 大數據的4v特征有哪些 大數據技術包括哪些技術
大數據的4v特征有哪些 大數據技術包括哪些技術
大數據的4v特征有哪些
大數據的4V特征是指數據的特點,主要包括以下四個方面:
1. Volume(數據量):所謂大數據,就是指數據量達到了一定的規模大小,通常需要使用分布式系統和算法進行處理和分析。數據的增長速度非常快,而且數據的來源和種類也更加多樣化。
2. Velocity(處理速度):大數據通常需要快速處理和分析,這就需要使用高效的分布式系統和并行算法來快速處理數據。如Hadoop、Spark等分布式處理框架可以有效地解決大數據的處理速度問題。
3. Variety(數據種類):大數據的來源非常廣泛,數據的種類也非常豐富,包括結構化數據、非結構化數據、半結構化數據、時間序列數據等等。這些數據需要使用不同的技術進行處理和分析。
4. Veracity(數據準確性):由于數據來源和種類的多樣性,大數據的準確性也成為一項關鍵的挑戰。針對數據質量的問題,需要采用有效的數據清洗和校驗方案,確保在大數據分析和決策中使用的數據具有高度的準確性和可靠性。
綜上所述,大數據的4V特征是指數據量大、處理速度快、數據種類豐富、數據準確性高的特點。在大數據的處理和分析過程中,需要采用有效的技術方案和方法,以便更好地挖掘數據的價值。
大數據技術包括哪些技術
1、大數據收集
數據的收集就是從數據源中把數據采集和存儲到數據存儲上。而數據源主要包括Flume NG、NDC,Netease Data Canal、Logstash2、Sqoop、Strom集群結構、Zookeeper等。
2、大數據的存儲
采集到大量復雜信息后,就需要有一個存儲的數據庫。大數據存儲,指用存儲器,以數據庫的形式,存儲采集到的數據的過程,主要包括有Hadoop、HBase、Phoenix、Yarn、Mesos、Redis、Atlas、Kudu等,不同的存儲數據庫可適用于不同類型的數據。
3、大數據的清洗
隨著業務數據量的增多,需要進行訓練和清洗的數據會變得越來越復雜,這個時候就需要任務調度系統,比如oozie或者azkaban,對關鍵任務進行調度和監控。
4、大數據的查詢分析
如何將這些龐大復雜的數據整合成我們所需要的信息呢?這就涉及到了數據的分析處理,主要會用到這些程序,如Hive、Impala、Spark、Nutch、Solr、Elasticsearch等。
5、大數據的可視化分析
何為可視化分析,就是指借助圖形的方式,清楚并高效率的傳送信息的分析手段。主要應用于龐大的數據關聯分析,就是借助分析平臺,對那些相對分散看似沒用的信息進行關聯分析,并得出完整的分析圖表并用于指導決策服務的過程。主流的BI平臺有如國外的敏捷BI Tableau、Qlikview、PowrerBI等,國內的SmallBI和新興的網易有數等。
6、大數據挖掘
其實有關數據挖掘的算法非常多,而且不一樣的算法適用于不同的數據類型,那么得出的數據特點也會不一樣。但是通常情況下,創建模型的過程是很類似的,就是一開始要分析用戶提供的數據,接著開始查找,不一樣的類型模式有不一樣的查詢方式,然后分析結果得出模型的最佳參數,并將這些參數都應用在整個數據集,即可提取詳細的統計信息
7、模型預測
大數據采集到后,除了能夠通過分析計算反應過去和當前的信息情況,還可以通過建立科學的數據模型,通過模型得出新的數據,預測將來會發生的事情,從而提前做出應對政策。
8、結果呈現
再好的數據分析結論如果沒有一個好的呈現方式,那么也是在做無用功,利用大數據分析得出的結論可以通過不用的方式呈現。如云計算、標簽云等。借助云計算,可以完成對大數據的統一管理和實時高效的分析,最大限度的挖掘數據的價值,讓大數據的意義發揮到最佳效果。標簽云是一些列相關聯的標簽以及以此相對應的權重,比較典型的標簽云有30-150個左右的標簽,而權重是影響使用的字體大小或其他視覺呈現效果。
-
存儲
+關注
關注
13文章
4355瀏覽量
86175 -
數據采集
+關注
關注
39文章
6252瀏覽量
114045 -
大數據
+關注
關注
64文章
8908瀏覽量
137793
發布評論請先 登錄
相關推薦
緩存對大數據處理的影響分析
大數據的3V、4V、7V,到底是什么意思?

