 為什么重采樣很重要?Pandas中重新采樣的關鍵問題解析
為什么重采樣很重要?Pandas中重新采樣的關鍵問題解析
重采樣是時間序列分析中處理時序數據的一項基本技術。它是關于將時間序列數據從一個頻率轉換到另一個頻率,它可以更改數據的時間間隔,通過上采樣增加粒度,或通過下采樣減少粒度。在本文中,我們將深入研究Pandas中重新采樣的關鍵問題。
為什么重采樣很重要?
時間序列數據到達時通常帶有可能與所需的分析間隔不匹配的時間戳。例如以不規則的間隔收集數據,但需要以一致的頻率進行建模或分析。
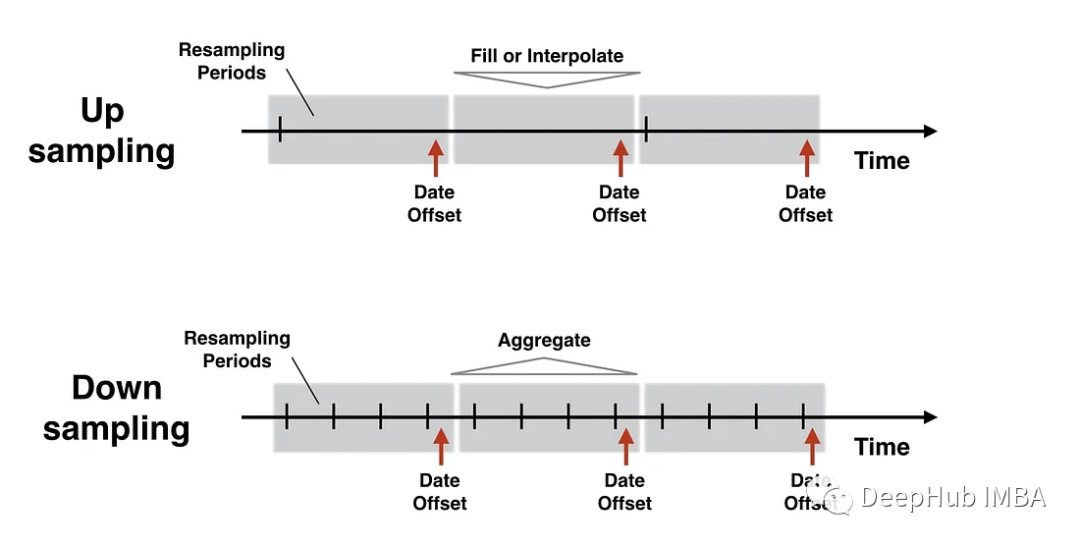
重采樣分類
重采樣主要有兩種類型:
1、Upsampling
上采樣可以增加數據的頻率或粒度。這意味著將數據轉換成更小的時間間隔。
2、Downsampling
下采樣包括減少數據的頻率或粒度。將數據轉換為更大的時間間隔。

重采樣的應用
重采樣的應用十分廣泛:
在財務分析中,股票價格或其他財務指標可能以不規則的間隔記錄。重新可以將這些數據與交易策略的時間框架(如每日或每周)保持一致。
物聯網(IoT)設備通常以不同的頻率生成數據。重新采樣可以標準化分析數據,確保一致的時間間隔。
在創建時間序列可視化時,通常需要以不同的頻率顯示數據。重新采樣夠調整繪圖中的細節水平。
許多機器學習模型都需要具有一致時間間隔的數據。在為模型訓練準備時間序列數據時,重采樣是必不可少的。
重采樣過程
重采樣過程通常包括以下步驟:
首先選擇要重新采樣的時間序列數據。該數據可以采用各種格式,包括數值、文本或分類數據。
確定您希望重新采樣數據的頻率。這可以是增加粒度(上采樣)或減少粒度(下采樣)。
選擇重新采樣方法。常用的方法包括平均、求和或使用插值技術來填補數據中的空白。
在上采樣時,可能會遇到原始時間戳之間缺少數據點的情況。插值方法,如線性或三次樣條插值,可以用來估計這些值。
對于下采樣,通常會在每個目標區間內聚合數據點。常見的聚合函數包括sum、mean或median。
評估重采樣的數據,以確保它符合分析目標。檢查數據的一致性、完整性和準確性。
Pandas中的resample()方法
resample可以同時操作Pandas Series和DataFrame對象。它用于執行聚合、轉換或時間序列數據的下采樣和上采樣等操作。
下面是
resample()
方法的基本用法和一些常見的參數:
import pandas as pd
# 創建一個示例時間序列數據框
data = {'date': pd.date_range(start='2023-01-01', end='2023-12-31', freq='D'),
'value': range(365)}
df = pd.DataFrame(data)
# 將日期列設置為索引
df.set_index('date', inplace=True)
# 使用resample()方法進行重新采樣
# 將每日數據轉換為每月數據并計算每月的總和
monthly_data = df['value'].resample('M').sum()
# 將每月數據轉換為每季度數據并計算每季度的平均值
quarterly_data = monthly_data.resample('Q').mean()
# 將每季度數據轉換為每年數據并計算每年的最大值
annual_data = quarterly_data.resample('Y').max()
print(monthly_data)
print(quarterly_data)
print(annual_data)
在上述示例中,我們首先創建了一個示例的時間序列數據框,并使用
resample()
方法將其轉換為不同的時間頻率(每月、每季度、每年)并應用不同的聚合函數(總和、平均值、最大值)。
resample()
方法的參數:
- 第一個參數是時間頻率字符串,用于指定重新采樣的目標頻率。常見的選項包括
'D'(每日)、'M'(每月)、'Q'(每季度)、'Y'(每年)等。 - 你可以通過第二個參數
how來指定聚合函數,例如'sum'、'mean'、'max'等,默認是'mean'。 - 你還可以使用
closed參數來指定每個區間的閉合端點,可選的值包括'right'、'left'、'both'、'neither',默認是'right'。 - 使用
label參數來指定重新采樣后的標簽使用哪個時間戳,可選的值包括'right'、'left'、'both'、'neither',默認是'right'。 - 可以使用
loffset參數來調整重新采樣后的時間標簽的偏移量。 - 最后,你可以使用聚合函數的特定參數,例如
'sum'函數的min_count參數來指定非NA值的最小數量。
1、指定列名
