 昇騰AI處理器:全面解密DaVinci架構
昇騰AI處理器:全面解密DaVinci架構
在達芬奇架構下,控制單元為整個計算過程提供了指令控制,相當于AI Core的司令部,負責整個AI Core的運行,起到了至關重要的作用。 控制單元的主要組成部分為系統控制模塊、指令緩存、標量指令處理隊列、指令發射模塊、矩陣運算隊列、向量運算隊列、存儲轉換隊列和事件同步模塊,如圖3-13中加粗所示。 在指令執行過程中,可以提前預取后續指令,并一次讀入多條指令進入緩存,提升指令執行效率。
01 DaVinci架構(總覽)
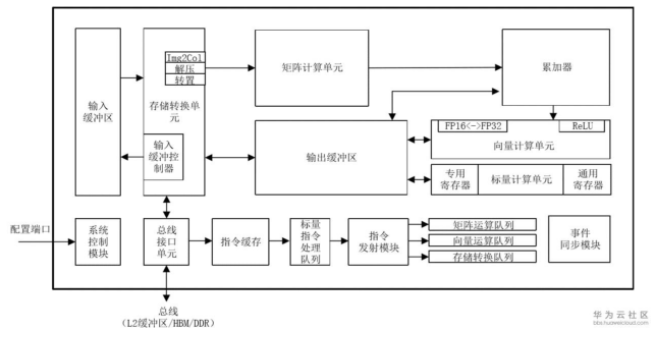
不同于傳統的支持通用計算的CPU和GPU,也不同于專用于某種特定算法的專用芯片ASIC,達芬奇架構本質上是為了適應某個特定領域中的常見的應用和算法,通常稱之為“特定域架構(Domain Specific Architecture,DSA)”芯片。
昇騰AI芯片的計算核心主要由AI Core構成,負責執行標量、向量和張量相關的計算密集型算子。 AI Core采用了達芬奇架構,其基本結構如圖3-2所示,從控制上可以看成是一個相對簡化的現代微處理器的基本架構。 它包括了三種基礎計算資源:矩陣計算單元(Cube Unit)、向量計算單元(Vector Unit)和標量計算單元(Scalar Unit)。 這三種計算單元分別對應了張量、向量和標量三種常見的計算模式,在實際的計算過程中各司其職,形成了三條獨立的執行流水線,在系統軟件的統一調度下互相配合達到優化的計算效率。 此外在矩陣計算單元和向量計算單元內部還提供了不同精度、不同類型的計算模式。 AI Core中的矩陣計算單元目前可以支持INT8、INT4和FP16的計算; 向量計算單元目前可以支持FP16和FP32的計算。
為了配合AI Core中數據的傳輸和搬運,圍繞著三種計算資源還分布式的設置了一系列的片上緩沖區,比如用來放置整體圖像特征數據、網絡參數以及中間結果的輸入緩沖區(Input Buffer,IB)和輸出緩沖區(Output Buffer,OB),以及提供一些臨時變量的高速寄存器單元,這些寄存器單元位于各個計算單元中。 這些存儲資源的設計架構和組織方式不盡相同,但目的都是為了更好的適應不同計算模式下格式、精度和數據排布的需求。 這些存儲資源和相關聯的計算資源相連,或者和總線接口單元(Bus Interface Unit,BIU)相連從而可以獲得外部總線上的數據。
在AI Core中,輸入緩沖區之后設置了一個存儲轉換單元(Memory Transfer Unit,MTE)。 這是達芬奇架構的特色之一,主要的目的是為了以極高的效率實現數據格式的轉換。 比如前面提到GPU要通過矩陣計算來實現卷積,首先要通過Im2Col的方法把輸入的網絡和特征數據重新以一定的格式排列起來。 這一步在GPU當中是通過軟件來實現的,效率比較低下。 達芬奇架構采用了一個專用的存儲轉換單元來完成這一過程,將這一步完全固化在硬件電路中,可以在很短的時間之內完成整個轉置過程。 由于類似轉置的計算在深度神經網絡中出現的極為頻繁,這樣定制化電路模塊的設計可以提升AI Core的執行效率,從而能夠實現不間斷的卷積計算。
AI Core中的控制單元主要包括系統控制模塊、標量指令處理隊列、指令發射模塊、矩陣運算隊列、向量運算隊列、存儲轉換隊列和事件同步模塊。 系統控制模塊負責指揮和協調AI Core的整體運行模式,配置參數和實現功耗控制等。
