") 圖解 72 個機器學習基礎(chǔ)知識點
圖解 72 個機器學習基礎(chǔ)知識點
來源:尤而小屋、數(shù)據(jù)派THU
圖解機器學習算法系列以圖解的生動方式,闡述機器學習核心知識 & 重要模型,并通過代碼講通應(yīng)用細節(jié)。
1. 機器學習概述
1)什么是機器學習
人工智能(Artificial intelligence)是研究、開發(fā)用于模擬、延伸和擴展人的智能的理論、方法、技術(shù)及應(yīng)用系統(tǒng)的一門新的技術(shù)科學。它是一個籠統(tǒng)而寬泛的概念,人工智能的最終目標是使計算機能夠模擬人的思維方式和行為。 大概在上世紀50年代,人工智能開始興起,但是受限于數(shù)據(jù)和硬件設(shè)備等限制,當時發(fā)展緩慢。 機器學習(Machine learning)是人工智能的子集,是實現(xiàn)人工智能的一種途徑,但并不是唯一的途徑。它是一門專門研究計算機怎樣模擬或?qū)崿F(xiàn)人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結(jié)構(gòu)使之不斷改善自身的性能的學科。大概在上世紀80年代開始蓬勃發(fā)展,誕生了一大批數(shù)學統(tǒng)計相關(guān)的機器學習模型。 深度學習(Deep learning)是機器學習的子集,靈感來自人腦,由人工神經(jīng)網(wǎng)絡(luò)(ANN)組成,它模仿人腦中存在的相似結(jié)構(gòu)。在深度學習中,學習是通過相互關(guān)聯(lián)的「神經(jīng)元」的一個深層的、多層的「網(wǎng)絡(luò)」來進行的。「深度」一詞通常指的是神經(jīng)網(wǎng)絡(luò)中隱藏層的數(shù)量。大概在2012年以后爆炸式增長,廣泛應(yīng)用在很多的場景中。 讓我們看看國外知名學者對機器學習的定義: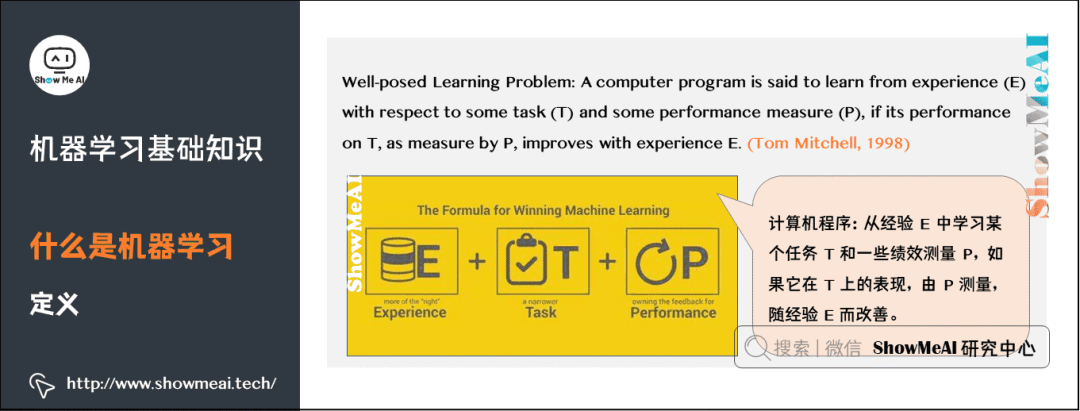 ?機器學習研究的是計算機怎樣模擬人類的學習行為,以獲取新的知識或技能,并重新組織已有的知識結(jié)構(gòu),使之不斷改善自身。
從實踐的意義上來說,機器學習是在大數(shù)據(jù)的支撐下,通過各種算法讓機器對數(shù)據(jù)進行深層次的統(tǒng)計分析以進行「自學」,使得人工智能系統(tǒng)獲得了歸納推理和決策能力。
?機器學習研究的是計算機怎樣模擬人類的學習行為,以獲取新的知識或技能,并重新組織已有的知識結(jié)構(gòu),使之不斷改善自身。
從實踐的意義上來說,機器學習是在大數(shù)據(jù)的支撐下,通過各種算法讓機器對數(shù)據(jù)進行深層次的統(tǒng)計分析以進行「自學」,使得人工智能系統(tǒng)獲得了歸納推理和決策能力。
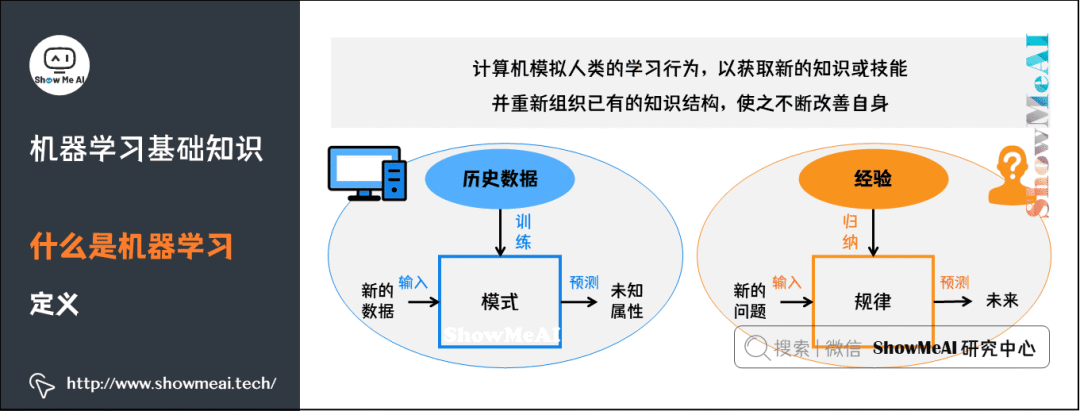 ?通過經(jīng)典的垃圾郵件過濾應(yīng)用,我們再來理解下機器學習的原理,以及定義中的T、E、P分別指代什么:
?通過經(jīng)典的垃圾郵件過濾應(yīng)用,我們再來理解下機器學習的原理,以及定義中的T、E、P分別指代什么:
2)機器學習三要素
機器學習三要素包括數(shù)據(jù)、模型、算法。這三要素之間的關(guān)系,可以用下面這幅圖來表示: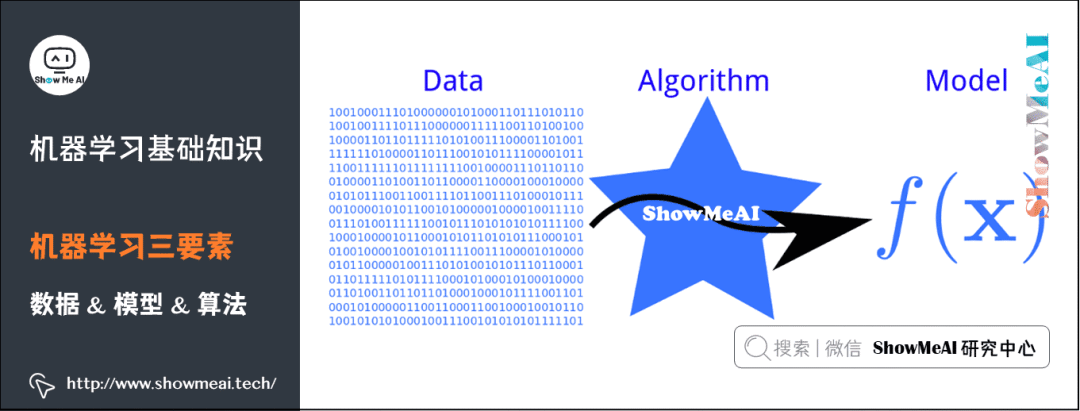 ?
