") NVIDIA NeMo 如何支持對(duì)話式 AI 任務(wù)的訓(xùn)練與推理?
NVIDIA NeMo 如何支持對(duì)話式 AI 任務(wù)的訓(xùn)練與推理?
編輯推薦
大模型驅(qū)動(dòng)的對(duì)話式 AI 正在引發(fā)新一輪的商業(yè)增量。對(duì)話式機(jī)器人正在不同領(lǐng)域發(fā)揮著越來(lái)越大的作用,幫助企業(yè)用戶解決客戶服務(wù)等難題,提高客戶的體驗(yàn)。然而,盡管技術(shù)已經(jīng)趨近成熟,門檻大大降低,開(kāi)發(fā)和運(yùn)行可落地的語(yǔ)音人工智能服務(wù)仍然是一項(xiàng)復(fù)雜而艱巨的任務(wù),通常需要面臨實(shí)時(shí)性、可理解性、自然性、低資源、魯棒性等挑戰(zhàn)。
本期分享我們邀請(qǐng)到了NVIDIA 的解決方案架構(gòu)師丁文,分享如何使用 NVIDIA NeMo 進(jìn)行對(duì)話式 AI 任務(wù)的訓(xùn)練和推理,從而幫助開(kāi)發(fā)者快速構(gòu)建、訓(xùn)練和微調(diào)對(duì)話式人工智能模型。
本文轉(zhuǎn)載自DataFunSummit
01?
NeMo 背景介紹
1. NeMo 和對(duì)話式 AI 的整體介紹
NeMo 工具是一個(gè)用于對(duì)話式 AI 的深度學(xué)習(xí)工具,它可以用于自動(dòng)語(yǔ)音識(shí)別( ASR,Automatic Speech Recognition)、自然語(yǔ)言處理(NLP,Natural Language Processing)、語(yǔ)音合成( TTS,Text to Speech)等多個(gè)對(duì)話式 AI 相關(guān)任務(wù)的訓(xùn)練和推理。下面的這張圖給出了一個(gè)對(duì)話式 AI 的全流程。
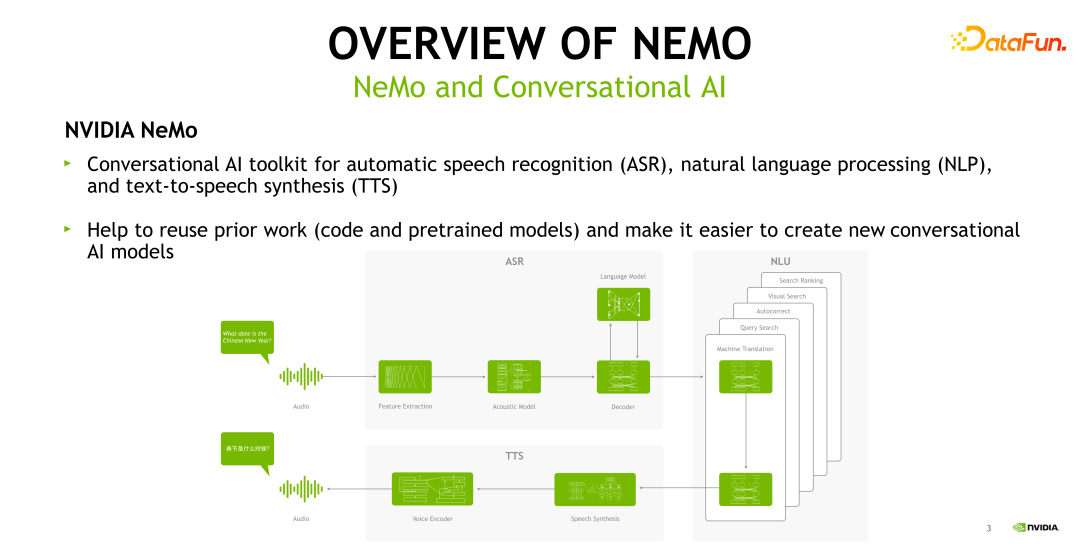
對(duì)話式 AI 的輸入是一個(gè)音頻,音頻首先會(huì)進(jìn)入 ASR 模塊,ASR 模塊包括了特征提取、聲學(xué)模型、語(yǔ)言模型以及解碼器,識(shí)別出來(lái)的文本接著進(jìn)入 NLU 模塊,根據(jù)不同的業(yè)務(wù)需求進(jìn)行相應(yīng)的處理,如機(jī)器翻譯或者是 query 匹配等。以機(jī)器翻譯為例,我們將英文文本翻譯成中文文本,接著將中文文本輸入 TTS 模塊,最終輸出一個(gè)語(yǔ)音段。整個(gè) pipeline 均可在 NeMo 中實(shí)現(xiàn)。NeMo 希望協(xié)助 AI 從業(yè)者利用已有的代碼或 pretrained模型,加快搭建語(yǔ)音語(yǔ)言相關(guān)的任務(wù)。整個(gè) pipeline 的開(kāi)始和結(jié)束分別是 ASR 和 TTS。這兩個(gè)部分屬于 speech AI 的一個(gè)領(lǐng)域,也是今天重點(diǎn)討論的范圍。
2. Speech AI—— ASR 的背景介紹
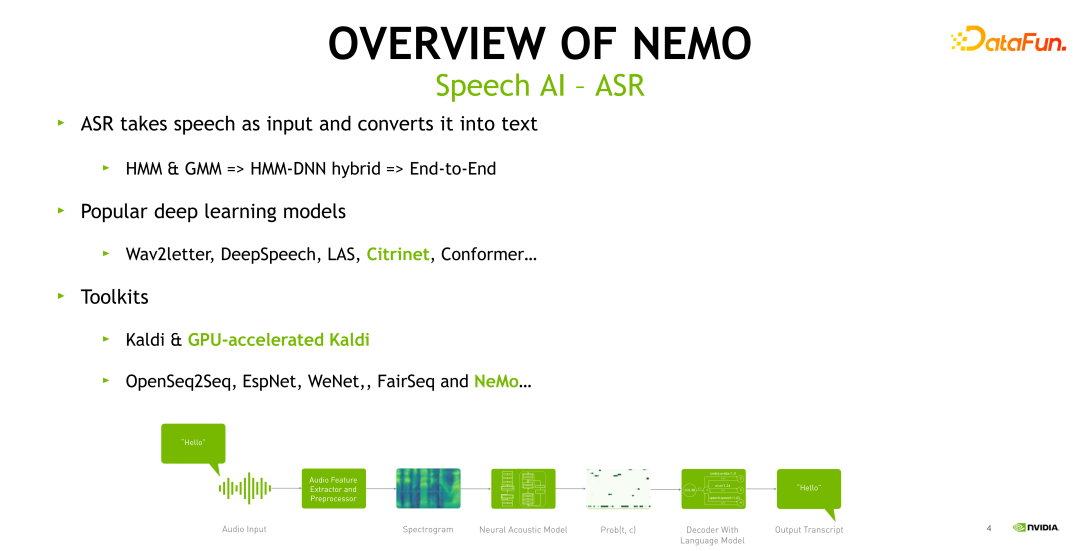
