 適用于任意數據模態的自監督學習數據增強技術
適用于任意數據模態的自監督學習數據增強技術
本文提出了一種適用于任意數據模態的自監督學習數據增強技術。
自監督學習算法在自然語言處理、計算機視覺等領域取得了重大進展。這些自監督學習算法盡管在概念上是通用的,但是在具體操作上是基于特定的數據模態的。這意味著需要為不同的數據模態開發不同的自監督學習算法。為此,本文提出了一種通用的數據增強技術,可以應用于任意數據模態。相較于已有的通用的自監督學習,該方法能夠取得明顯的性能提升,同時能夠代替一系列為特定模態設計的復雜的數據增強方式并取得與之類似的性能。
簡介 當前 Siamese 表征學習 / 對比學習需要利用數據增強技術來構建同一個數據的不同樣本,并將其輸入兩個并行的網絡結構,從而產生足夠強的監督信號。然而這些數據增強技術往往非常依賴于模態特定的先驗知識,通常需要手動設計或者搜索適用于當前模態的最佳組合。除了耗時耗力外,找到的最優數據增強方式也極難遷移到別的領域。例如,常見的針對于自然 RGB 圖像的顏色抖動(color jittering)無法應用于除了自然圖像以外的其他數據模態。 一般性地,輸入數據可以被表征為由序列維度(sequential)和通道維度(channel)組成的二維向量。其中序列維度通常是模態相關的,例如圖像上的空間維度、語音的時間維度以及語言的句法維度。而通道維度是模態無關的。在自監督學習中,masked modeling [1] 或者以 masking 作為數據增強 [2] 已經成為一種有效的學習方式。