") 涌現(xiàn)能力的定義、常見的激發(fā)手段和具體的分類和任務(wù)
涌現(xiàn)能力的定義、常見的激發(fā)手段和具體的分類和任務(wù)
摘要
一個(gè)一直以來的共識(shí)是,模型的規(guī)模越大,模型在下游任務(wù)上的能力越多、越強(qiáng)。隨著最近的新的模型的提出,大規(guī)模的語言模型出現(xiàn)了很多超乎研究者意料的能力。我們針對(duì)這些在小模型上沒有出現(xiàn),但是在大模型上出現(xiàn)的不可預(yù)測(cè)的能力——“涌現(xiàn)能力”做了一些歸納和總結(jié),分別簡(jiǎn)要介紹了涌現(xiàn)能力的定義、常見的激發(fā)手段和具體的分類和任務(wù)。
縮放法則(Scaling Law)
Kaplan J等人[1]在 2020 年提出縮放法則,給出的結(jié)論之一是:模型的性能強(qiáng)烈依賴于模型的規(guī)模,具體包括:參數(shù)數(shù)量、數(shù)據(jù)集大小和計(jì)算量,最后的模型的效果(圖中表現(xiàn)為loss值降低)會(huì)隨著三者的指數(shù)增加而線性提高(對(duì)于單個(gè)變量的研究基于另外兩個(gè)變量不存在瓶頸)。這意味著模型的能力是可以根據(jù)這三個(gè)變量估計(jì)的,提高模型參數(shù)量,擴(kuò)大數(shù)據(jù)集規(guī)模都可以使得模型的性能可預(yù)測(cè)地提高。Cobbe等人[2]的工作提出縮放定律同樣適用于微調(diào)過程。
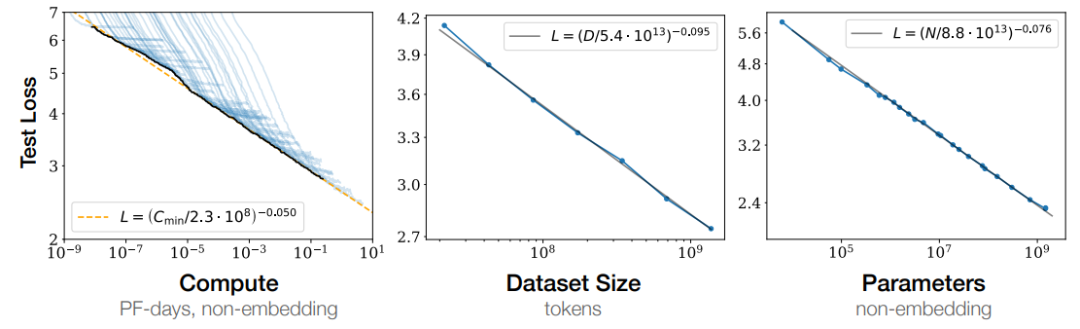
圖1:Loss值隨計(jì)算資源、數(shù)據(jù)規(guī)模大小和參數(shù)量的指數(shù)提升呈線性下降
縮放定律的一個(gè)重要作用就是預(yù)測(cè)模型的性能,但是隨著規(guī)模的擴(kuò)大,模型的能力在不同的任務(wù)上并不總表現(xiàn)出相似的規(guī)律。在很多知識(shí)密集型任務(wù)上,隨著模型規(guī)模的不斷增長(zhǎng),模型在下游任務(wù)上的效果也不斷增加;但是在其他的復(fù)雜任務(wù)上(例如邏輯推理、數(shù)學(xué)推理或其他需要多步驟的復(fù)雜任務(wù)),當(dāng)模型小于某一個(gè)規(guī)模時(shí),模型的性能接近隨機(jī);當(dāng)規(guī)模超過某個(gè)臨界的閾值時(shí),性能會(huì)顯著提高到高于隨機(jī)(如下圖所示)。這種無法通過小規(guī)模模型的實(shí)驗(yàn)結(jié)果觀察到的相變,我們稱之為“涌現(xiàn)能力”。
涌現(xiàn)能力的概述
涌現(xiàn)能力的定義
