 CVPR 2023 | 華科&MSRA新作:基于CLIP的輕量級開放詞匯語義分割架構
CVPR 2023 | 華科&MSRA新作:基于CLIP的輕量級開放詞匯語義分割架構
本文提出了 SAN 框架,用于開放詞匯語義分割。該框架成功地利用了凍結的 CLIP 模型的特征以及端到端的流程,并最大化地采用凍結的 CLIP 模型。

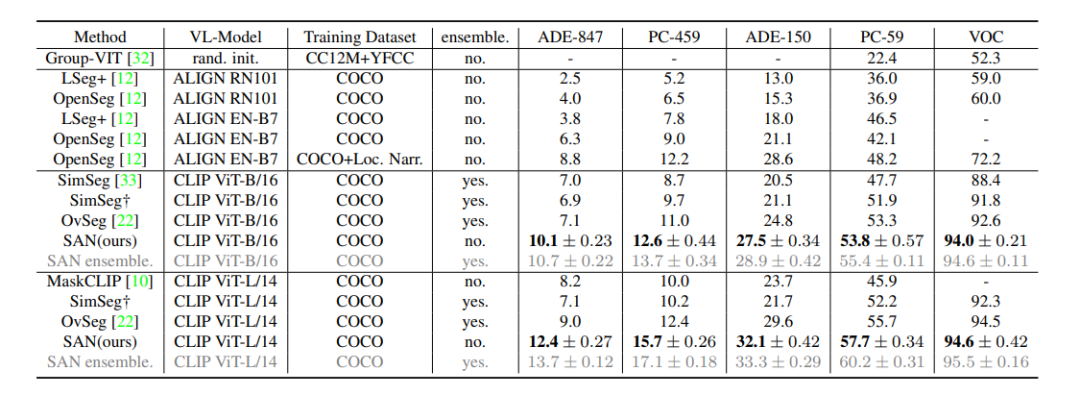
簡介本文介紹了一種名為Side Adapter Network (SAN)的新框架,用于基于預訓練的視覺語言模型進行開放式語義分割。該方法將語義分割任務建模為區域識別問題,并通過附加一個側面的可學習網絡來實現。該網絡可以重用CLIP(Contrastive Language-Image Pre-Training)模型的特征,從而使其非常輕便。整個網絡可以進行端到端的訓練,使側面網絡適應凍結的CLIP模型,從而使預測的掩碼提案具有CLIP感知能力。作者在多個語義分割基準測試上評估了該方法,并表明其速度快、準確度高,只增加了少量可訓練參數,在一系列數據集上相較于之前的SOTA模型取得了大幅的性能提升(如下表所示)最后,作者希望該方法能夠成為一個baseline,并幫助未來的開放式語義分割研究。

論文鏈接:
https://arxiv.org/abs/2211.08073
 ?
? ?
?Introduction
作者首先討論了語義分割的概念和現代語義分割方法的限制,以及如何將大規模視覺語言模型應用于開放式語義分割。現代語義分割方法通常依賴于大量標記數據,但數據集通常只包含數十到數百個類別,昂貴的數據收集和注釋限制了我們進一步擴展類別的可能性。最近,大規模視覺語言模型(如CLIP)的出現促進了零樣本學習的發展,這也鼓勵我們探索其在語義分割中的應用。然而,將CLIP模型應用于開放式語義分割十分困難,因為CLIP模型是通過圖像級對比學習訓練的,其學習到的表示缺乏像素級別的識別能力,而這種能力在語義分割中是必需的。解決這個問題的一個方法是在分割數據集上微調模型,但是分割數據集的數據規模遠遠小于視覺語言預訓練數據集,因此微調模型在開放式識別方面的能力通常會受到影響。
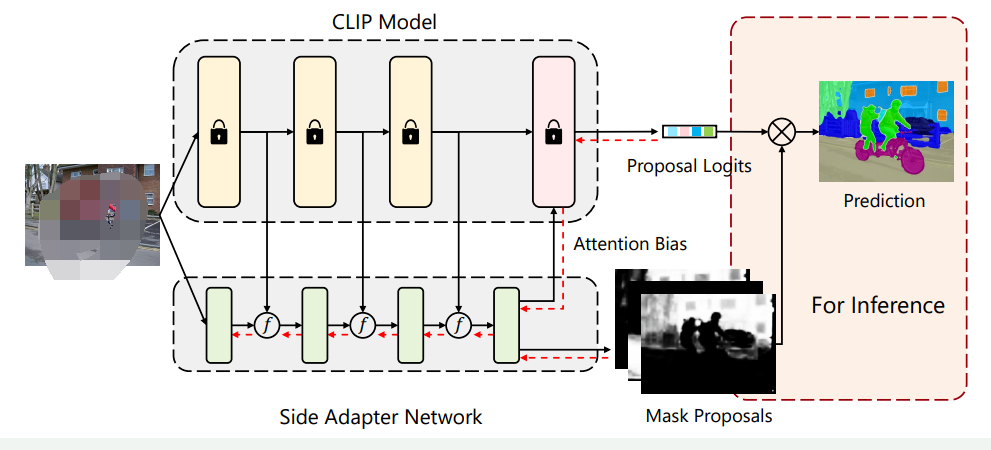
為了充分發揮視覺-語言預訓練模型在開放詞匯語義分割中的能力。作者提出了一種名為Side Adapter Network(SAN)的新框架。由于端到端訓練,SAN的掩膜預測和分類是基于CLIP輔助的。整個模型十分輕量化。SAN有兩個分支:一個用于預測掩膜,另一個用于預測應用于CLIP的注意力偏好,以進行掩膜類別識別。作者表明,這種分離的設計可以提高分割性能。此外,作者還提出了一種單向前設計,以最小化CLIP的成本:將淺層CLIP塊的特征融合到SAN中,將其他更深層次的塊與注意偏置結合以進行掩膜識別。