然而這些操作都作用于序列維度。為了能夠廣泛應用于不同數據模態,本文提出一種作用于通道維度的數據增強手段:隨機量化(randomized quantization)。每個通道中的數據通過非均勻量化器進行動態量化,量化值是從隨機劃分的區間中隨機采樣的。通過這種方式,落在同一個區間內原始輸入的信息差被刪除,同時不同區間數據的相對大小被保留,從而達到 masking 的效果。
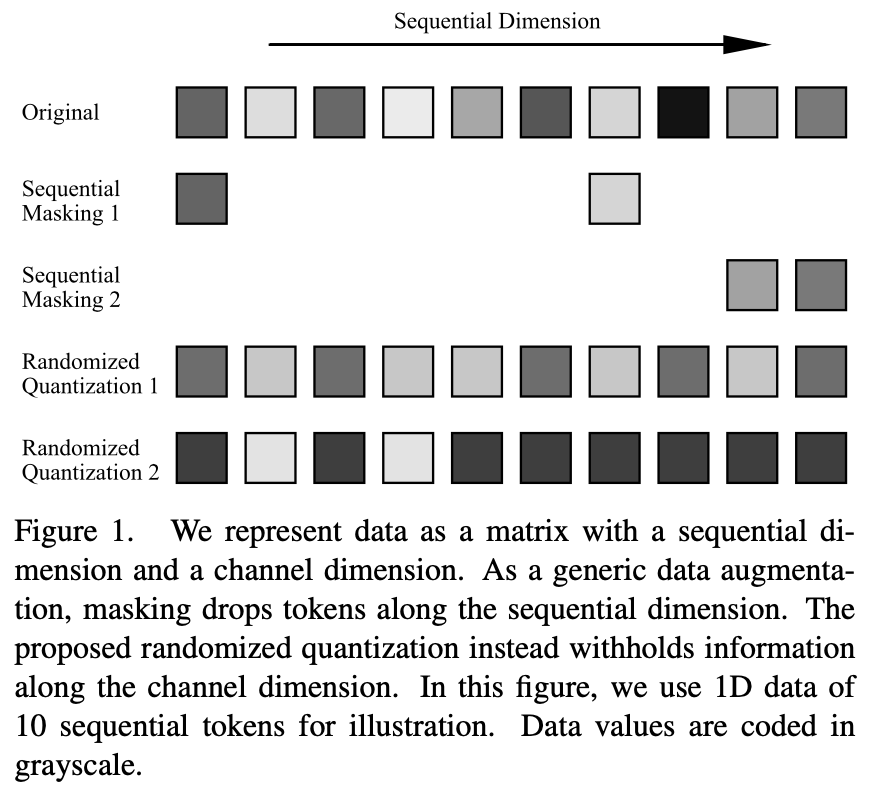
該方法在各種不同數據模態上超過了已有任意模態自監督學習方法,包括自然圖像、3D 點云、語音、文本、傳感器數據、醫療圖像等。在多種預訓練學習任務中,例如對比學習(例如 MoCo-v3)和自蒸餾自監督學習(例如 BYOL)都學到了比已有方法更優的特征。該方法還經過驗證,適用于不同的骨干網絡結構,例如 CNN 和 Transformer。 方法 量化(Quantization)指的是利用一組離散的數值表征連續數據,以便于數據的高效存儲、運算以及傳輸。然而,一般的量化操作的目標是在不損失精確度的前提下壓縮數據,因而該過程是確定性的,而且是設計為與原數據盡量接近的。這就限制了其作為增強手段的強度和輸出的數據豐富程度。 本文提出一種隨機量化操作(randomized quantization),將輸入的每個 channel 數據獨立劃分為多個互不重疊的隨機區間(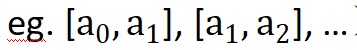 ),并將落在各個區間內的原始輸入映射到從該區間內隨機采樣的一個常數
