 慢的不是Ruby,而是你的數據庫
慢的不是Ruby,而是你的數據庫
許多人不停抱怨 Ruby 運行緩慢。誠然,它的確不如人意,然而這并非致命傷,因為問題的根源在于你的數據庫速度緩慢,成為了瓶頸。因此,這個標題也可以改為 “Ruby 雖慢,但對你而言無關緊要”。
在編寫一個在現有的 Postgresql 數據庫中提供鍵值存儲的 gem,并對其進行基準測試時,我不斷地念叨:Ruby 可不慢,數據庫才慢。因此,我決定搜集這些基準數據,以支持我的觀點。
在業界,這被稱為 I/O 密集型(I/O-bound),與 計算密集型(CPU-bound)性能相對立。我所協助解決的大部分 Ruby 性能問題都屬于前者。Ruby 的緩慢并未引發任何問題。
Ruby 很慢,但不重要讓我們明確一點:Ruby 很慢。垃圾收集器、JIT 編譯器、其高度動態的特性、更改代碼運行時的能力等等,所有這些加在一起,都使得 Ruby 顯得較為遲緩。
然而,當人們抱怨 “Ruby 很慢” 時,當深入研究時,通常可以細分為以下三類:
Ruby 很慢,這對我們的用例來說是個問題。Ruby 很慢,但實際上對我們來說并不重要。Ruby 應用程序很慢,但實際上它是堆棧,而不僅僅是語言。
我想更深入地研究最后一個問題,但在此之前,我們先解決前兩個問題。
Ruby 每年都在提高性能,這受到了大家歡迎,但從更大的角度來看,這可能并不重要:
速度并不是減緩 Ruby 應用的主要因素。大多數使用 Ruby 的人并不要求它更快。他們固然熱衷于免費的提升,但并非因速度而避之不及。 ——https://www.fastruby.io/blog/ruby/performance/why-wasnt-ruby-3-faster.html因為性能確實非常依賴于環境:
[……] 你的系統需要多快?它現在的速度又有多快?如果你能測試它目前的性能,并且了解優秀的性能指標,那么你就應該有信心做出改變。有時候,為了獲得其他優勢而適度放緩某些需要是明智的決策,尤其是如果這種放緩仍在可接受的范圍內。
——《構建微服務》(Building Microservices)Sam Newman 著
因此通常情況下,Ruby 的速度緩慢并不重要,因為你的應用場景無需 Ruby 所追求的規模、速度或吞吐量。做好這種權衡是值得的。通常情況下,開發迅速、成本低廉、發布迅速,這些都是值得為應用程序投入額外資源(如服務器、硬件、SAAS)以保持性能可接受的。
雖然并非始終如此,但時常亦是如此。
快速基準測試為了再次驗證 Ruby 的性能不佳,我進行了一項快速的基準測試,在我近期遇到的一個(簡化版)實際工作中,比較了 Ruby 和 Rust 的性能:解析 CSV,從一列中提取一個數字,然后進行桶計數(bucket-count)。這是一個簡化版本(而我實際版本使用的 CSV 是這里使用的例子的十倍)。這個例子計算了一部電影的票數,并對這些票數進行分組:0 到 10 票之間,10 到 100 票之間等等。
