") 如何權(quán)衡可靠性和SSD使用壽命?
如何權(quán)衡可靠性和SSD使用壽命?
01背景及動(dòng)機(jī)
3D閃存架構(gòu)中的制程差異增加了壞塊管理的難度。由于不同塊之間的錯(cuò)誤特征不同,現(xiàn)有的基于P/E次數(shù)的壞塊管理策略下,很難確定合適的P/E閾值。若P/E設(shè)置激進(jìn),則增加數(shù)據(jù)丟失的可能性;若P/E設(shè)置保守,則無法充分利用強(qiáng)可靠性閃存塊的壽命,從而降低了SSD的整體使用壽命。本文探討的壞塊管理,本質(zhì)是如何權(quán)衡可靠性和SSD使用壽命?
一個(gè)理想的壞塊管理策略是在一個(gè)塊失敗之前立即退役,關(guān)鍵是能夠準(zhǔn)確地預(yù)測(cè)閃存塊何時(shí)接近其生命周期的末端。
在本文中,利用閃存塊之間的空間相關(guān)性劃分集群,以集群為粒度進(jìn)行壞塊管理。如果在塊級(jí)存在空間相關(guān)性,那么一個(gè)塊的失效是其相鄰塊近期失效的有力指標(biāo)。本文在海力士3D TLC閃存上進(jìn)行可靠性實(shí)驗(yàn),分析相鄰閃存塊之間的錯(cuò)誤特征,并且表明存在集群相似性,即物理接近的閃存塊具有相似的錯(cuò)誤特征。
02集群相似性
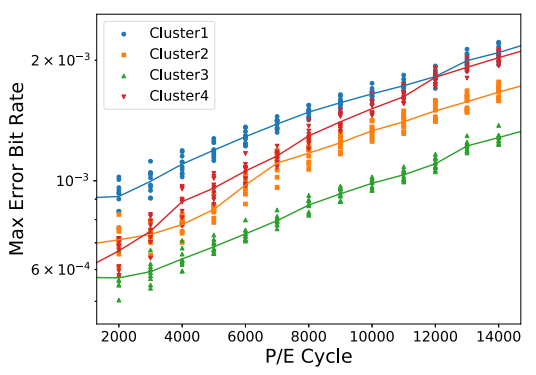
實(shí)驗(yàn)設(shè)置:從10塊海力士TLC閃存選取40個(gè)cluster,每個(gè)cluster的選取采用同個(gè)plane中的連續(xù)10個(gè)塊。對(duì)這些塊執(zhí)行編程隨機(jī)數(shù)據(jù),然后執(zhí)行擦除,循環(huán)直到報(bào)廢。擦除之前數(shù)據(jù)的dwell time為10s。收集對(duì)應(yīng)P/E下的比特錯(cuò)誤率。
結(jié)論:1)對(duì)于不同集群中的塊,在P/E周期中的比特錯(cuò)誤率趨勢(shì)可能非常不同;2)對(duì)于同一集群中的塊,比特錯(cuò)誤率趨勢(shì)更加相似,即存在集群相似性。
03基于集群的壞塊管理
