 如何取替英偉達?如何顛覆英偉達?
如何取替英偉達?如何顛覆英偉達?
隨著生成式AI的火熱以及英偉達市值沖破萬億美元,如何取替英偉達,成為AI芯片市場新貴,又成為了一個熱門話題。
以下為文章原文摘錄:
看到英偉達這個萬億美元的市值,我想沒有任何人敢說他不想要。。。。。。想要,就得琢磨琢磨怎么才能造他娘的反。
王侯將相寧有種乎!
你得盤個邏輯,提個口號才能舉旗,得想辦法證明舊社會的不足和新社會的先進性才有機會。
不知道多少人分析過Nvidia的GPU的成本,我們以最新的Hopper H100為例。大致上,為了跑AI大模型,你從Nvidia手上購買到的是如下這樣的一張卡,他叫做SXM5模組,單手就能拿捏的樣子。
這個模組附帶了大量的供電VRM,也通常會使用相對高階的PCB保證供電的銅損最小。最中間的差不多就是一顆Hopper GPU芯片,看得出由7顆Die用chiplet方式封裝,分別是1顆logic Die和6顆HBM。
把他的成本打開,SXM的成本不會高于300$,封裝的Substrate及CoWoS大約也需要$300,中間的Logic Die最大顆,這是一顆看起來非常高貴的die,使用4nm工藝打,尺寸為814mm2,TSMC一張12英寸Wafer大致上可以制造大約60顆這個尺寸的Die,Nvidia在Partial Good上一向做得很好(他幾乎不賣Full Good),所以這60顆大致能有50顆可用,Nvidia是大客戶,從TSMC手上拿到的價格大約是$15000,所以這個高貴的Die大約只需要$300。哦,只剩下HBM了,當前DRAM市場疲軟得都快要死掉一家的鬼樣了,即使是HBM3大抵都是虧本在賣,差不多只需要$15/GB,嗯,80GB的容量成本是$1200。
你掐指一算……
凸(艸皿艸 ),你花錢到底買到的是什么?這居然是一個投機倒把倒賣DRAM的貨,整顆GPU物料成本中DRAM占了~60%,而且這DRAM的容量,80GB,它是個啥?夠個屁啊,老黃還騙我買8張卡來存放一個GPT3大模型。
高貴的黃教主啊,想不到你是個高價倒賣DRAM的二手販子啊........Grace把LPDDR也集成進去了,是不是這集成的LPDDR不得也比標準DDR DIMM貴個幾倍?
所以,要革Nvidia命的第一步,就應該從DRAM出手,如果我做把DRAM成本做到更合理的結構,并且再把容量做大到更少的芯片數量就能存放大模型。
這天,我能翻。
就前幾天,聰明絕頂的GraphCore聯合創始人兼CTO為眾多競爭者指出了一條路,如下:
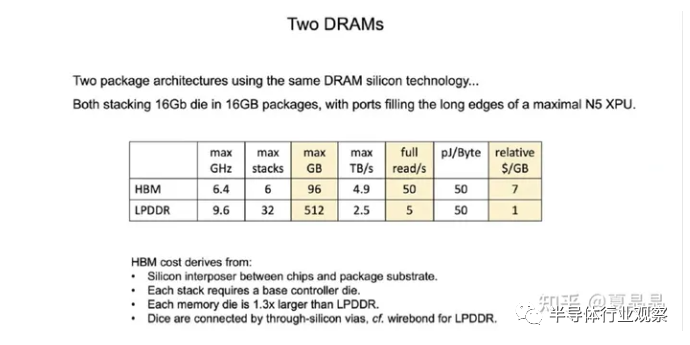
看到沒,LPDDR定制一下是可以做到50% HBM的帶寬,但是容量遠大于HBM的,剩下你只要在AI大模型的存/算帶寬容量比上做到最好就行。
不過。。。。。。。他自己為啥不做?
因為一顆H100 GPGPU雖然成本只有 ~$2000,但它在市場上的售價是 ~$30000,在15倍的暴利面前,你想用降成本的方式來獲取競爭力。嗯,假設你做一顆成本$1000,比H100性價比更高的DSA,能打贏嗎?
客戶他又不是傻子,他愿意用$30000的價格買一個$2000成本的東西,他真的會圖你的成本能再降低$1000 ?
這個巨大的溢價空間,并非源自GPGPU本身,而來自于其背后的巨大黑手,一個復雜的系統,這個系統本身,甚至潛移默化影響了用戶的算法。
Nvidia是一個偽裝成賣Device,但真實是在賣一個system的公司。Apple也是。
只有打掉這個系統才有可能破解其成本,想一想,iOS有Android,Windows有Linux,cuda卻沒有開源路徑……
一計不成,再生一計。我再治他一個system的閹人之罪。
回到中國本土市場,你注意到老黃最近在呼吁,美國政府對中國的技術管制要三思而后行。嗯,網傳老黃差點就來大陸炒光模塊的A股了。
邏輯是沒問題的,美國的技術管制大概率Nvidia是參與了,所以他才那么在美國發布管制時,第一時間推出了A800、H800這樣的數字對中國人是好意頭的芯片型號,這種體貼AMD蘇媽媽就慢了一拍(蘇媽媽推出了mi388……)。
美國技術管制的約束大致是芯片總帶寬要小于600GB/s(雙向)。
GPU A100的Nvlink帶寬是600GB/s,考慮到PCIe不能裁,A800的Nvlink被限制到400GB/s(12Lane降低到8Lane)。
