 大模型訓練和部署的關鍵技術
大模型訓練和部署的關鍵技術
電子發燒友網報道(文/李彎彎)ChatGPT的出現讓大模型迅速出圈,事實上,在過去這些年中,模型規模在快速提升。數據顯示,自2016年至今,模型大小每18個月增長40倍,自2019年到現在,更是每18個月增長340倍。
然而相比之下,硬件增長速度較慢,自2016年至今,GPU的性能增長每18個月1.7倍,模型大小和硬件增長的差距逐漸擴大。顯存占用大、算力消費大、成本高昂等瓶頸嚴重阻礙AIGC行業的快速發展。在此背景下,潞晨科技創始人尤洋認為,分布式訓練勢在必行。
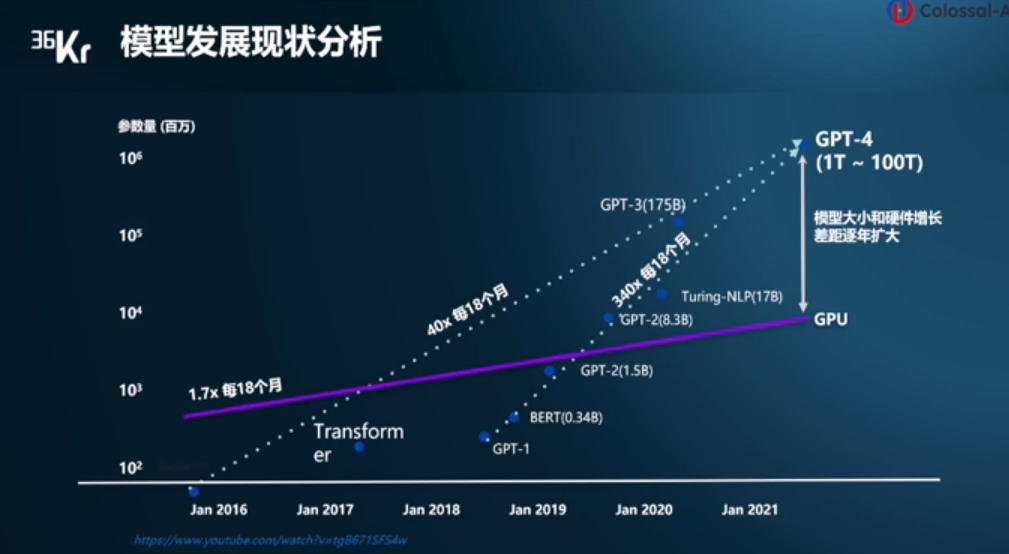
圖:潞晨科技創始人尤洋演講
基礎大模型結構為模型訓練提供了基礎架構
其一、Google首創的Transformer大模型,是現在所有大模型最基礎的架構。現在Transformer已經成為除了MLP、CNN、RNN以外第四種最重要的深度學習算法架構。
其二、Google發布的首個預大模型BERT,從而引爆了預練大橫型的潮流和的勢,BERT強調了不再像以往一樣采用傳統的單向語言模型或者把兩個單向語言橫型進行淺層拼接的方法進行預認訓練,而是采用新的masked language model(MLM),以致能生成深度的雙向語言表征。
其三、ViT Google提出的首個使用Transformert的視覺大模型,ViT作為視覺轉換器的使用,而不是CNN威混合方法來執行圖像任務,作者假設進一步的預認訓練可以提高性能,因為與其他現有技術模型相比,ViT具有相對可擴展性。
其四、Google將Transformer中的Feedforward Network(FFN)層替換成了MoE層,并且將MoE層和數據并行巧妙地結合起來,在數據并行訓練時,模型在訓練集群中已經被復制了若干份,通過在多路數據并行中引入Al-to-Al通信來實現MoE的功能。
在這些基礎大模型結構之上,過去這些年,在大模型的發展歷程中,出現了幾個具有里程碑意義性的大模型包括GPT-3、T5、Swin Transformer、Switch Transformer。
GPT-3:OpenAI發布的首個百億規模的大模型,應該非常具有開創性意義,現在的大模型都是對標GPT-3,GPT-3依舊延續自己的單向語言模型認訓練方式,只不過這次把模型尺寸增大到了1750億,并且使用45TB數據進行訓練。
T5(Text-To-Text Transfer Transformer):Google T5將所有NLP任務都轉化成Text-to-Text(文本到文本)任務。它最重要作用給整個NLP預訓型領城提供了一個通用框架,把所有任務都轉化成一種形式。
Swin Transformer:微軟亞研提出的Swin Transformer的新型視覺Transformer,它可以用作計算機視的通用backbone。在個領域之同的差異,例如視覺實體尺度的巨大差異以及與文字中的單詞相比,圖像中像素的高分率,帶來了使Transformer從語言適應視覺方面的挑戰。
超過萬億規模的稀疏大模型Switch Transformer:能夠訓練包含超過一萬億個參數的語言模型的技術,直接將參數量從GPT-3的1750億拉高到1.6萬億,其速度是Google以前開發的語言模型T5-XXL的4倍。
另外,更具里程碑意義的大模型,在Pathways上實現的大預言模型PaLM。
