 NVIDIA Hopper GPU上的新cuBLAS12.0功能和矩陣乘法性能
NVIDIA Hopper GPU上的新cuBLAS12.0功能和矩陣乘法性能
人工智能和機器學習基準測試中相當一部分操作是 通用矩陣乘法 ,也稱為 matmul 函數。 GEMs 也存在于深度學習訓練的前向和后向通道以及推理中。
GEMM 的突出性使得深度學習軟件能夠最大限度地利用用于矩陣乘法的硬件,同時支持幾個關鍵的 AI 組件。這些成分包括具有偏置和流行激活功能的融合體及其衍生物。
本文探討了 NVIDIA cuBLAS 庫 在里面 CUDA 12.0 重點是最近推出的 FP8 format 、 NVIDIA Hopper 上的 GEM 性能 GPU ,以及新 64 位整數應用程序編程接口 ( API )和新融合等用戶體驗的改進。
在深入了解這些功能之前,簡要概述了當前可用的 cuBLAS API 、如何更有效地應用每種 API ,以及 cuBLAS 與其他可用的 NVIDIA 矩陣乘法工具的關系。
確定要使用的 cuBLAS API
cuBLAS 庫是在 NVIDIA CUDA 運行時之上的基本線性代數子程序( BLAS )的一種實現,旨在利用 NVIDIA GPU 進行各種矩陣乘法運算。本文主要討論 cuBLAS 和 cuBLASLt API 的新功能。然而, cuBLAS 庫還提供了針對多 GPU 分布式 GEMs 的 cuBLASXt API 。 cuBLASXt API 將于 2023 年在 Early Access 中提供,目標是 GEMs 及其設備內融合功能。
表 1 概述了每種 API 的設計用途以及用戶可以在哪里獲得最佳性能。
| API | API complexity | Called from | Fusion support | Matrix sizes for maximum performance |
|
cuBLAS (since CUDA 6.0) |
Low | Host | None | Large (global memory) |
| cuBLASXt (since CUDA 6.0) | Low | Host | None | Very Large (multi-GPU, global memory) |
|
cuBLASLt (since CUDA 10.1) |
Medium | Host | Fixed set | Medium (global memory) |
| cuBLASDx (targeting 2023 EA) | Medium/High | Device | User ops | Small (shared memory) |
表 1 。各種 cuBLAS 原料藥的比較。通常, API 復雜度越高, API 越適合內核開發人員.
cuBLAS API
cuBLAS API 在所有三個級別實現 NETLIB BLAS 規范,每個例程最多有四個版本:實數單精度、實數雙精度、復數單精度和復數雙精度,分別帶有 S 、 D 、 C 和 Z 前綴。
對于 BLAS L3 GEMM ,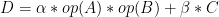 ,
,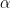 和
和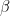 變量(如主機和設備引用)有更多可用選項。該 API 還提供了幾個 extensions ,如傳統函數的批處理和降低/混合精度版本。
變量(如主機和設備引用)有更多可用選項。該 API 還提供了幾個 extensions ,如傳統函數的批處理和降低/混合精度版本。
cuBLASLt API
cuBLASLt API 是一個比 cuBLAS 更靈活的解決方案,專門為人工智能和機器學習中的 GEMM 操作而設計。它通過以下選項的參數可編程性提供靈活性:
矩陣數據布局
輸入類型
計算類型
結語
算法實現選擇
啟發式
一旦用戶確定了預期 GEM 操作的一組選項,這些選項就可以重復用于不同的輸入。簡而言之,與 cuBLAS API 相比, cuBLASLt 可以支持復雜的情況,例如:
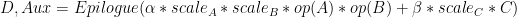
該案例有多個輸出,是基于變壓器的模型中遇到的一個突出的 GEMM .
