 首篇!Point-In-Context:探索用于3D點云理解的上下文學習
首篇!Point-In-Context:探索用于3D點云理解的上下文學習
前言:
本文是第一篇將NLP領域中的In-Context Learning(ICL)引入3D點云理解的文章。該文首次提出將ICL應用于多任務3D點云模型Point-In-Context(PIC),實現一個模型一次訓練,適應多種任務,驗證了ICL在3D點云中的可行性。同時,該文為in-context learning定義一個統一的衡量基準,涵蓋幾種常見的點云任務,并構建了常見點云分析算法的多任務模型baseline。最后該文進行了大量的實驗,PIC在3D點云多任務處理上達到了SOTA的效果,并且驗證了PIC可以通過選擇更高質量的prompt來提升效果甚至超越特定于單一任務的模型,為未來3D點云中ICL的研究方向開拓了方向。
摘要:
隨著基于廣泛數據訓練的大模型興起,上下文學習(In-Context Learning)已成為一種新的學習范式,在自然語言處理(NLP)和計算機視覺(CV)任務中表現出了巨大的潛力。與此同時,在3D點云(Point Cloud)領域中,上下文學習在很大程度上仍未得到探索。盡管掩碼建模(Masked Modeling)訓練策略已經成功應用于2D視覺中的上下文學習,但將其直接擴展到3D點云上仍然是一個艱巨的挑戰。因為在點云的情況下,tokens本身就是在訓練過程中被掩蓋的點云位置(坐標)。此外,先前一些工作中的位置嵌入(Position Embedding)方式可能會無意中導致目標點云產生信息泄漏。為了應對這些挑戰,作者提出了一個專為3D點云上下文學習而設計的新型框架Point-In-Context(PIC),且將每個任務的輸入和輸出都建模為點的三維坐標。其中,作者提出的聯合采樣(Joint Sampling)模塊與通用點采樣算子協同工作,有效解決了上述技術問題(信息泄露)。最后作者進行了大量的實驗,以驗證Point-In-Context在處理多任務時的多功能性和適應性。此外,作者還證明了Point-In-Context可以通過采用更有效的提示(Prompt)選擇策略,生成更精確的結果并超越單獨訓練的模型。
論文和開源倉庫的地址:

論文題目:Explore In-Context Learning for 3D Point Cloud Understanding
發表單位:中山大學,南洋理工大學,蘇黎世聯邦理工學院,北京大學
論文地址:https://arxiv.org/pdf/2306.08659.pdf
項目地址:https://github.com/fanglaosi/Point-In-Context