為了進行對比,我嘗試用 Rust 和 Ruby 創建了一個內部盡可能相似的版本。結果令人失望,Ruby 和 Rust 的性能都很差勁,甚至存在一些錯誤,而且都沒有進行性能優化。我確信 Ruby 和 Rust 版本都可以進一步改進(盡管作為 Ruby 專家和 Rust 新手,我已經意識到 Rust 版本比 Ruby 版本更容易進行進一步優化)。所有的基準測試代碼都可以在 GitHub repo 中找到。
這并不是一項嚴謹的科學實驗,但它揭示了一個顯而易見的事實:Ruby 的確較慢 [1]。
Rust:
ber@berkes:db_benchmarks ? time ./target/release/movie_ratings
Some(0..=10): ###################### - 445
Some(10..=100): ############################################################ - 1208
Some(100..=1000): ############################################################################################################### - 2229
Some(1000..=10000): ############################################# - 914
Some(10000..=18446744073709551615): - 7
real 0m0,162s
user 0m0,146s
sys 0m0,016s
Ruby:
ber@berkes:db_benchmarks ? time ruby movie_ratings.rb
10000..: - 7
1000..10000: ############################################# - 914
100..1000: ############################################################################################################### - 2229
10..100: ############################################################ - 1208
0..10: ###################### - 445
real 0m1,491s
user 0m1,389s
sys 0m0,103s
Rust 版本的速度大約是 Ruby 版本的十倍,這是一個令人咋舌的差距!然而,在處理更大的數據集時,這種速度差異并非呈線性增長,而是呈現出不規則的變化。其中一部分時間是由啟動時間(在這個用例中很難測量)和 JIT 編譯器占據的,而另一部分則是 Ruby 中垃圾回收機制的任意啟動和停止所有進程所造成的問題。處理大型數據集,使這成為一個真實而惱人的問題。
但兩者的絕對差異又如何呢?Ruby 版本僅慢 1.2 秒多一點。這在測試和開發過程中已經足夠令人惱火了。當你一遍又一遍地運行此操作時,這一天只需要幾分鐘的時間:在開發過程中運行大約 20 次的腳本上總共需要 1.2 秒,然后可能每周運行一次。