基于集群相似性,提出了一種基于集群的壞塊管理策略。集群中的閃存塊可靠性及在P/E影響下錯(cuò)誤率趨勢(shì)具有相似性。也就是說,在壞塊管理時(shí),當(dāng)其中一個(gè)閃存塊成為壞塊時(shí),整個(gè)集群中的閃存塊全部標(biāo)記為壞塊。通過這種集群相似性特征來管理壞塊,可以及時(shí)標(biāo)記壞塊,從而在確保可靠性的前提下,盡可能提升閃存壽命。
提出的基于集群的壞塊管理策略有兩個(gè)關(guān)鍵設(shè)計(jì)問題。
1) 集群大小的選擇。集群大小決定了SSD壽命和可靠性之間的權(quán)衡。更大的集群大小會(huì)導(dǎo)致更低的故障率(更加保守,并不能完全耗盡每一個(gè)閃存塊的壽命),但會(huì)以更短的SSD壽命為代價(jià)。如何選擇集群相似度強(qiáng)的集群大小,在不犧牲SSD壽命的情況下保證可靠性,對(duì)于基于集群的壞塊管理機(jī)制的有效性至關(guān)重要。為此,本文提出了一個(gè)度量標(biāo)準(zhǔn)來量化集群的相似性,并推導(dǎo)出閃存塊故障率和集群大小之間的相關(guān)性。因此,給定集群大小的可靠性和SSD壽命之間的權(quán)衡可以被定量地評(píng)估。
2) 集群退役時(shí)對(duì)I/O性能的影響。集群退役的時(shí)候,該集群的所有有效數(shù)據(jù)需要拷貝到其他集群。由于集群退役而導(dǎo)致的讀寫突發(fā)可能會(huì)干擾用戶的I/O請(qǐng)求。為了解決這一問題,本文提出了一種關(guān)鍵塊優(yōu)先調(diào)度策略,當(dāng)集群中某個(gè)塊標(biāo)記為壞塊時(shí),該塊的數(shù)據(jù)遷移優(yōu)先級(jí)高于用戶請(qǐng)求。集群中其余塊在之后SSD空閑時(shí),執(zhí)行關(guān)聯(lián)的讀寫操作。因此,可以盡量減少集群退役時(shí)的性能影響。
04實(shí)驗(yàn)測(cè)試
實(shí)驗(yàn)一:對(duì)比基于集群的管理方法和基于塊的管理方法
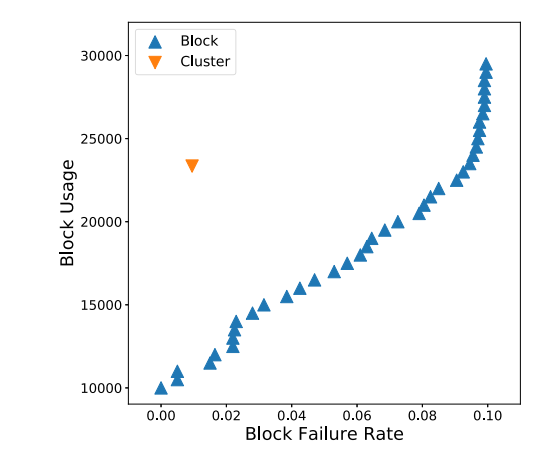
權(quán)衡Block usage和Block failure rate。其中,?Block? usage指的是被定義為在SSD不再可用之前所承受的平均P/E。Block failure rate定義為發(fā)生塊故障的塊的比例。