本節(jié)主要對(duì) ASR 進(jìn)行簡(jiǎn)單的回顧和概述。ASR是將語(yǔ)音轉(zhuǎn)換成文字的一個(gè)過(guò)程。傳統(tǒng)的 ASR 建模方法是基于隱馬爾可夫( HMM )和混合高斯模型(GMM)進(jìn)行建模。2015 年微軟首次將神經(jīng)網(wǎng)絡(luò)引入到語(yǔ)音識(shí)別建模當(dāng)中,使用神經(jīng)網(wǎng)絡(luò)來(lái)建模基于給定的音頻幀,HMM 狀態(tài)的后驗(yàn)概率分布,并使用 HMM 進(jìn)行混合解碼得到文本。
近些年,得益于算力和數(shù)據(jù)的豐富,端到端的 ASR 得到了廣泛的關(guān)注。端到端的 ASR 也使得整個(gè)語(yǔ)音建模過(guò)程的 pipeline 更加簡(jiǎn)潔。上圖給出了一個(gè)典型 ASR 的 pipeline。輸入的語(yǔ)音首先進(jìn)入特征提取和前處理模塊,以獲得頻譜特征。接著輸入到神經(jīng)網(wǎng)絡(luò)的聲學(xué)模型里。最后解碼器結(jié)合語(yǔ)言模型輸出一個(gè)文本。近年流行的神經(jīng)網(wǎng)絡(luò)模型結(jié)構(gòu)包括 Wav2letter,DeepSpeech,LAS,Citrinet 以及現(xiàn)在非常熱門的 Conformer。常見(jiàn)的語(yǔ)音識(shí)別工具包括 Kaldi,它也是語(yǔ)音識(shí)別當(dāng)中最重要的工具之一, NVIDIA 針對(duì) Kaldi 做了一系列的優(yōu)化。Kaldi 主要支持 hybrid 系統(tǒng)及部分常見(jiàn)神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。第二類的工具是基于 PyTorch 或者是 Tensorflow 的開(kāi)源工具,例如 OpenSeq2Seq、EspNet、WeNet 以及 NeMo。
3. NeMo 對(duì) ASR 的支持
下面介紹 NeMo 目前支持的 ASR 的幾個(gè)方面。

它主要支持的模型結(jié)構(gòu)包括傳統(tǒng)的 LSTM 以及由 NVIDIA 的 NeMo 團(tuán)隊(duì)提出的 Jasper 家族(包括 Jasper,QuartzNet,Citrinet 等純 CNN 的結(jié)構(gòu)),以及現(xiàn)在比較主流的模型如 Conformer 和 Squeezeformer 等。
NeMo 支持 CTC 和 Transducer/RNNT 兩種,也是目前學(xué)術(shù)和工業(yè)界較為關(guān)注的兩種解碼器。語(yǔ)言模型方面,NeMo 支持 N-gram 進(jìn)行 LM fusion 以及神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型進(jìn)行 Rescoring 兩種方式。此外,NeMo 也支持流式訓(xùn)練及解碼,可以配置不同的 chunk size 來(lái)適配不同的業(yè)務(wù)需求。
02
案例:基于 NeMo 訓(xùn)練 ASR 模型
1. ASR 的數(shù)據(jù)準(zhǔn)備