雖然我只關注 CPU,但內存也是一個重要問題。然而,在現代軟件的典型用例中,內存使用并不明顯:客戶與服務器軟件交互時會感到緩慢,但并不會直接體驗到內存的使用。然而,不深入探討這個問題的主要原因是對內存進行基準測試相當復雜。
因此,可以說 Ruby 的確較慢,并且使用較多的資源。它做出了權衡,因此可能包括開發在內的整體成本更低。這取決于具體情況,沒有絕對的定論。
讓它變慢的是堆棧,而不僅僅是語言讓我們來深入探討一個不容忽視的問題:Ruby on Rails。雖然有些 Ruby 項目不使用 Rails,但大部分生產中運行的 Ruby 代碼都是基于 Rails 開發的。我個人主要使用 Ruby 編寫代碼,但很少涉及 Rails(因為我不太喜歡它),不過我是個例外。在 Ruby 開發中,幾乎總是采用 “用 Rails 進行 Web 開發” 的方式。
其中一個 Rails 的問題是它與數據庫的高度耦合(也可以說是一種好處)。Rails 專注于掌控數據庫的一切。沒有數據庫,Rails 將毫無用處,甚至可能阻礙工作進展,而不是提供幫助 [2]。此外,Rails 專注于 Web 開發。雖然你可以在 Rails 中處理非 Web 相關的任務,但這毫無意義。Rails 的目標是處理 HTTP 請求 - 響應。而且,Rails 的規模相當龐大 [3]。與 Ruby 語言類似,它更側重于人機工程學(對開發者友好度)而非性能。這是好事!然而,這也導致在 Rails 中性能成為一個問題,甚至比在 Ruby 中更加突出。
因此,“堆棧” 指的是 “使用數據庫的 Ruby on Rails”。由于 Rails 專注于 Web 開發,并且只處理 HTTP 請求 - 響應,我們將僅從 Web 服務的角度看待 Ruby。
為了深入分析這個問題,我將會比較一些非 Rails、非 HTTP、純 Ruby 的腳本。
Ruby 在處理大量數據方面并不擅長,但從本質上講,這正是 Web 服務所需要的。為了說明相對性能的差異,我們進行了一項實驗,比較了在不同源上寫入和讀取一百萬條記錄時的表現:內存、內存中的 SQLite 數據庫和 Postgresql 數據庫。
顯然,這并不令人驚訝,內存比其他任何選項都要快得多 [7]。在這里的 Postgresql 是一個 docker 容器,只占用 CPU 資源,而且根本不需要調整配置。這與絕對數值無關,所以具體設置 Postgresql 并不重要。重要的是差異的程度。
ber@berkes:db_benchmarks ? ruby ruby_slow.rb
user system total real
Mem write 0.005277 0.000000 0.005277 ( 0.005271)
Sqlite mem write 0.080462 0.000000 0.080462 ( 0.080464)
Postgres write 0.665662 0.151700 0.817362 ( 3.068891)
Mem read 0.002772 0.000000 0.002772 ( 0.002767)