在其他的學(xué)科中已經(jīng)有很多與“涌現(xiàn)能力”相關(guān)的研究了,不同學(xué)科解釋的方式和角度也不盡相同。物理學(xué)中對(duì)“涌現(xiàn)能力”的定義[3]是:
當(dāng)系統(tǒng)的量變導(dǎo)致行為的質(zhì)變的現(xiàn)象(Emergence is when quantitative changes in a system result in qualitative changes in behavior)。
對(duì)于大規(guī)模語言模型的涌現(xiàn)能力,在 Jason Wei 等人的工作中[4]的工作中,給出的定義:
在小模型中沒有表現(xiàn)出來,但是在大模型中變現(xiàn)出來的能力"(An ability is emergent if it is not present in smaller models but is present in larger models.)。
涌現(xiàn)能力大概可以分為兩種:通過提示就可以激發(fā)的涌現(xiàn)能力和使用經(jīng)過特殊設(shè)計(jì)的prompt激發(fā)出的新的能力。
基于普通提示的涌現(xiàn)能力
通過 prompt 激發(fā)大模型能力的方法最早在GPT3[5]的論文中提出提示范式的部分加以介紹:給定一個(gè)提示(例如一段自然語言指令),模型能夠在不更新參數(shù)的情況下給出回復(fù)。在此基礎(chǔ)上,Brown等在同一篇工作中提出了Few-shot prompt,在提示里加入輸入輸出實(shí)例,然后讓模型完成推理過程。這一流程與下游任務(wù)規(guī)定的輸入輸出完全相同,完成任務(wù)的過程中不存在其他的中間過程。
下圖展示了來自不同的工作的對(duì)于大模型的在few-shot下測(cè)試結(jié)果。其中,橫坐標(biāo)為模型訓(xùn)練的預(yù)訓(xùn)練規(guī)模(FLOPs:floating point operations,浮點(diǎn)運(yùn)算數(shù)。一個(gè)模型的訓(xùn)練規(guī)模不僅和參數(shù)有關(guān),也和數(shù)據(jù)多少、訓(xùn)練輪數(shù)有關(guān),因此用FLOPs綜合地表示一個(gè)模型的規(guī)模);縱軸為下游任務(wù)的表現(xiàn)。可以發(fā)現(xiàn),當(dāng)模型規(guī)模在一定范圍內(nèi)時(shí)(大多FLOPs在10^22以內(nèi)),模型的能力并沒有隨著模型規(guī)模的提升而提高;當(dāng)模型超過一個(gè)臨界值時(shí),效果會(huì)馬上提升,而且這種提升和模型的結(jié)構(gòu)并沒有明顯的關(guān)系。
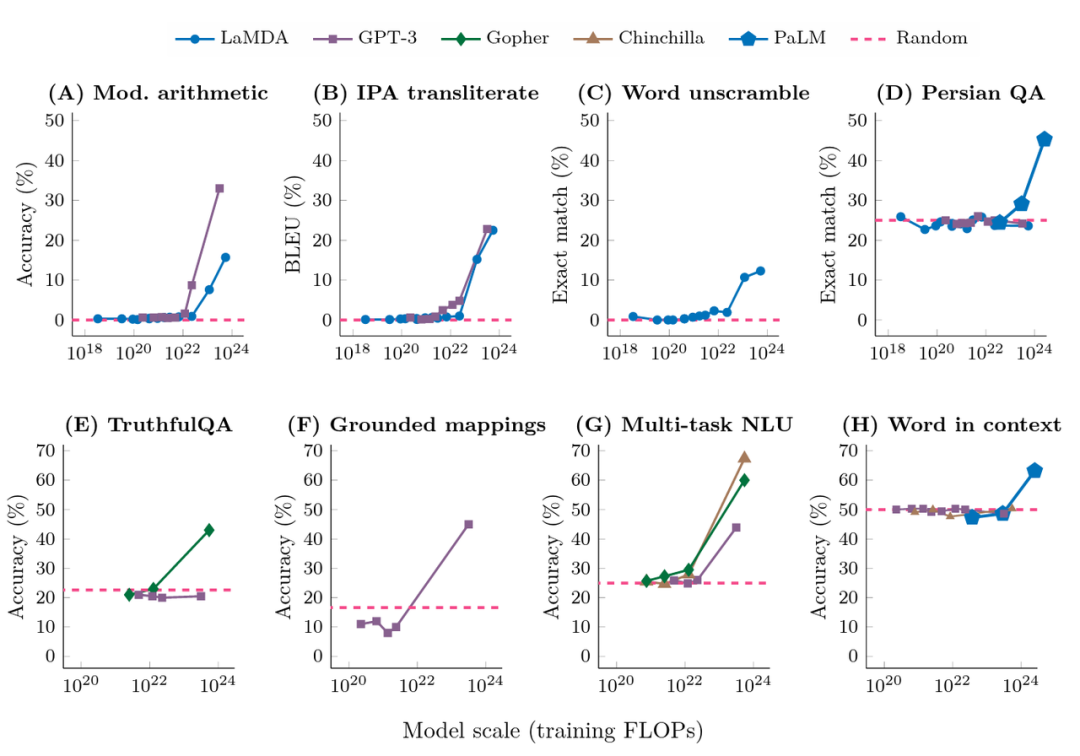
圖2:在普通prompt方式下,不同任務(wù)上的效果隨模型訓(xùn)練的計(jì)算量的提升的變化