默認情況下,Pandas的resample()方法使用Dataframe或Series的索引,這些索引應該是時間類型。但是,如果希望基于特定列重新采樣,則可以使用on參數。這允許您選擇一個特定的列進行重新采樣,即使它不是索引。
df.reset_index(drop=False, inplace=True)
df.resample('W', on='index')['C_0'].sum().head()
在這段代碼中,使用resample()方法對'index'列執行每周重采樣,計算每周'C_0'列的和。
2、指定開始和結束的時間間隔
closed參數允許重采樣期間控制打開和關閉間隔。默認情況下,一些頻率,如'M', 'A', 'Q', 'BM', 'BA', 'BQ'和'W'是右閉的,這意味著包括右邊界,而其他頻率是左閉的,其中包括左邊界。在轉換數據頻率時,可以根據需要手動設置關閉間隔。
df = generate_sample_data_datetime()
pd.concat([df.resample('W', closed='left')['C_0'].sum().to_frame(name='left_closed'),
df.resample('W', closed='right')['C_0'].sum().to_frame(name='right_closed')],
axis=1).head(5)
在這段代碼中,我們演示了將日頻率轉換為周頻率時左閉間隔和右閉間隔的區別。
3、輸出結果控制
label參數可以在重采樣期間控制輸出結果的標簽。默認情況下,一些頻率使用組內的右邊界作為輸出標簽,而其他頻率使用左邊界。在轉換數據頻率時,可以指定是要使用左邊界還是右邊界作為輸出標簽。
df = generate_sample_data_datetime()
df.resample('W', label='left')['C_0'].sum().to_frame(name='left_boundary').head(5)
df.resample('W', label='right')['C_0'].sum().to_frame(name='right_boundary').head(5)
在這段代碼中,輸出標簽是根據在label參數中指定“left”還是“right”而變化的,建議在實際應用時顯式指定,這樣可以減少混淆。
4、匯總統計數據
重采樣可以執行聚合統計,類似于使用groupby。使用sum、mean、min、max等聚合方法來匯總重新采樣間隔內的數據。這些聚合方法類似于groupby操作可用的聚合方法。
df.resample('D').sum()
df.resample('W').mean()
df.resample('M').min()
df.resample('Q').max()
df.resample('Y').count()
df.resample('W').std()
df.resample('M').var()
df.resample('D').median()
df.resample('M').quantile([0.25, 0.5, 0.75])
custom_agg = lambda x: x.max() - x.min()
df.resample('W').apply(custom_agg)
上采樣和填充
在時間序列數據分析中,上采樣和下采樣是用來操縱數據觀測頻率的技術。這些技術對于調整時間序列數據的粒度以匹配分析需求非常有價值。
我們先生成一些數據
import pandas as pd
import numpy as np
def generate_sample_data_datetime():
np.random.seed(123)
number_of_rows = 365 * 2
num_cols = 5
start_date = '2023-09-15' # You can change the start date if needed
cols = ["C_0", "C_1", "C_2", "C_3", "C_4"]
df = pd.DataFrame(np.random.randint(1, 100, size=(number_of_rows, num_cols)), columns=cols)
df.index = pd.date_range(start=start_date, periods=number_of_rows)
return df
df = generate_sample_data_datetime()
上采樣包括增加數據的粒度,這意味著將數據從較低的頻率轉換為較高的頻率。
假設您有上面生成的每日數據,并希望將其轉換為12小時的頻率,并在每個間隔內計算“C_0”的總和:
df.resample('12H')['C_0'].sum().head(10)
代碼將數據重采樣為12小時的間隔,并在每個間隔內對' C_0 '應用總和聚合。這個.head(10)用于顯示結果的前10行。