?(1)數(shù)據(jù)
數(shù)據(jù)驅(qū)動:數(shù)據(jù)驅(qū)動指的是我們基于客觀的量化數(shù)據(jù),通過主動數(shù)據(jù)的采集分析以支持決策。與之相對的是經(jīng)驗驅(qū)動,比如我們常說的「拍腦袋」。

(2)模型&算法
模型:在AI數(shù)據(jù)驅(qū)動的范疇內(nèi),模型指的是基于數(shù)據(jù)X做決策Y的假設(shè)函數(shù),可以有不同的形態(tài),計算型和規(guī)則型等。
算法:指學習模型的具體計算方法。統(tǒng)計學習基于訓練數(shù)據(jù)集,根據(jù)學習策略,從假設(shè)空間中選擇最優(yōu)模型,最后需要考慮用什么樣的計算方法求解最優(yōu)模型。通常是一個最優(yōu)化的問題。
3)機器學習發(fā)展歷程
人工智能一詞最早出現(xiàn)于1956年,用于探索一些問題的有效解決方案。1960年,美國國防部借助「神經(jīng)網(wǎng)絡(luò)」這一概念,訓練計算機模仿人類的推理過程。 2010年之前,谷歌、微軟等科技巨頭改進了機器學習算法,將查詢的準確度提升到了新的高度。而后,隨著數(shù)據(jù)量的增加、先進的算法、計算和存儲容量的提高,機器學習得到了更進一步的發(fā)展。
4)機器學習核心技術(shù)
分類:應(yīng)用以分類數(shù)據(jù)進行模型訓練,根據(jù)模型對新樣本進行精準分類與預(yù)測。
聚類:從海量數(shù)據(jù)中識別數(shù)據(jù)的相似性與差異性,并按照最大共同點聚合為多個類別。
異常檢測:對數(shù)據(jù)點的分布規(guī)律進行分析,識別與正常數(shù)據(jù)及差異較大的離群點。
回歸:根據(jù)對已知屬性值數(shù)據(jù)的訓練,為模型尋找最佳擬合參數(shù),基于模型預(yù)測新樣本的輸出值。
5)機器學習基本流程
機器學習工作流(WorkFlow)包含數(shù)據(jù)預(yù)處理(Processing)、模型學習(Learning)、模型評估(Evaluation)、新樣本預(yù)測(Prediction)幾個步驟。
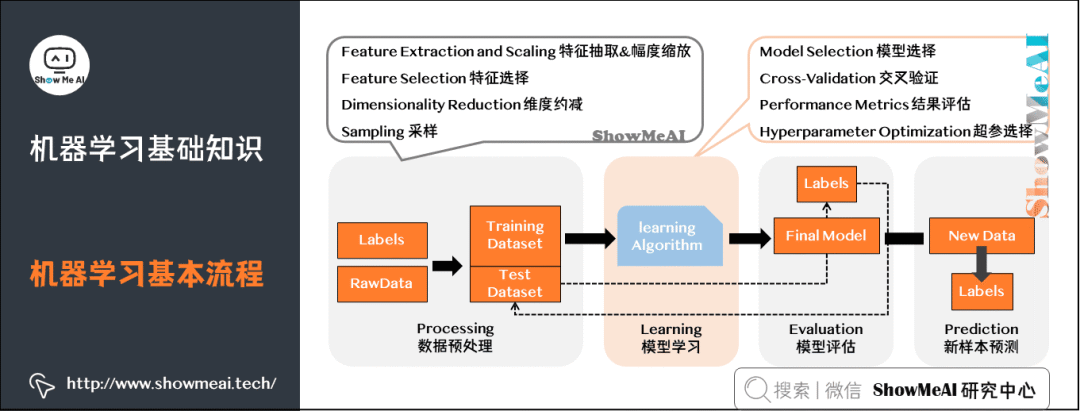
6)機器學習應(yīng)用場景
作為一套數(shù)據(jù)驅(qū)動的方法,機器學習已廣泛應(yīng)用于數(shù)據(jù)挖掘、計算機視覺、自然語言處理、生物特征識別、搜索引擎、醫(yī)學診斷、檢測信用卡欺詐、證券市場分析、DNA序列測序、語音和手寫識別和機器人等領(lǐng)域。