),并將落在各個區間內的原始輸入映射到從該區間內隨機采樣的一個常數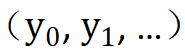 。 ?
。 ?

隨機量化作為自監督學習任務中 masking 通道維度數據的能力取決于以下三個方面的設計:1) 隨機劃分數值區間;2) 隨機采樣輸出值以及 3)劃分的數值區間個數。 具體而言,隨機的過程帶來了更加豐富的樣本,同一個數據每次執行隨機量化操作都可以生成不同的數據樣本。同時,隨機的過程也帶來對原始數據更大的增強力度,例如隨機劃分出大的數據區間,或者當映射點偏離區間中值點時,都可以導致落在該區間的原始輸入和輸出之間的更大差異。 除此之外,也可以非常容易地通過適當減少劃分區間的個數,提高增強力度。這樣,當應用于 Siamese 表征學習的時候,兩個網絡分支就可以見到有足夠信息差異的輸入數據,從而構建足夠強的學習信號,幫助到特征學習。 下圖可視化了不同數據模態在使用了該數據增強方式之后的效果:
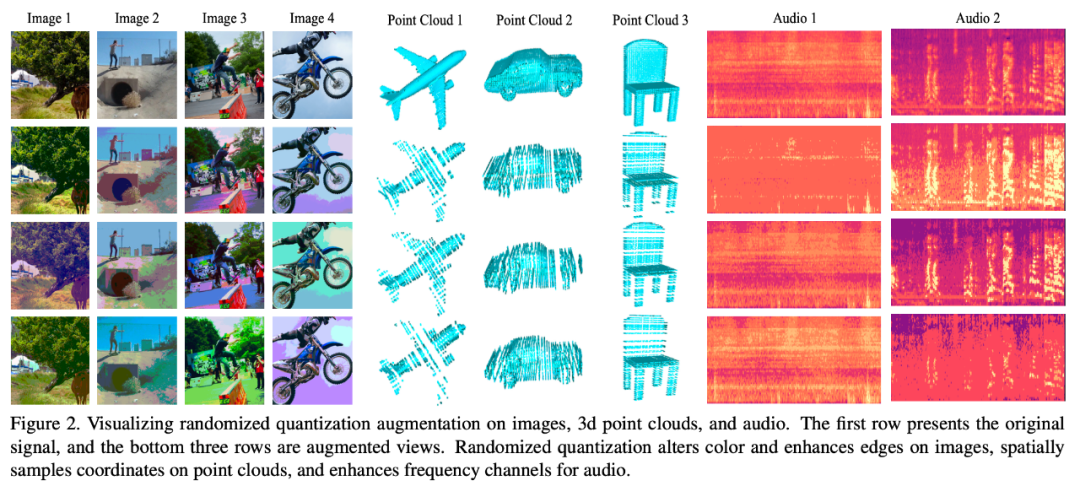
實驗結果模態 1:圖像 本文在 ImageNet-1K 數據集上評估了 randomized quantization 應用于 MoCo-v3 和 BYOL 的效果,評測指標為 linear evaluation。當作為唯一的數據增強方式單獨使用的時候,即將本文的 augmentation 應用于原始圖像的 center crop,以及和常見的 random resized crop(RRC)配合使用的時候,該方法都取得了比已有通用自監督學習方法更好的效果。