由于訓練是端到端的,SAN可以最大程度地適應凍結的CLIP模型。作者的研究基于官方發布的ViT CLIP模型,采用Visual Transformer實現。準確的語義分割需要高分辨率圖像,但發布的ViT CLIP模型設計用于低分辨率圖像(如),直接應用于高分辨率圖像會導致性能下降。為了緩解輸入分辨率的沖突,作者在CLIP模型中使用低分辨率圖像,在SAN中使用高分辨率圖像。作者表明,這種不對稱的輸入分辨率非常有效。此外,作者還探討了僅微調ViT模型的位置嵌入,并取得了改進。作者在各種基準測試中評估了他們的方法。與之前的方法相比,作者的方法在所有基準測試中都取得了最好的性能。作者的方法只有8.4M可訓練參數和64.3 GFLOPs。
 ?Method
?Method
3.1 基礎架構
SAN的詳細架構如下圖所示。輸入圖像被分成個patch。首先通過一個線性層將圖片轉化為Visual Tokens。這些Visual Tokens會與個可學習的Query Tokens拼接起來,并送到后續的Transformer Layer中。每個Transformer Layer的Visual Tokens和Query Tokens都添加了position embedding。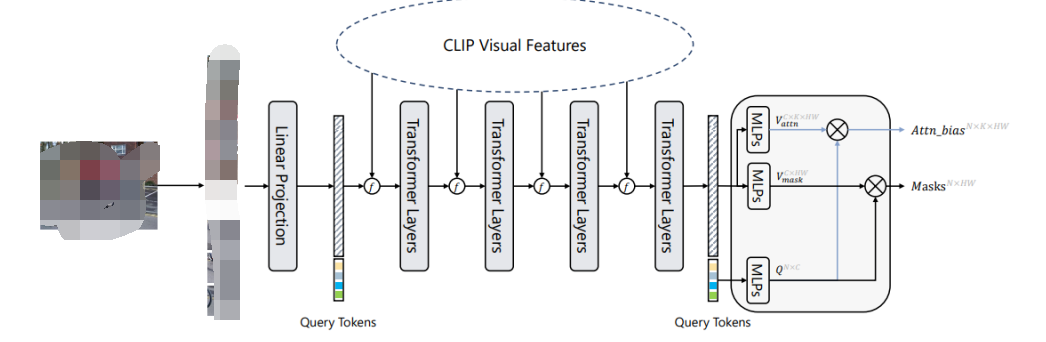 示例圖片SAN的輸出由兩部分構成:掩膜提議(Mask Proposals)和注意力偏好(Attention Biases)。在掩膜提議中,Query Tokens和Visual Tokens首先通過兩個單獨的3層MLP,投影成256維,我們將投影的Query Tokens表示為,其中是Query Tokens的數量,投影的Visual Tokens表示為,其中和是輸入圖像的高度和寬度。然后,通過和的內積生成掩膜:
其中。生成注意力偏好的過程類似于掩膜提議。Query Tokens和Visual Tokens也通過3層MLP進行投影,表示為和,其中是CLIP模型的注意頭數。通過對和進行內積,我們得到注意力偏好:
其中。此外,如果需要,注意力偏好還將進一步調整為,其中和是CLIP中注意力映射的高度和寬度。在實踐中,和可以共享,并且注意力偏好將應用于CLIP的多個自注意層,即偏好將在不同的自注意層中使用。這樣的雙輸出設計的動機很直觀:作者認為用于在CLIP中識別掩模的感興趣區域可能與掩模區域本身不同。作者在后文的對比實驗中也證實了這個想法。
示例圖片SAN的輸出由兩部分構成:掩膜提議(Mask Proposals)和注意力偏好(Attention Biases)。在掩膜提議中,Query Tokens和Visual Tokens首先通過兩個單獨的3層MLP,投影成256維,我們將投影的Query Tokens表示為,其中是Query Tokens的數量,投影的Visual Tokens表示為,其中和是輸入圖像的高度和寬度。然后,通過和的內積生成掩膜:
其中。生成注意力偏好的過程類似于掩膜提議。Query Tokens和Visual Tokens也通過3層MLP進行投影,表示為和,其中是CLIP模型的注意頭數。通過對和進行內積,我們得到注意力偏好:
其中。此外,如果需要,注意力偏好還將進一步調整為,其中和是CLIP中注意力映射的高度和寬度。在實踐中,和可以共享,并且注意力偏好將應用于CLIP的多個自注意層,即偏好將在不同的自注意層中使用。這樣的雙輸出設計的動機很直觀:作者認為用于在CLIP中識別掩模的感興趣區域可能與掩模區域本身不同。作者在后文的對比實驗中也證實了這個想法。3.2掩膜預測
原始的CLIP模型只能通過標記進行圖像級別的識別。作者工作在不改變CLIP模型參數的情況下,嘗試通過指導標記的注意力圖在感興趣區域上實現精確的掩膜識別。為了實現這個目標,作者創建了一組名為標記(仿照Maskclip,如下圖)。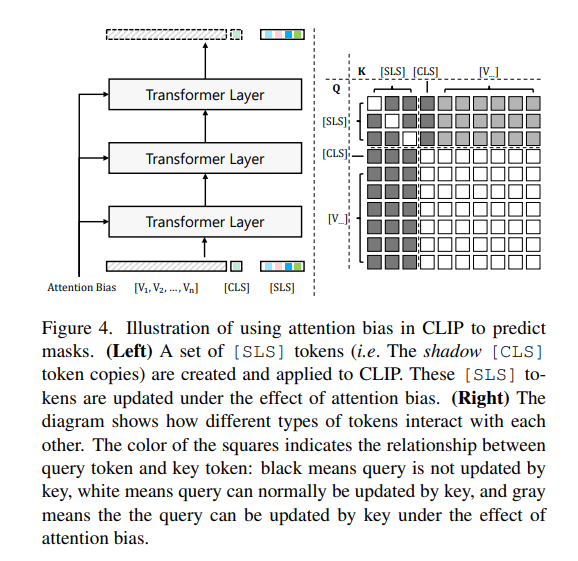 這些標記單向地通過Visual Tokens進行更新,但是Visual Tokens和標記都不受的影響。在更新標記時,預測的注意力偏差被添加到注意力矩陣中:
其中表示層編號,表示第個注意力頭,和是的Query 和Key,是Visual Tokens 的Key。,和分別是Query、Key和Value的編碼權重。通過注意力偏好,標記的特征逐漸演變以適應掩膜預測,并且可以通過比較標記和類名CLIP文本編碼之間的距離/相似性來輕松獲得掩膜的類別預測,表示為,其中是類別數。
這些標記單向地通過Visual Tokens進行更新,但是Visual Tokens和標記都不受的影響。在更新標記時,預測的注意力偏差被添加到注意力矩陣中:
其中表示層編號,表示第個注意力頭,和是的Query 和Key,是Visual Tokens 的Key。,和分別是Query、Key和Value的編碼權重。通過注意力偏好,標記的特征逐漸演變以適應掩膜預測,并且可以通過比較標記和類名CLIP文本編碼之間的距離/相似性來輕松獲得掩膜的類別預測,表示為,其中是類別數。3.3分割結果生成
使用上文提到的掩膜和類別預測,我們可以計算語義分割圖: 其中。這是標準的語義分割輸出,因此與主流的語義分割評估兼容。在訓練,我們通過Dice Loss 和binary cross-entropy loss 來監督掩膜生成,通過cross-entropy loss 來監督掩膜識別。總損失為: 其中作者使用的損失權重,,分別為5.0,5.0和2.0。通過端到端的訓練,SAN可以最大程度地適應凍結的CLIP模型,并得到很好的結果。 ?