Sqlite mem read 10.323161 0.021355 10.344516 ( 10.345039)
Postgres read 8.296689 0.041118 8.337807 ( 8.682667)
數據庫寫入速度緩慢。即使經過索引和負載狀態調優,讀取速度依舊無法改善。
然而,這一現象仍需深入探究原因。他們未指明導致緩慢的具體因素。令人意外的是,這也是 ORM 棧的一環。我選擇使用 Sequel,因為它相對簡單,方便我們剖析問題。
請見以下兩幅火焰圖,顯示在插入數據時,Postgresql 成為瓶頸。這并不奇怪,因為此時數據庫需處理大量工作。我們的表只有一項索引,而且是最輕類型的索引。
數據庫寫入速度之慢令人咋舌,以至于其他時間變得微不足道。
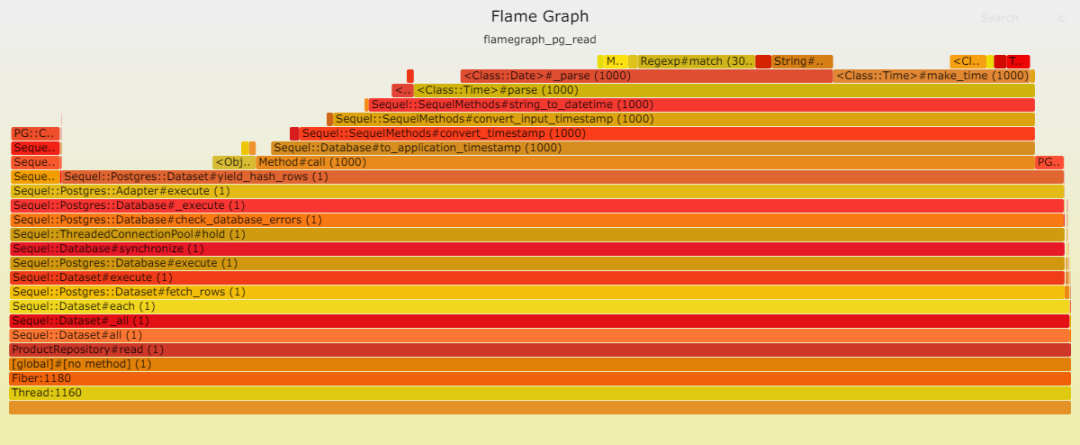
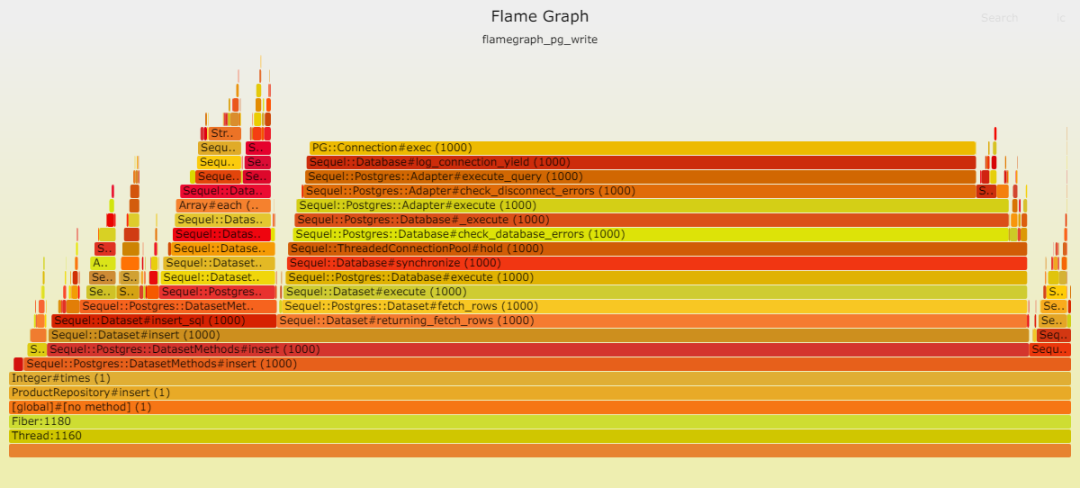
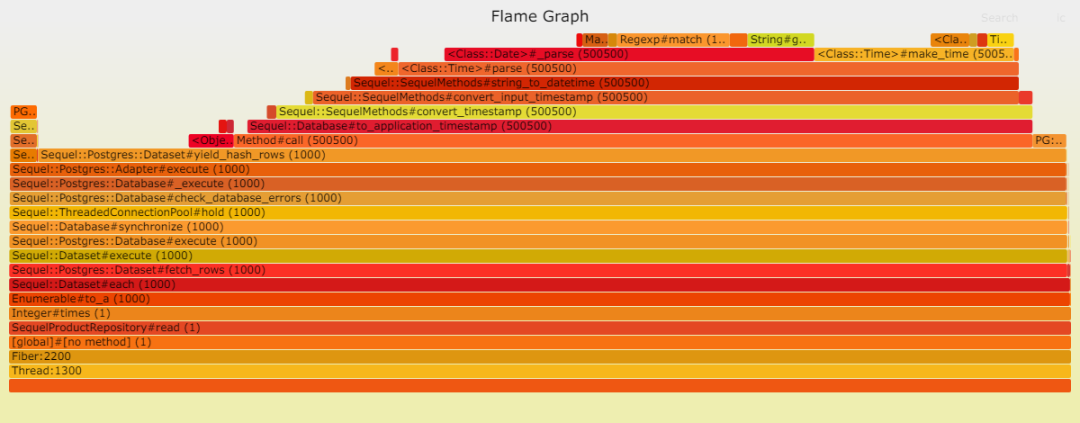
在讀取方面,Postgresql 表現卓越。這歸功于其簡單的查找操作,無需連接,僅使用一個索引,所需數據量也很少等等。然而,解析(處理數據)卻耗費了大量時間:DateTime::parse。換言之,DateTime::parse的性能問題相當顯著,以至于它在數據庫中耗費的時間微乎其微。
我們已經明確了堆棧中的兩大性能瓶頸:Postgresql 和 ORM。
需要明確的是:這并不意味著 Sequel 性能低下,或者 DateTime::parse 存在問題 [8]。相反,這表明我們加入堆棧的工具越多,性能就越糟糕。再強調一次:這是顯而易見的,并不令人意外。然而,值得重申。
在對整個 Rails 進行全面基準測試之前,我們先來審視一下 Rails 中的 ORM:ActiveRecord。同樣地,由于查詢操作非常簡單,不涉及復雜內容,因此在數據庫中所花費的時間非常有限。
user system total real
Postgres Sequel write 0.679423 0.112094 0.791517 ( 2.963639)
Postgres Sequel read 8.798584 0.011155 8.809739 ( 9.194935)
Postgres AR write 1.741980 0.189130 1.931110 ( 4.404335)
Postgres AR read 1.551020 0.040676 1.591696 ( 1.922000)
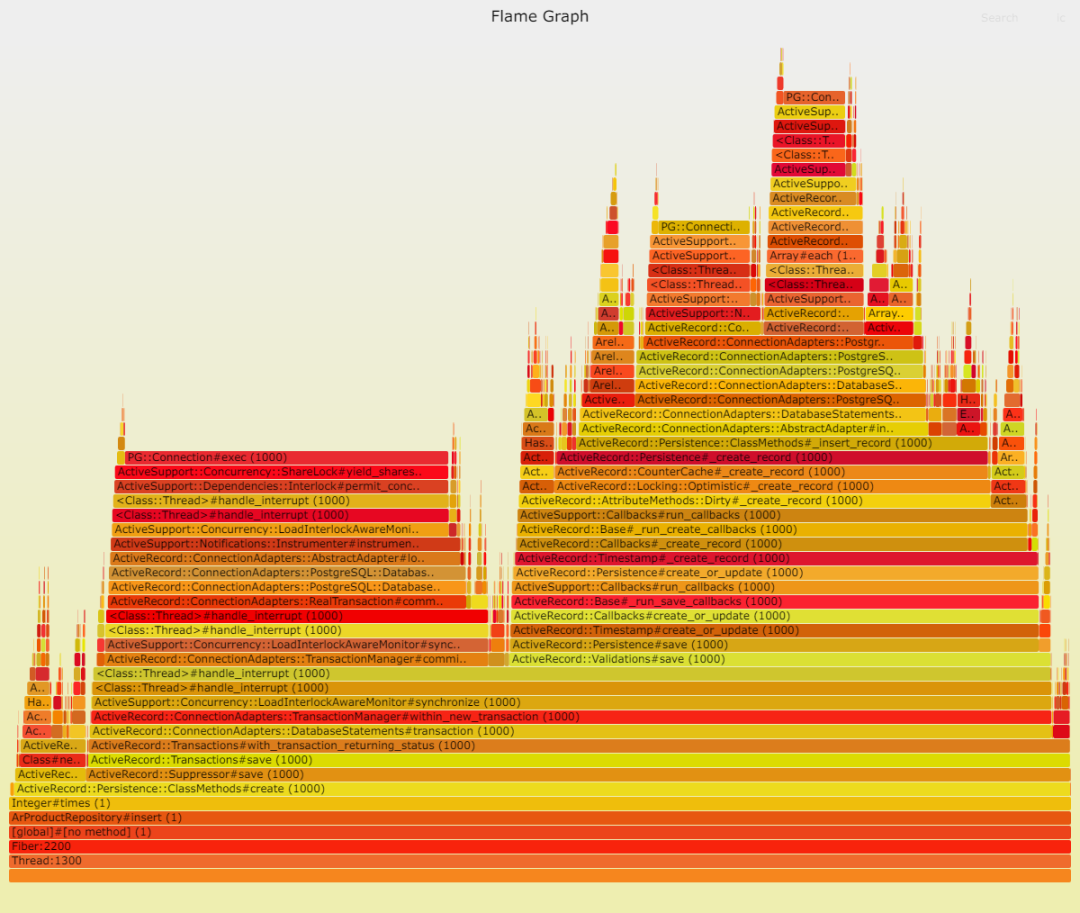
通過 ActiveRecord 寫入:
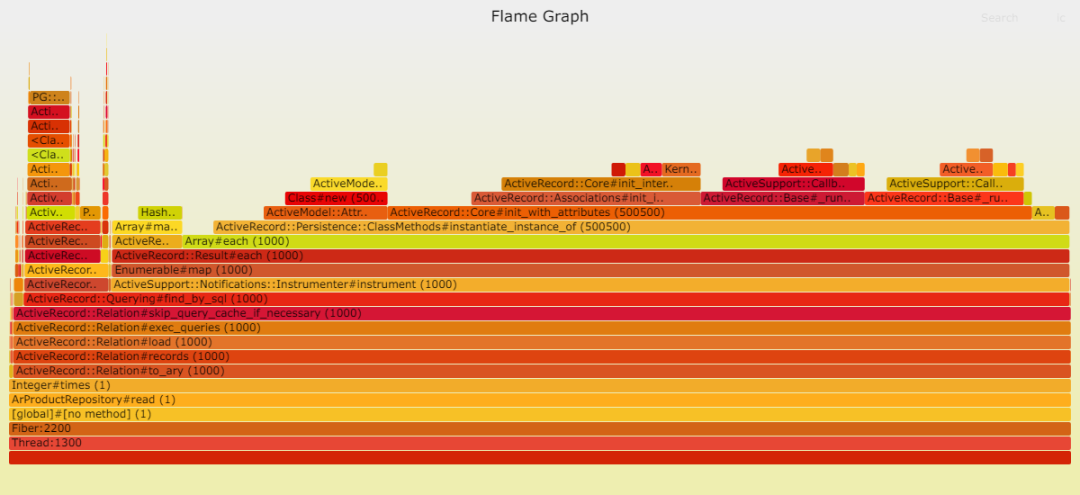
通過 ActiveRecord 讀取:
通過 Sequel 讀取:
通過 Sequel 寫入:
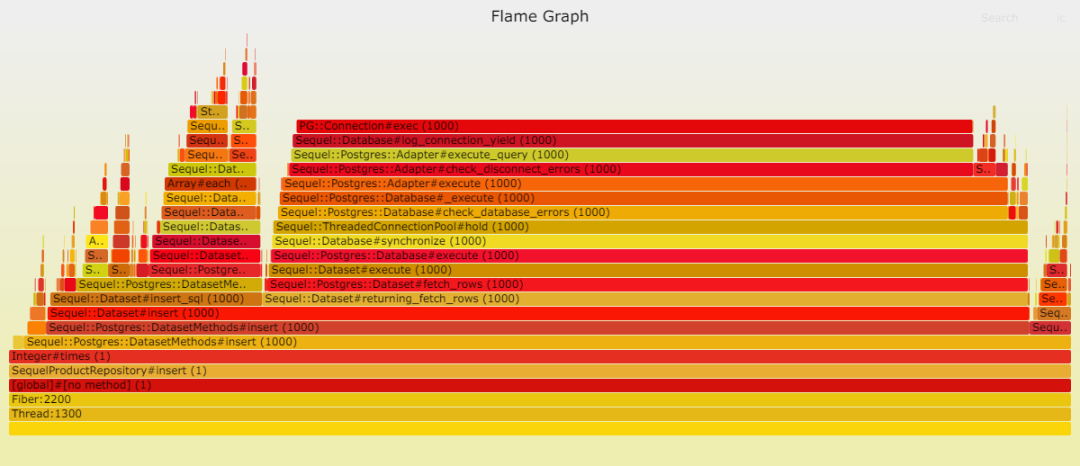