本節(jié)中將以語(yǔ)音識(shí)別為例,介紹如何在 NeMo 里快速地搭建語(yǔ)音識(shí)別模型,會(huì)按照前面所提的語(yǔ)音 ASR 各個(gè)模塊逐一介紹。
NeMo 中通過(guò)配置 config 文件來(lái)使用不同的模塊和參數(shù)。首先,需要準(zhǔn)備數(shù)據(jù)集的 manifest,它是一個(gè)JSON文件。例子如上圖所示,audio_filepath 需提供各條音頻地址。Duration 是音頻長(zhǎng)度,text 是標(biāo)注好的文本。我們也提供了不同數(shù)據(jù)集的預(yù)處理腳本,例如 Librispeech、中文數(shù)據(jù)集 Aishell-1/2 等。也可以使用 Kaldi2json 腳本將 Kaldi 格式的數(shù)據(jù)轉(zhuǎn)換成 NeMo 訓(xùn)練所需要的格式。配置時(shí)需要指定 train,validation 和 test 三個(gè)部分。上圖右下角給出了示例 train_ds 的配置寫(xiě)法。用戶根據(jù)自己數(shù)據(jù)的情況來(lái)進(jìn)行相應(yīng)配置。它主要包括:manifest_filepath 音頻的路徑;采樣率 sample_rate,通常是 16K 或者是 8K;labels 為訓(xùn)練時(shí)的建模單元;max_duration 是最大音頻長(zhǎng)度,中文里我們通常選取 0.1 秒到 20 秒的長(zhǎng)度區(qū)間,超過(guò)則會(huì)被丟棄。
NeMo 主要支持字(character)、子詞(subword)或者是 BPE(Byte Pair Encoding)作為建模單元。如上圖示例所示,左側(cè)一個(gè)子詞作為一個(gè)建模單元,右側(cè)是一個(gè)字作為單元。若我們以字作為建模單元,則需要在 labels 處指定字典即可。若我們以子詞、BPE 作為建模單元,則需要在 config 中指定對(duì)應(yīng)的 tokenizer。我們也提供從文本中獲得 tokenizer 的腳本。詳見(jiàn)圖片下方的鏈接,可以直接用來(lái)獲取根據(jù)個(gè)人數(shù)據(jù)訓(xùn)練出的 tokenizer。
2. 特征和增強(qiáng)

準(zhǔn)備好數(shù)據(jù)后,首先需要做特征提取,將語(yǔ)音段轉(zhuǎn)換成特征例如梅爾譜或者是 MFCC 特征。NeMo 中用于特征提取模塊有兩個(gè):使用 AudioToMelSpectrogramPreprocessor 提取梅爾譜或者使用 AudioToMFCCPreprocessor 提取 MFCC 特征。上圖右邊給出了一個(gè)示例。如使用梅爾譜特征,需要在 preprocessor 模塊的 target 部分賦值為 AudioToMelSpectrogramPreprocessor。此外,在 ASR 中常用的特征增強(qiáng)與數(shù)據(jù)增強(qiáng)的方式,NeMo 也是支持的。例如 Spec Augmentation,只需在target 處賦值為 SpectrogramAugmentation 即可。NeMo 也支持其他的數(shù)據(jù)增強(qiáng)方式,包括 Speed perturbation 等。
3. 模型結(jié)構(gòu)