為了提供最近的示例, a 和 B 可以采用兩種新的 FP8 格式中的任一種,并在 FP32 中進行乘法和累加。 Epilogue 可以包括 GELU 和偏倚,偏倚在 BF16 或 FP16 中。許多常見的尾聲現在都融入了 matmul 。此外,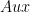 是一個可選的附加尾聲輸出,用于計算梯度。使用 cuBLASLt 操作 handle type 描述了上述操作和許多類似操作。
是一個可選的附加尾聲輸出,用于計算梯度。使用 cuBLASLt 操作 handle type 描述了上述操作和許多類似操作。
NVIDIA 切割機和 GEMS
作為最著名的開源 NVIDIA 庫之一, NVIDIA CUTLASS 還為 NVIDIA GPU 上的 GEMM (和卷積)提供 CUDA C ++和 Python 抽象,并在設備、塊、扭曲和線程級別提供原語。 CUTRASS 的一個優點是,用戶可以專門為其所需范圍編譯 GEMs ,而無需像 cuBLAS 庫那樣加載更大的二進制文件。
當然,這會帶來性能上的權衡,因為需要大量的努力來為每個單獨的用例找到和實例化最佳內核。 cuBLAS 庫通過廣泛訓練的啟發式方法,在廣泛的問題范圍內提供最大的性能。
事實上,對于許多用例和數據類型, cuBLAS 可能包括從 CULASS 實例化的幾個內核。通常, cuBLAS 使用各種內核源,以確保在應用程序之間更均勻地實現最大性能。
NVIDIA Hopper 上的 FP8 支持
首次在 CUDA 18.1 中引入, FP8 是 16 位浮點類型的自然發展,減少了 神經網絡訓練的記憶和計算要求 。此外,由于其對實數的非線性采樣,與 int8 相比, FP8 在推理方面也具有優勢。
FP8 由兩種編碼 E4M3 和 E5M2 組成,其中名稱明確表示指數( E )和尾數( M )位數,符號位隱含。在 CUDA C ++中,這些編碼公開為 __nv_fp8_e4m3 和 __nv_fp8_e5m2 類型。 NVIDIA Hopper Tensor Core 支持 FP16 和 FP32 累積的 FP8 矩陣產品。
在 CUDA 12.0 (以及 CUDA 11.8 )中, cuBLAS 提供了多種 matmul 操作,支持具有 FP32 累積的 both encodings 。(有關完整列表,請參見 cuBLAS 文檔 .) FP8 matmul 操作還支持附加的融合操作,這些操作對于使用 FP8 進行訓練和推理非常重要,包括:
除了傳統的 alpha 和 beta 外, A 、 B 、 C 和 D 矩陣的每矩陣比例因子
輸出矩陣的絕對最大值計算
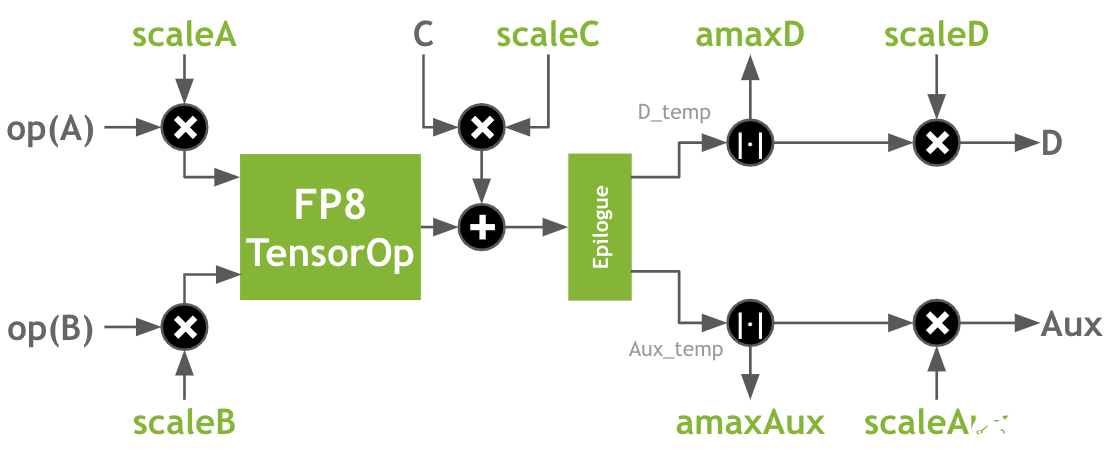 圖 2 :變壓器中常見的 GEM 示意圖,帶有尾聲、縮放因子和 cuBLASLt API 支持的多個輸出
圖 2 :變壓器中常見的 GEM 示意圖,帶有尾聲、縮放因子和 cuBLASLt API 支持的多個輸出