我們可以清楚地看到,Sequel 中的 DateTime::parse 問題依然存在。我推測,ActiveRecord 采用了一種更高效的策略,將 Postgresql 中的日期時間轉換為本地 DateTime。
盡管如此,Ruby 的糟糕性能相對來說并不重要。如果最快的數據庫查詢需要 150 毫秒,那么 Ruby 暫停 15 毫秒進行垃圾回收并沒有太大關系。JIT 的開銷、Rack 和 Rails 的 HTTP 解析和轉發的多層堆棧,除了向數據庫插入查詢耗時 190ms 之外,對整體性能影響不大。
這個例子展示了從表中獲取一條記錄的操作,雖然它并非關系型數據庫所擅長的領域,但它揭示了 ORM 存在的實際性能問題:缺乏連接、排序、過濾和計算等操作。
因此,即使 ORM 性能較差,數據庫仍然是主要的耗時組件。
擴大規模我們都曾遇到過這樣的情況:Ruby/Rails 代碼變得錯綜復雜,設置糟糕透頂,以至于堆棧(或自定義代碼)成為瓶頸。問題看似簡單解決:只需增加額外服務器。盡管單個請求速度不變,但至少服務器負載不再影響其他用戶性能。應用雖未變快,卻能容納更多用戶。
起初,這很容易實現,直到數據庫再次成為瓶頸。寫入關系數據庫始終是個難題:只能垂直擴展,即增加更強大的數據庫服務器。至于查詢(讀取)方面,可以通過增加復雜性來解決:讀取副本(曾稱為 “從屬”)。幾乎所有常見的關系數據庫服務器都支持此方法。雖然并不簡單,因為它將“最終一致性”引入了一個設置 / 框架,這個設置 / 框架從來沒有被設計成最終一致,但這是可行的。寫入(創建、插入、更新、刪除等)則不然:數據庫可能在某個時刻成為瓶頸。除非永遠如此:但性能從一開始就并非問題。
解決 Ruby 代碼中的性能問題輕而易舉:只需增加更多服務器。然而,解決數據庫性能問題就沒那么容易了,因為擴大關系數據庫規模困難重重,甚至有時不可能。
因此,為保持代碼可擴展性,應盡量在代碼中保留邏輯、轉換等元素。將業務邏輯、約束、驗證和計算推入數據庫,等于放棄了最簡單、通常也最經濟的性能提升手段:“增加更多服務器”。
Rails正如多次提到的,Rails 的復雜性導致了真正難以解決的性能問題。讓我們深入探討一下。
引用 DHH 在 Rails 的一句話:
“所有花哨的優化都是為了讓你更接近于如果你沒有使用這么多技術就會得到的性能”
https://macwright.com/2020/05/10/spa-fatigue.html——https://twitter.com/dhh/status/1259644085322670080
Rails 的內部復雜性對性能有兩大影響。首先,它包含大量抽象,被批評為 “黑魔法”。其次,在典型的 HTTP 循環中,數據需要經過所有這些層和所有這些復雜性,直到請求響應完成。
由于 Ruby 處理數據相對較慢(參見下文),數據傳遞的代碼越多,結果就越慢。這對所有軟件都是如此,但 Ruby 放大了這一點。Rails 的 163500 行 Ruby 代碼當然無助于加快速度。
“代碼行” 并非性能指標,但它們是一種指示。即使是最小的 Rails 項目也包含數十萬行代碼,即使你只使用其中一小部分數據。
