 基于一種用于JumpStarter的抗離群的采樣算法
基于一種用于JumpStarter的抗離群的采樣算法
隨著在線服務系統的蓬勃發展,多元時間序列的異常檢測,例如CPU利用率的組合,平均響應時間和每秒請求,對于系統可靠性很重要。盡管為此目的設計了一系列基于學習的方法,但實證研究表明,這些方法遭受了長時間的初始化時間,以獲得足夠的培訓數據。本文壓縮感測技術引入了多元時間序列異常檢測,以快速初始化。為了構建跳躍異常檢測器,提出了一種名為Jumpstarter的方法。基于域特異性見解,設計了一種基于形狀的聚類算法以及一種用于JumpStarter的抗離群的采樣算法。
背景及動機
1、多元時間序列
在在線服務系統中,操作員不斷收集多個指標的監視數據,或從日志中提取數值。服務水平度量(例如,平均響應時間)或機器級度量(例如CPU利用率,內存利用率)通常是通過相等的間隔收集的,形成單變量時間序列。但是,任何單變量時間序列都無法捕獲系統的所有類型的性能問題。由于系統通常具有監視指標的集合,因此可以表示為多變量時間序列,其中包括各種類型的單變量時間序列,從而跟蹤性能問題的各個方面。隨著系統的規模和復雜性的增加,手動檢查系統異常變得越來越困難。因此,多元時間序列異常檢測非常重要。
2、異常檢測
使用多元時間序列的異常檢測在線服務系統中很重要。在以前的異常檢測工作中,操作員在以下幾點上有一個粗略的共識:
1)多元時間序列異常是數據點或數據段,它顯著偏離了操作員對操作員的期望正常行為,可以在視覺上觀察到。
2)異常表明可能出現問題,盡管仍需要進一步調查進行驗證。
3)異常檢測通常用作失敗發現機制。
初始化時間的實證研究
1、異常檢測初始化時間
在部署或更新的新服務時,運營商通常為其啟動一種異常檢測方法。如圖所示,異常檢測方法的初始化時間是啟動何時(T1)到有效的時間(T2)。
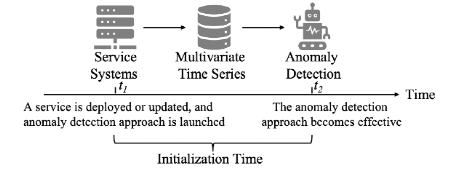
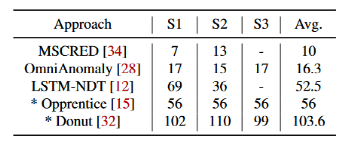
許多先前方法使用基于學習的工作流來檢測異常。通常,它們是根據歷史數據進行定期培訓的。這些方法的初始化時間,例如數十天相對較長,因為它們通常需要提供大量的歷史數據進行培訓。在表中,列出了不同數據集上五種基于學習的異常檢測方法的建議初始化時間。
2、增量再訓練
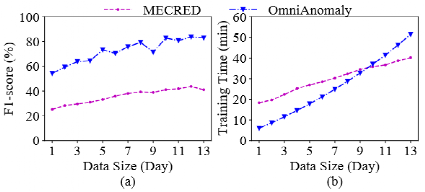
考慮到基于學習的異常檢測方法的漫長初始化時間,人們可能建議逐步保留,即逐漸(逐步)添加一個短期(例如一天)數據來訓練這些方法。這樣,我們可以逐步提高這些方法的性能。每次添加一天的數據是因為這些基于學習的方法至少需要數千個數據點來收斂。然后,嘗試將增量再培訓應用于最新的多元時間序列檢測方法,即全曲率和mecred。
這聽起來很理想,但是使用增量再培訓的異常檢測不能確保令人滿意的性能。圖中顯示了隨著訓練數據的增加(日復一日)的增加,F1的平均得分和訓練時間。從圖中,可以看到,使用更多的訓練數據,以及使用更多的訓練數據,直到將10天的數據用于培訓,它們才收斂。一個主要原因是,這些基于學習的方法必須從大量培訓數據中明確學習多元時間序列的概率分布,以捕獲其正常行為。圖中表明,訓練時間隨訓練數據的規模線性增加。當培訓數據集包含10天的數據時,大約需要35分鐘才能訓練。因此,這些方法由于其非舒適性和相當大的培訓成本而不適合新部署或更新的系統。
Jumpstarter方法
1、關鍵思想和挑戰