?討論
具體來說,作者提出了一種全新的端到端架構,以極小的參數量在多個數據集上取得了SOTA效果。SAN的主要特點如下:
-
SAN中沿用了MaskCLIP得出的結論:在下游數據集上微調會破壞CLIP優秀的特征空間。因此在SAN的設計中,無需微調(fine-tune)CLIP模型,以便最大程度的保持CLIP模型的開放詞匯能力。
-
在凍結CLIP模型的同時,引入了額外的可編碼網絡,能夠根據下游任務數據集學習分割所需要的特征,彌補了CLIP模型對于位置信息的缺失。
- 將語義分割任務分解為掩膜預測與類別預測兩個子任務。CLIP模型的開放識別能力不僅僅依賴于物體區域本身,也依賴于物體的上下文信息(Context Information)。這促使作者提出掩膜預測與類別預測解耦的雙輸出設計,下表顯示該設計可以進一步提升模型的預測精度。
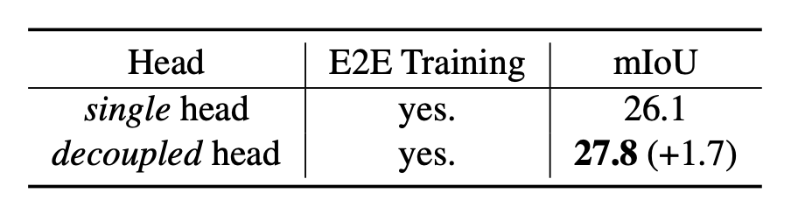 ?
?-
充分復用了CLIP模型的特征,大幅度降低所需的額外參數量的同時獲得最佳性能。下表展示了復用CLIP特征帶來的性能增益。
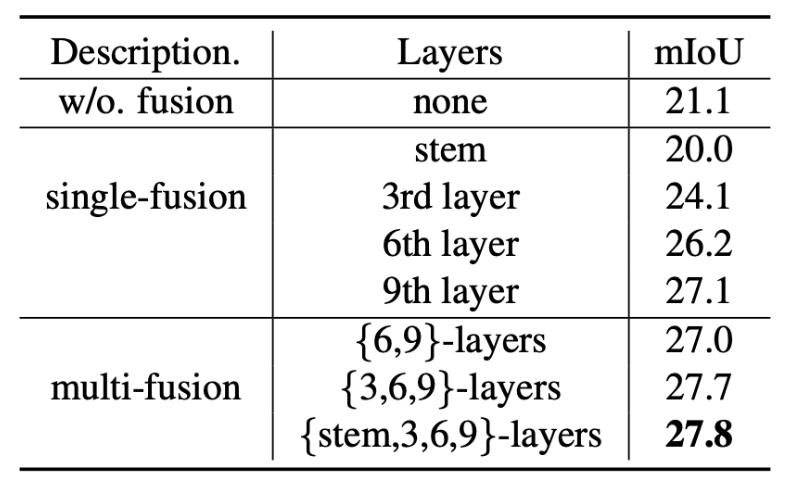 ?
?
?
? ?結論作者在這項工作中提出了SAN框架,用于開放詞匯語義分割。該框架成功地利用了凍結的CLIP模型的特征以及端到端的流程,并最大化地采用凍結的CLIP模型。所提出的框架在五個語義分割基準測試中顯著優于以往的最先進方法,而且具有更少的可訓練參數和更少的計算成本。
·
?結論作者在這項工作中提出了SAN框架,用于開放詞匯語義分割。該框架成功地利用了凍結的CLIP模型的特征以及端到端的流程,并最大化地采用凍結的CLIP模型。所提出的框架在五個語義分割基準測試中顯著優于以往的最先進方法,而且具有更少的可訓練參數和更少的計算成本。
·
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
物聯網
+關注
關注
2913文章
44924瀏覽量
377022
原文標題:CVPR 2023 | 華科&MSRA新作:基于CLIP的輕量級開放詞匯語義分割架構
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
凌科電氣YU系列工業級連接器登場,解鎖USB&Type-C多模塊新體驗!