智能醫(yī)療:智能假肢、外骨骼、醫(yī)療保健機器人、手術(shù)機器人、智能健康管理等。人臉識別:門禁系統(tǒng)、考勤系統(tǒng)、人臉識別防盜門、電子護照及身份證,還可以利用人臉識別系統(tǒng)和網(wǎng)絡(luò),在全國范圍內(nèi)搜捕逃犯。機器人的控制領(lǐng)域:工業(yè)機器人、機械臂、多足機器人、掃地機器人、無人機等。
2. 機器學習基本名詞
、
監(jiān)督學習(Supervised Learning):訓練集有標記信息,學習方式有分類和回歸。
無監(jiān)督學習(Unsupervised Learning):訓練集沒有標記信息,學習方式有聚類和降維。
強化學習(Reinforcement Learning):有延遲和稀疏的反饋標簽的學習方式。
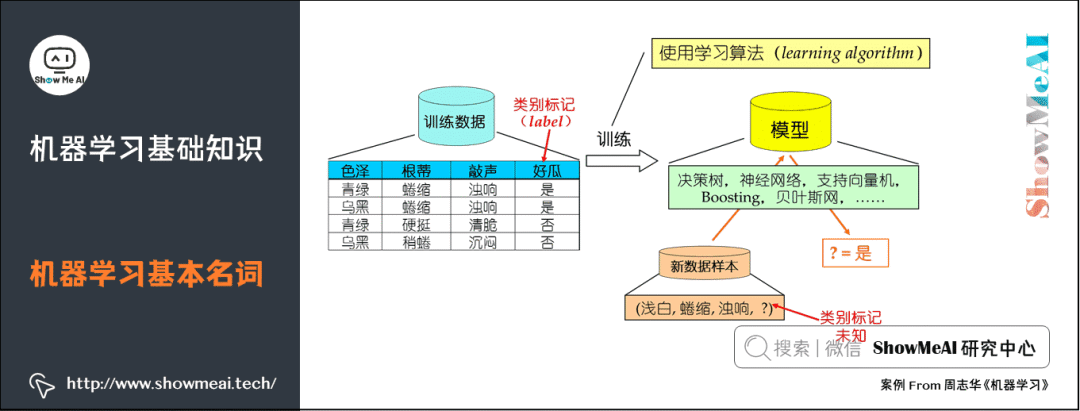
示例/樣本:上面一條數(shù)據(jù)集中的一條數(shù)據(jù)。
屬性/特征:「色澤」「根蒂」等。
屬性空間/樣本空間/輸入空間X:由全部屬性張成的空間。
特征向量:空間中每個點對應(yīng)的一個坐標向量。
標記:關(guān)于示例結(jié)果的信息,如((色澤=青綠,根蒂=蜷縮,敲聲=濁響),好瓜),其中「好瓜」稱為標記。
分類:若要預(yù)測的是離散值,如「好瓜」,「壞瓜」,此類學習任務(wù)稱為分類。
假設(shè):學得模型對應(yīng)了關(guān)于數(shù)據(jù)的某種潛在規(guī)律。
真相:潛在規(guī)律自身。
學習過程:是為了找出或逼近真相。
泛化能力:學得模型適用于新樣本的能力。一般來說,訓練樣本越大,越有可能通過學習來獲得具有強泛化能力的模型。3. 機器學習算法分類
1)機器學習算法依托的問題場景
機器學習在近30多年已發(fā)展為一門多領(lǐng)域交叉學科,涉及概率論、統(tǒng)計學、逼近論、凸分析、計算復(fù)雜性理論等多門學科。機器學習理論主要是設(shè)計和分析一些讓計算機可以自動「學習」的算法。 機器學習算法從數(shù)據(jù)中自動分析獲得規(guī)律,并利用規(guī)律對未知數(shù)據(jù)進行預(yù)測。
機器學習理論關(guān)注可以實現(xiàn)的、行之有效的學習算法。很多推論問題屬于無程序可循難度,所以部分的機器學習研究是開發(fā)容易處理的近似算法。

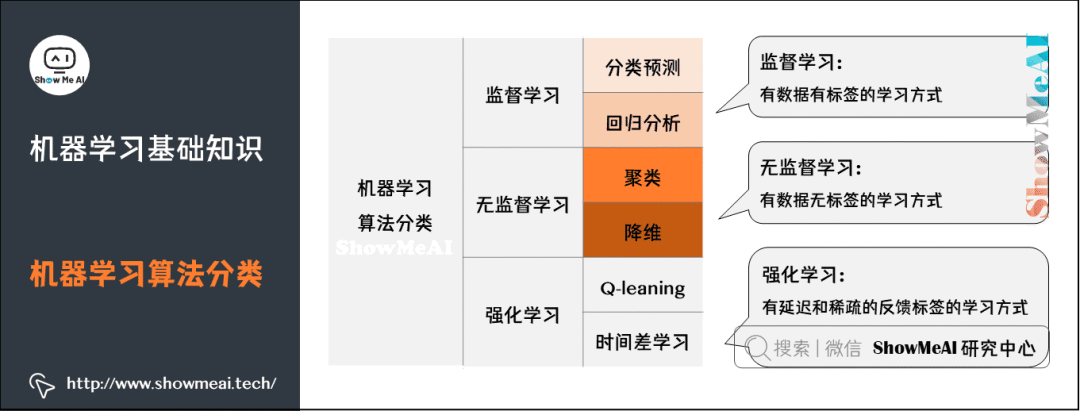
