 大模型訓練,英偉達Turing、Ampere和Hopper算力分析
大模型訓練,英偉達Turing、Ampere和Hopper算力分析
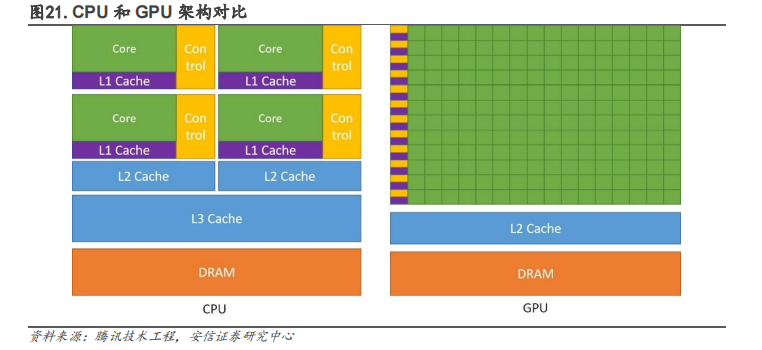
大 GPU 優勢在于通過并行計算實現大量重復性計算。GPGPU即通用GPU,能夠幫助 CPU 進行非圖形相關程序的運算。在類似的價格和功率范圍內,GPU 能提供比CPU 高得多的指令吞吐量和內存帶寬。GPGPU 架構設計時去掉了 GPU 為了圖形處理而設計的加速硬件單元,保留了 GPU 的 SIMT架構和通用計算單元,通過 GPU 多條流水線的并行計算來實現大量計算。
所以基于 GPU 的圖形任務無法直接運行在 GPGPU 上,但對于科學計算,AI 訓練、推理任務(主要是矩陣運算)等通用計算類型的任務仍然保留了 GPU 的優勢,即高效的搬運和運算有海量數據的重復性任務。目前主要用于例如物理計算、加密解密、科學計算以及比特幣等加密貨幣的生成。
隨著超算等高并發性計算的需求不斷提升,英偉達以推動 GPU 從專用計算芯片走向通用計算處理器為目標推出了GPGPU,并于 2006 年前瞻性發布并行編程模型 CUDA,以及對應工業標準的 OpenCL。CUDA 是英偉達的一種通用并行計算平臺和編程模型,它通過利用圖形處理器 (GPU)的處理能力,可大幅提升計算性能。CUDA 使英偉達的 GPU 能夠執行使用 C、C++、Fortran、OpenCL、DirectCompute 和其他語言編寫的程序。在 CUDA 問世之前,對 GPU 編程必須要編寫大量的底層語言代碼;CUDA 可以讓普通程序員可以利用 C 語言、C++等為 CUDA 架構編寫程序在 GPU平臺上進行大規模并行計算,在全球 GPGPU 開發市場占比已超過 80%。GPGPU 與 CUDA 組成的軟硬件底座,構成了英偉達引領 AI 計算及數據中心領域的根基。
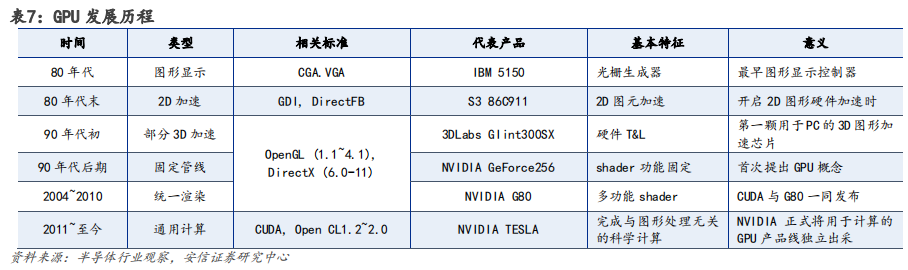
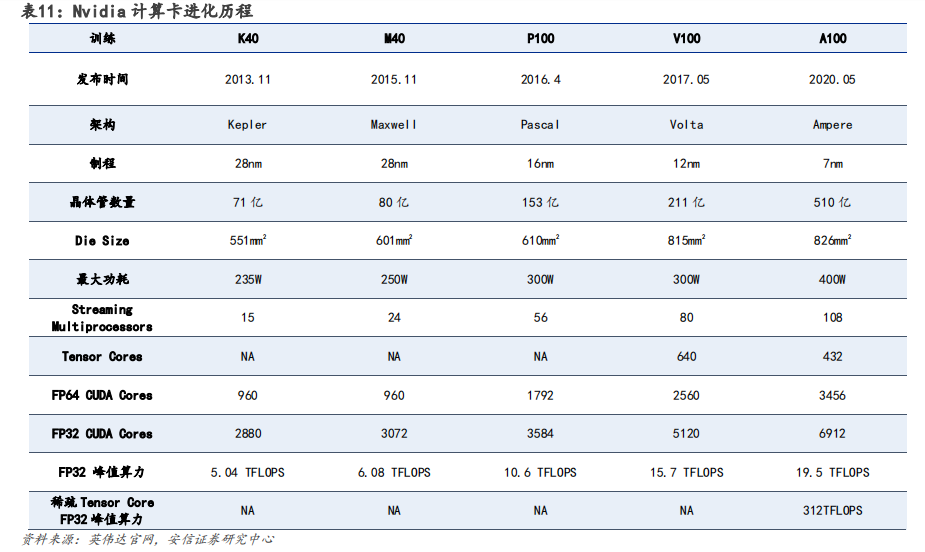