近日,凌科全新推出YU系列USB&Type-C多模塊工業級連接器,在功能上實現了全面升級。
新品 | 可拼接燈板矩陣 Puzzle Unit & 創意固定套件CLIP-A/CLIP-B
本月的第三波新品上線了3款全新產品,涵蓋了多種需求和應用領域。從激發興趣和創意的PuzzleUnit,到多功能創意套件CLIP-A&;CLIP-B,每一款都為不同場景提供了創新解決方案。快來

北美運營商AT&amp;amp;T認證的費用受哪些因素影響
申請北美運營商AT&T認證的價格因多種因素而異,包括產品類型、認證范圍、測試難度等。一般來說,申請AT&T認證的費用可能相對較高,因為AT&T作為北美地區的主要電信運營商,其

onsemi LV/MV MOSFET 產品介紹 &amp;amp; 行業應用
01直播介紹直播時間2024/10/281430直播內容1.onsemiLV/MVMOSFET產品優勢&市場地位。2.onsemiLV/MVMOSFETRoadmap。3.onsemiT10

輕量級多級菜單控制框架
輕量級菜單框架(C語言)
作為嵌入式軟件開發,可能經常會使用命令行或者顯示屏等設備實現人機交互的功能,功能中通常情況都包含 UI 菜單設計;很多開發人員都會有自己的菜單框架模塊,防止重復造輪子,網上
發表于 10-12 09:36
國產芯上運行TinyMaxi輕量級的神經網絡推理庫-米爾基于芯馳D9國產商顯板
本篇測評由優秀測評者“短笛君”提供。本文將介紹基于米爾電子MYD-YD9360商顯板(米爾基于芯馳D9360國產開發板)的TinyMaxi輕量級的神經網絡推理庫方案測試。
算力測試TinyMaix
發表于 08-09 18:26
國產芯上運行TinyMaxi輕量級的神經網絡推理庫-米爾基于芯馳D9國產商顯板
D9360國產開發板)的TinyMaxi輕量級的神經網絡推理庫方案測試。
算力測試
TinyMaix 是面向單片機的超輕量級的神經網絡推理庫,即 TinyML 推理庫,可以讓你在任意單片機上運行輕量級深度
發表于 08-07 18:06
圖像語義分割的實用性是什么
圖像語義分割是一種重要的計算機視覺任務,它旨在將圖像中的每個像素分配到相應的語義類別中。這項技術在許多領域都有廣泛的應用,如自動駕駛、醫學圖像分析、機器人導航等。 一、圖像語義
圖像分割和語義分割的區別與聯系
圖像分割和語義分割是計算機視覺領域中兩個重要的概念,它們在圖像處理和分析中發揮著關鍵作用。 1. 圖像分割簡介 圖像分割是將圖像劃分為多個區
FS201資料(pcb &amp; DEMO &amp; 原理圖)
電子發燒友網站提供《FS201資料(pcb & DEMO & 原理圖).zip》資料免費下載
發表于 07-16 11:24
?2次下載
圖像分割與語義分割中的CNN模型綜述
圖像分割與語義分割是計算機視覺領域的重要任務,旨在將圖像劃分為多個具有特定語義含義的區域或對象。卷積神經網絡(CNN)作為深度學習的一種核心模型,在圖像
解讀北美運營商,AT&amp;amp;T的認證分類與認證內容分享
在數字化日益深入的今天,通信技術的穩定與安全對于個人、企業乃至整個國家都至關重要。作為北美通信領域的領軍者,AT&T一直致力于為用戶提供高效、可靠的通信服務。而在這背后,AT&T
未來輕量級深度學習技術探索
除了輕量級架構設計外,作者提到了可以應用于壓縮給定架構的各種高效算法。例如,量化方法 旨在減少數據所需的存儲空間,通常是通過用8位或16位數字代替32位浮點數,甚至使用二進制值表示數據。
發表于 04-23 15:54
?448次閱讀
百度智能云推出全新輕量級大模型
在近日舉辦的百度智能云千帆產品發布會上,三款全新的輕量級大模型——ERNIE Speed、ERNIE Lite以及ERNIE Tiny,引起了業界的廣泛關注。相較于傳統的千億級別參數大模型,這些輕量級大模型在參數量上有了顯著減少,為客戶提供了更加靈活和經濟高效的解決方案。
Open RAN的未來及其對AT&amp;T的意義
3月14日消息,在“Connected America 2024”會議上,AT&T高級副總裁兼網絡首席技術官Yigal Elbaz討論了Open RAN 的未來及其對AT&T的意義。





 工商網監
工商網監
評論