更多監(jiān)督學習的算法模型總結(jié),可以查看ShowMeAI的文章 AI知識技能速查 | 機器學習-監(jiān)督學習(公眾號不能跳轉(zhuǎn),本文鏈接見文末)。
無監(jiān)督學習:與監(jiān)督學習相比,訓練集沒有人為標注的結(jié)果。常見的無監(jiān)督學習算法有生成對抗網(wǎng)絡(luò)(GAN)、聚類。
更多無監(jiān)督學習的算法模型總結(jié)可以查看ShowMeAI的文章 AI知識技能速查 | 機器學習-無監(jiān)督學習。
強化學習:通過觀察來學習做成如何的動作。每個動作都會對環(huán)境有所影響,學習對象根據(jù)觀察到的周圍環(huán)境的反饋來做出判斷。
2)分類問題
分類問題是機器學習非常重要的一個組成部分。它的目標是根據(jù)已知樣本的某些特征,判斷一個新的樣本屬于哪種已知的樣本類。分類問題可以細分如下:
二分類問題:表示分類任務(wù)中有兩個類別新的樣本屬于哪種已知的樣本類。多類分類(Multiclass classification)問題:表示分類任務(wù)中有多類別。多標簽分類(Multilabel classification)問題:給每個樣本一系列的目標標簽。
了解更多機器學習分類算法:KNN算法、邏輯回歸算法、樸素貝葉斯算法、決策樹模型、隨機森林分類模型、GBDT模型、XGBoost模型、支持向量機模型等。(公眾號不能跳轉(zhuǎn),本文鏈接見文末)
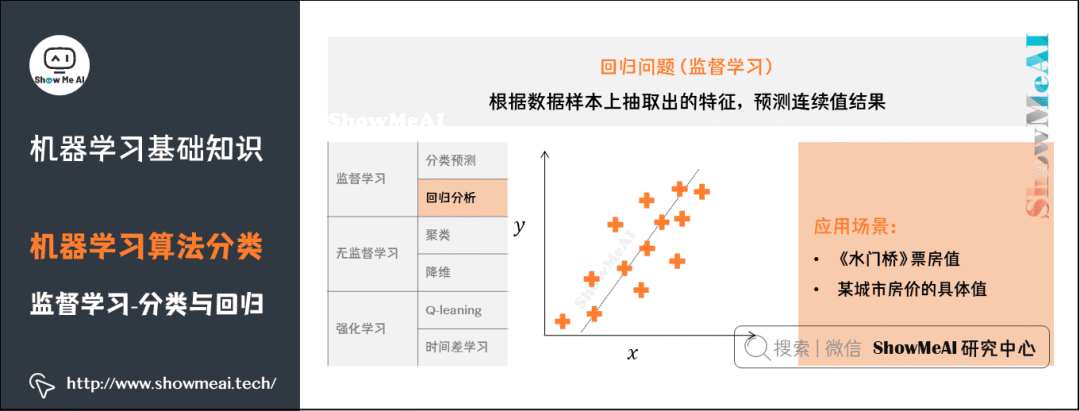
3)回歸問題
了解更多機器學習回歸算法:決策樹模型、隨機森林分類模型、GBDT模型、回歸樹模型、支持向量機模型等。
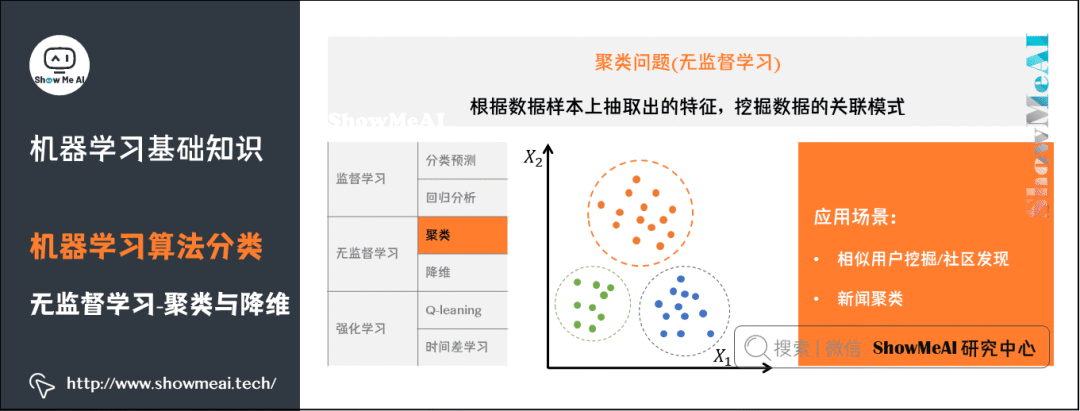
4)聚類問題
了解更多機器學習聚類算法:聚類算法。
5)降維問題
了解更多機器學習降維算法:PCA降維算法。
 ?
?4.機器學習模型評估與選擇
1)機器學習與數(shù)據(jù)擬合
機器學習最典型的監(jiān)督學習為分類與回歸問題。分類問題中,我們學習出來一條「決策邊界」完成數(shù)據(jù)區(qū)分;在回歸問題中,我們學習出擬合樣本分布的曲線。
2)訓練集與數(shù)據(jù)集
我們以房價預(yù)估為例,講述一下涉及的概念。
訓練集(Training Set):幫助訓練模型,簡單的說就是通過訓練集的數(shù)據(jù)讓確定擬合曲線的參數(shù)。
