 大數據的特征及技術關鍵
大數據的特征及技術關鍵
大數據的特征
大數據的定義多而雜,不同企業、行業等都從自身角度來定義大數據,意思都差不多,就一句話,大數據由巨型數據集組成,這些數據集規模超出了常用軟件在可接受時間下的收集、管理、處理和使用能力。
雖然大數據的定義沒有統一,但是國際知名咨詢公司IDC定義的大數據四個特征卻受到業界的廣泛接受,也就是4V特征——數據量大(Volume)、數據種類多(Variety)、數據價值密度低(Value) 以及數據產生和處理速度快(Velocity)。
01
數據量大(Volume)
傳感器、物聯網、工業互聯網、車聯網、手機、平板電腦等等,無一不是數據來源或者承載的方式。當今的數字時代,人們日常生活(微信、QQ、上網搜索與購物等)都在產生著數量龐大的數據。
大數據不再以GB或TB為單位來衡量,而是以PB(1000個T)、EB(100萬個T)或ZB(10億個T)為計量單位,從TB躍升到PB、EB乃至ZB級別。顧名思義,這就是大數據的首要特征。
02
數據種類多(Variety)
大數據不僅體現在量的急劇增長,數據類型亦是多樣,可分為結構化、半結構化和非結構化數據。結構化數據存儲在多年來一直主導著IT應用的關系型數據庫中;半結構化數據包括電子郵件、文字處理文件以及大量的網絡新聞等,以內容為基礎,這也是谷歌和百度存在的理由;而非結構化數據隨著社交網絡、移動計算和傳感器等新技術應用不斷產生,廣泛存在于社交網絡、物聯網、電子商務之中。
有報告稱,全世界結構化數據和非結構化數據的增長率分別是32%、63%,網絡日志、音視頻、圖片、地理位置信息等非結構化數據量占比達到80%左右,并在逐步提升。然而,產生人類智慧的大數據往往就是這些非結構化數據。
03
數據價值密度低(Value)
大數據的重點不在于其數據量的增長,而是在信息爆炸時代對數據價值的再挖掘,如何挖掘出大數據的有效信息,才是至關重要。
價值密度的高低與數據總量的大小成反比。雖然價值密度低是日益凸顯的一個大數據特性,但是對大數據進行研究、分析挖掘仍然是具有深刻意義的,大數據的價值依然是不可估量的。畢竟,價值是推動一切技術(包括大數據技術)研究和發展的內生決定性動力。
04
數據產生和處理速度快(Velocity)
美國互聯網數據中心指出,企業數據正在以55%的速度逐年增長,互聯網數據每年將增長50%,每兩年便將翻一番。IBM研究表明,整個人類文明所獲得的全部數據中,90%是過去兩年內產生的。
要求數據處理速度快也是大數據區別于傳統數據挖掘技術的本質特征。有學者提出了與之相關的“一秒定律”,意思就是在這一秒有用的數據,下一秒可能就失效。數據價值除了與數據規模相關,還與數據處理速度成正比關系,也就是,數據處理速度越快、越及時,其發揮的效能就越大、價值越大。
大數據的關鍵技術
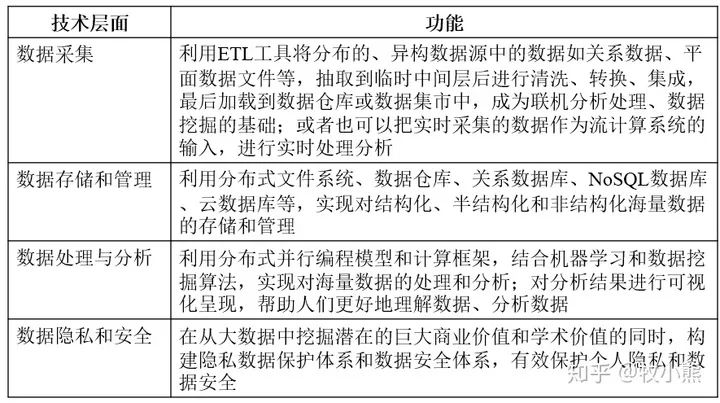
大數據技術是IT領域新一代的技術與架構,是從各種類型的數據中快速獲得有價值信息的技術。大數據本質也是數據,其關鍵技術依然不外乎:大數據采集和預處理;大數據存儲與管理;大數據分析和挖掘;大數據展現和應用(大數據檢索、大數據可視化、大數據安全等)。
01
大數據采集和預處理技術
大數據技術的意義確實不在于掌握規模龐大的數據信息,而在于對這些數據進行智能處理,從中分析和挖掘出有價值的信息,但前提是得擁有大量的數據。