處理好特征后,接下來(lái)介紹 NeMo 中如何配置神經(jīng)網(wǎng)絡(luò)模型。以 Conformer 為例,主要的配置是在 encoder 部分。將 target 設(shè)置成 ConformerEncoder。我們可以通過(guò)配置不同的 number of layers(n_layers) 和 dimension(d_model) 來(lái)構(gòu)建不同參數(shù)量的 Conformer 模型。也可以通過(guò)配置 self-attention 相關(guān)參數(shù),如 number of heads(n_heads),以直接調(diào)整參數(shù)量。同時(shí)也支持相對(duì)位置編碼。
NeMo 支持流式的訓(xùn)練和解碼。在這里我們可以通過(guò)配置 att_context_size 來(lái)調(diào)整。[-1,-1] 表示左右可以看到的長(zhǎng)度為無(wú)限長(zhǎng),所以此處是一個(gè)離線模型的配置。
右圖給出了當(dāng)前 NeMo ASR 支持的全部模型,以及任務(wù)的配置文件的列表。比如想訓(xùn)練一個(gè) Conformer 模型,只需要點(diǎn)開(kāi) Conformer 的 folder 就可以看到現(xiàn)在可以支持哪些配置。

NeMo 支持CTC和RNN-Transducer兩種 decoder。如果使用的是 CTC loss,需在 decoder 部分的 target 處設(shè)置成 Conv ASR Decoder。num_classes 指字典或者是 BPE 的詞表大小。如果使用 RNN Transducer loss,需在 decoder 的 target 處設(shè)置為 RNNT Decoder,同時(shí)需要配置 prediction network(prednet) 的 hidden size(pred_hidden)和 number of layers(pred_rnn_layers),同時(shí)還需要配置 joint network。如上圖右側(cè)所示,前往 conformer 文件夾下可以看我們能夠同時(shí)支持 CTC 和 Transducer 的 loss,character 和 BPE 的建模基本單元。另外,若需訓(xùn)練流式 conformer 模型,只需前往 streaming 文件夾內(nèi)便可看到如何操作。
4. Conformer-CTC 配置

結(jié)合上面的介紹,如果想啟動(dòng)一個(gè)基于 Conformer CTC 的語(yǔ)音識(shí)別模型訓(xùn)練,只需前往 NeMo 的 git 倉(cāng)庫(kù)內(nèi) examples/ ASR /conf/conformer,選擇 conformer_ctc_char.yaml,即可進(jìn)行相應(yīng)的配置。需要自行指定的部分,包括最重要的 Dataset。默認(rèn) Spec Augment 是開(kāi)啟的。默認(rèn) Decoder 是 CTC(因?yàn)榍懊孢x擇了 CTC 配置)。默認(rèn)的優(yōu)化器是 Adam。訓(xùn)練使用 PyTorch Lightning。訓(xùn)練時(shí)可以指定 GPU 還是 CPU、以及最大的 epoch。此外,其他的訓(xùn)練配置可以在 Exp_manager 里面進(jìn)行設(shè)置。