測試集(Test Set):為了測試已經(jīng)訓練好的模型的精確度。 當然,test set這并不能保證模型的正確性,只是說相似的數(shù)據(jù)用此模型會得出相似的結(jié)果。因為在訓練模型的時候,參數(shù)全是根據(jù)現(xiàn)有訓練集里的數(shù)據(jù)進行修正、擬合,有可能會出現(xiàn)過擬合的情況,即這個參數(shù)僅對訓練集里的數(shù)據(jù)擬合比較準確,這個時候再有一個數(shù)據(jù)需要利用模型預(yù)測結(jié)果,準確率可能就會很差。3)經(jīng)驗誤差
在訓練集的數(shù)據(jù)上進行學習。模型在訓練集上的誤差稱為「經(jīng)驗誤差」(Empirical Error)。但是經(jīng)驗誤差并不是越小越好,因為我們希望在新的沒有見過的數(shù)據(jù)上,也能有好的預(yù)估結(jié)果。
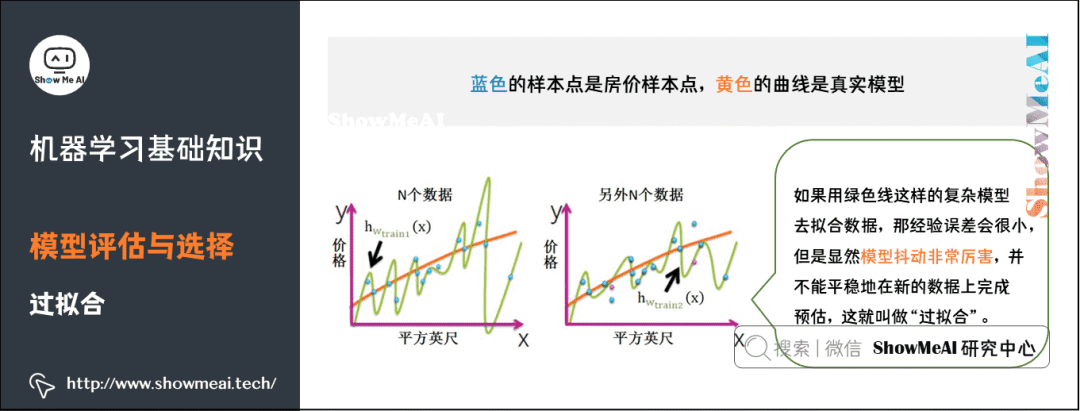
4)過擬合
過擬合,指的是模型在訓練集上表現(xiàn)的很好,但是在交叉驗證集合測試集上表現(xiàn)一般,也就是說模型對未知樣本的預(yù)測表現(xiàn)一般,泛化(Generalization)能力較差。
正則化:指的是在目標函數(shù)后面添加一個正則化項,一般有L1正則化與L2正則化。L1正則是基于L1范數(shù),即在目標函數(shù)后面加上參數(shù)的L1范數(shù)和項,即參數(shù)絕對值和與參數(shù)的積項。
數(shù)據(jù)集擴增:即需要得到更多的符合要求的數(shù)據(jù),即和已有的數(shù)據(jù)是獨立同分布的,或者近似獨立同分布的。一般方法有:從數(shù)據(jù)源頭采集更多數(shù)據(jù)、復(fù)制原有數(shù)據(jù)并加上隨機噪聲、重采樣、根據(jù)當前數(shù)據(jù)集估計數(shù)據(jù)分布參數(shù),使用該分布產(chǎn)生更多數(shù)據(jù)等。
DropOut:通過修改神經(jīng)網(wǎng)絡(luò)本身結(jié)構(gòu)來實現(xiàn)的。5)偏差
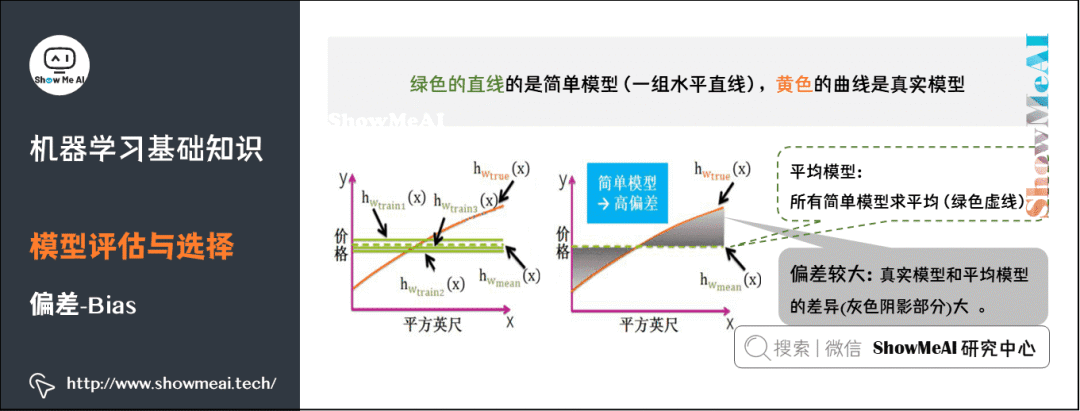
偏差(Bias),它通常指的是模型擬合的偏差程度。給定無數(shù)套訓練集而期望擬合出來的模型就是平均模型。偏差就是真實模型和平均模型的差異。
簡單模型是一組直線,平均之后得到的平均模型是一條直的虛線,與真實模型曲線的差別較大(灰色陰影部分較大)。因此,簡單模型通常高偏差。
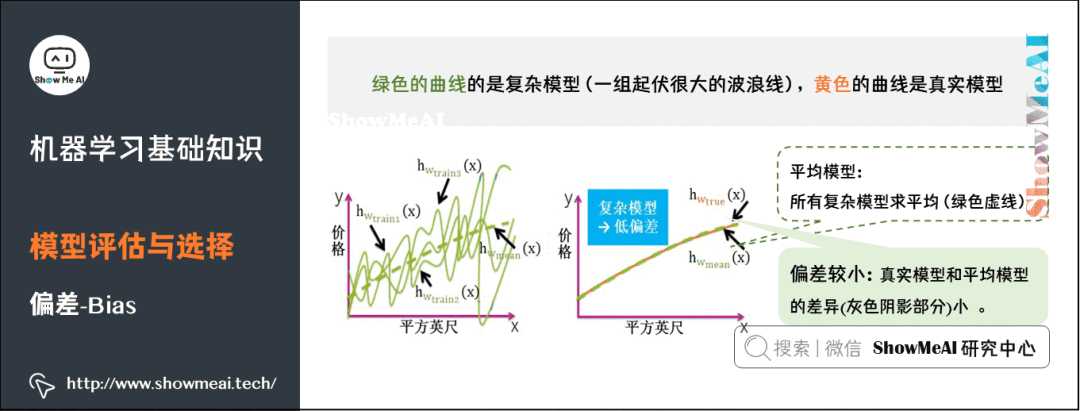
6)方差
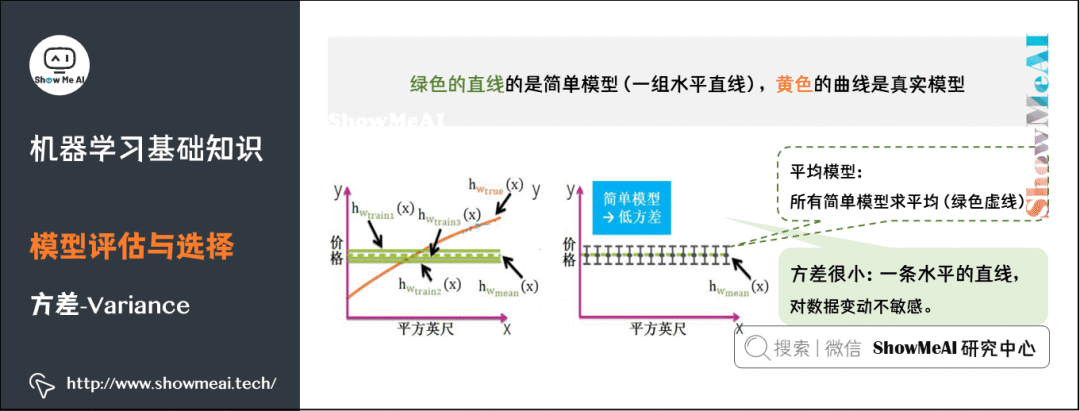