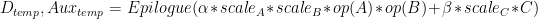
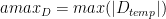
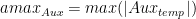
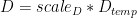
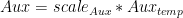
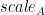 、
、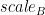 和
和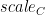
請注意,所有比例因子都是乘法應用的。這意味著有時需要根據應用的上下文使用縮放因子或其倒數。縮放因子和矩陣之間的乘法的特定順序無法保證。
cuBLAS 12.0 performance on NVIDIA H100 GPU
我們比較了 H100 PCIe 和 SXM (預覽版)與 A100 ( PCIe )上 FP16 、 BF16 和 FP8 GEMM 在三種情況下的基本時鐘性能: cuBLAS 庫對于大矩陣大小的峰值性能,以及 MLPerf 和 NVIDIA 深度學習示例 中存在的 GEMM 。
大型 GEMM 表現出較大的算術強度,因此受到計算限制。當標準化為 A100 時,加速因子接近于 GPU 對之間基礎數據類型的峰值性能比率。對于計算綁定的 FP16 GEMM , cuBLAS 庫在 H100 SXM 上實現了相對于 A100 的三倍加速。
另一方面, MLPerf 和 NVIDIA DL 示例由跨越一系列算術強度的 GEMM 組成。有些距離計算范圍較遠,因此表現出比大型 GEMs 更小的加速。對于 MLPerf 和 NVIDIA DL 示例中的 GEMs , cuBLAS 庫在 H100 SXM 上分別實現了 2.7 倍和 2.2 倍的加速。
在 MLPerf 和 NVIDIA DL 示例中,通過 H100 ( PCIe 和 SXM ) GPU 上的 cuBLASLt 標準化為 A100 PCIe GPU ,實現 FP16 矩陣乘法和 GEMM 的加速。通過將圖形時鐘鎖定到每個 GPU 的基本時鐘來完成測量。
為了比較 H100 上的 FP8 和 BF16 性能,我們選擇 A100 上的 BF16 作為基線。之所以選擇此選項,是因為 FP8 支持僅在 NVIDIA Hopper 架構上可用。與 A100 PCIe 上的 BF16 相比, cuBLAS 庫在 H100 SXM 上為 BF16 和 FP8 提供了近 2.8 倍的加速。
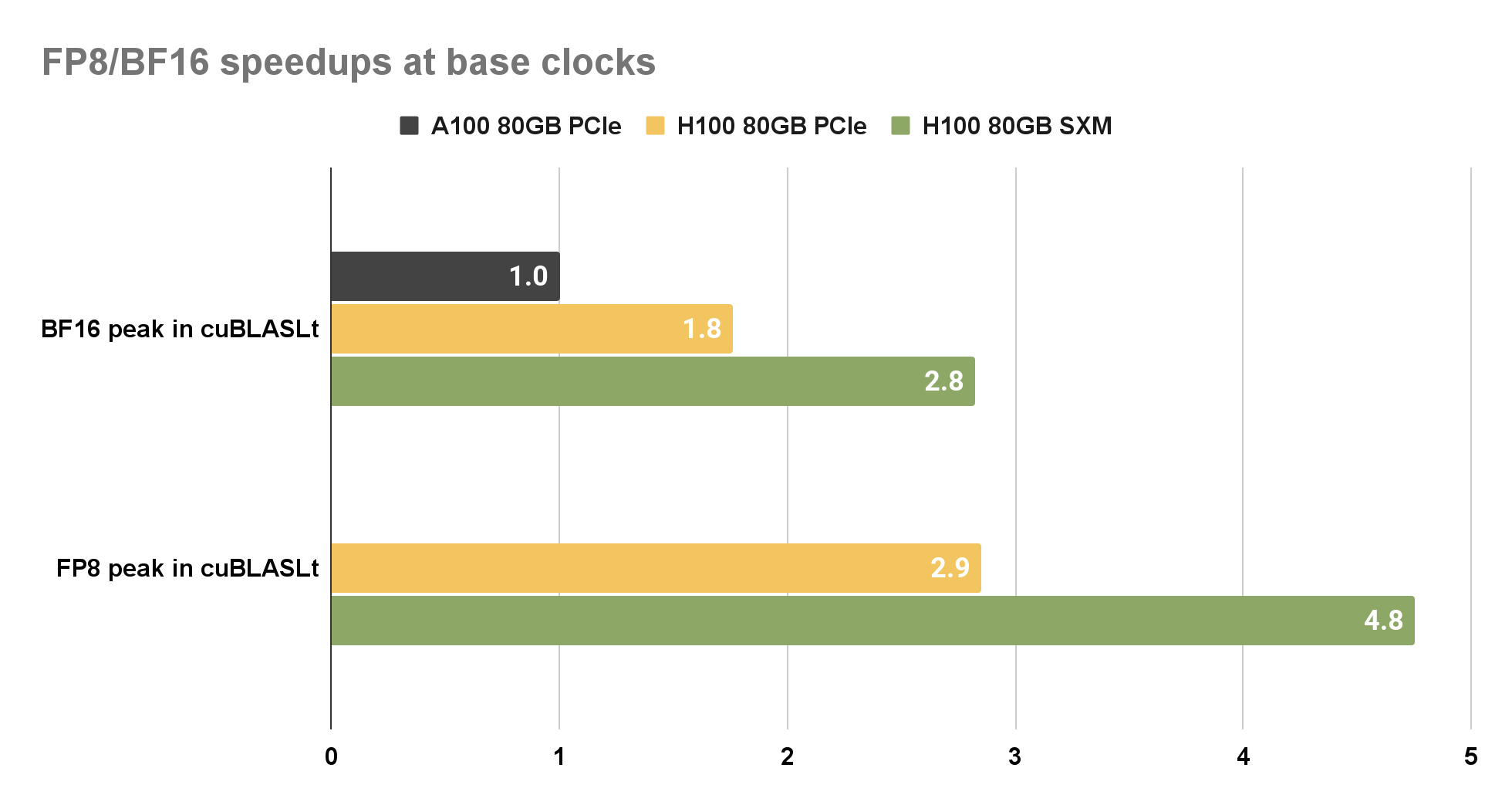 圖 4 。通過 H100 ( PCIe 和 SXM ) GPU 上的 cuBLASLt 實現加速, BF16 和 FP8 矩陣乘法標準化為 A100 80 GB PCIe GPU 。通過將圖形時鐘鎖定到每個 GPU 的基本時鐘來完成測量。