提交時間:2023年6月14日
1. 背景介紹
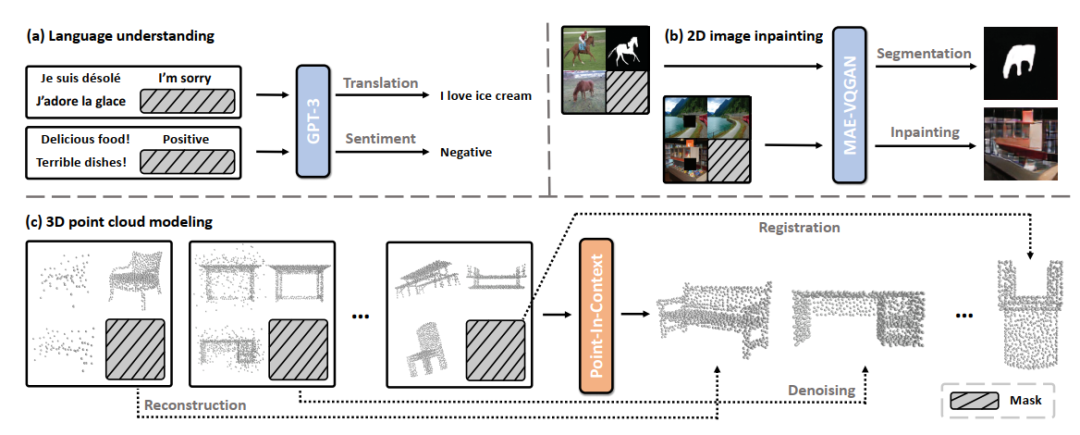
圖1 In-Context Learning應用于多任務處理的示意圖
In-Context Learning(ICL)源于自然語言處理(NLP),通過將特定于任務的輸入-輸出對(Prompt)合并到一個測試示例中,再輸入到模型中進行處理,從而獲得對應任務的輸出,如圖1(a)所示。最近在2D圖像領域基于ICL的工作主要采用掩碼圖像建模(Masked Image Modeling)訓練策略進行上下文任務提示,如圖1(b)所示。然而,目前還沒有研究探索使用掩碼點建模框架理解3D點云的In-Context Learning。
對于Masked Modeling訓練策略,前期的研究主要集中在自然語言處理中的GPT和BERT系列模型以及2D圖像領域的BEiT和MAE等。這些方法通過掩碼建模和下游任務微調顯著提升了自然語言處理和圖像處理的性能。在3D點云領域,Point-BERT和Point-MAE等方法采用了類似的思路,使用Transformer和掩碼點建模來處理3D點云數據,并在各種下游任務上取得了競爭性的性能。
本文的方法基于Masked Point Modeling(MPM)框架,探索了Transformer和MPM的結合,以實現3D點云領域的In-Context Learning。與之前的研究不同,本文的方法首次探索了3D prompt對3D點云中In-Context Learning的影響,并為3D點云中In-Context Learning的基準測試提出了新的baseline。
本文是第一個將In-Context Learning應用于3D點云領域的工作,并提出了一個適應于多種常見點云任務的多任務框架Point-In-Context。它通過上下文任務提示可以調節模型的輸入和輸出,適應不可見任務的推理。本文探索了在3D點云領域應用In-Context Learning的方法,強調了其在點云領域的創新性和首創性,為進一步推動3D點云領域的研究和應用提供了新的方向和參考。
2. 研究方法
2.13 3D點云中的ICL建模
受2D圖像中的ICL啟發,作者設計了一個3D視覺的ICL范式。在訓練過程中,每個輸入樣本包含兩對點云:示例對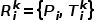 和查詢輸入對