5. 訓(xùn)練和評(píng)估

配置完成后,便可以啟動(dòng)訓(xùn)練。只需要調(diào)用 Python 腳本 examples/ASR/ASR_ctc/speech_to_text_ctc.py。config-name 需要設(shè)置成前面配置好的 conformer_ctc_char.yaml。
如果有一些其他參數(shù)需要配置或者是替代,可以在啟動(dòng)訓(xùn)練時(shí)給定一個(gè)值。如想替換訓(xùn)練數(shù)據(jù)集 manifest 的地址,以及指定訓(xùn)練的具體某個(gè) GPU,如果想使用混合精度訓(xùn)練,只需將 trainer.precision 設(shè)置成 16,它就會(huì)用 FP32 和 FP16 的混合精讀訓(xùn)練來(lái)加速整個(gè)訓(xùn)練流程。
訓(xùn)練好模型后,需要測(cè)試評(píng)估,主要使用 speech_to_text_eval.py 文件,可以把訓(xùn)練好的 NeMo 的 checkpoint 填入 model_path。dataset_manifest 填入希望去測(cè)試的一個(gè)集合,格式也是 JSON 文件。如果 metrics 是 CER,這里需要配置 user_cer=True。這樣即可使用 CER 來(lái)衡量語(yǔ)音識(shí)別模型的性能。
6. 部署
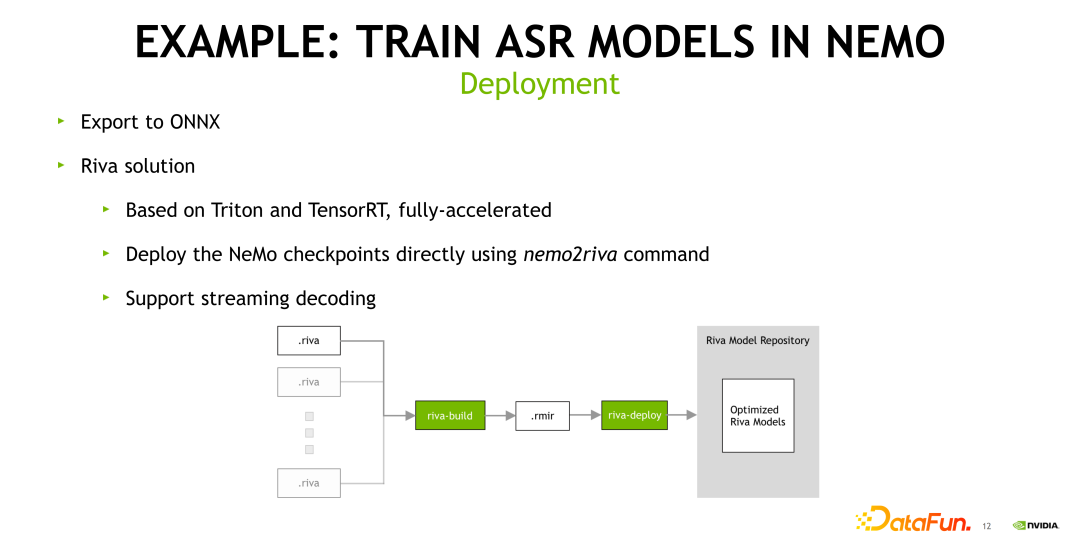
NeMo 具有可以直接部署的方案。NeMo 首先可以支持直接導(dǎo)出到 ONNX。NVIDIA 也有提供相應(yīng)的模型部署的方案,主要是使用 Riva 這個(gè)產(chǎn)品。Riva 使用的是 NVIDIA TensorRT 加速神經(jīng)網(wǎng)絡(luò)模型,并且使用 NVIDIA Triton 進(jìn)行服務(wù)。訓(xùn)練好的 NeMo 模型是可以直接使用 NeMo2riva 命令進(jìn)行轉(zhuǎn)換,從而可以在 Riva 中使用該模型。Riva 中的 ASR 部分也提供流式解碼功能,可以滿足不同的業(yè)務(wù)的需求。
03
?中文支持
1. NeMo 內(nèi)的中文模型及應(yīng)用

下面主要介紹 NeMo 里中文語(yǔ)音支持的情況。首先在 ASR 部分提供了 Aishell-1 和 Aishell-2 兩個(gè)預(yù)處理的腳本,以及一些 pretrained 的模型,包括 Citrinet-CTC 和 Conformer-Transducer。大家可以去 NGC 下載預(yù)訓(xùn)練好的模型進(jìn)行測(cè)試或 finetune。上圖也給出了現(xiàn)在 Conformer transducer 在 Aishell-2 的性能。總體表現(xiàn)較好。此外,如果想使用其他的網(wǎng)絡(luò)結(jié)構(gòu),只需要在配置文件的 labels 處替換成相應(yīng)的字典或者是 BPE 詞表即可。NeMo 加入了對(duì)中文的文本正則化的支持(基于 WFST),便于使用者對(duì)于一些中文數(shù)據(jù)的預(yù)處理。此外,中文的 TTS 也在計(jì)劃支持中。
