注
關注
0文章
3瀏覽量
5007
發布評論請先 登錄
相關推薦
看國內外語音交互廠商如何定位人工智能
語音轉文字用這個操作方法,幾秒鐘實現音頻轉換文字
會議記錄太難?是你沒選好手機錄音轉文字的好幫手
TTS文字轉語音模塊的學習資料分享
搜狗智能錄音筆C1可實現將語音準確轉換為文字
谷歌Live Transcribe語音識別技術可轉文字
微信新iOS版本語音轉文字功能上線
谷歌研發語音識別轉文字工具Live Transcribe
桌面版微信v2.9測試版體驗 新增語音消息自動轉文字功能
訊飛會議寶S8提升語音轉文字的速度,開啟高效記錄新時代
淺析語音識別技術的發展歷程
OpenAI官宣把ChatGPT API開放





 工商網監
工商網監
評論