和查詢輸入對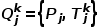 。每對點云由一個輸入點云及其相應的輸出點云組成。與PointMAE類似,作者采用FPS和KNN技術,將點云轉換為類似句子的數據格式后利用Transformer進行Masked Point Modeling任務。在推理過程中,輸入點云是示例輸入點云和查詢點云,而目標點云由一個示例目標和掩碼標記組成,如圖1(c)所示。基于不同的
。每對點云由一個輸入點云及其相應的輸出點云組成。與PointMAE類似,作者采用FPS和KNN技術,將點云轉換為類似句子的數據格式后利用Transformer進行Masked Point Modeling任務。在推理過程中,輸入點云是示例輸入點云和查詢點云,而目標點云由一個示例目標和掩碼標記組成,如圖1(c)所示。基于不同的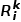 ,給定查詢點云
,給定查詢點云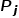 ,模型輸出相應的目標
,模型輸出相應的目標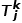 。
。
2.2 數據集及任務定義
由于先前的工作中沒有研究過3D的ICL,所以作者以ShapeNet和ShapeNetPart數據集為基礎定義了新的benchmark,包含四種常見的點云任務:點云重建,點云去噪,點云配準和部件分割。并且將這四種任務的輸入輸出空間都統一到XYZ坐標空間當中。
點云重建的目的是由極其稀疏的點云重建成稠密的完整點云。本文設置了5個重建等級作為評價標準,分別是當輸入點云為512,256,128,64和32個點時,點數越少,重建難度越高。點云去噪任務中的輸入點云包含符合正態分布的高斯噪聲點,要求模型去除噪聲點,同時設立了5個等級的噪聲干擾,噪聲點數量范圍從100到500。重建和去噪的任務輸出是一個干凈,正立的點云,為了將點云配準任務的目標點云與前兩個任務解耦,本文將配準任務的輸出設為干凈,倒立的點云。
部件分割任務的目的是給每個點分配一個部件標簽,作者將其輸出空間的50個部件標簽抽象為均分分布在立方體內的50個點,每個點代表不同的部件。因此部件分割任務的輸出是聚類到不同中心的點簇,輸出點簇的數量由部件數量決定。
2.3 Point-In-Context
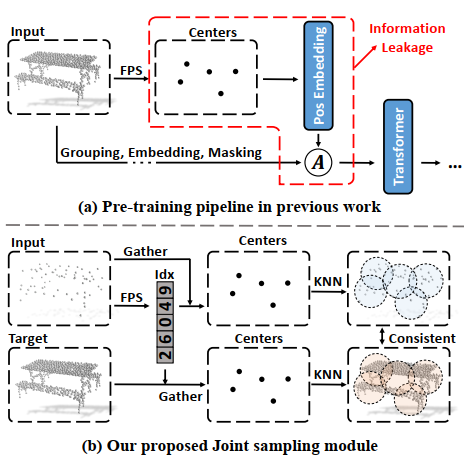
圖2 信息泄露問題及解決方案(聯合采樣模塊)