當(dāng)P/E次數(shù)增加時(shí),塊的使用情況和塊的故障率都會(huì)上升。基于集群的塊管理方法中,可以實(shí)現(xiàn)23000P/E次數(shù),并實(shí)現(xiàn)block failure rate為0.01。對(duì)于基于塊的管理方法,當(dāng)確保塊失敗率為0.01時(shí),P/E僅為11000。如果要實(shí)現(xiàn)23000P/E,塊失敗率為0.09。這表明,所提出的基于集群相似性的方法在塊使用和塊故障率之間實(shí)現(xiàn)了更好的權(quán)衡。
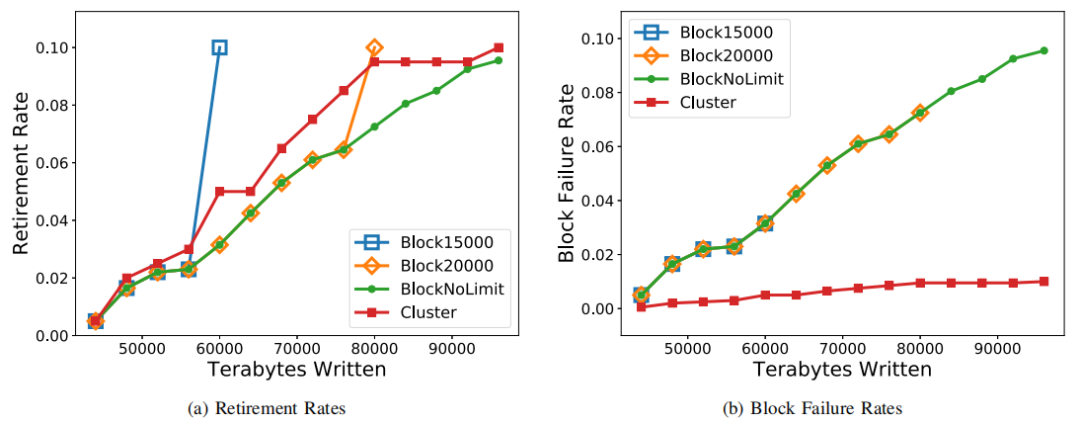
為了進(jìn)行更詳細(xì)的分析,從塊管理策略中選擇以下設(shè)置,以查看塊退休率和塊故障率如何隨時(shí)間變化。
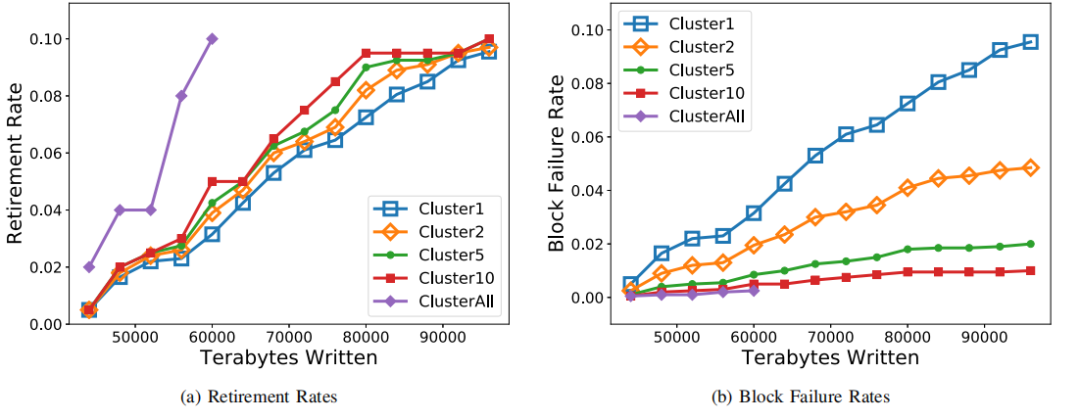
不同的集群大小如何影響基于集群的管理策略?圖8展示了塊退休率和塊故障率隨時(shí)間變化趨勢(shì)。評(píng)估了五種不同的集群大小,包括1、2、5、10,以及clusterAll表示同一芯片內(nèi)的所有塊視為單個(gè)集群。注意,cluster1相當(dāng)于BlockNoLimit,clusterALL代表集群很大。
當(dāng)集群大小增加時(shí),壽命降低。然而,對(duì)于集群大小為1、2、5、10,差異不顯著。這是因?yàn)楫?dāng)集群大小等于10時(shí),集群相似性仍然很強(qiáng)。
隨著集群大小的增加,塊故障率減小。當(dāng)集群大小等于10時(shí),塊故障率已經(jīng)小于0.01。因此,沒有必要選擇一個(gè)更大的集群大小。
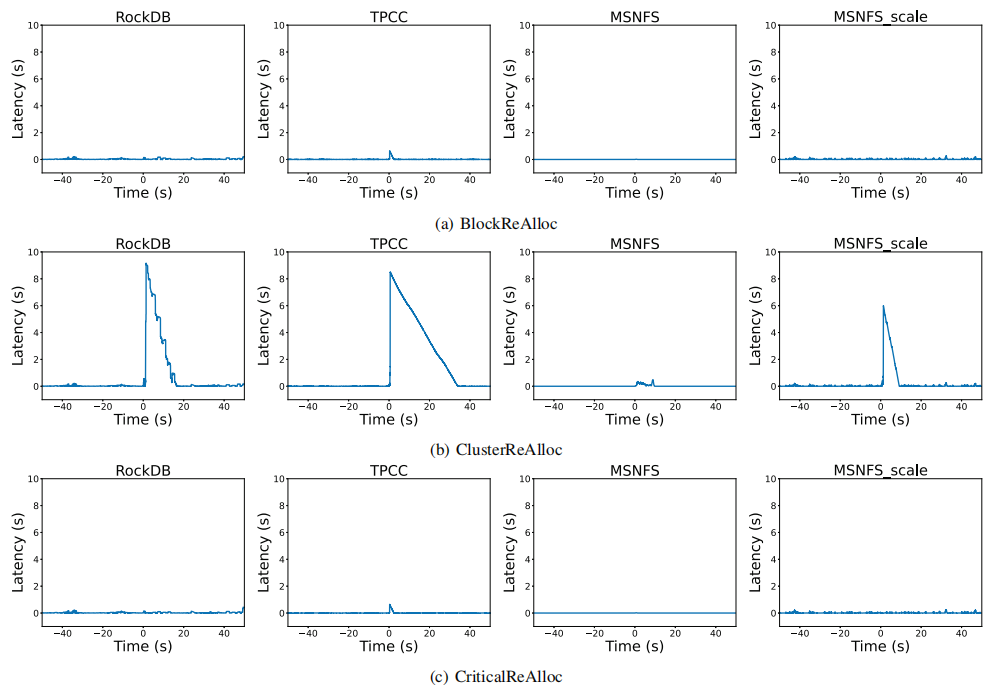
實(shí)驗(yàn)二:測(cè)試數(shù)據(jù)重新分配的性能情況
比較了基于集群管理策略與基于塊管理策略的I/O性能。該實(shí)驗(yàn)表明,通過關(guān)鍵塊優(yōu)先分配調(diào)度可以減輕基于集群管理策略的I/O影響。下圖表示塊退役前后的I/O延遲。x軸表示分析時(shí)間和塊退役之間的時(shí)間差,從塊退役前50秒到塊退役后50秒。y軸表示每1000個(gè)請(qǐng)求的平均I/O延遲。可以看到,基于集群的方法會(huì)引入延遲尖峰。而關(guān)鍵塊優(yōu)先分配解決了此問題。