方差(Variance),它通常指的是模型的平穩(wěn)程度(簡單程度)。簡單模型的對應(yīng)的函數(shù)如出一轍,都是水平直線,而且平均模型的函數(shù)也是一條水平直線,因此簡單模型的方差很小,并且對數(shù)據(jù)的變動不敏感。
復(fù)雜模型的對應(yīng)的函數(shù)千奇百怪,毫無任何規(guī)則,但平均模型的函數(shù)也是一條平滑的曲線,因此復(fù)雜模型的方差很大,并且對數(shù)據(jù)的變動很敏感。
7)偏差與方差的平衡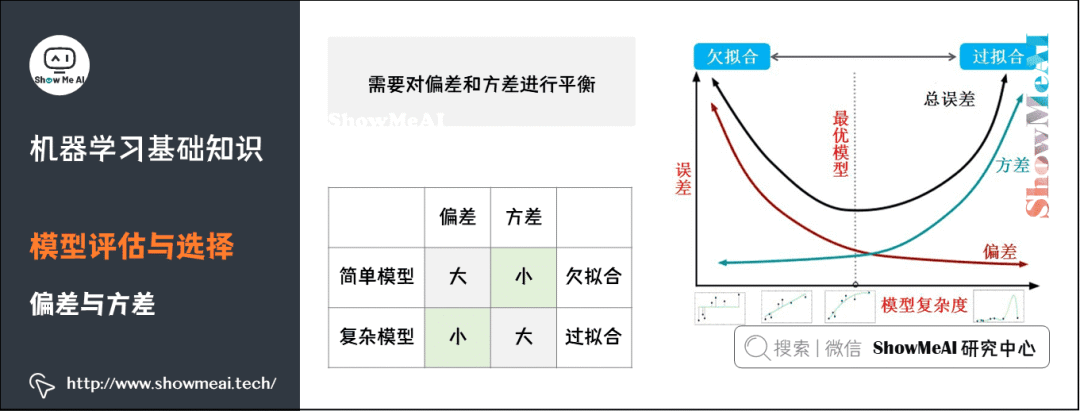
8)性能度量指標
性能度量是衡量模型泛化能力的數(shù)值評價標準,反映了當前問題(任務(wù)需求)。使用不同的性能度量可能會導致不同的評判結(jié)果。更詳細的內(nèi)容可見 模型評估方法與準則(鏈接見文末)。(1)回歸問題
關(guān)于模型「好壞」的判斷,不僅取決于算法和數(shù)據(jù),還取決于當前任務(wù)需求。回歸問題常用的性能度量指標有:平均絕對誤差、均方誤差、均方根誤差、R平方等。
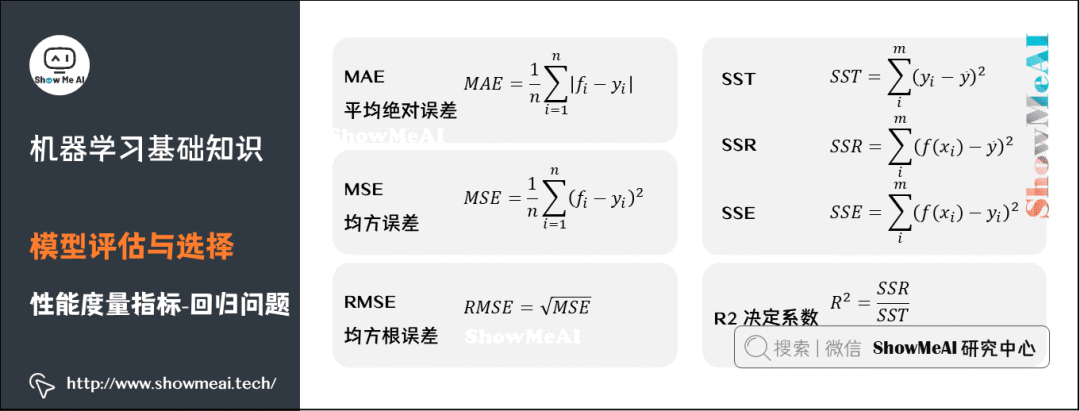
平均絕對誤差(Mean Absolute Error,MAE),又叫平均絕對離差,是所有標簽值與回歸模型預(yù)測值的偏差的絕對值的平均。
平均絕對百分誤差(Mean Absolute Percentage Error,MAPE)是對MAE的一種改進,考慮了絕對誤差相對真實值的比例。
均方誤差(Mean Square Error,MSE)相對于平均絕對誤差而言,均方誤差求的是所有標簽值與回歸模型預(yù)測值的偏差的平方的平均。
均方根誤差(Root-Mean-Square Error,RMSE),也稱標準誤差,是在均方誤差的基礎(chǔ)上進行開方運算。RMSE會被用來衡量觀測值同真值之間的偏差。
R平方,決定系數(shù),反映因變量的全部變異能通過目前的回歸模型被模型中的自變量解釋的比例。比例越接近于1,表示當前的回歸模型對數(shù)據(jù)的解釋越好,越能精確描述數(shù)據(jù)的真實分布。(2)分類問題
分類問題常用的性能度量指標包括錯誤率(Error Rate)、精確率(Accuracy)、查準率(Precision)、查全率(Recall)、F1、ROC曲線、AUC曲線和R平方等。更詳細的內(nèi)容可見 模型評估方法與準則(鏈接見文末)。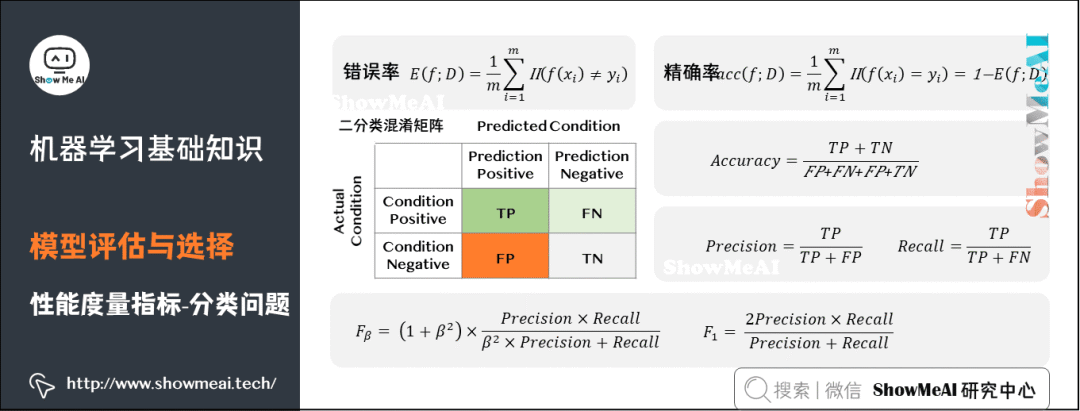 ?