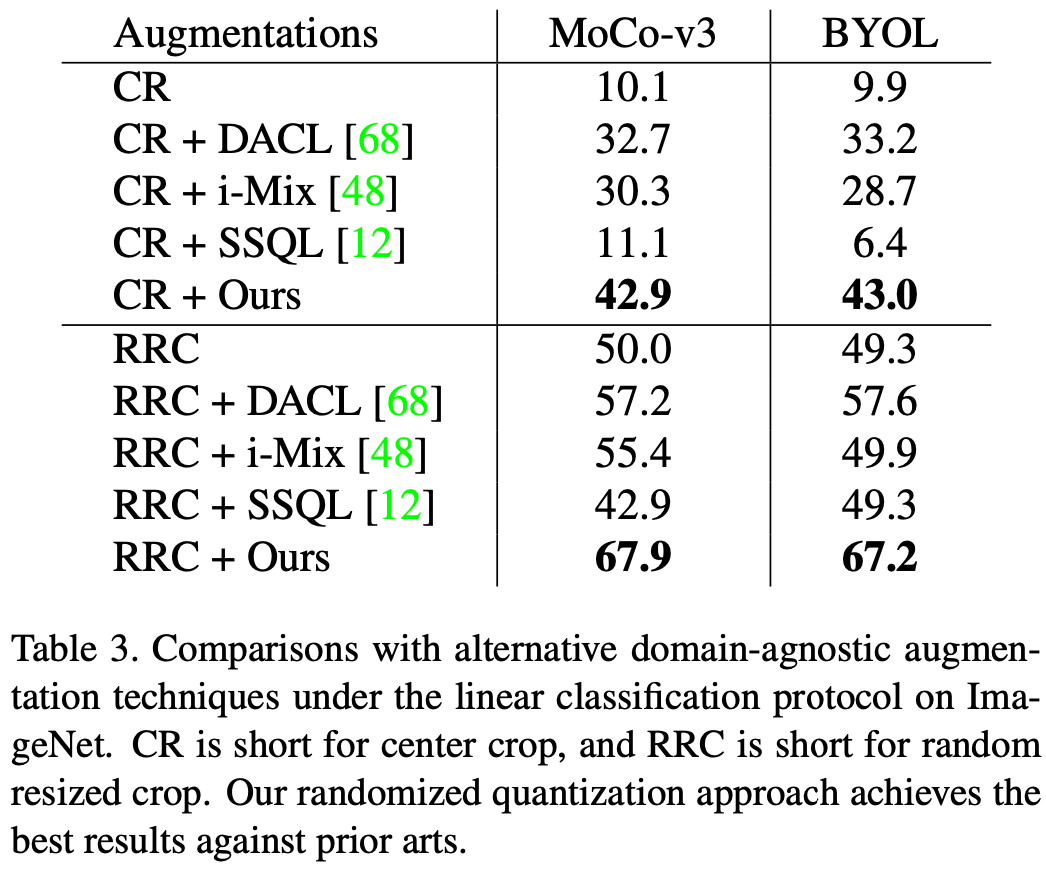
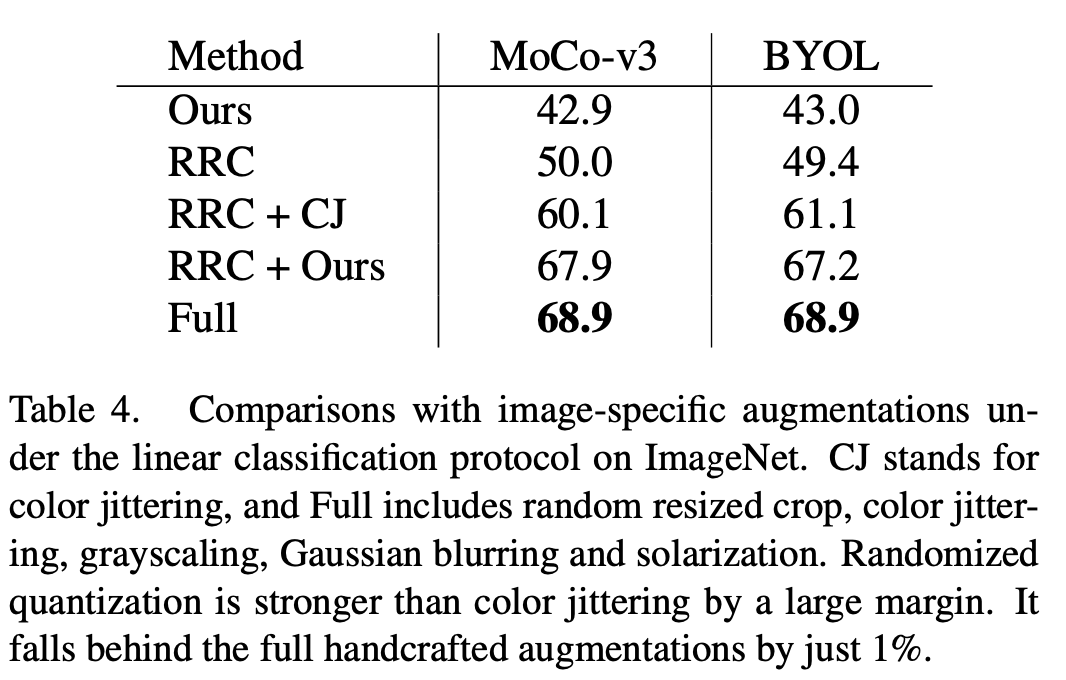
相比于已有的針對圖像數據開發的數據增強方式,例如 color jittering (CJ),本文的方法有著明顯的性能優勢。同時,該方法也可以取代 MoCo-v3/BYOL 中一系列復雜的數據增強方式(Full),包括顏色抖動(color jittering)、隨機灰度化(gray scale)、隨機高斯模糊(Gaussian blur)、隨機曝光(solarization),并達到與復雜數據增強方式類似的效果。
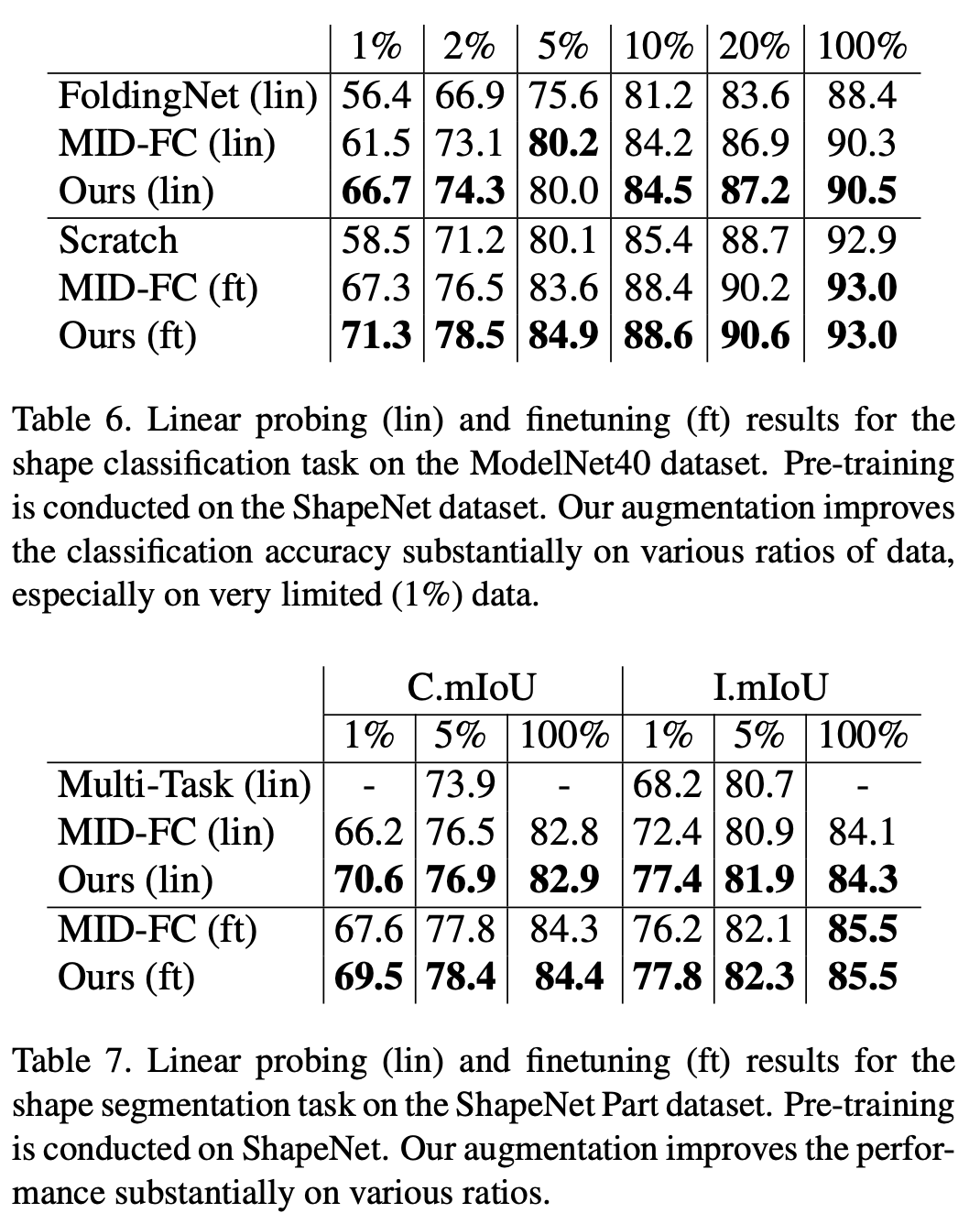
模態 2:3D 點云 本文還在 ModelNet40 數據集的分類任務和 ShapeNet Part 數據集的分割任務上驗證了 randomized quantization 相對于已有自監督工作的優越性。尤其在下游訓練集數據量較少的情況下,本文的方法顯著超過已有點云自監督算法。
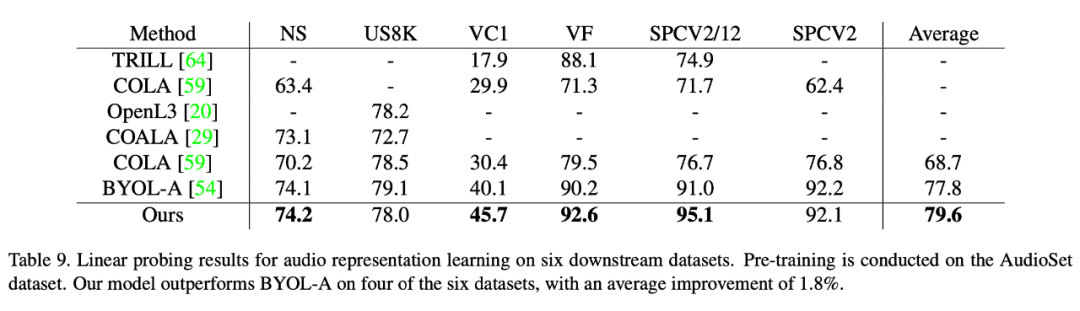