05總結(jié)
本文發(fā)現(xiàn)物理接近的閃存塊間存在相似的誤差特征(集群相似性),提出一種基于集群的壞塊管理方式,確保閃存可靠性的前提下,提升閃存壽命。考慮到基于集群的管理下,集群退役引起的I/O性能問題,本文還提供了一種針對(duì)壞塊重新分配的關(guān)鍵塊優(yōu)先調(diào)度方法。實(shí)驗(yàn)表明所提出的方法可以延長閃存壽命2倍,而不會(huì)有任何I/O性能下降。
審核編輯:劉清
-
SSD
+關(guān)注
關(guān)注
21文章
2887瀏覽量
117858 -
TLC
+關(guān)注
關(guān)注
0文章
136瀏覽量
51615 -
延遲器
+關(guān)注
關(guān)注
0文章
5瀏覽量
6713
原文標(biāo)題:如何解決閃存制程差異下的壞塊管理問題?
文章出處:【微信號(hào):SSDFans,微信公眾號(hào):SSDFans】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深度解讀企業(yè)級(jí)SSD的可靠性意義
#硬聲創(chuàng)作季 #可靠性 電子封裝可靠性評(píng)價(jià)中的實(shí)驗(yàn)力學(xué)方法-3

#硬聲創(chuàng)作季 #可靠性 電子封裝可靠性評(píng)價(jià)中的實(shí)驗(yàn)力學(xué)方法-5
#硬聲創(chuàng)作季 #可靠性 電子封裝可靠性評(píng)價(jià)中的實(shí)驗(yàn)力學(xué)方法-6
可靠性是什么?
LED加速壽命和可靠性試驗(yàn)
可靠性設(shè)計(jì)分析系統(tǒng)
采用nvSRAM確保企業(yè)級(jí)SSD故障時(shí)電源可靠性
六類可靠性試驗(yàn)的異同,終于搞懂了!
什么是高可靠性?
C&K高可靠性鍵盤開關(guān) 面向需要長使用壽命的應(yīng)用
壽命試驗(yàn)的可靠性測(cè)試詳解
西數(shù)推出企業(yè)級(jí)TLC SSD 壽命和可靠性都是頂級(jí)的存在
SSD的可靠性可靠性量化指標(biāo)MTBF





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論