針對 Rails 的基準測試已經進行了許多次。我現在將獲得更多元數據,而不是繼續討論整個堆棧的 “基準” 和火焰圖。少談數字,多談概念。因為對于 Rails,我確信性能問題是概念性的。如上所述,技術性能問題是由 Ruby 而不是 Rails 引起的。
ActiveRecord(Rails 中的實現,而非模式 per-sé)是對系統(關系數據庫)的抽象,需要大量詳細知識來保持性能。ActiveRecord (模式)不僅是一個漏洞的抽象,更多地是一個抽象,隱藏了一些不應被隱藏的細節。
更實際的情況是:幾年前我為了修復一個 N+1 查詢而加入的 User.active.includes(:roles) 動態地選擇它認為你需要的內容。它可能會“突然地、神奇地、動態地”開始構建其他連接和查詢,從而降低性能。(好吧,不是從一分鐘到下一分鐘的運行時,而是經過小的更改)。
我曾在一個擁有百萬級用戶的應用程序中,導致數據庫服務器集群崩潰:原因在于一個無關控制器的簡單更改,使 Rails 切換到一個外部連接,該連接具有巨大物化視圖,本不應以這種方式連接(用于報告)。然而,Rails 的魔力使其從此開始使用這一特性。每次頁面加載都會導致大約 2 秒鐘的數據庫查詢,占用數據庫服務器上的所有 CPU 和 IO。
當然,這是個愚蠢的錯誤。我們沒有看到這一點,因為在開發和測試中,性能從未下降。但我們應該注意到的是,這種錯誤在代碼庫中比比皆是。這些項目之所以繼續運行,唯一的原因是 Heroku 服務器的巨大成本(1200 美元 / 月),能為數百訪問者提供服務一天。這樣的錯誤不會導致數據庫集群崩潰,而是逐漸累積成昂貴且性能糟糕的應用程序。20 毫秒的減速幾乎無法衡量,數百個 20 毫秒的速度減慢在幾個月內逐漸增加,使響應變得令人無法接受。最糟糕的是,這些 “錯誤” 被團隊貼上了 “以 Rails 方式完成” 的標簽。
Rails 里到處都是這樣的 footgun(footgun,意即傷自己的腳的槍,Rails 稱其為“尖刀”。譯注:指在一個產品上添加一個新東西,容易讓槍打著自己腳。表明設計不好,促使用戶不敢加東西。)。其中大部分本身是無害的。很容易以次優的方式連接表,對未索引的列進行排序或過濾。Active-record 充滿了一些工具,可以很容易地濫用數據庫,無需警告。我開發的 Rails 應用程序數量驚人,其中包含某種形式的 .sort(params[:sort by]):僅在 2021 年,我就開發了三個獨立的 Rails 應用程序,所有這些應用程序都可以通過使用 ?sort=some_unindexed_field 觸發請求來處理數據庫。雖然這個例子很極端,可能被視為安全問題,但它說明了讓應用程序性能變差是多么容易。
sorting-by-un-indexed-field 示例揭示了 Rails 與數據庫的耦合如何使其許多性能問題成為數據庫問題。
根據我的經驗,Rails 中的性能問題總是:
-
N+1 個查詢。易于檢測。難以修復(不引入大量耦合問題)。
-