信息泄露。雖然MPM是我們的一個基本框架,但簡單地將其應用于點云是不可行的。如圖2(a)所示,之前工作中預訓練時會嵌入了所有patch的中心點坐標(即位置信息),即使是那些被屏蔽(不可見)的patch。由于在目標中被屏蔽的patch在我們的設置中是不可見的,所以這樣的操作會導致信息泄漏,從而不滿足要求。此外,我們還發現,與學習到的嵌入相比,正弦-余弦編碼序列會顯著降低模型的性能,甚至會導致訓練的崩潰。原因是缺少有價值的位置信息,使得模型無法在處理過程中找到需要重建的patch。與2D圖像不同,3D點云patch序列沒有固定的位置,因此我們需要對由輸入點云和目標點云生成的patch序列進行對齊。
聯合采樣模塊。為了處理上述問題,我們從每個輸入點云中收集N個中心點,并檢索它們的索引,然后我們使用這些索引來獲取輸入點云和目標點云中每個patch的中心點。該過程如圖2(b)所示,我們的JS模塊的關鍵是在保持目標點云和輸入點云中對應patch的中心點索引。換句話說,輸入序列和目標序列的順序是良好對齊的。這種設計補償了目標位置嵌入的缺失,避免信息泄露。因此,它有助于使模型學習輸入和目標之間的內在關聯,并簡化了學習過程。隨后,所有點云根據每個斑塊對應的中心點搜索包含M個相鄰點的鄰域。

圖3 Point-In-Context的兩種輸入形式
PIC-Sep和PIC-Cat。如圖3所示,我們定義了兩種輸入形式,對應PIC的兩種形式,分別是PIC-Sep和PIC-Cat。對于PIC-Sep,我們將輸入點云和帶有掩碼的目標點云平行輸入到Transformer中,然后在幾個block之后使用一個簡單的平均值進行融合操作合并它們的特征。對于PIC-Cat,我們將輸入和目標連接起來,形成一個新的點云。然后我們在整體上進行掩碼操作,并將其輸入到Transformer中進行預測。
我們將prompt表示為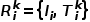 ,將查詢輸入表示為
,將查詢輸入表示為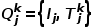 ,然后PIC-Sep和PIC-Cat可以公式化為:
,然后PIC-Sep和PIC-Cat可以公式化為:
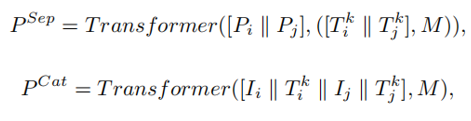
其中 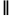 代表Concat操作,
代表Concat操作,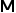 代表用來代替可見token的掩碼token。
代表用來代替可見token的掩碼token。
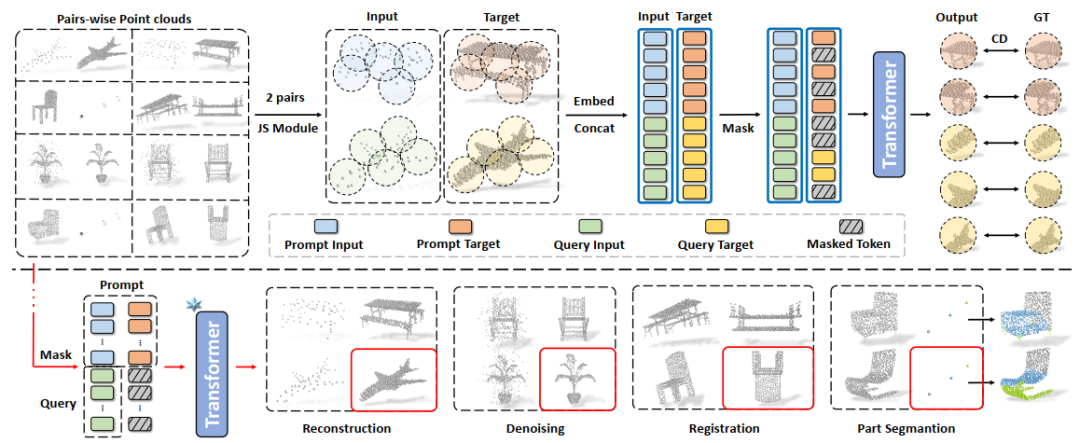
圖4 PIC-Sep的總體方案