ADS1675最大數據吞吐率是是多少?
raid 在大數據分析中的應用
智慧城市與大數據的關系
基于Kepware的Hadoop大數據應用構建-提升數據價值利用效能
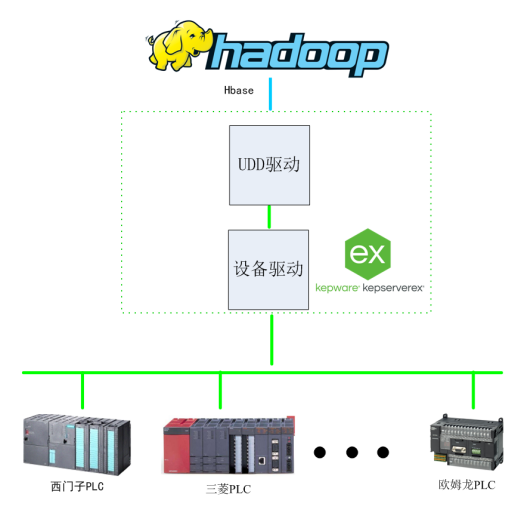
使用CYW20829的BLE進行最大數據發送應用,BLE丟失數據如何解決?
大數據在軍事方面的應用
大數據采集系統分為幾類
大數據在軍事方面的應用有哪些
大數據在軍事訓練領域的應用有哪些
大數據在部隊管理中的運用有哪些
CYBT-343026傳輸大數據時會丟數據的原因?
簡析大數據技術下智能充電樁在網絡系統中的應用
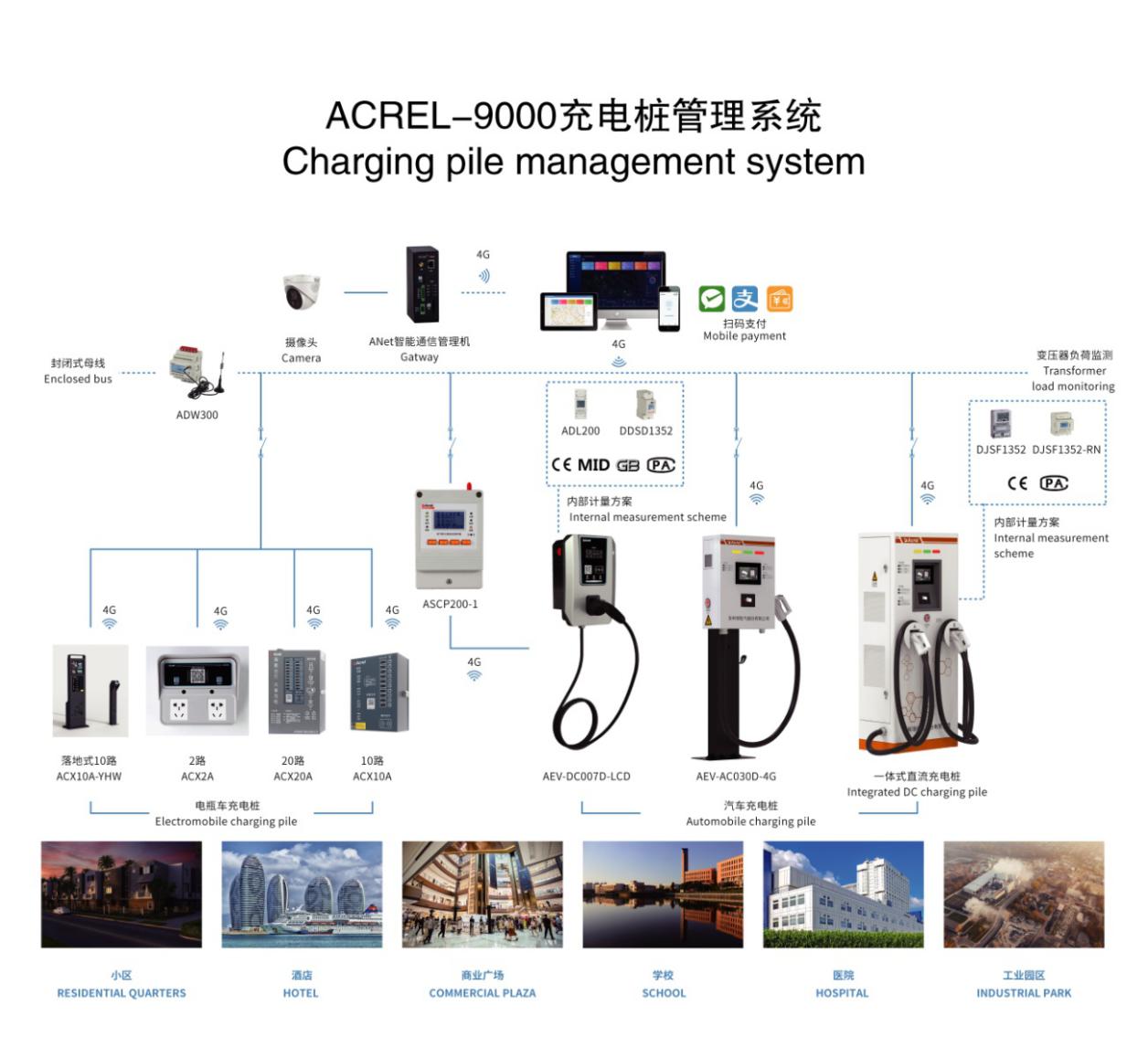





 工商網監
工商網監
評論