未優化的連接。添加簡單的 has_many 太容易了,這使得開發人員可以在數據庫中啟動過于繁重的查詢。一旦通過應用程序引入和傳播,這幾乎不可能解決。總有一些代碼最終運行類似 User.with_access_to(project).notifications.last.sent_to 的代碼。而且它會查詢五個連接表并且連接到至少一個索引上,而這個索引并不是為此準備的。導致大約 800 毫秒的查詢。在每次頁面加載時。
-
未優化的 where、group 和 order 調用。使用難以篩選、分組或排序或優化不佳的列。使用非索引列。
-
我的經驗法則是,每個添加或刪除的 where、has_many、group 或任何此類 active-record 方法都必須伴隨著數據庫遷移。因為只有當你已經有了以前沒有使用過的索引時,才需要為這種新的查詢方式優化數據庫(這意味著它以前優化得很差)。另一種情況是當你重用現有索引時,在這種情況下,你很可能應該重構以將查詢轉移到單一責任(例如,命名范圍)。
使用 Rails 人性化的 active-record API,很容易忘記你仍然只是在查詢一個復雜的關系數據庫。它需要微調、調優和調整,以便在合理的時間內為你提供數據。
使用 Rails,很容易累積許多小錯誤,從而使數據庫成為瓶頸。但是,即使所有這些都在你的控制之下,高性能的數據庫調用仍然比許多其他調用慢很多。
從內存和代碼中填充某個數組,然后從數據庫中填充該數組,速度仍然要快一千倍或更多。正如我在第一段中所展示的那樣。
所以,該怎么辦呢?我采用的一些經驗法則是:
-
在可以避免的情況下,不要使用數據庫。這總是比我想象的更頻繁。我不需要將世界上 195 個國家存儲在數據庫中,并在顯示國家下拉列表時加入。只需硬編碼或在啟動時輸入配置讀取。見鬼,也許你的電子商務網站的整個產品目錄可以是一個單獨的 YAML 啟動時讀取?這適用于比我通常認為的更多的對象。
-
將邏輯與數據庫分離,因為數據庫是最慢且最難擴展的地方。
-
謹慎處理 sort()、where()、join() 等調用。如果添加(或刪除)了索引,它們必須伴隨著至少調優索引的遷移。
-
保持所有數據庫調用簡單。盡可能少的連接,盡可能少的過濾器和排序。一般來說,數據庫可以更容易地為此進行優化。這也使應用程序與實際的數據庫細節分離。
-
N+1 個查詢并不總是壞事。有時甚至是首選。因為它們使業務邏輯保留在代碼中。并將獲取內容的邏輯保存在一個地方,從而允許在那里進行性能優化。
-
保持對實際性能問題的了解。根據性能是 I/O 密集型的還是計算性的,主動擴大規模。并祈禱它是計算性的。
內文注釋:
[1] 不過,我要強調的是:作為 Rust 新手,我花了一個多小時編寫 Rust 版本,而作為 Ruby 資深用戶(10 年以上),我只用了不到 10 分鐘。我需要運行兩個版本 2000 多次,然后我花在開發 Rust 版本上的額外時間才能在等待它運行的額外時間中得到回報。
[2] 我確信你可以給我展示一個項目,在那里你不用數據庫就可以運行 Rails,而且這很有意義。這些案例是存在的。我遇到的一些問題是:“我已經知道 Rails,但不知道 Sinatra”,或者“管理要求我們在類似的代碼庫上運行一切”。實際上,最后一個理由不成立。大多數都是合理的理由,除了最后一個:這是選擇 Rails 的一個可怕的理由。