分布式框架Pathways:Pathways的很多重要思想來源于現有系統,包括用于表達和執行TPU計算的XLA、用于表征和執行分布式CPU計算的TensorFlow圖和執行器、基于Python編程框架的JAX以及TensorFlowAPL,通過有效地使用這些模塊,Pathways不需要對現有橫型進行很多改動就能運行。
PaLM模型:PaLM吸引人眼球的是該模型具有5400億參數以及果用新一代AI框架Pathways訓練。模型結構也給出了很多方面優化,這些技術優化工作汲取了現有突出的研究成果,具體包括SwiGLU激活函數代替ReLU、層并行技術(Parallel Layers)、多查詢注意力(Multi-Query Attention),旋轉位置編碼(RoPE)、共享輸入和輸出詞嵌入、去掉偏置參數(No Biases)等。

PaLM模型也是通過堆疊Transformer中的Decoder部分而成,該模型具有5400億參數以及采用新一代AI框架Pathways訓練。
大規模分布式訓練當前主要技術路線
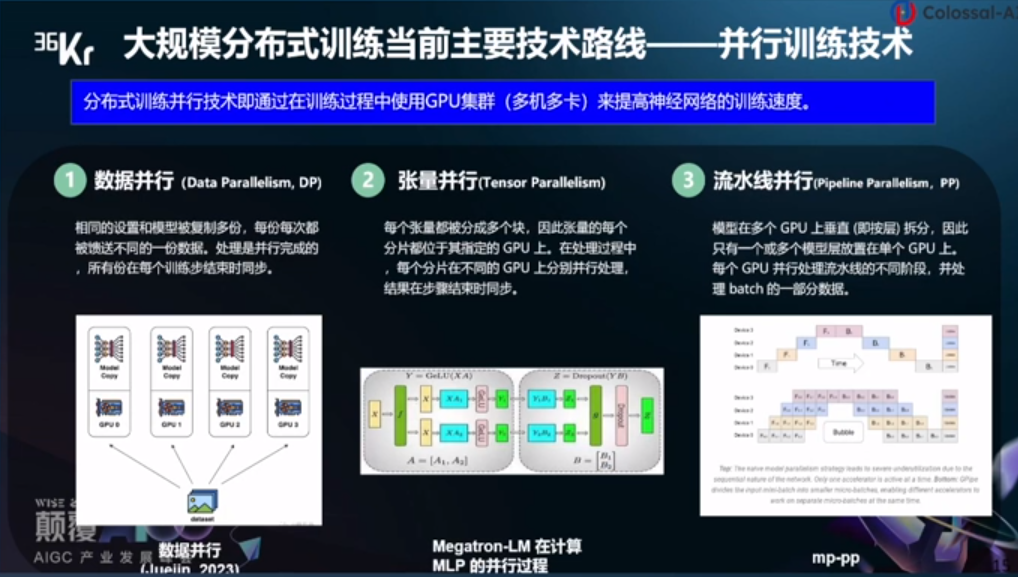
大規模分布式訓練當前主要技術路線——并行訓練技術。分布式訓練并行技術即通過在訓練過程中使用GPU集群(多機多卡)來提高神經網絡的訓練速度。
數據并行:相同的設置和模型被復制多份,每份每次都被饋送不同的一份數據,處理是并行完成的,所有份在每個訓練步結束時同步。
張量并行:每個張量都被分成多個塊,因此張量的每個分片都位于其指定的GPU上,在處理過程中,每個分片在不同的GPU上分別并行處理,結果在步驟結束時同步。
流水線并行:模型在多個GPU上垂直(即按量)拆分,因此只有一個或多個模型層放置在單個GPU上,每個GPU并行處理流水線的不同階段,并處理batch的一部分數據。
潞晨科技成立于2021年,是一家致力于“解放AI生產力”的全球性公司。主要業務是通過打造分布式AI開發和部署平臺,幫助企業降低大模型的落地成本,提升訓練、推理效率。
潞晨開源的智能系統架構Colossal-AI技術,有兩大特性:一是最小化部署成本,Colossal-AI 可以顯著提高大規模AI模型訓練和部署的效率。僅需在筆記本電腦上寫一個簡單的源代碼,Colossal-AI 便可自動部署到云端和超級計算機上。
通常訓練大模型 (如GPT-3) 需要 100 多個GPU,而使用Colossal-AI僅需一半的計算資源。即使在低端硬件條件下,Colossal-AI也可以訓練2-3倍的大模型。
二是最大化計算效率,在并行計算技術支持下,Colossal-AI在硬件上訓練AI模型,性能顯著提高。潞晨開源的目標是提升訓練AI大模型速度10倍以上。
小結
如今,全球眾多科技企業都在研究大模型,然而大模型的訓練和部署對硬件也有極高的要求,高昂的硬件需求和訓練成本是當前亟待解決的問題。可見,除了OpenAI、谷歌、百度、阿里等致力于大模型研究企業,以及英偉達等提供硬件的企業之外,潞晨科技這類提供微調,致力于提升大模型訓練和部署效率、降低成本的企業,也值得關注。
-
大模型
+關注
關注
2文章
2551瀏覽量
3174
發布評論請先 登錄
相關推薦
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
云計算HPC軟件關鍵技術
AI模型部署邊緣設備的奇妙之旅:如何實現手寫數字識別
如何訓練自己的LLM模型
如何訓練自己的AI大模型
基于Pytorch訓練并部署ONNX模型在TDA4應用筆記






 工商網監
工商網監
評論