GPU 架構升級過程計算能力不斷強化,Hopper 架構適用于高性能計算(HPC)和 AI 工作負載。英偉達在架構設計上,不斷加強 GPU 的計算能力和能源效率。在英偉達 GPU 架構的演變中,從最先 Tesla 架構,分別經過 Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere至發展為今天的 Hopper 架構。
以 Pascal 架構為分界點,自 2016 年后英偉達逐步開始向深度學習方向演進。根據英偉達官網,Pascal 架構,與上一代 Maxwell 相比,神經網絡訓練速度提高 12 倍多,并將深度學習推理吞吐量提升了 7 倍。
Volta 架構,配備 640 個 Tensor 內核增強性能,可提供每秒超過 100 萬億次(TFLOPS)的深度學習性能,是上一代 Pascal 架構的 5 倍以上。
Turing 架構,配備全新 Tensor Core,每秒可提供高達 500 萬億次的張量運算。
Ampere架構,采用全新精度標準 Tensor Float 32(TF32),無需更改任何程序代碼即可將AI 訓練速度提升至 20 倍。
最新Hopper 架構是第一個真正異構加速平臺,采用臺積電 4nm 工藝,擁有超 800 億晶體管,主要由 Hopper GPU、Grace CPU、NVLINK C2C 互聯和 NVSwitch 交換芯片組成,根據英偉達官網介紹,其性能相較于上一代 Megatron 530B 擁有 30 倍 AI 推理速度的提升。
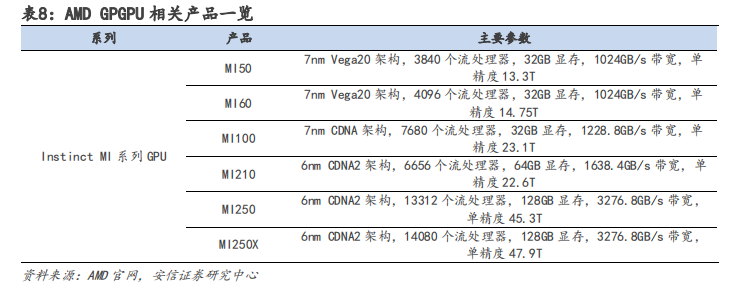
AMD 數據中心領域布局全面,形成 CPU+GPU+FPGA+DPU 產品矩陣。與英偉達相比,AMD 在服務器端 CPU 業務表現較好,根據 Passmark 數據顯示,2021 年 Q4 AMD EPYC 霄龍系列在英特爾壟斷下有所增長,占全球服務器 CPU 市場的 6%。依據 CPU 業務的優勢,AMD 在研發 GPGPU 產品時推出 Infinity Fabric 技術,將 EPYC 霄龍系列 CPU 與 Instinct MI 系列 GPU 直接相連,實現一致的高速緩存,形成協同效應。此外,AMD 分別于 2022 年 2 月、4 月收購 Xilinx 和Pensando,補齊 FPGA 與 DPU 短板,全面進軍數據中心領域。