[3] 一個快速 grep:超過 9000 個類,超過 33000 個方法;不包括所有神奇的動態方法,比如圍繞數據庫模型的方法。這還不包括 rails 本身附帶的 70 多個依賴項。
[4] 一個常見的 Rails 應用程序將發送電子郵件,可能會生成 pdf,接收 CSV 或導出 CSV,但所有交互通常都通過 HTTP 進行。我知道 Rails 只用于運行 cron 作業、ETL 管道甚至媒體編碼的例外情況(我曾研究過),但這些確實是例外情況。
[5] 具有諷刺意味的是,在這種非 http、非 rails 的環境中,性能問題變得不那么明確了,然而在這些情況下,人們通常會因為 ruby 的性能問題而將其作為選項。這也是 Ruby 很少在 Rails(和 / 或 Web)之外使用的原因之一。
[7] 令人驚訝的是,從內存中的 SQLite 中查找比從數據庫中查找要慢。但這說明了另一個重要問題:數據庫運行在單獨的線程中,甚至可能在單獨的硬件上。因此負載是分布式的:在 SQLite 和我們的內存示例中,一個 Ruby 線程完成了所有的過濾、獲取和提升。對于外部數據庫,這是偏移量。根據你的設置,Ruby 線程甚至可能在數據庫進行查找時繼續工作。在這種情況下,經過優化以過濾和獲取數據的 Postgresql 可以比 SQLite-inside-ruby 更快地完成這項工作。在典型的生產設置中,Postgresql 更適合這一點。
[8] 請注意,雖然 DateTime:parse 很慢,但這個函數是用 C 編寫的。之所以慢,并不是因為它是用 Ruby 編寫的,而是因為解析如此復雜的文本很慢。對于 Rust 中的功能相當的版本來說,它可能會一樣慢。
[9] 有更多的理由說明這是一個更好的主意。最明顯的一點是,你永遠不能把所有的業務邏輯都放在數據庫中,即使你想這樣做。因此,你將在多個地方擁有業務邏輯,而不需要任何去往何處的結構。所以把它放在一個地方的顯而易見的解決方案是……放在一個地方。唯一可以保存所有內容的地方:你的應用程序。
-
數據庫
+關注
關注
7文章
3848瀏覽量
64690 -
ruby
+關注
關注
0文章
44瀏覽量
3467 -
postgresql
+關注
關注
0文章
22瀏覽量
237
原文標題:慢的不是 Ruby,而是你的數據庫
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
分布式數據庫,什么是分布式數據庫
MySQL數據庫誤刪后的回復技巧
多維數據庫有哪些
數據庫教程之如何進行數據庫設計
工業大數據中的實時數據庫與時序數據庫是什么
云數據庫和自建數據庫的區別及應用
華為云數據庫-RDS for MySQL數據庫
【數據庫數據恢復】MongoDB數據庫數據遷移報錯的數據恢復案例
數據庫上云已成趨勢,華為云數據庫與傳統數據庫對比解析

python讀取數據庫數據 python查詢數據庫 python數據庫連接
什么是數據庫?除了MySQL還有哪些數據庫?
數據庫數據恢復——MongoDB數據庫介紹和數據恢復案例

選擇 KV 數據庫最重要的是什么?





 工商網監
工商網監
評論