為了處理上述基于學習方法的局限性,將壓縮感測(CS)用于多變量時間序列異常檢測。CS是一種信號處理技術,用于從一系列采樣測量結果中重建信號。從這些樣品中重建的信號保留了原始信號的高能量成分,在某些輕度假設下概率很高。可以通過檢查重建信號是否與原始信號(多元時間序列)存在超過白噪聲的不同,來確認檢測異常。由于CS不需要任何訓練,因此基于CS的異常檢測的初始化時間是窗口大小W。
有兩個方式來進行信號重建:
1、將多變量時間序列視為一個N×W的矩陣。
2、將多變量時間序列視為N個長度為W的單變量序列。
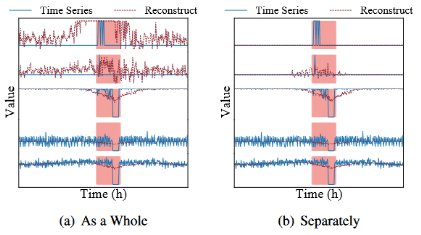
結果如圖所示,第一種方式,對數據隨機采樣并進行重建之后,出現前兩維數據在全時間跨度內重建序列和原始序列都差異較大的情況。
第二種方式,原始和重建的單變量時間序列之間的差異表現為正常段中的白噪聲和異常的大波動,可準確捕獲每個單變量時間序列的異常。但是,它無法捕獲多元時間序列之間的復雜關系。此外,由于大量單變量時間序列的挑戰,單獨的重建在計算上更昂貴。
2、概述
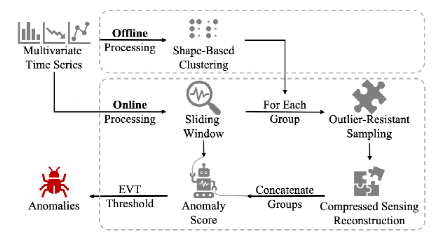
1、采用一種基于形狀的聚類方法將多元時間序列的單變量時間序列分組為離線處理中的幾個組。
2、滑動窗口技術應用于在線異常檢測中的多元時間序列。
3、對于每組單變量時間序列,使用一種新型的抗異常值采樣算法來解決來自異常段采樣引入的挑戰,并應用壓縮感測來重建它們。之后,比較原始時間序列和重建的多元時間序列,并使用EVT閾值對異常得分進行異常確定。
3、Shape-Based Clustering
先前提到的兩種方式都存在自己的問題。特別是第一種方式無法很好的在不同形狀的維度上進行重建,因此一種方式就是按照形狀將多元分為幾個群集進而重建每個群集。
采用基于形狀的距離(已有相關工作),是一種基于跨相關的方法,以測量兩個單變量時間序列之間的距離。在處理高維度序列時,它可以實現高計算效率。表中說明了聚類結果的示例。多元時間序列的九個單變量時間序列分為三個群集。在每個集群中,時間序列與其相應監視指標的物理含義相關,表明這個方法是直觀有效的。
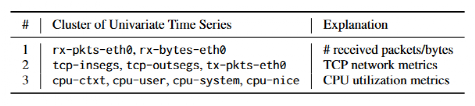
基于一日數據的每個多變量時間序列將單變量時間序列集成,因為大多數單變量時間序列大致與24小時的周期大致相同,與客戶的企業使用模式相吻合。此外,在軟件更改后,單變量時間序列的形狀通常保持不變。因此,在軟件更改后,它無需重新群集。
4、Outlier-Resistant Sampling

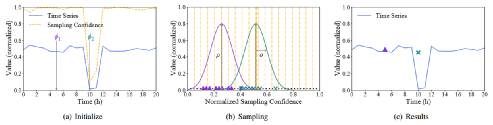
異常通常是觀察窗口(滑動)窗口中的異常值。如果異常的持續時間比窗口大小更長,則可以從一開始就捕獲,因為它與正常模式顯著不同。因此,可以采用簡單的離群檢測算法來獲得每個數據點的采樣置信度。數據點可能越高,其采樣置信度越低,選擇的可能性就越小。基于這種見解,文章設計了一種抗離群的抽樣算法,即一維隨機高斯,它不僅可以保證撕裂,而且還可以抵抗異常值。
從圖中的result部分可以看出最后得到的兩個樣本點,盡管綠色的取樣點位于原始時間序列的異常段,但是得到的樣本點依舊穩定。
4、Compressed Sensing Reconstruction
壓縮傳感理論首先將信號投影到一個低維的信號空間,然后通過解一個基于凸優化的非線性恢復算法將信號恢復,而僅僅需要很少的數據,文章使用了CVXPY這個凸優化算法。
5、異常得分
使用歐幾里得距離計算兩個時間序列之間的差異得分。
6、選擇閾值