這還好,灑灑水啦。
H100相比A100算力FP16從300T增加到接近1P,Nvlink帶寬從600GB/s提升到900GB/s,咔嚓一刀,H800的Nvlink帶寬還是得降低到400GB/s。
有點憋屈,但是我作為驕傲的中國客戶,為了圖8這個吉利,連4這個數字都能忍了。
我記得我列過幾次大模型訓練的結構,以GPT3為例,大致上用1024張A100訓練GPT,8P一個Node,在Node內模型并行, 然后按8個8P(64P)做8級流水并行,然后16組8x8做Batch 16的數據并行。。。。。。
H100的下一代是B100,它的FP16算力大致上從900T提升到了~2P Flops附近。
哦豁,在這個算力下如果B800只有400GB/s的Nvlink帶寬,基本上Tensor并行這個訓練行為就沒法正常執行了,各大廠商走過路過想一下啊,B800你還要再下10億美元的單嗎?
大概Nvidia和US政府定規則的時候,只考慮了Ampere和Hopper,沒把摩爾定律算進去。
所以這個破綻很簡單,壞人不讓我們做的,我們就越要發展。單芯片的IO能力懟上去啊,600GB不夠就上1TB,把互聯做得大大的,8P的模型并行不夠,直接來16P、32P的大互聯。
有人會說:這樣是不是有點不公平?嗯,美國卡中國是公平的,反過來利用一下反而不公平了?如果能給老黃一個猴子偷桃就一定要偷。
黃教主近期在臺北發布了GH200,就有很多黃粉大吹特吹不是?然后呢?這塊芯片的帶寬是超標美國對中國技術管制的……嗯,老黃在中國發布了不能賣給中國的產品。很公平?
還有人會說:如果真這么做了,美國就會放松技術管制了。我只能說,如果你不做,技術管制不會憑空的放開,你只有做了,才有放開的一天。
當然,你說,革命之事,你求的本就是天下,不是一城一池。那是。
Nvidia看長遠,最大的破腚,其實是基尼系數太高,不患貧而患不均。
TSMC曾經講過一個故事。臺灣同胞辛辛苦苦攢錢建廠,一張4nm那么先進的工藝哦,才能賣到$15000,但是那某個客戶拿去噢,能賣出$1500000($30000*50)的貨啦,機車,那樣很討厭耶。你懂我意思嗎?
就如最開始說的,在這個世界的商業規則下,$2000成本的東西賣$30000,只有一家,銷售量還很大,這是不符合邏輯的,這種金母雞得有航母才守得住。
天下財共一石,老黃獨占八斗。
這是對全天下IT產業的傷害,包括TSMC,一個健康的產業,其整個環節是需要一個合理的分配比例的,你要說Logic制造的技術含量最高,但是分成的收益卻不到1%,這種分配關系不足以長期維系,tsmc的工藝演進是需要錢的(靠的就是大家共籌,利益均分),如果全世界IT就這么多錢,英偉達你是可以通過系統優勢拿走更多,但產業鏈中tsmc及其他各個環節就會更加艱難。三星的HBM其實同理,操了白粉的心,賣個白菜的價,不值得。
嗯,不過tsmc沒錢發展工藝對我們也不是壞事。或者說把芯片制造行業打到毛利接近零,那全世界只有中國人能做,也挺好。
摩爾定律之下,長期穩定地擠牙膏才是發展的王道(當然Intel最終也沒擠好,但如果Intel如果過早把牙膏都擠了,死得更早)。
一個人過早獲得了超額的財富,剩下就看他能不能守得住了 :) 從歷史來看,很難的。
AI這個行業,也終將,昔日王榭堂前燕 飛入尋常百姓家。這是大勢。
審核編輯:劉清
-
pcb
+關注
關注
4326文章
23160瀏覽量
399966 -
VRM
+關注
關注
0文章
30瀏覽量
12720 -
英偉達
+關注
關注
22文章
3847瀏覽量
91975 -
AI芯片
+關注
關注
17文章
1906瀏覽量
35216 -
chiplet
+關注
關注
6文章
434瀏覽量
12631
原文標題:如何顛覆英偉達?
文章出處:【微信號:ZYNQ,微信公眾號:ZYNQ】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
剛剛!英偉達最新回應!
英偉達被立案調查 英偉達回應反壟斷調查

英偉達超越蘋果成為市值最高 英偉達取代英特爾加入道指
英偉達市值飆升,逼近蘋果

AI芯片巨頭英偉達漲超4% 英偉達市值暴增7500億






 工商網監
工商網監
評論