2. Riva 內(nèi)的中文模型及應(yīng)用

Riva 主要是支持 Citrinet-CTC 和 Conformer-CTC 兩種 ASR 的模型,支持 N-gram LM fusion 的解碼方式,也支持中文標(biāo)點(diǎn)模型。
04
NeMo 對(duì)其他 Speech AI 相關(guān)應(yīng)用的支持
接下來(lái)需要討論的是,已經(jīng)有了一個(gè) ASR 模型,正式去搭建一個(gè)語(yǔ)音識(shí)別服務(wù)時(shí),還需要 Speech AI 其他的哪些功能。
1. 語(yǔ)音端點(diǎn)檢測(cè)
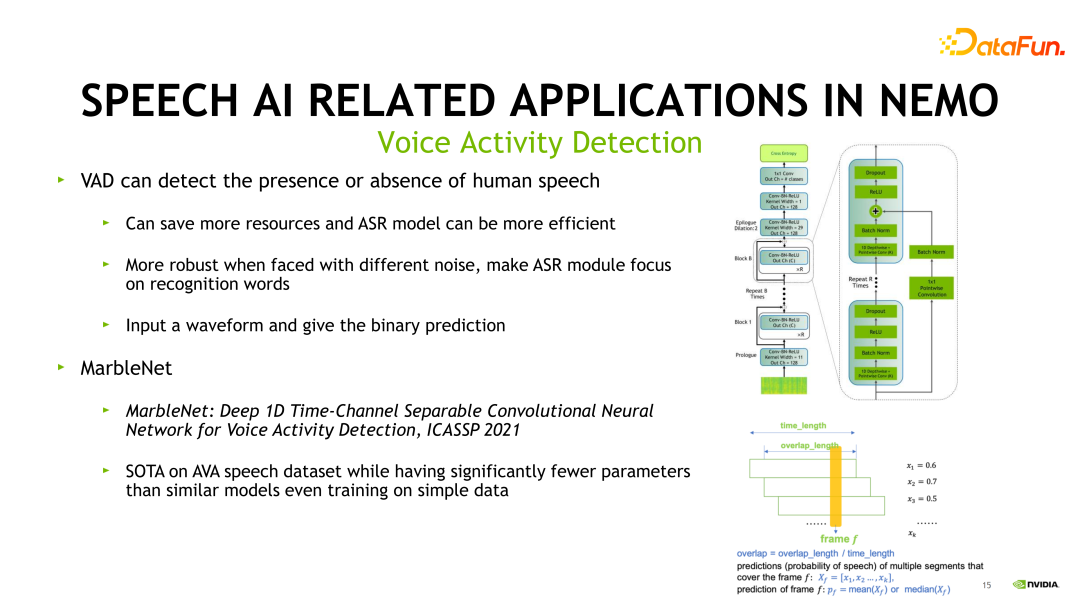
首先需要一個(gè)VAD(Voice Activity Detection)模塊。VAD 是語(yǔ)音端點(diǎn)檢測(cè),可以檢測(cè)出音頻中的人聲段,通常是很多語(yǔ)音識(shí)別任務(wù)的前置模塊,用來(lái)過(guò)濾出有效的人聲段。它能夠節(jié)省很多資源,使 ASR 或者后續(xù)的其他語(yǔ)音任務(wù)更加高效,同時(shí)面對(duì)不同噪聲能夠更加魯棒,讓 ASR 能夠 focus 在識(shí)別的任務(wù)本身。它可以看作是把音頻判斷出 Label 為“是人聲”和“不是人聲”的一個(gè)二分類任務(wù)。在 NeMo 中,我們主要使用的 VAD 模型是 MarbleNet。它的結(jié)構(gòu)見(jiàn)上圖右側(cè),它也是 Jasper 家族的一個(gè)變種,一個(gè)純卷積網(wǎng)絡(luò)的結(jié)構(gòu),它達(dá)到了在 AVA speech 數(shù)據(jù)集上的一個(gè) SOTA 的結(jié)果。并且使用了更少的參數(shù)量,取得了更好的性能表現(xiàn)。
2. 說(shuō)話人日志

第二個(gè)要介紹的 speech AI 任務(wù)是Speaker Diarization,即說(shuō)話人日志。它主要想解決的問(wèn)題是 ” who spoke when?” (什么人在什么時(shí)候說(shuō)話了?)。即給定一段音頻,需要給出屬于不同說(shuō)話人的音頻段,以及相應(yīng)的時(shí)間戳。這個(gè)任務(wù)在很多場(chǎng)景中都有應(yīng)用,例如在會(huì)議轉(zhuǎn)寫(xiě)場(chǎng)景里面,SD 模塊可給出不同參會(huì)者所說(shuō)出的音頻段。
上圖右側(cè)給出了 SD 和 ASR 結(jié)合的示例。最上側(cè)是一個(gè)語(yǔ)音識(shí)別模塊所做的事情,它識(shí)別出了音頻中對(duì)應(yīng)的文本。最下側(cè)是 SD 模塊,它需要給出 speaker1 說(shuō)了 “hey” 和 “quite busy” 兩段音頻,speaker2 說(shuō)了 “how are you”,并且給出了對(duì)應(yīng)話的在音頻段中的開(kāi)始和結(jié)束時(shí)間點(diǎn)。SD 模塊可以在原始的 ASR 識(shí)別出的文本中加入說(shuō)話人的信息,能夠捕捉到不同說(shuō)話人的特征,并且區(qū)分錄音中哪一段屬于哪個(gè)說(shuō)話人。它通過(guò)提取說(shuō)話人的語(yǔ)音特征,統(tǒng)計(jì)說(shuō)話人的數(shù)量,將音頻的片段分配給對(duì)應(yīng)的說(shuō)話人,得到一個(gè)索引。