在上采樣過程中,特別是從較低頻率轉換到較高頻率時,由于新頻率引入了間隙,會遇到丟失數據點的情況。所以需要對間隙的數據進行填充,填充一般使用以下幾個方法:
向前填充-前一個可用的值填充缺失的值。可以使用limit參數限制正向填充的數量。
df.resample('8H')['C_0'].ffill(limit=1)
反向填充 -用下一個可用的值填充缺失的值。
df.resample('8H')['C_0'].bfill(limit=1)
最近填充 -用最近的可用值填充缺失的數據,該值可以是向前的,也可以是向后的。
df.resample('8H')['C_0'].nearest(limit=1)
Fillna —結合了前面三個方法的功能。可以指定方法(例如,'pad'/' fill', 'bfill', 'nearest'),并使用limit參數進行數量控制。
df.resample('8H')['C_0'].fillna(method='pad', limit=1)
Asfreq-指定一個固定的值來填充所有缺失的部分一次。例如,可以使用-999填充缺失的值。
df.resample('8H')['C_0'].asfreq(-999)
插值方法-可以應用各種插值算法。
df.resample('8H').interpolate(method='linear').applymap(lambda x: round(x, 2))
一些常用的函數
1、使用agg進行聚合
result = df.resample('W').agg(
{
'C_0': ['sum', 'mean'],
'C_1': lambda x: np.std(x, ddof=1)
}
).head()
使用agg方法將每日時間序列數據重新采樣到每周頻率。并為不同的列指定不同的聚合函數。對于“C_0”,計算總和和平均值,而對于“C_1”,計算標準差。
2、使用 apply 聚合
def custom_agg(x):
agg_result = {
'C_0_mean': round(x['C_0'].mean(), 2),
'C_1_sum': x['C_1'].sum(),
'C_2_max': x['C_2'].max(),
'C_3_mean_plus1': round(x['C_3'].mean() + 1, 2)
}
return pd.Series(agg_result)
result = df.resample('W').apply(custom_agg).head()
定義了一個名為custom_agg的自定義聚合函數,它將DataFrame x作為輸入,并在不同列上計算各種聚合。使用apply方法將數據重新采樣到每周的頻率,并應用自定義聚合函數。
3、使用transform進行變換
df['C_0_cumsum'] = df.resample('W')['C_0'].transform('cumsum')
df['C_0_rank'] = df.resample('W')['C_0'].transform('rank')
result = df.head(10)
使用transform 方法來計算每周組中'C_0'變量的累積和排名。DF的原始索引結構保持不變。
4、使用pipe 進行管道操作
result = df.resample('W')['C_0', 'C_1']
.pipe(lambda x: x.cumsum())
.pipe(lambda x: x['C_1'] - x['C_0'])
result = result.head(10)
使用管道方法對下采樣的'C_0'和'C_1'變量進行鏈式操作。cumsum函數計算累積和,第二個管道操作計算每個組的'C_1'和'C_0'之間的差值。像管道一樣執行順序操作。
總結
時間序列的重采樣是將時間序列數據從一個時間頻率(例如每日)轉換為另一個時間頻率(例如每月或每年),并且通常伴隨著對數據進行聚合操作。重采樣是時間序列數據處理中的一個關鍵操作,通過進行重采樣可以更好地理解數據的趨勢和模式。
在Python中,可以使用Pandas庫的
resample()
方法來執行時間序列的重采樣。
-
轉換器
+關注
關注
27文章
8745瀏覽量
148054 -
物聯網
+關注
關注
2914文章
44938瀏覽量
377071 -
數據處理
+關注
關注
0文章
613瀏覽量
28631 -
python
+關注
關注
56文章
4807瀏覽量
85040 -
重采樣
+關注
關注
0文章
2瀏覽量
1113
發布評論請先 登錄
相關推薦
關于labview中xy圖中波形重采樣的問題
使用FPGA實現高效并行實時上采樣

什么是中頻采樣?什么是IQ采樣?中頻采樣和IQ采樣的比較和轉換






 工商網監
工商網監
評論