模態 3:語音 在語音數據集上本文的方法也取得了比已有自監督學習方法更優的性能。本文在六個下游數據集上驗證了該方法的優越性,其中在最難的數據集 VoxCeleb1 上(包含最多且遠超其他數據集的類別個數),本文方法取得了顯著的性能提升(5.6 個點)。
模態 4:DABS DABS 是一個模態通用自監督學習的基準,涵蓋了多種模態數據,包括自然圖像、文本、語音、傳感器數據、醫學圖像、圖文等。在 DABS 涵蓋的多種不同模態數據上,我們的方法也優于已有的任意模態自監督學習方式。

審核編輯:彭菁
-
傳感器
+關注
關注
2553文章
51407瀏覽量
756631 -
數據
+關注
關注
8文章
7145瀏覽量
89584 -
模態
+關注
關注
0文章
9瀏覽量
6276 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46130
原文標題:ICCV 2023?|?通用數據增強技術,隨機量化適用于任意數據模態
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于transformer和自監督學習的路面異常檢測方法分享

你想要的機器學習課程筆記在這:主要討論監督學習和無監督學習
機器學習算法中有監督和無監督學習的區別
自監督學習與Transformer相關論文
半監督學習最基礎的3個概念
為什么半監督學習是機器學習的未來?
半監督學習:比監督學習做的更好

弱監督學習解鎖醫學影像洞察力
半監督學習代碼庫存在的問題與挑戰
通用數據增強技術!適用于任意數據模態的隨機量化





 工商網監
工商網監
評論