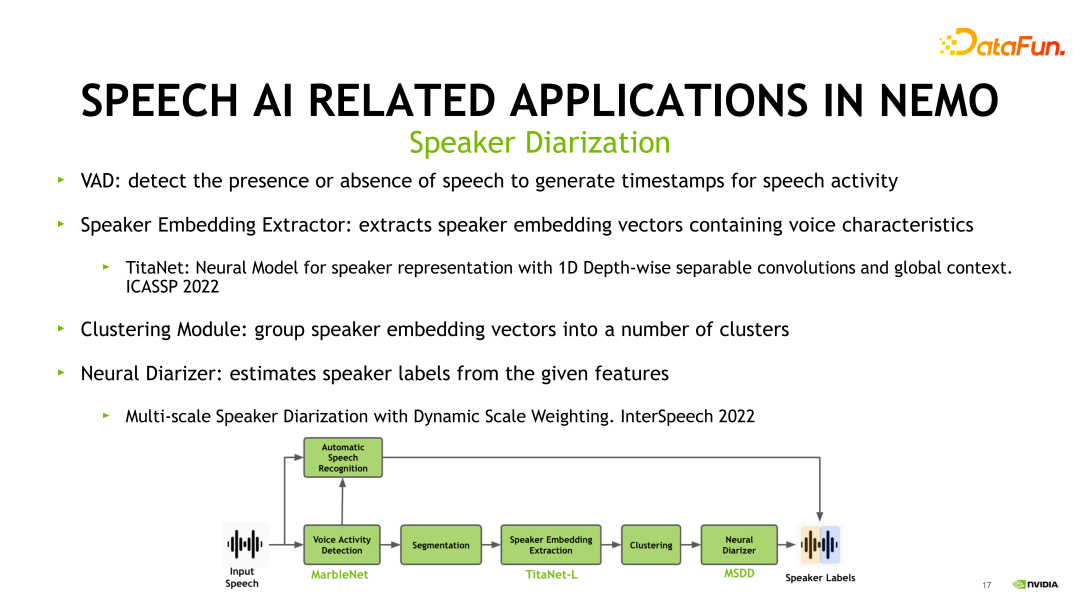
接下來(lái)展示 NeMo 中 Speaker Diarization 是如何實(shí)現(xiàn)的。上圖展示了它的 pipeline。首先是一個(gè)前置的 VAD 模塊,會(huì)從一個(gè)長(zhǎng)音頻中檢測(cè)出各個(gè)人聲段的開(kāi)始和結(jié)束。第二步進(jìn)行說(shuō)話人的 Embedding 提取。NeMo 當(dāng)中采用的模型就是 TitaNet,也是在最新發(fā)表在 ICASSP 2022 的論文里提出的模型,根據(jù)聲學(xué)特征來(lái)提取說(shuō)話人的信息。接下來(lái)是聚類模塊,它對(duì)提取完畢的說(shuō)話人的 Embedding 進(jìn)行聚類,分成不同的類別。
最后一步,我們需要將前面的信息進(jìn)行匯總,來(lái)得到不同的說(shuō)話人時(shí)間戳信息。NeMo 中采用的是 Multi-scale Speaker Diarization 的方式,這也是在我們最新發(fā)表在 InterSpeech 2022 的論文內(nèi)容,感興趣的同學(xué)可以看一下。
3. NeMo 提供的 SD 開(kāi)源資源
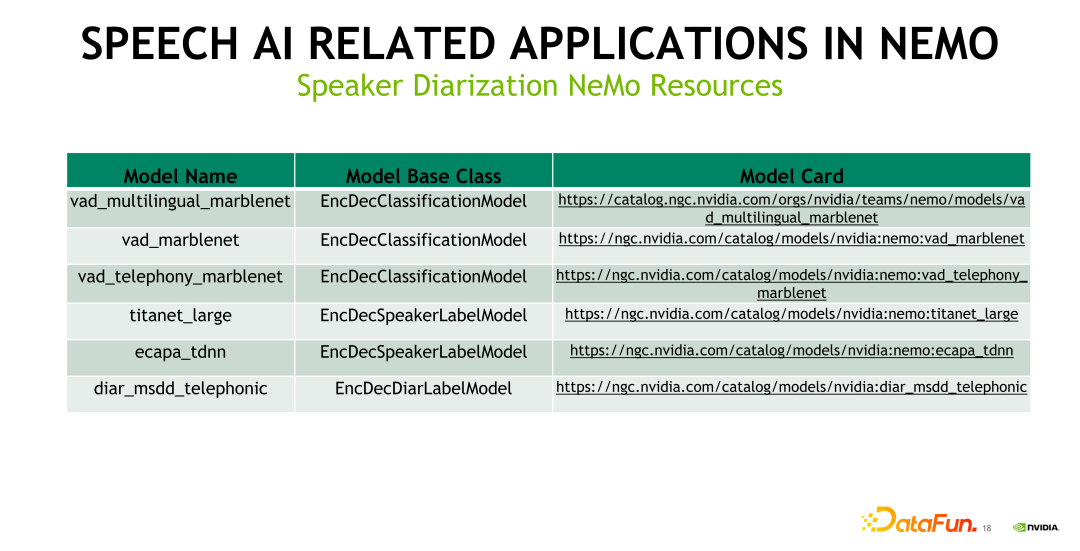
上圖中給出了 Speaker Diarization 方向目前由 NeMo 開(kāi)源出來(lái)的 pretrained 模型,包括基于不同數(shù)據(jù)訓(xùn)練出來(lái)的 VAD 模型,以及提取說(shuō)話人 Embedding 特征 的 Titanet 和 Ecapa_tdnn。前文提到的 Multi-scale Speaker Diarization 模型,也進(jìn)行了開(kāi)源,大家可以到對(duì)應(yīng)的 NGC 鏈接來(lái)下載相應(yīng)的模型進(jìn)行測(cè)試和 finetune。
05
?問(wèn)答環(huán)節(jié)
Q1:Kaldi 單機(jī)多卡訓(xùn)練問(wèn)題,如何避免任務(wù)互相搶占?
A1:把 GPU 的模式設(shè)成 Exclusive status,他就不會(huì)發(fā)生任務(wù)互相搶占。
Q2:對(duì)中文 TTS 的支持情況如何?
A2:應(yīng)該是年底就會(huì)完成支持。我們已經(jīng)在去推進(jìn)這個(gè)事情了。
Q3:有什么通用的數(shù)據(jù)集,如果強(qiáng)行的把詞表放在 GPU 顯存,會(huì)不會(huì)給不夠?
A3:我們現(xiàn)在 NeMo 里面中文用的是漢字,大概是 5000 個(gè)常用字(最核心的應(yīng)該是 3000 個(gè)左右),其實(shí) GPU 是可以放下的。
Q4:MarbleNet 的資源消耗和并發(fā)情況如何,以及模型的大小?