軟件方面,AMD 推出 ROCm 平臺打造 CDNA 架構,但無法替代英偉達 CUDA 生態。AMD 最新的面向 GPGPU 架構為 CDNA 系列架構,CDNA 架構使用 ROCm 自主生態進行編寫。AMD 的 ROCm 生態采取 HIP 編程模型,但 HIP 與 CUDA 的編程語法極為相似,開發者可以模仿 CUDA 的編程方式為 AMD 的 GPU 產品編程,從而在源代碼層面上兼容 CUDA。所以從本質上來看,ROCm 生態只是借用了 CUDA 的技術,無法真正替代 CUDA 產生壁壘。
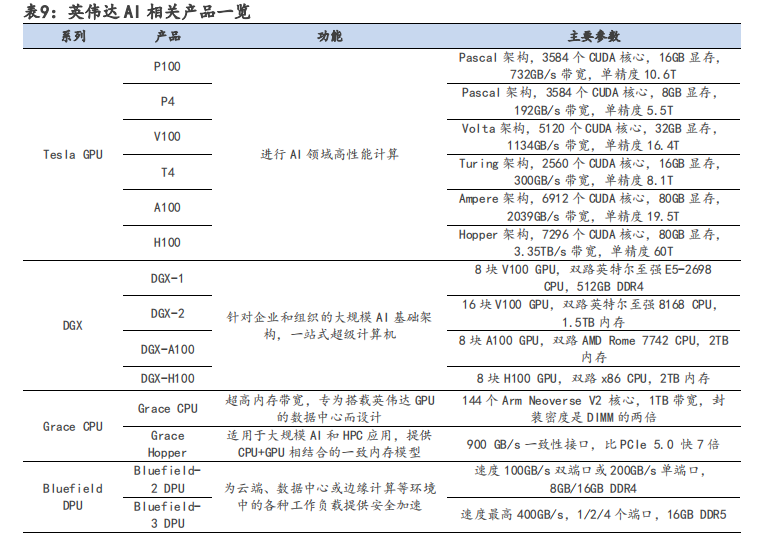
軟硬件共同布局形成生態系統,造就英偉達核心技術壁壘。
? 硬件端:基于 GPU、DPU 和 CPU 構建英偉達加速計算平臺生態:
(1)主要產品 Tesla GPU 系列迭代速度快,從 2008 年至 2022 年,先后推出 8 種 GPU 架構,平均兩年多推出新架構,半年推出新產品。超快的迭代速度使英偉達的 GPU 性能走在 AI 芯片行業前沿,引領人工智能計算領域發生變革。
(2)DPU 方面,英偉達于 2019 年戰略性收購以色列超算以太網公司 Mellanox,利用其InfiniBand(無限帶寬)技術設計出 Bluefield 系列 DPU 芯片,彌補其生態在數據交互方面的不足。InfiniBand 與以太網相同,是一種計算機網絡通信標準,但它具有極高的吞吐量和極低的延遲,通常用于超級計算機的互聯。英偉達的 Bluefield DPU 芯片可用于分擔 CPU 的網絡連接算力需求,從而提高云數據中心的效率,降低運營成本。
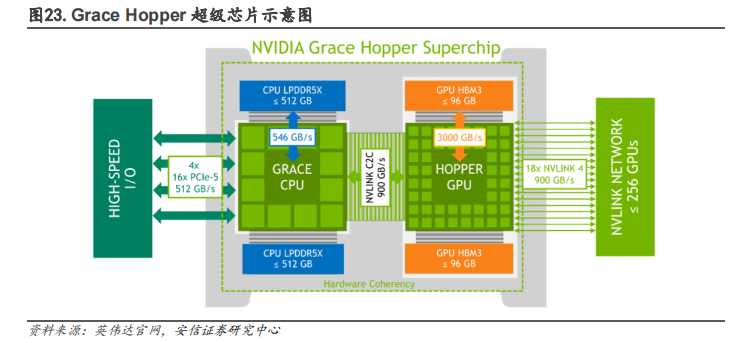
(3)CPU 方面,自主設計 Grace CPU 并推出 Grace Hopper 超級芯片,解決內存帶寬瓶頸問題。采用 x86 CPU 的傳統數據中心會受到 PCIe 總線規格的限制,CPU 到 GPU 的帶寬較小,算效率受到影響;而 Grace Hopper 超級芯片提供自研 Grace CPU+GPU 相結合的一致內存模型,從而可以使用英偉達 NVLink-C2C 技術快速傳輸,其帶寬是第 5 代 PCIe 帶寬的 7 倍,極大提高了數據中心的運行性能。
