") Macaw-LLM:具有圖像、音頻、視頻和文本集成的多模態(tài)語言建模
Macaw-LLM:具有圖像、音頻、視頻和文本集成的多模態(tài)語言建模
文章:https://lnkd.in/gcwEeKE3
Python 代碼:https://lnkd.in/ggEK6KwU
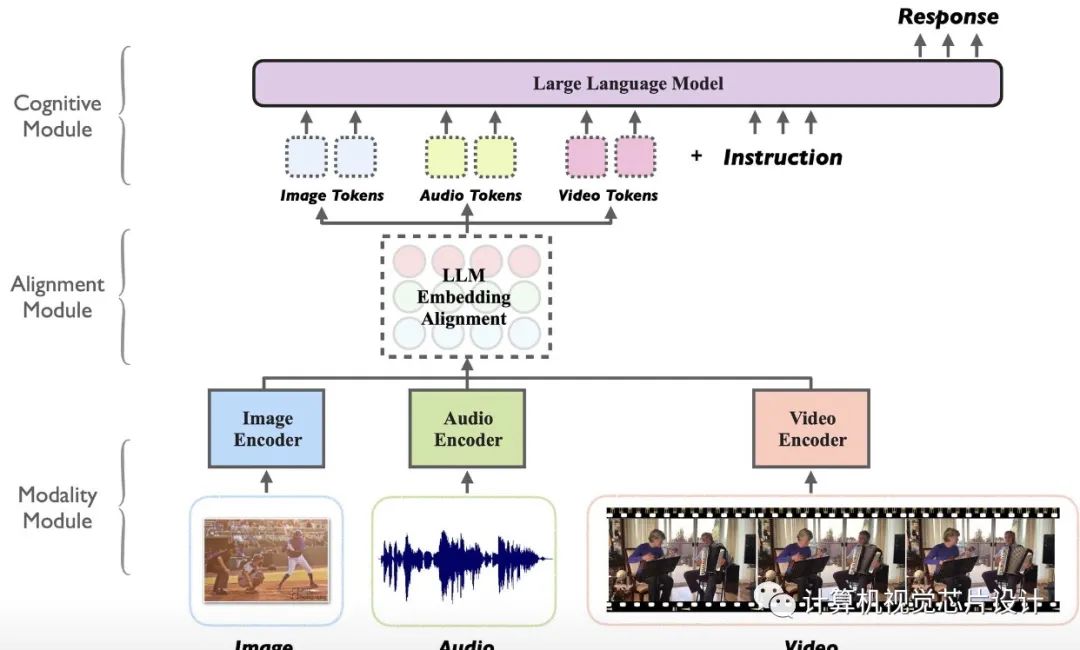
盡管指令調(diào)整的大型語言模型 (LLM) 在各種 NLP 任務中表現(xiàn)出卓越的能力,但它們在文本以外的其他數(shù)據(jù)模式上的有效性尚未得到充分研究。在這項工作中,我們提出了 Macaw-LLM,一種新穎的多模式 LLM,它無縫集成了視覺、音頻和文本信息。
Macaw-LLM 由三個主要組件組成:用于編碼多模態(tài)數(shù)據(jù)的模態(tài)模塊、用于利用預訓練 LLM 的認知模塊以及用于協(xié)調(diào)不同表示的對齊模塊。
我們新穎的對齊模塊將多模態(tài)特征無縫地連接到文本特征,簡化了從模態(tài)模塊到認知模塊的適應過程。
此外,我們在多輪對話方面構建了一個大規(guī)模的多模態(tài)指令數(shù)據(jù)集,包括 69K 圖像實例和 50K 視頻實例。我們已經(jīng)公開了我們的數(shù)據(jù)、代碼和模型,我們希望這可以為多模態(tài) LLM 的未來研究鋪平道路,并擴展 LLM 處理不同數(shù)據(jù)模態(tài)和解決復雜現(xiàn)實場景的能力。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
模塊
+關注
關注
7文章
2735瀏覽量
47753 -
語言建模
+關注
關注
0文章
5瀏覽量
6278 -
語言模型
+關注
關注
0文章
538瀏覽量
10342 -
LLM
+關注
關注
0文章
299瀏覽量
400
原文標題:Macaw-LLM:具有圖像、音頻、視頻和文本集成的多模態(tài)語言建模
文章出處:【微信號:計算機視覺芯片設計,微信公眾號:計算機視覺芯片設計】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
自然語言處理的圖像文本建模相關研究及分析
近年來,圖像文本建模研究已經(jīng)成為自然語言處理領域一個重要的硏究方向。圖像常被用于增強句子的語義理解與表示。然而也有硏究人員對
發(fā)表于 03-24 11:33
?27次下載