基于增強(qiáng)提示的激發(fā)方法
隨著對(duì)大規(guī)模語言模型的研究越來越深入,為大模型添加prompt的方式也越來越多,主要表現(xiàn)出的一個(gè)趨勢(shì)是,相比于普通的 few-shot 模式(只有輸入輸出)的 prompt 方式,新的方法會(huì)讓模型在完成任務(wù)的過程中擁有更多的中間過程,例如一些典型的方法:思維鏈(Chain of Thought)[6]、寄存器(Scratchpad)[7]等等,通過細(xì)化模型的推理過程,提高模型的下游任務(wù)的效果。
下圖展示了各種增強(qiáng)提示的方法對(duì)于模型的作用效果,具體的任務(wù)類型包括數(shù)學(xué)問題、指令恢復(fù)、數(shù)值運(yùn)算和模型校準(zhǔn),橫軸為訓(xùn)練規(guī)模,縱軸為下游任務(wù)的評(píng)價(jià)方式。與上圖類似,在一定的規(guī)模以上,模型的能力才隨著模型的規(guī)模突然提高;在這個(gè)閾值以下的現(xiàn)象則不太明顯。當(dāng)然,在這一部分,不同的任務(wù)采用的激發(fā)方式不同,模型表現(xiàn)出的能力也不盡相同,我們會(huì)在下文分類介紹。
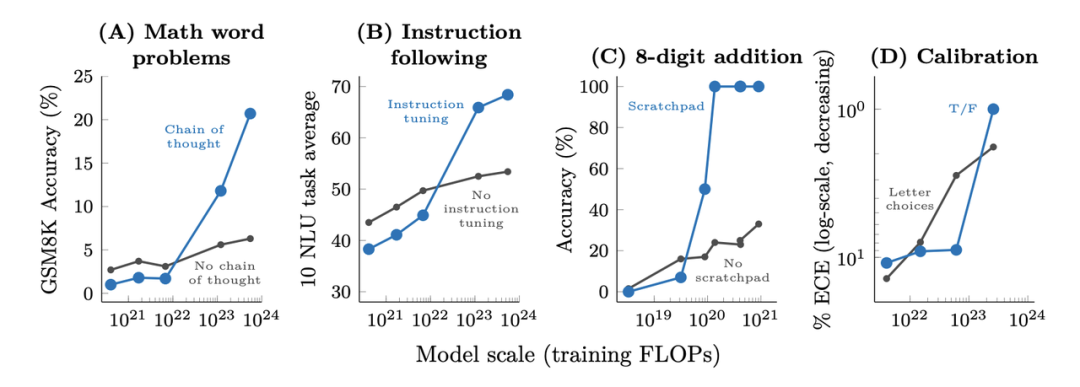
圖3:在增強(qiáng)的prompt方式下,一些復(fù)雜任務(wù)的效果隨模型訓(xùn)練的計(jì)算量提升而提升
不同的涌現(xiàn)能力的介紹
在這一部分,我們并沒有沿用Jason Wei 等人[4]的工作中以使用方法分類的脈絡(luò),因?yàn)橥环N方式激發(fā)出的能力可能能應(yīng)用于多個(gè)任務(wù),多種激發(fā)方式也可能只是不同程度地提升同種能力;我們采用Yao等人[8]的方式,從能力出發(fā),對(duì)不同的方法激發(fā)出的能力和激發(fā)效果進(jìn)行總結(jié)。
優(yōu)秀的上下文學(xué)習(xí)能力
大規(guī)模的語言模型展現(xiàn)出了優(yōu)秀的上下文學(xué)習(xí)能力(In-context learning)。這種能力并非大模型專屬,但是大模型的足夠強(qiáng)大的上下文學(xué)習(xí)能力是之后各種涌現(xiàn)能力激發(fā)的基礎(chǔ)。類似于無監(jiān)督的預(yù)測(cè),在上下文學(xué)習(xí)過程中,不需要對(duì)模型進(jìn)行參數(shù)調(diào)整,只需要在輸入測(cè)試樣例之前輸入少量帶有標(biāo)注的數(shù)據(jù),模型就可以預(yù)測(cè)出測(cè)試樣例的答案。