總體流程如圖4所示(以PIC-Sep為例)。我們使用一個標準的具有編碼器-解碼器結構的Transformer作為我們的主干網絡,和一個簡單的1×1卷積層作為點云重建的任務頭。頂部:MPM框架的訓練框架。在訓練過程中,每個樣本包含兩對輸入和目標點云,它們被輸入到Transformer中執行掩碼點重建任務。底部:關于多任務的in-context inference。我們的PIC可以推斷出各種下游點云任務的結果,包括點云重建、去噪、配準和部件分割。
損失函數。該模型的訓練目的是重建出被掩蔽掉的點。為此,我們使用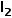 Chamfer Distance作為訓練損失。
Chamfer Distance作為訓練損失。
3.實驗結果
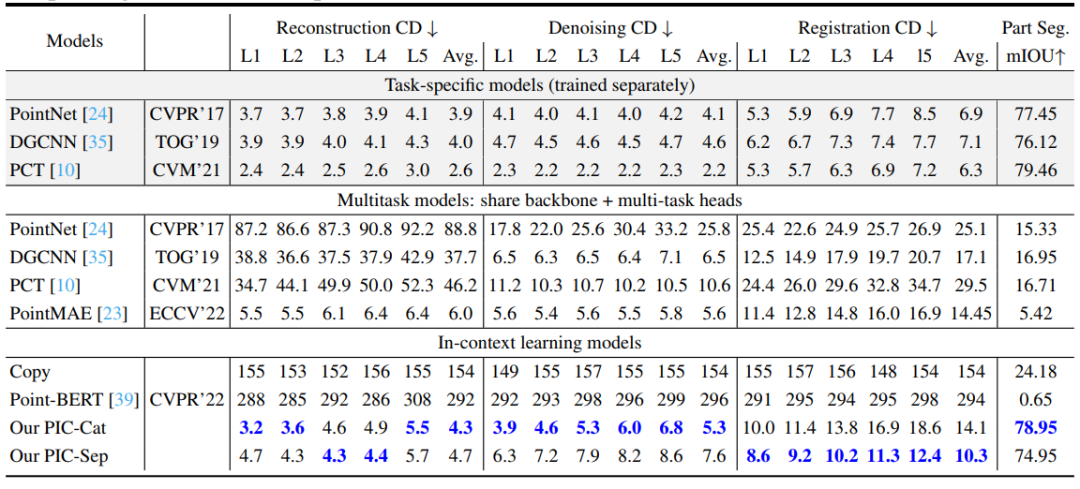
表1 主要實驗結果對比
作者在四個常見點云任務上進行了實驗,分別對比了特定于任務的模型、多任務模型和In-context learning模型。對于重建、去噪和配準,本文報告了CD距離損失(x1000)。對于部分分割,報告了mIOU。由表可見,本文的PIC-Cat和PIC-Sep表現出了令人印象深刻的結果,并且僅在一次訓練后就能夠適應不同的任務,在于多任務模型的比較中都取得了最先進的結果。
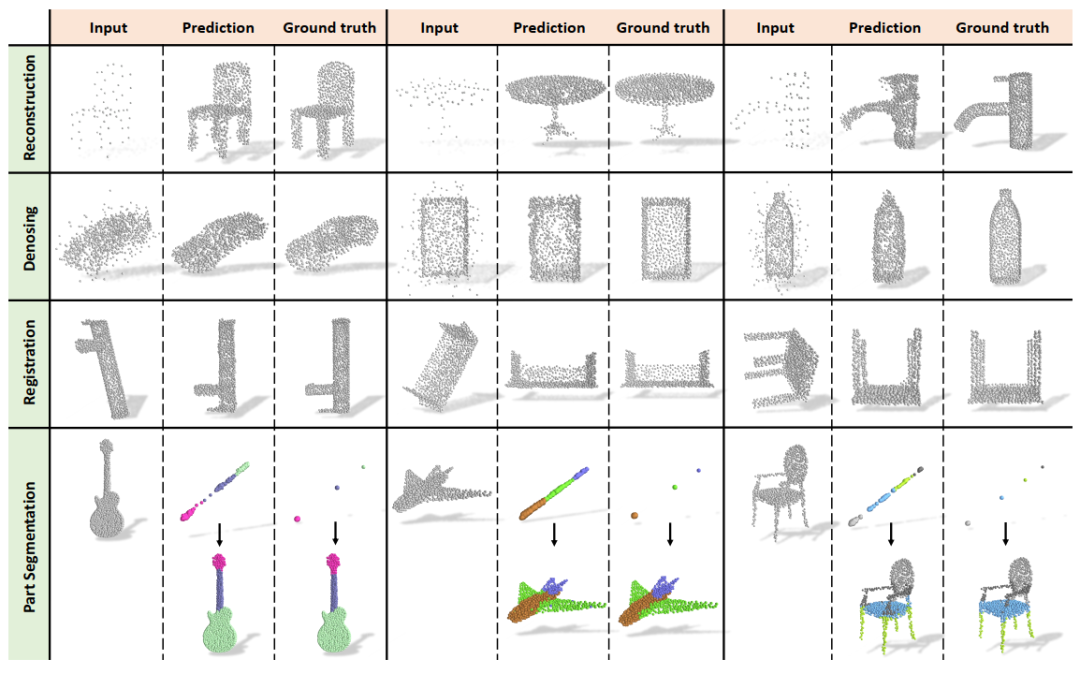
圖5 可視化結果
此外,本文還可視化了PIC-Sep的輸出結果,PIC-Sep可以在重構、去噪、配準和部分分割等四個任務中生成相應的預測。對于部分分割任務,我們將生成的目標和映射目標一起可視化,兩者都添加了類別的顏色,以便更好地比較。
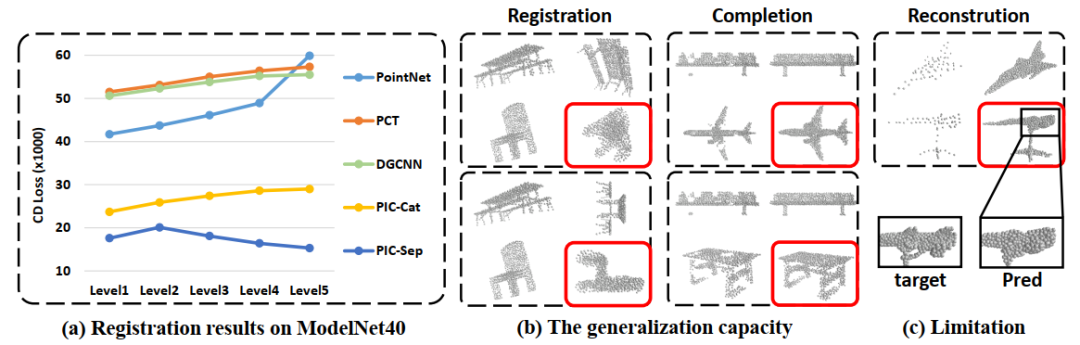
圖6 泛化能力。(a)在ModelNet40上進行點云配準任務的結果(b)泛化到新任務上
通常,In-Context Learning具有一定程度的泛化能力,從而允許模型快速適應不同的任務。這也適用于我們的模型。首先,本文通過對ModelNet40數據集進行配準評估,在分布外點云上測試了所提出的方法。如圖6(a)所示,PIC-Sep和PIC-Cat在開放類任務上都表現出優于專門訓練的監督學習模型。我們將其與在單個任務上訓練的模型進行了比較,如PointNet、DGCNN和PCT。當轉移到新的數據集時,這些模型的性能明顯下降。難度越大(旋轉水平越高),下降量就越多。
此外,本文還驗證了它們在未知任務上的泛化能力,如任意角度配準的和局部補全。如圖6(b)所示,PIC在這兩個任務上都表現得很好,驗證了它們轉移學習知識的能力。