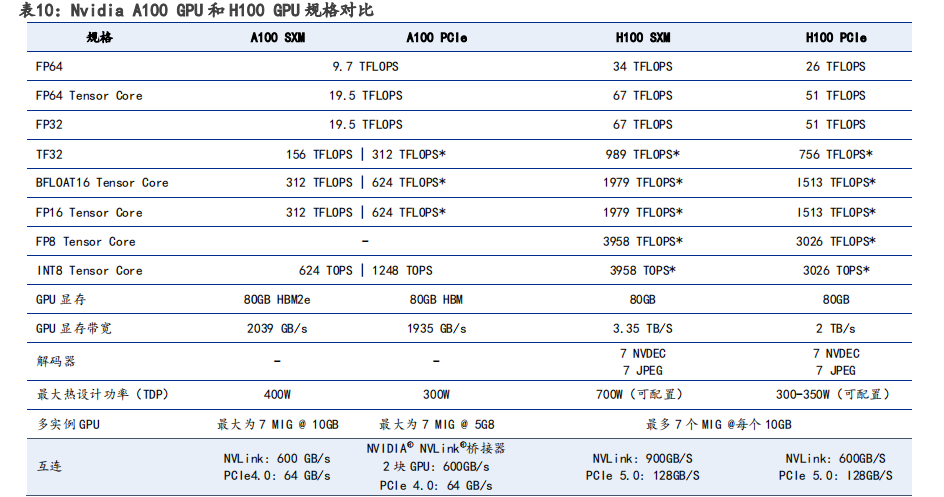
相較于 A100 GPU,H100 性能再次大幅提升。在 H100 配備第四代 Tensor Core 和 Transformer引擎(FP8 精度),同上一代 A100 相比,AI 推理能力提升 30 倍。其核心采用的是 TSMC 目前最先進的 4nm 工藝,H100 使用雙精度 Tensor Core 的 FLOPS 提升 3 倍。
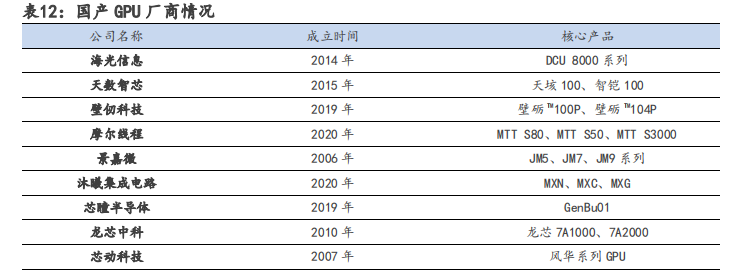
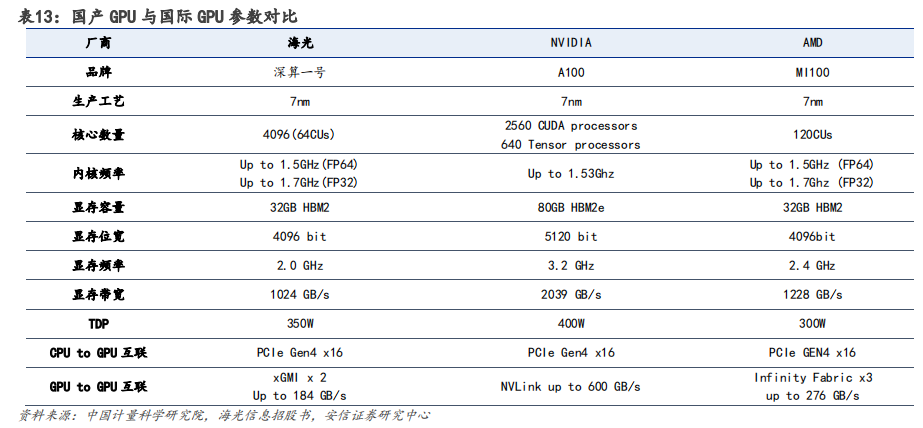
在算力需求快速增長的進程中,國產 GPU 正面臨機遇與挑戰并存的局面。目前,國產 GPU 廠商的核心架構多為自研,難度極高,需投入海量資金以及高昂的人力和時間成本。由于我國 GPU 行業起步較晚,缺乏相應生態,目前同國際一流廠商仍存在較大差距。在中美摩擦加劇、經濟全球化逆行的背景下,以海光信息、天數智芯、壁仞科技和摩爾線程等為代表的國內 GPU 廠商進展迅速,國產 GPU 自主可控未來可期。
以Open AI的算力基礎設施為例,芯片層面 GPGPU 的需求最為直接受益,其次是 CPU、AI 推理芯片、FPGA 等。AI 服務器市場的擴容,同步帶動高速網卡、HBM、DRAM、NAND、PCB 等需求提升。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4775瀏覽量
129357 -
AI
+關注
關注
87文章
31520瀏覽量
270335 -
算力
+關注
關注
1文章
1014瀏覽量
14957
原文標題:大模型訓練,英偉達Turing、Ampere和Hopper算力分析
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
通往AGI之路:揭秘英偉達A100、A800、H800、V100在高性能計算與大模型訓練中的霸主地位






 工商網監
工商網監
評論