有關(guān)上下文學(xué)習(xí)的能力來源仍然有很多討論。在 Min等人[9]的實(shí)驗(yàn)中,分析了上下文學(xué)習(xí)能力的作用原理。實(shí)驗(yàn)表明,上下文學(xué)習(xí)的過程中,prompt中的ground truth信息并不重要,重要的是prompt中實(shí)例的形式,以及輸入空間與標(biāo)簽空間是否與測(cè)試數(shù)據(jù)一致。Xie 等人的工作[10]將上下文學(xué)習(xí)的過程理解為一個(gè)貝葉斯推理的過程,在in-context learning的過程中,模型先基于prompt推測(cè)concept,然后基于concept和prompt生成output。在對(duì)多個(gè)樣例進(jìn)行觀測(cè)的過程中,prompt中的數(shù)據(jù)會(huì)給concept提供“信號(hào)”(與預(yù)訓(xùn)練過程中的相似之處)和“噪聲”(與預(yù)訓(xùn)練過程分布差別較大之處),當(dāng)信號(hào)大于噪聲時(shí),模型就可以推理成功。
可觀的知識(shí)容量
在問答和常識(shí)推理任務(wù)上需要模型具有較好的知識(shí)推理能力,在這種情況下,對(duì)大型模型進(jìn)行提示不一定優(yōu)于精調(diào)小型模型。但是大模型擁有更高的標(biāo)注效率,因?yàn)椋?/p>
在許多數(shù)據(jù)集中,為了獲得所需的背景/常識(shí)知識(shí),小模型需要一個(gè)外部語料庫(kù)/知識(shí)圖譜來檢索,或者需要通過多任務(wù)學(xué)習(xí)在增強(qiáng)的數(shù)據(jù)上進(jìn)行訓(xùn)練
對(duì)于大型語言模型,可以直接去掉檢索器,僅依賴模型的內(nèi)部知識(shí),且無需精調(diào)
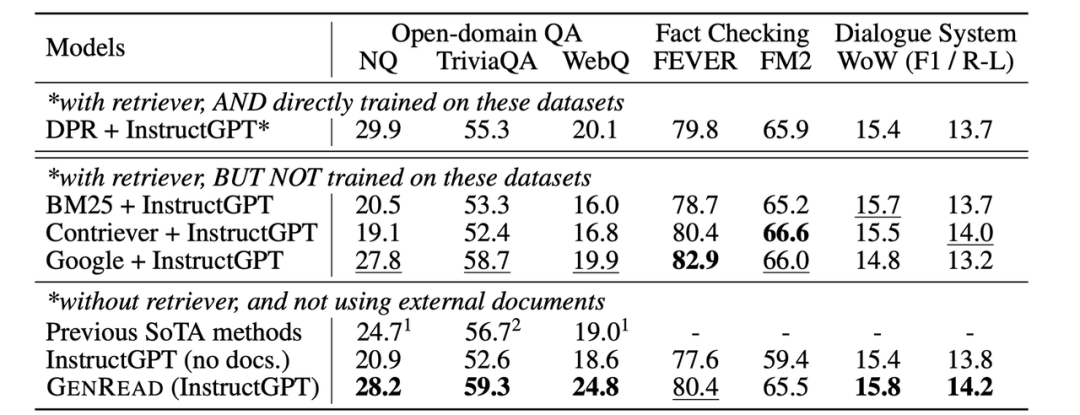
圖4:之前的需要外部檢索的SOTA和GPT-3的性能對(duì)比
上表來自于 Yu等人[11]的工作。如表中所示,雖然在常識(shí)/開放域問答任務(wù)上GPT-3 并沒有明顯優(yōu)于之前的精調(diào)模型,但它不需要從外部文檔中檢索,因?yàn)槠浔旧砭桶酥R(shí)。
為了理解這些結(jié)果的重要性,我們可以回顧一下NLP的發(fā)展歷史:NLP 社區(qū)從一開始就面對(duì)著如何有效編碼知識(shí)的挑戰(zhàn)。研究者們一直在不斷探索如何把知識(shí)保存在模型外部或者內(nèi)部的方法。上世紀(jì)九十年代以來,研究者們一直試圖將語言和世界的規(guī)則記錄到一個(gè)巨大的圖書館中,將知識(shí)存儲(chǔ)在模型之外。但這是十分困難的,畢竟我們無法窮舉所有規(guī)則。因此,研究人員開始構(gòu)建特定領(lǐng)域的知識(shí)庫(kù),來存儲(chǔ)非結(jié)構(gòu)化文本、半結(jié)構(gòu)化(如維基百科)或完全結(jié)構(gòu)化(如知識(shí)圖譜)等形式的知識(shí)。