采集是大數據價值挖掘最重要的一環,一般通過傳感器、通信網絡、智能識別系統及軟硬件資源接入系統,實現對各種類型海量數據的智能化識別、定位、跟蹤、接入、傳輸、信號轉換等。為了快速分析處理,大數據預處理技術要對多種類型的數據進行抽取、清洗、轉換等操作,將這些復雜的數據轉化為有效的、單一的或者便于處理的數據類型。
就算是大數據服務企業也很難就“哪些數據未來將成為資產”這個問題給出確切的答案。但可以肯定的是,誰掌握了足夠的數據,誰就有可能掌握未來,現在的數據采集就是將來的流動資產積累。
02
大數據存儲與管理技術
數據有多種分類方法,有結構化、半結構化、非結構化;也有元數據、主數據、業務數據;還可以分為GIS、視頻、文本、語音、業務交易類各種數據。傳統的關系型數據庫已經無法滿足數據多樣性的存儲要求。除了關系型數據庫,還有兩種存儲類型,一種是以HDFS為代表的可以直接應用于非結構化文件存儲的分布式存儲系統,另一種是NoSQL數據庫,可以存儲半結構化和非結構化數據。大數據存儲與管理就是要用這些存儲技術把采集到的數據存儲起來,并進行管理和調用。
在一般的大數據存儲層,關系型數據庫、NoSQL數據庫和分布式存儲系統三種存儲方式都可能存在,業務應用根據實際的情況選擇不同的存儲模式。為了提高業務的存儲和讀取便捷性,存儲層可能封裝成為一套統一訪問的數據服務(Data as a Service,DaaS)。DaaS可以實現業務應用和存儲基礎設施的徹底解耦,用戶并不需要關心底層存儲細節,只關心數據的存取。
03
大數據分析和挖掘技術
大數據分析和挖掘就是從大量的、不完全的、有噪聲的、模糊的、隨機的實際應用數據中提取隱含在其中的、有用的信息和知識的過程。大數據分析和挖掘涉及的技術方法很多:根據挖掘任務可分為分類或預測模型發現、關聯規則發現、依賴關系或依賴模型發現、異常和趨勢發現等;根據挖掘方法可分為機器學習、統計方法、神經網絡等。其中,機器學習又可細分為歸納學習、遺傳算法等;統計方法可細分為回歸分析、聚類分析、探索性分析等;神經網絡可細分為前饋網絡、反饋網絡等。
面對不同的分析或預測需求,所需要的分析挖掘算法和模型是完全不同的。上面提到的各種技術方法只是一個處理問題的思路,面對真正的應用場景時,都得按需求來調整這些算法和模型。
04
大數據展現和應用技術
大數據的使用對象遠遠不只是程序員和專業工程師,如何將大數據技術的分析成果展現給普通用戶或者公司決策者,這就要看數據展現的可視化技術了,它是目前解釋大數據最有效的手段之一。在數據可視化中,數據結果以簡單形象的可視化、圖形化、智能化的形式呈現給用戶供其分析使用。常見的大數據可視化技術有標簽云、歷史流、空間信息流等。
我國的大數據應用廣泛存在于商業智能、政府決策和公共服務等重點領域,疫情防控、反電信詐騙、智能交通、環境監測等日常生活場景都有大數據的功勞。
大數據時代對我們駕馭數據的能力提出了新挑戰,也為獲得更全面、睿智的洞察力提供了空間和潛力。大數據領域已經涌現出了大量新技術,它們成為大數據采集、存儲、處理和展現的有力武器。隨著大數據等新興技術的發展和應用,我國“十四五”規劃提出的碳達峰碳中和、數字化轉型、數字經濟等一系列戰略目標將獲得更大的技術支撐。
-
IDC
+關注
關注
4文章
393瀏覽量
37292 -
Value
+關注
關注
0文章
11瀏覽量
8670 -
大數據
+關注
關注
64文章
8908瀏覽量
137791
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論