要正確生成異常警報,需要準確選擇一個閾值,以確定異常得分是否足夠高以觸發警報。靜態閾值無法正常工作,因為數據分布會隨時間變化。由于JumpStarter產生的異常得分的極值通常代表異常,因此采用廣泛使用的極值理論(EVT)自動調整異常閾值。EVT是一種旨在找到極值定律的統計理論,并且不假定數據分布。已證明它可以準確選擇異常檢測方法的閾值。
實驗
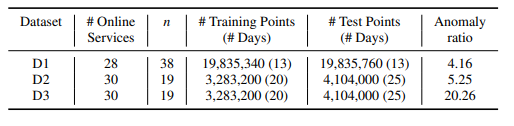
實驗部分主要解決以下研究問題:RQ1:Jumpstarter在多元時間序列序列檢測中的表現如何?RQ2:每個組件是否有助于Jumpstarter?RQ3:Jumpstarter的主要參數如何影響其性能?數據集的情況如下圖所示。
RQ1: Performance of JumpStarter
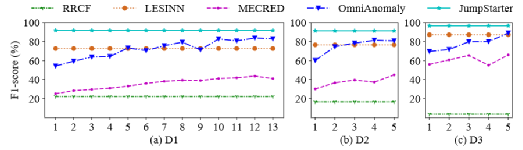
可以看到,在在線實驗中,JumpStarter的性能明顯優于所有三個數據集中所有段的四個基線方法。
接下來是軟件更改后的異常檢測。
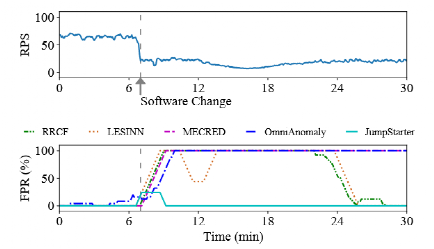
上圖顯示了軟件更改后五種方法的平均FPR,所有這些方法遇到的軟件更改都發生在圖中的第七分鐘。可以觀察到,在這些軟件更改后,所有五種方法都會產生誤報。但是,JumpStarter僅遭受大約五分鐘的高FPR,此后其FPR變得很低。
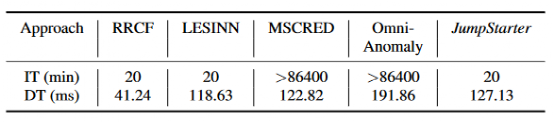
同時可以看到JumpStarter的準備時間和運行時間都比較少。
RQ2: Contributions of Components
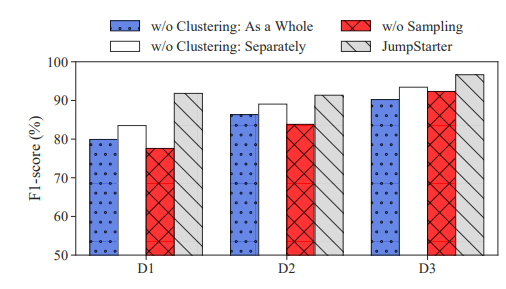
通過去除各個步驟得到的F1-score來看,基于形狀的聚類和抗異常值的采樣的組合有助于準確有效。
RQ3: Parameter Sensitivity
JumpStarter的初始化時間取決于檢測窗口大小w。我們從經驗上將窗戶尺寸從十分鐘增加到60分鐘。圖中顯示了隨著窗口尺寸的增加,Jumpstarter的平均最佳F1分數和連桿檢測時間如何變化。在窗口大小達到20分鐘之前,Jumpstarter的準確性會增加,之后它變得穩定,而檢測時間逐漸增加。因此,窗口尺寸為二十分鐘,這使Jumpstarter既準確又有效。請注意,對于那些持續超過20分鐘的異常,Jumpstarter仍然能夠檢測到它們,因為它可以在啟動時很容易捕獲這些異常。
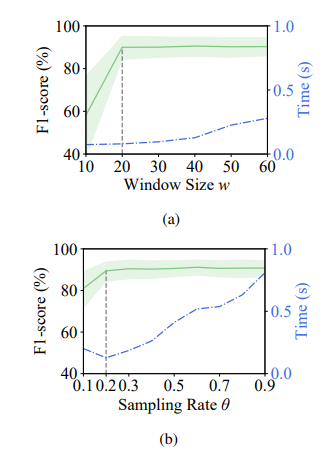
JumpStarter的另一個重要參數是初始采樣率σ。圖中顯示了f1的平均最佳F1分數和跳躍體的點檢測時間如何隨著σ的增加而變化。同樣,當采樣率從0.1增加到0.2時,JumpStarter的F1得分會增加,此后變得穩定。
-
檢測器
+關注
關注
1文章
869瀏覽量
47784 -
數據
+關注
關注
8文章
7139瀏覽量
89576 -
機器
+關注
關注
0文章
784瀏覽量
40818
原文標題:JumpStarter:在線服務系統中的多元時間序列異常檢測
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種基于高效采樣算法的時序圖神經網絡系統介紹
一種基于查詢前綴的快速抗沖突算法
一種基于過采樣的單通道MPSK信號盲分離算法
一種改進的DSP固定點采樣算法
局部密度離群點檢測算法

一種基于MapReduce的圖結構聚類算法
一種散亂點云近離群點的識別算法
一種信號矢量分解的采樣濾波移動節點定位算法
一種抗噪性強的改進Prony算法

一種新型的高維數據流離群點快速檢測算法







 工商網監
工商網監
評論