通常,結(jié)構(gòu)化知識(shí)很難構(gòu)建,但易于推理,非結(jié)構(gòu)化知識(shí)易于構(gòu)建,但很難用于推理。然而,語言模型提供了一種新的方法,可以輕松地從非結(jié)構(gòu)化文本中提取知識(shí),并在不需要預(yù)定義模式的情況下有效地根據(jù)知識(shí)進(jìn)行推理。下表為優(yōu)缺點(diǎn)對(duì)比:
| 構(gòu)建 | 推理 | |
|---|---|---|
| 結(jié)構(gòu)化知識(shí) | 難構(gòu)建需要設(shè)計(jì)體系結(jié)構(gòu)并解析 | 容易推理有用的結(jié)構(gòu)已經(jīng)定義好了 |
| 非結(jié)構(gòu)化知識(shí) | 容易構(gòu)建只存儲(chǔ)文本即可 | 難推理需要抽取有用的結(jié)構(gòu) |
| 語言模型 | 容易構(gòu)建在非結(jié)構(gòu)化文本上訓(xùn)練 | 容易推理使用提示詞即可 |
優(yōu)秀的泛化性
在 2018 年至 2022 年期間,NLP、CV 和通用機(jī)器學(xué)習(xí)領(lǐng)域有大量關(guān)于分布偏移/對(duì)抗魯棒性/組合生成的研究,人們發(fā)現(xiàn)當(dāng)測(cè)試集分布與訓(xùn)練分布不同時(shí),模型的行為性能可能會(huì)顯著下降。然而,在大型語言模型的上下文學(xué)習(xí)中似乎并非如此。

圖5: GPT-3的同分布和不同分布之間的對(duì)比,以及和RoBERTa的對(duì)比
上圖來自Si等人[12]在2022年的研究,在此實(shí)驗(yàn)中,同分布情況下基于prompt的 GPT-3 的效果并沒有精調(diào)后的 RoBERTa要好。但它在三個(gè)其他分布(領(lǐng)域切換、噪聲和對(duì)抗性擾動(dòng))中優(yōu)于 RoBERTa,這意味著 GPT3 更加魯棒。
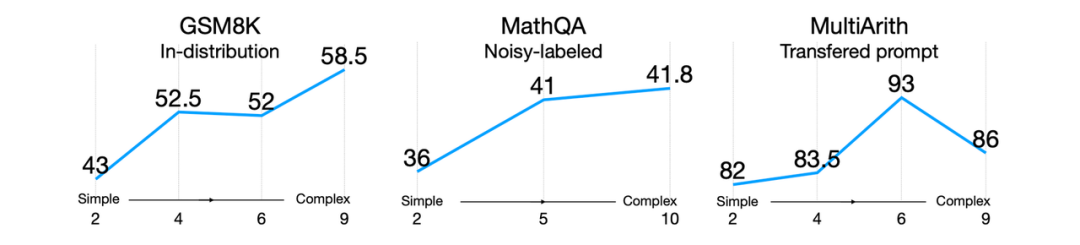
圖6:不同復(fù)雜程度的提示在不同分布中對(duì)模型效果的影響
此外,即使存在分布偏移,好的提示詞所帶來的泛化性能依舊會(huì)繼續(xù)保持。比如Fu 等人[13]2022年的研究(上圖所示),輸入提示越復(fù)雜,模型的性能就越好。這種趨勢(shì)在分布轉(zhuǎn)移的情況下也會(huì)繼續(xù)保持:無論測(cè)試分布與原分布不同、來自于噪聲分布,或者是從另一個(gè)分布轉(zhuǎn)移而來的,復(fù)雜提示始終優(yōu)于簡(jiǎn)單提示。
復(fù)雜推理能力