圖 4 。通過 H100 ( PCIe 和 SXM ) GPU 上的 cuBLASLt 實現加速, BF16 和 FP8 矩陣乘法標準化為 A100 80 GB PCIe GPU 。通過將圖形時鐘鎖定到每個 GPU 的基本時鐘來完成測量。
NVIDIA Hopper 架構工作空間要求
H100 原生內核增加了對工作空間大小的需求。因此,強烈建議為 cuBLASLt 調用或使用 cublasSetWorkspace 時提供至少 32 MiB ( 33554432 B )的工作空間。
cuBLAS 用戶體驗的改進
cuBLAS 12.0 啟用了新的 FP8 和 FP16 / BF16 融合外延。在 NVIDIA Hopper 上, FP8 融合現在提供偏置( BF16 和 FP16 )、 ReLU 和 GELU ,以及輔助輸出緩沖器和輔助輸出緩沖器。新的 FP16 融合器還可用于 NVIDIA Hopper 的偏置、 ReLU 和 GELU 、 dBias 和 dReLU 。對于 NVIDIA Ampere 架構,單核、更快的 BF16 融合(帶有偏置和 GELU )以及 dBias 和 dGELU 現在已經公開。
Heuristics cache 允許將 matmul 問題映射到先前通過啟發式選擇的內核。這有助于減少重復 matmul 問題的主機端開銷。
cuBLAS 12.0 擴展了 cuBLAS API ,以支持 64 位整數問題大小、前導維數和向量增量。這些新函數與 32 位整數對應函數具有相同的 API ,不同之處在于它們的名稱中有_64后綴,并將相應的參數聲明為int64_t。
例如,對于經典的 32 位整數函數:
cublasStatus_t cublasIsamax( cublasHandle_t handle, int n, const float *x, int incx, int *result);
64 位整數對應項是:
cublasStatus_t cublasIsamax_64( cublasHandle_t handle, int64_t n, const float *x, int64_t incx, int64_t *result);
性能是 cuBLAS 的主要關注點,因此當傳遞給 64 位整數 API 的參數符合 32 位范圍時,庫將使用與用戶調用 32 位整數 API 相同的內核。要嘗試新的 API ,遷移應該像向 cuBLAS 函數添加_64后綴一樣簡單,這要歸功于 C / C ++將int32_t值自動轉換為int64_t。
cuBLAS 12.0 和 NVIDIA Hopper GPU
-
NVIDIA
+關注
關注
14文章
5076瀏覽量
103724 -
gpu
+關注
關注
28文章
4776瀏覽量
129358 -
AI
+關注
關注
87文章
31529瀏覽量
270342
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論