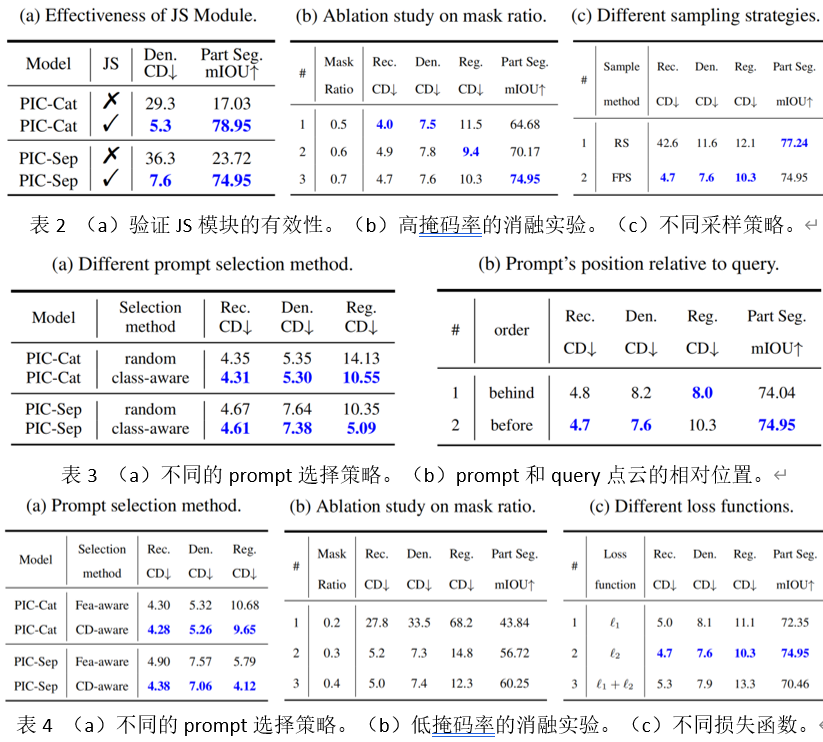
本文進行了大量的消融實驗。其中應該特別注意的是,在表2(a)和表4(a)中作者初步探索了四種不同的prompt選擇策略對于結果的影響。除了隨機選擇的方案,另外三種方案的結果都比默認的方案效果好。這也體現出in-context learning巨大的潛力,這說明PIC可以通過選擇更加適合的prompt來提升在點云任務上的性能。甚至,PIC-Sep在CD-aware策略的點云配準任務上超越了表1中的三種特定于任務的模型。
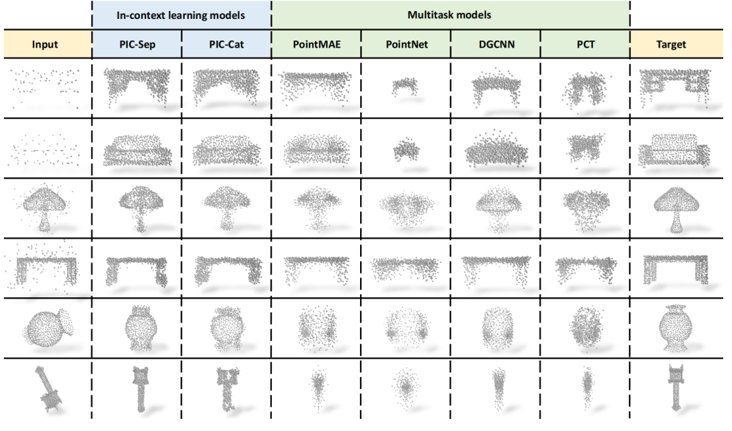
圖7 PIC與多任務模型比較結果的可視化
4. 未來展望
本文提出了第一個采用In-Context Learning范式來理解3D點云的框架,Point-In-Context。并且建立了一個包含四個基本任務的大規模點云對數據集,以驗證in-context能力。PIC具有良好的學習能力,它對分布外的樣本和不可見的任務具有良好的泛化能力。同時,通過選擇更高質量的prompt,可以激發出PIC中巨大的潛力,甚至超越特定于一個任務的模型。它為進一步探索三維模式中的In-Context Learning開拓了探索方向。由于時間和計算資源有限,本文沒有進行更多的實驗,如提升模型的生成結果的精細度和在大規模場景分割點云數據集上進行實驗。這將是未來會繼續研究的方向。
-
計算機視覺
+關注
關注
8文章
1700瀏覽量
46126 -
數據集
+關注
關注
4文章
1209瀏覽量
24830 -
點云
+關注
關注
0文章
58瀏覽量
3820
原文標題:首篇!Point-In-Context:探索用于3D點云理解的上下文學習
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
為什么transformer性能這么好?Transformer的上下文學習能力是哪來的?
關于進程上下文、中斷上下文及原子上下文的一些概念理解
無頭EGL上下文似乎不使用Capture SDK ?
進程上下文與中斷上下文的理解
ucos上下文該怎么切換?
中斷中的上下文切換詳解
基于交互上下文的預測方法
基于Pocket PC的上下文菜單實現
基于Pocket PC的上下文菜單實現
基于上下文相似度的分解推薦算法
初學OpenGL:什么是繪制上下文
如何分析Linux CPU上下文切換問題
谷歌新作SPAE:GPT等大語言模型可以通過上下文學習解決視覺任務

鴻蒙Ability Kit(程序框架服務)【應用上下文Context】





 工商網監
工商網監
評論