復(fù)雜推理能力包含若干方面,如數(shù)學(xué)推理能力、代碼生成、腳本生成等等,以下的介紹我們以數(shù)學(xué)推理能力為例。數(shù)學(xué)推理的一個(gè)典型的數(shù)據(jù)集是GSM8K,其由8.5K個(gè)人工標(biāo)注的高質(zhì)量的小學(xué)數(shù)學(xué)問題組成。數(shù)據(jù)集的標(biāo)注內(nèi)容不僅包含最終結(jié)果,還包含得到結(jié)果的2~8個(gè)推理步驟。
在最開始的GPT3的論文中,對(duì)于這個(gè)任務(wù)的學(xué)習(xí)方式仍然是微調(diào)的方式,得到的結(jié)果基本符合縮放定律。作者在論文里得出一個(gè)結(jié)論:
175B的模型仍然需要兩個(gè)額外數(shù)量級(jí)的訓(xùn)練數(shù)據(jù)才能達(dá)到80%的準(zhǔn)確率。
但是在之后的工作中,通過其他的方式大大提高了該任務(wù)上的結(jié)果。Wei等人[6]通過思維鏈的方式,將540B的PaLM模型上的準(zhǔn)確率提高到56.6%,這一過程并沒有微調(diào),而是將8個(gè)提示示例作為prompt,通過few-shot的方式激發(fā)模型的推理能力。在此基礎(chǔ)上,Wang等人[14]通過多數(shù)投票的方式,將這一準(zhǔn)確率提高到74.4%。Yao等人[15]提出Complexity-based Prompting,通過使用更復(fù)雜、推理步驟更多的樣例作為prompt,進(jìn)一步提高模型的效果。在此之外,數(shù)據(jù)集的難度也越來越高:Chung等人[16]將測(cè)試范圍擴(kuò)展到高中的各個(gè)學(xué)科;Minerva[17]的工作將測(cè)試范圍擴(kuò)展到大學(xué)的各個(gè)學(xué)科;Jiang等人[18]進(jìn)一步將測(cè)試范圍擴(kuò)展到國(guó)際數(shù)學(xué)奧林匹克問題上。
我們看到,從涌現(xiàn)能力的角度講,模型在在達(dá)到一定規(guī)模后,用恰當(dāng)?shù)姆绞郊ぐl(fā)出的性能確實(shí)遠(yuǎn)遠(yuǎn)超過縮放法則所預(yù)測(cè)的效果;與此同時(shí),各種方法都是few-shot或zero-shot的方式,需要的數(shù)據(jù)也更少。現(xiàn)在并沒有太多工作能夠直接對(duì)比在同樣的足夠大的模型上,微調(diào)和prompting的方式的性能差距;但是在下游任務(wù)數(shù)據(jù)集的規(guī)模往往遠(yuǎn)小于模型充足訓(xùn)練所需要的數(shù)據(jù)規(guī)模的情境下,利用prompting激發(fā)模型本來的能力確實(shí)能夠顯著提高效果,這也是目前大多數(shù)任務(wù)面臨的情況。
涌現(xiàn)能力是海市蜃樓?