簡述文本與圖像領域的多模態(tài)學習有關問題
模型中的幾個分支角度,簡述文本與圖像領域的多模態(tài)學習有關問題。 1. 引言 近年來,計算機視覺和自然語言處理方向均取得了很大進展。而融合二者
復旦&微軟提出?OmniVL:首個統(tǒng)一圖像、視頻、文本的基礎預訓練模型
根據(jù)輸入數(shù)據(jù)和目標下游任務的不同,現(xiàn)有的VLP方法可以大致分為兩類:圖像-文本預訓練和視頻-文本預訓練。前者從圖像-
微軟多模態(tài)ChatGPT的常見測試介紹
研究者將一個基于 Transformer 的語言模型作為通用接口,并將其與感知模塊對接。他們在網(wǎng)頁規(guī)模的多模態(tài)語料庫上訓練模型,語料庫包括了文本數(shù)據(jù)、任意交錯的
發(fā)表于 03-13 11:23
?864次閱讀
ImageBind:跨模態(tài)之王,將6種模態(tài)全部綁定!
最近,很多方法學習與文本、音頻等對齊的圖像特征。這些方法使用單對模態(tài)或者最多幾種視覺模態(tài)。最終嵌入僅限于用于訓練的

如何利用LLM做多模態(tài)任務?
大型語言模型LLM(Large Language Model)具有很強的通用知識理解以及較強的邏輯推理能力,但其只能處理文本數(shù)據(jù)。雖然已經(jīng)發(fā)布的GPT4具備圖片理解能力,但目前還未開放
邱錫鵬團隊提出SpeechGPT:具有內(nèi)生跨模態(tài)能力的大語言模型
雖然現(xiàn)有的級聯(lián)方法或口語語言模型能夠感知和生成語音,但仍存在一些限制。首先,在級聯(lián)模型中,LLM 僅充當內(nèi)容生成器。由于語音和文本的表示沒有對齊,LLM 的知識無法遷移到語音

邱錫鵬團隊提出具有內(nèi)生跨模態(tài)能力的SpeechGPT,為多模態(tài)LLM指明方向
大型語言模型(LLM)在各種自然語言處理任務上表現(xiàn)出驚人的能力。與此同時,多模態(tài)大型語言模型,如

基于實體和動作時空建模的視頻文本預訓練
摘要 盡管常見的大規(guī)模視頻-文本預訓練模型已經(jīng)在很多下游任務取得不錯的效果,現(xiàn)有的模型通常將視頻或者文本視為一個整體建模跨

用圖像對齊所有模態(tài),Meta開源多感官AI基礎模型,實現(xiàn)大一統(tǒng)
最近,很多方法學習與文本、音頻等對齊的圖像特征。這些方法使用單對模態(tài)或者最多幾種視覺模態(tài)。最終嵌入僅限于用于訓練的

VisCPM:邁向多語言多模態(tài)大模型時代
隨著 GPT-4 和 Stable Diffusion 等模型多模態(tài)能力的突飛猛進,多模態(tài)大模型已經(jīng)成為大模型邁向通用人工智能(AGI)目標的下一個前沿焦點。總體而言,面向

大模型+多模態(tài)的3種實現(xiàn)方法
我們知道,預訓練LLM已經(jīng)取得了諸多驚人的成就, 然而其明顯的劣勢是不支持其他模態(tài)(包括圖像、語音、視頻模態(tài))的輸入和輸出,那么如何在預訓練

自動駕駛和多模態(tài)大語言模型的發(fā)展歷程
多模態(tài)大語言模型(MLLM) 最近引起了廣泛的關注,其將 LLM 的推理能力與圖像、視頻和
發(fā)表于 12-28 11:45
?561次閱讀

韓國Kakao宣布開發(fā)多模態(tài)大語言模型“蜜蜂”
韓國互聯(lián)網(wǎng)巨頭Kakao最近宣布開發(fā)了一種名為“蜜蜂”(Honeybee)的多模態(tài)大型語言模型。這種創(chuàng)新模型能夠同時理解和處理圖像和文本數(shù)據(jù)
利用OpenVINO部署Qwen2多模態(tài)模型
多模態(tài)大模型的核心思想是將不同媒體數(shù)據(jù)(如文本、圖像、音頻和視頻等)進行融合,通過學習不同





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論