?錯誤率:分類錯誤的樣本數(shù)占樣本總數(shù)的比例。
精確率:分類正確的樣本數(shù)占樣本總數(shù)的比例。
查準率(也稱準確率),即在檢索后返回的結(jié)果中,真正正確的個數(shù)占你認為是正確的結(jié)果的比例。
查全率(也稱召回率),即在檢索結(jié)果中真正正確的個數(shù),占整個數(shù)據(jù)集(檢索到的和未檢索到的)中真正正確個數(shù)的比例。
F1是一個綜合考慮查準率與查全率的度量,其基于查準率與查全率的調(diào)和平均定義:即:F1度量的一般形式-Fβ,能讓我們表達出對查準率、查全率的不同偏好。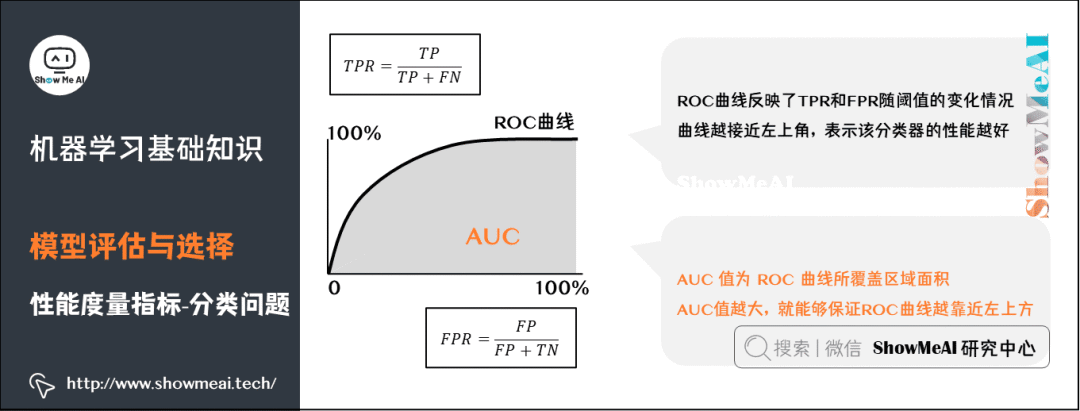 ?ROC曲線(Receiver Operating Characteristic Curve)全稱是「受試者工作特性曲線」。綜合考慮了概率預(yù)測排序的質(zhì)量,體現(xiàn)了學習器在不同任務(wù)下的「期望泛化性能」的好壞。ROC曲線的縱軸是「真正例率」(TPR),橫軸是「假正例率」(FPR)。
AUC(Area Under ROC Curve)是ROC曲線下面積,代表了樣本預(yù)測的排序質(zhì)量。
?ROC曲線(Receiver Operating Characteristic Curve)全稱是「受試者工作特性曲線」。綜合考慮了概率預(yù)測排序的質(zhì)量,體現(xiàn)了學習器在不同任務(wù)下的「期望泛化性能」的好壞。ROC曲線的縱軸是「真正例率」(TPR),橫軸是「假正例率」(FPR)。
AUC(Area Under ROC Curve)是ROC曲線下面積,代表了樣本預(yù)測的排序質(zhì)量。
從一個比較高的角度來認識AUC:仍然以異常用戶的識別為例,高的AUC值意味著,模型在能夠盡可能多地識別異常用戶的情況下,仍然對正常用戶有著一個較低的誤判率(不會因為為了識別異常用戶,而將大量的正常用戶給誤判為異常。
9)評估方法
我們手上沒有未知的樣本,如何可靠地評估?關(guān)鍵是要獲得可靠的「測試集數(shù)據(jù)」(Test Set),即測試集(用于評估)應(yīng)該與訓練集(用于模型學習)「互斥」。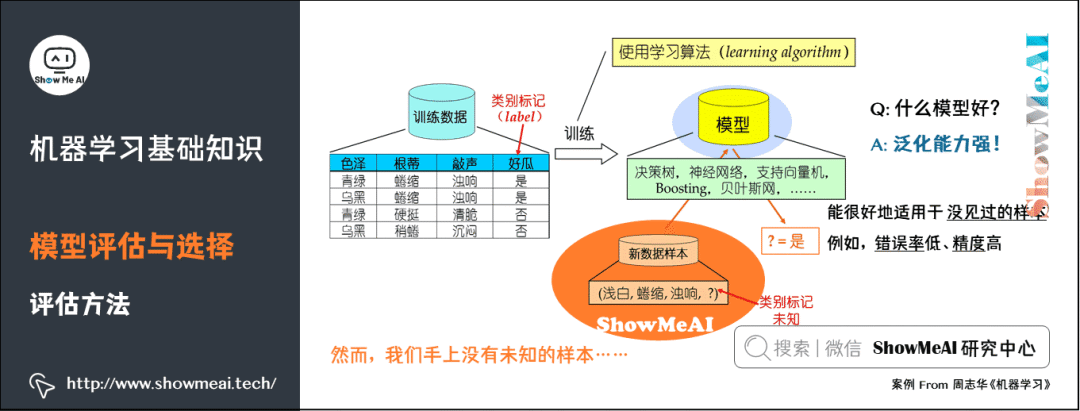 ?常見的評估方法有:留出法(Hold-out)、交叉驗證法( Cross Validation)、自助法(Bootstrap)。更詳細的內(nèi)容可見 模型評估方法與準則(鏈接見文末)。
留出法(Hold-out)是機器學習中最常見的評估方法之一,它會從訓練數(shù)據(jù)中保留出驗證樣本集,這部分數(shù)據(jù)不用于訓練,而用于模型評估。
?常見的評估方法有:留出法(Hold-out)、交叉驗證法( Cross Validation)、自助法(Bootstrap)。更詳細的內(nèi)容可見 模型評估方法與準則(鏈接見文末)。
留出法(Hold-out)是機器學習中最常見的評估方法之一,它會從訓練數(shù)據(jù)中保留出驗證樣本集,這部分數(shù)據(jù)不用于訓練,而用于模型評估。