在斯坦福大學(xué)最新的工作[19]中指出,大模型的涌現(xiàn)能力來自于其不連續(xù)的評(píng)價(jià)指標(biāo),這種不連續(xù)的評(píng)價(jià)指標(biāo)導(dǎo)致了模型性能在到達(dá)一定程度后出現(xiàn)“大幅提升”。如果換成更為平滑的指標(biāo),我們會(huì)發(fā)現(xiàn)相對(duì)較小的模型的效果也并非停滯不前,規(guī)模在閾值以下的模型,隨著規(guī)模的提高,生成的內(nèi)容也在逐漸靠近正確答案。
為了驗(yàn)證這一觀點(diǎn),斯坦福的研究人員做了兩組實(shí)驗(yàn),第一組是將NLP中不連續(xù)的非線性評(píng)價(jià)指標(biāo)轉(zhuǎn)為連續(xù)的線性評(píng)價(jià)指標(biāo),結(jié)果如下圖所示,模型的涌現(xiàn)能力消失了(從圖2到下圖)。
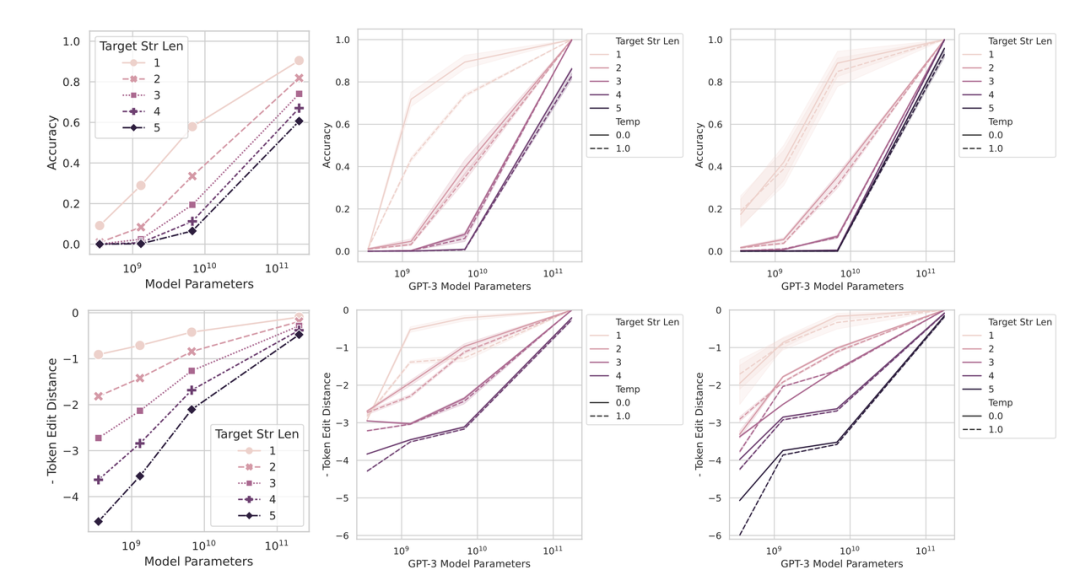
圖7:不同類型指標(biāo)下,不同規(guī)模的模型的性能對(duì)比。當(dāng)換為更加平滑的指標(biāo)后,小模型的性能也隨著規(guī)模擴(kuò)大而逐步提高
第二組實(shí)驗(yàn)是將CV任務(wù)中的連續(xù)指標(biāo)轉(zhuǎn)換為了類似NLP中的不連續(xù)指標(biāo),結(jié)果如下圖所示,CV任務(wù)中也出現(xiàn)了涌現(xiàn)能力:
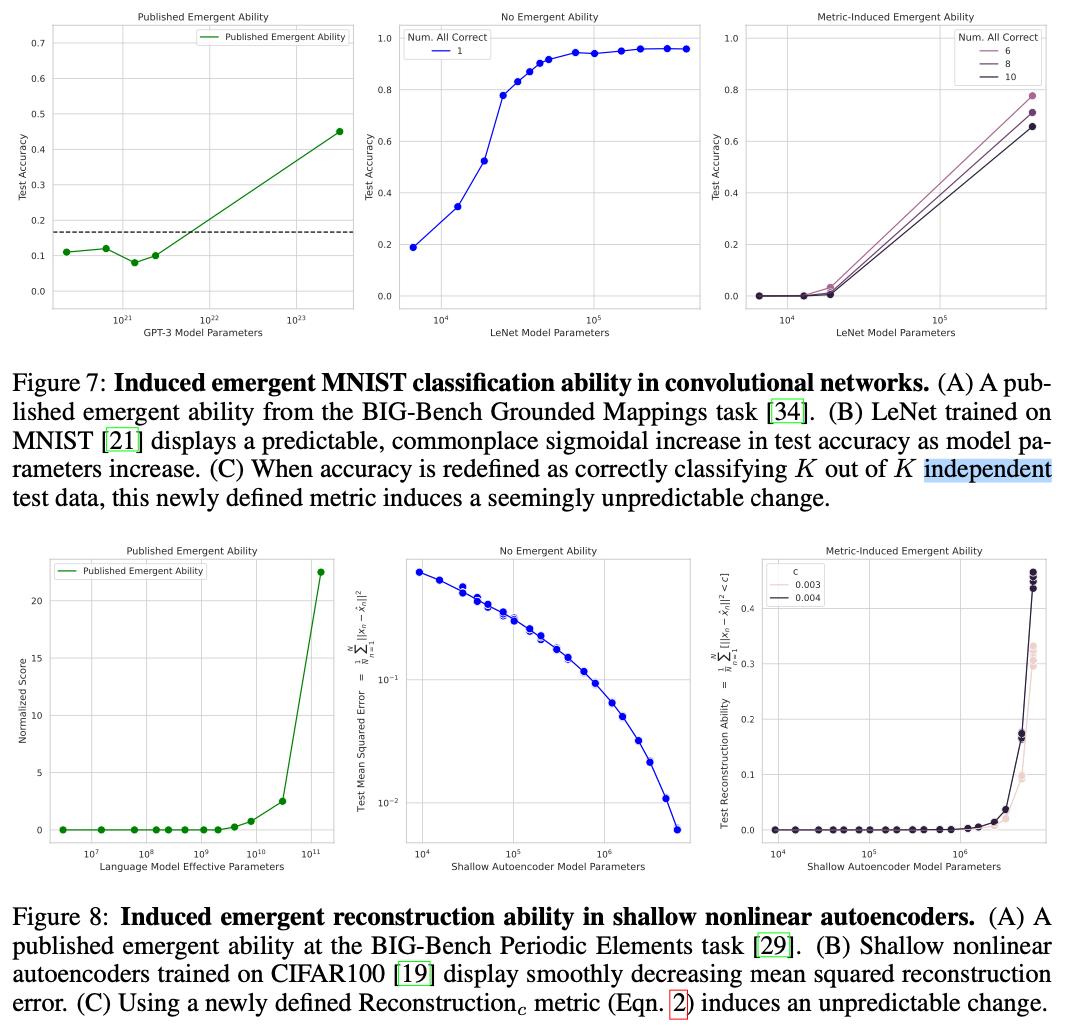
圖8:更換指標(biāo)之后,cv任務(wù)中的模型規(guī)模與模型效果之間的關(guān)系。當(dāng)換為不平滑指標(biāo)后,cv任務(wù)中的模型也出現(xiàn)類似的“涌現(xiàn)能力”
因此LLM中的涌現(xiàn)能力到底是什么,又是如何出現(xiàn)的,依然值得研究者們研究。
結(jié)語