A4:它的模型非常小,可能幾百 k。其實(shí)在 Riva 里面已經(jīng)支持了 MarbleNet,集成到整個(gè) pipeline 當(dāng)中。
Q5:NeMo 的 ASR、VAD、SD 如何同時(shí)使用,有相關(guān)的腳本嗎?
A5:有的,在 NeMo 的 tutorial 里面有這樣的一個(gè)示例,怎么把 VAD 加 SD 串聯(lián)起來(lái)。
Q6:什么是預(yù)訓(xùn)練模型?用預(yù)訓(xùn)練模型后怎么操作可以快速地滿足業(yè)務(wù)應(yīng)用語(yǔ)音識(shí)別的需求?
A6:比如我們?cè)?Aishell-2 上面訓(xùn)練了一個(gè) Conformer,然后把 Conformer 模型開(kāi)源出來(lái),大家就可以再根據(jù)自己數(shù)據(jù)的情況或者業(yè)務(wù)的情況,把它作為一個(gè)初始的模型來(lái)做 finetune,這樣會(huì)加速整個(gè)模型的迭代和收斂的速度。方便大家做后續(xù)的任務(wù)。
Q7:在 NeMo 的 pipeline 中,后處理的部分,CTC 測(cè)試部分,是用的 GPU 還是 CPU?
A7:我們現(xiàn)在 language model 的 fusion 是放在 CPU 上的,但我們其實(shí)也有一些 GPU 的解決方案。
Q8:具備對(duì)齊功能嗎?效果如何?
A8:沒(méi)有的,因?yàn)槲覀冎С值氖?CTC 和 RNNT,沒(méi)有 hybrid 系統(tǒng)里面的 alignment。
Q9:去噪模型有相應(yīng)的成果嗎?比如預(yù)訓(xùn)練模型。
A9:我們默認(rèn) Spec Augmentation 都是加的,但是其他的一些數(shù)據(jù)增強(qiáng)的方式,比如混響,加噪和變速默認(rèn)都是沒(méi)有開(kāi)的。我們的 pretrained 模型一般都是加了 Spec Augmentation 的。
Q10:看大 NeMo 還支持 NLP 相關(guān)的任務(wù),請(qǐng)問(wèn)如果是做關(guān)系抽取應(yīng)該怎么配置?
A10:關(guān)系抽取,NLP 上面的一些任務(wù),大家可以直接去 NeMo 的 Github官網(wǎng)上面看。它的 README 里面有寫(xiě)目前支持的模型以及方法。
Q11:ASR 同一模型可以在 inference 時(shí)設(shè)置 chunk size 同時(shí)滿足流式和離線嗎?
A11:在 inference 的時(shí)候,chunk size 需要設(shè)置成固定的,是不支持動(dòng)態(tài)的加 chunk size 的。
Q12:NeMo 對(duì)變長(zhǎng)的輸入會(huì)做什么特殊處理嗎?A12:沒(méi)有什么特殊處理。我們一般在訓(xùn)練時(shí)會(huì)對(duì)數(shù)據(jù)做一次排序,這樣每個(gè) batch 的長(zhǎng)度是基本一致的,padding 就不會(huì)打得長(zhǎng)度不一致。基本上每個(gè) batch 大小是比較固定的,能夠提高吞吐和訓(xùn)練速度。
今天的分享就到這里,謝謝大家。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3848瀏覽量
91985
原文標(biāo)題:NVIDIA NeMo 如何支持對(duì)話式 AI 任務(wù)的訓(xùn)練與推理?
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NVIDIA發(fā)布全新NIM AI Guardrail微服務(wù)
NVIDIA NeMo Guardrails引入三項(xiàng)全新NIM微服務(wù)
NVIDIA 發(fā)布保障代理式 AI 應(yīng)用安全的 NIM 微服務(wù)
NVIDIA技術(shù)助力Pantheon Lab數(shù)字人實(shí)時(shí)交互解決方案
NVIDIA與合作伙伴推出代理式AI Blueprint
NVIDIA助力企業(yè)創(chuàng)建定制AI應(yīng)用
日本企業(yè)借助NVIDIA產(chǎn)品加速AI創(chuàng)新
NVIDIA助力Figure發(fā)布新一代對(duì)話式人形機(jī)器人
NVIDIA助力麗蟾科技打造AI訓(xùn)練與推理加速解決方案

NVIDIA Nemotron-4 340B模型幫助開(kāi)發(fā)者生成合成訓(xùn)練數(shù)據(jù)

Mistral AI與NVIDIA推出全新語(yǔ)言模型Mistral NeMo 12B
英偉達(dá)推出全新NVIDIA AI Foundry服務(wù)和NVIDIA NIM推理微服務(wù)
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級(jí)芯片
AI推理,和訓(xùn)練有什么不同?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論