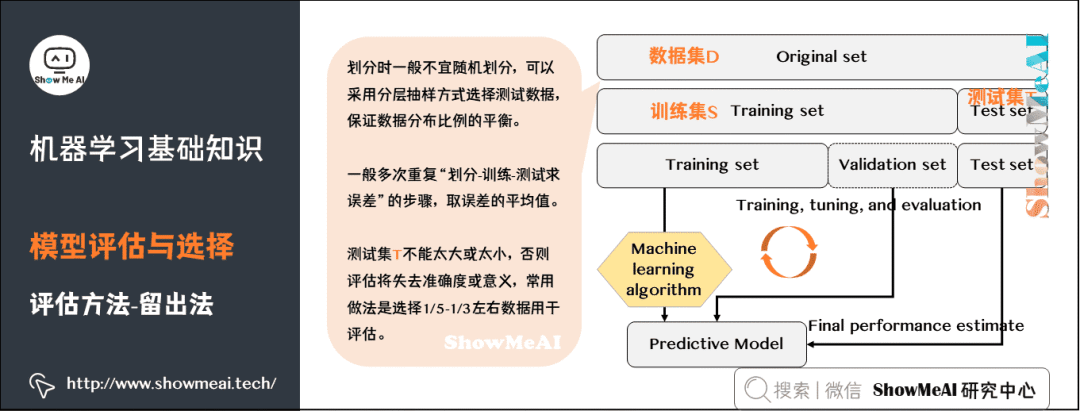 ?機器學習中,另外一種比較常見的評估方法是交叉驗證法(Cross Validation)。k 折交叉驗證對 k 個不同分組訓練的結(jié)果進行平均來減少方差,因此模型的性能對數(shù)據(jù)的劃分就不那么敏感,對數(shù)據(jù)的使用也會更充分,模型評估結(jié)果更加穩(wěn)定。
?機器學習中,另外一種比較常見的評估方法是交叉驗證法(Cross Validation)。k 折交叉驗證對 k 個不同分組訓練的結(jié)果進行平均來減少方差,因此模型的性能對數(shù)據(jù)的劃分就不那么敏感,對數(shù)據(jù)的使用也會更充分,模型評估結(jié)果更加穩(wěn)定。
 ?自助法(Bootstrap)是一種用小樣本估計總體值的一種非參數(shù)方法,在進化和生態(tài)學研究中應(yīng)用十分廣泛。
Bootstrap通過有放回抽樣生成大量的偽樣本,通過對偽樣本進行計算,獲得統(tǒng)計量的分布,從而估計數(shù)據(jù)的整體分布。
?自助法(Bootstrap)是一種用小樣本估計總體值的一種非參數(shù)方法,在進化和生態(tài)學研究中應(yīng)用十分廣泛。
Bootstrap通過有放回抽樣生成大量的偽樣本,通過對偽樣本進行計算,獲得統(tǒng)計量的分布,從而估計數(shù)據(jù)的整體分布。

10)模型調(diào)優(yōu)與選擇準則
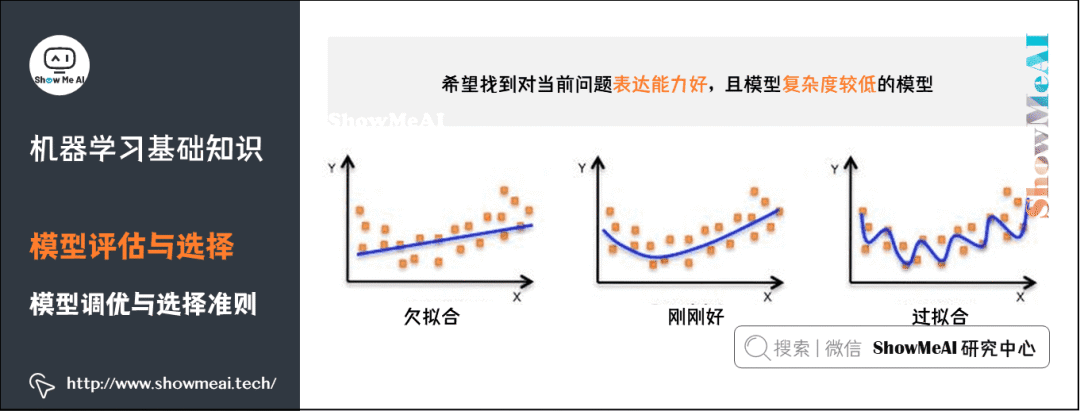
我們希望找到對當前問題表達能力好,且模型復(fù)雜度較低的模型:-
表達力好的模型,可以較好地對訓練數(shù)據(jù)中的規(guī)律和模式進行學習;
-
復(fù)雜度低的模型,方差較小,不容易過擬合,有較好的泛化表達。
11)如何選擇最優(yōu)的模型
(1)驗證集評估選擇
-
切分數(shù)據(jù)為訓練集和驗證集。
-
對于準備好的候選超參數(shù),在訓練集上進行模型,在驗證集上評估。
(2)網(wǎng)格搜索/隨機搜索交叉驗證
-
通過網(wǎng)格搜索/隨機搜索產(chǎn)出候選的超參數(shù)組。
-
對參數(shù)組的每一組超參數(shù),使用交叉驗證評估效果。
-
選出效果最好的超參數(shù)。
(3)貝葉斯優(yōu)化
-
基于貝葉斯優(yōu)化的超參數(shù)調(diào)優(yōu)。
-
imagination
+關(guān)注
關(guān)注
1文章
576瀏覽量
61448
原文標題:圖解 72 個機器學習基礎(chǔ)知識點
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Aigtek功率放大器應(yīng)用:電感線圈的知識點分享

傳統(tǒng)機器學習方法和應(yīng)用指導

硬件工程師面試基礎(chǔ)知識點
接口測試理論、疑問收錄與擴展相關(guān)知識點


【「時間序列與機器學習」閱讀體驗】+ 簡單建議
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)篇


一篇搞定DCS系統(tǒng)相關(guān)知識點
【量子計算機重構(gòu)未來 | 閱讀體驗】第二章關(guān)鍵知識點
機器學習基礎(chǔ)知識全攻略





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論