本文簡(jiǎn)要介紹了涌現(xiàn)能力,具體包括涌現(xiàn)能力之前的縮放法則,涌現(xiàn)能力的定義,涌現(xiàn)能力的分類,還簡(jiǎn)要介紹了不同涌現(xiàn)能力的典型激發(fā)方法。當(dāng)然,歸根結(jié)底,“涌現(xiàn)能力”只是對(duì)一種現(xiàn)象的描述,而并非模型的某種真正的性質(zhì),關(guān)于其出現(xiàn)原因的研究也越來越多。現(xiàn)有的一些工作認(rèn)為,模型的涌現(xiàn)能力的出現(xiàn)是和任務(wù)的評(píng)價(jià)目標(biāo)的平滑程度相關(guān)的。在之后的工作中,更好的評(píng)級(jí)方式,更高的數(shù)據(jù)質(zhì)量,更出乎人意料的prompt方式,都可能會(huì)更進(jìn)一步提高模型的效果,并讓觀測(cè)到的效果得到更客觀的評(píng)價(jià)。
審核編輯 :李倩
-
寄存器
+關(guān)注
關(guān)注
31文章
5363瀏覽量
121198 -
模型
+關(guān)注
關(guān)注
1文章
3313瀏覽量
49232 -
語言模型
+關(guān)注
關(guān)注
0文章
538瀏覽量
10342
原文標(biāo)題:摘要
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
ucos_ii 每個(gè)任務(wù)具體定義棧大小
常見電機(jī)分類和驅(qū)動(dòng)原理動(dòng)畫是什么
電器的定義和分類
流分類算法的定義和要求
如何利用機(jī)器學(xué)習(xí)思想,更好地去解決NLP分類任務(wù)

如何開發(fā)與自定義應(yīng)用的音頻分類模
3.小白初學(xué)UCosIII STM32F429 任務(wù)的定義與任務(wù)切換的實(shí)現(xiàn)1

圖像分類任務(wù)的各種tricks
淺談工業(yè)連接器的定義和分類
freeRTOS用于任務(wù)之間同步的手段事件標(biāo)志組
PyTorch文本分類任務(wù)的基本流程
TDengine+OpenVINO+AIxBoard助力時(shí)序數(shù)據(jù)分類





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論