 聊聊布隆過濾器
聊聊布隆過濾器
前言
布隆過濾器作為一個精巧且實用的數據結構,對于后端程序員來講,學習和理解布隆過濾器有很大的必要性。希望通過這篇文章讓更多人了解布隆過濾器的原理,并且會實際去使用它!
什么是布隆過濾器?
布隆過濾器 (Bloom Filter)是由 Burton Howard Bloom 于 1970 年提出,我們可以把它看作由二進制向量(或者說位數組)和一系列隨機映射函數(哈希函數)兩部分組成的數據結構。相比于我們平時常用的的 List、Map、Set 等數據結構,它占用空間更少并且效率更高,但是缺點是其返回的結果是概率性的,而不是非常準確的。理論情況下添加到集合中的元素越多,誤報的可能性就越大。而且,存放在布隆過濾器的數據不容易刪除。
Bloom Filter 會使用一個較大的 bit 數組來保存所有的數據,數組中的每個元素都只占用 1 bit ,并且每個元素只能是 0 或者 1(代表 false 或者 true),這也是 Bloom Filter 節省內存的核心所在。這樣來算的話,申請一個 100w 個元素的位數組只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空間。

位數組
總結:一個名叫 Bloom 的人提出了一種來檢索元素是否在給定大集合中的數據結構,這種數據結構是高效且性能很好的,但缺點是具有一定的錯誤識別率和刪除難度。并且,理論情況下,添加到集合中的元素越多,誤報的可能性就越大。
布隆過濾器使用場景
判斷給定數據是否存在:比如判斷一個數字是否存在于包含大量數字的數字集中(數字集很大,上億)、 防止緩存穿透(判斷請求的數據是否有效避免直接繞過緩存請求數據庫)等等、郵箱的垃圾郵件過濾(判斷一個郵件地址是否在垃圾郵件列表中)、黑名單功能(判斷一個IP地址或手機號碼是否在黑名單中)等等。
網頁爬蟲對URL去重,避免爬取相同的 URL 地址。
比如用戶日常刷新聞,每次推薦給該用戶的內容不能重復,過濾已經看過的內容。
以上場景都需要判斷給定數據是否存在,因此布隆過濾器主要是為了解決海量數據的存在性問題。
布隆過濾器的原理介紹
當一個元素加入布隆過濾器中的時候,會進行如下操作:
使用布隆過濾器中的哈希函數對元素值進行計算,得到哈希值(有幾個哈希函數得到幾個哈希值)。
根據得到的哈希值,在位數組中把對應下標的值置為 1。
當我們需要判斷一個元素是否存在于布隆過濾器的時候,會進行如下操作:
對給定元素再次進行相同的哈希計算;
得到值之后判斷位數組中的每個元素是否都為 1,如果值都為 1,那么說明這個值在布隆過濾器中,如果存在一個值不為 1,說明該元素不在布隆過濾器中。
Bloom Filter 的簡單原理圖如下:
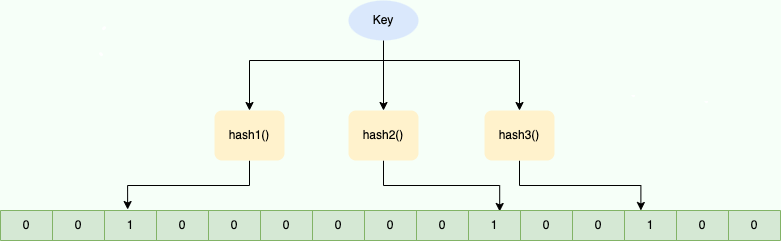
Bloom Filter 的簡單原理示意圖
如圖所示,當字符串存儲要加入到布隆過濾器中時,該字符串首先由多個哈希函數生成不同的哈希值,然后將對應的位數組的下標設置為 1(當位數組初始化時,所有位置均為 0)。當第二次存儲相同字符串時,因為先前的對應位置已設置為 1,所以很容易知道此值已經存在(去重非常方便)。
如果我們需要判斷某個字符串是否在布隆過濾器中時,只需要對給定字符串再次進行相同的哈希計算,得到值之后判斷位數組中的每個元素是否都為 1,如果值都為 1,那么說明這個值在布隆過濾器中,如果存在一個值不為 1,說明該元素不在布隆過濾器中。
不同的字符串可能哈希出來的位置相同,這種情況我們可以適當增加位數組大小或者調整我們的哈希函數。
綜上,我們可以得出:布隆過濾器說某個元素存在,小概率會誤判。布隆過濾器說某個元素不在,那么這個元素一定不在。
如何實現布隆過濾器
Guava 實現
Guava 中布隆過濾器的實現算是比較權威的,所以實際項目中我們不需要自己去實現一個布隆過濾器。
首先我們需要在項目中引入 Guava 的依賴:
com.google.guava guava 28.0-jre
實際使用如下:
我們創建了一個最多存放 最多 1500 個整數的布隆過濾器,并且我們可以容忍誤判的概率為百分之(0.01)
//創建布隆過濾器對象 BloomFilterfilter=BloomFilter.create( Funnels.integerFunnel(), 1500, 0.01); //判斷指定元素是否存在 System.out.println(filter.mightContain(1)); System.out.println(filter.mightContain(2)); //將元素添加進布隆過濾器 filter.put(1); filter.put(2); System.out.println(filter.mightContain(1)); System.out.println(filter.mightContain(2));
在我們的示例中,當mightContain()方法返回true時,我們可以 99%確定該元素在過濾器中,當過濾器返回false時,我們可以 100%確定該元素不存在于過濾器中。
Guava 提供的布隆過濾器的實現還是很不錯的(想要詳細了解的可以看一下它的源碼實現),但是它有一個重大的缺陷就是只能單機使用(另外,容量擴展也不容易),而現在互聯網一般都是分布式的場景。為了解決這個問題,我們就需要用到 Redis 中的布隆過濾器了。
Redis 中的布隆過濾器
Redis v4.0 之后有了 Module(模塊/插件)功能,Redis Modules 讓 Redis 可以使用外部模塊擴展其功能 ,使用戶可以根據需要額外集成一些實用功能。
審核編輯:劉清
-
URL
+關注
關注
0文章
139瀏覽量
15478 -
JAVA語言
+關注
關注
0文章
138瀏覽量
20178 -
過濾器
+關注
關注
1文章
432瀏覽量
19734
原文標題:聊聊布隆過濾器
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文理解布隆過濾器和布谷鳥過濾器
CN過濾器原理
過濾器的作用
如何使用計數型布隆過濾器進行可排序密文檢索的方法概述
解密高效空氣過濾器的性能及要求
絲扣Y過濾器
絲扣Y過濾器及過濾器測試原理簡介
絲扣Y形過濾器
漢克森過濾器系列介紹


一文解析布隆過濾器設計原理



什么情況下需要布隆過濾器





 工商網監
工商網監
評論