在AI Core中,存儲單元為各個計算單元提供轉置過并符合要求的數據,計算單元返回運算的結果給存儲單元,控制單元為計算單元和存儲單元提供指令控制,三者相互協調合作完成計算任務。
02 DaVinci架構(控制單元)
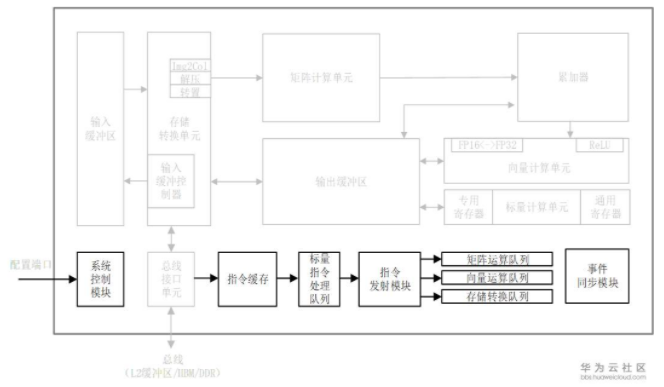
在達芬奇架構下,控制單元為整個計算過程提供了指令控制,相當于AI Core的司令部,負責整個AI Core的運行,起到了至關重要的作用。 控制單元的主要組成部分為系統控制模塊、指令緩存、標量指令處理隊列、指令發射模塊、矩陣運算隊列、向量運算隊列、存儲轉換隊列和事件同步模塊,如圖3-13中加粗所示。
在指令執行過程中,可以提前預取后續指令,并一次讀入多條指令進入緩存,提升指令執行效率。 多條指令從系統內存通過總線接口進入到AI Core的指令緩存中并等待后續硬件快速自動解碼或運算。 指令被解碼后便會被導入標量隊列中,實現地址解碼與運算控制。 這些指令包括矩陣計算指令、向量計算指令以及存儲轉換指令等。 在進入指令發射模塊之前,所有指令都作為普通標量指令被逐條順次處理。 標量隊列將這些指令的地址和參數解碼配置好后,由指令發射模塊根據指令的類型分別發送到對應的指令執行隊列中,而標量指令會駐留在標量指令處理隊列中進行后續執行,如圖所示。
指令執行隊列由矩陣運算隊列、向量運算隊列和存儲轉換隊列組成。 矩陣計算指令進入矩陣運算隊列,向量計算指令進入向量運算隊,存儲轉換指令進入存儲轉換隊列,同一個指令執行隊列中的指令是按照進入隊列的順序進行執行的,不同指令執行隊列之間可以并行執行,通過多個指令執行隊列的并行執行可以提升整體執行效率。
當指令執行隊列中的指令到達隊列頭部時就進入真正的指令執行環節,并被分發到相應的執行單元中,如矩陣計算指令會發送到矩陣計算單元,存儲轉換指令會發送到存儲轉換單元。 不同的執行單元可以并行的按照指令來進行計算或處理數據,同一個指令隊列中指令執行的流程被稱作為指令流水線。
對于指令流水線之間可能出現的數據依賴,達芬奇架構的解決方案是通過設置事件同步模塊來統一協調各個流水線的進程。 事件同步模塊時刻控制每條流水線的執行狀態,并分析不同流水線的依賴關系,從而解決數據依賴和同步的問題。 比如矩陣運算隊列的當前指令需要依賴向量計算單元的結果,在執行過程中,事件同步控制模塊會暫停矩陣運算隊列執行流程,要求其等待向量計算單元的結果。 而當向量計算單元完成計算并輸出結果后,此時事件同步模塊則通知矩陣運算隊列需要的數據已經準備好,可以繼續執行。 在事件同步模塊準許放行之后矩陣運算隊列才會發射當前指令。 在達芬奇架構中,無論是流水線內部的同步還是流水線之間的同步,都是通過事件同步模塊利用軟件控制來實現的。
在控制單元中還存在一個系統控制模塊。 在AI Core運行之前,需要外部的任務調度器來控制和初始化AI Core的各種配置接口,如指令信息、參數信息以及任務塊信息等。 這里的任務塊是指AI Core中的最小的計算任務粒度。 在配置完成后,系統控制模塊會控制任務塊的執行進程,同時在任務塊執行完成后,系統控制模塊會進行中斷處理和狀態申報。 如果在執行過程中出現了錯誤,系統控制模塊將會把執行的錯誤狀態報告給任務調度器,進而反饋當前AI Core的狀態信息給整個昇騰AI芯片系統。
03 DaVinci架構(計算單元)
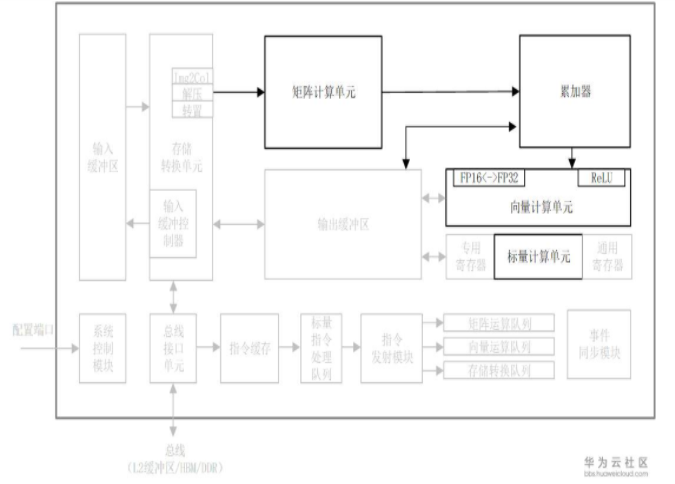
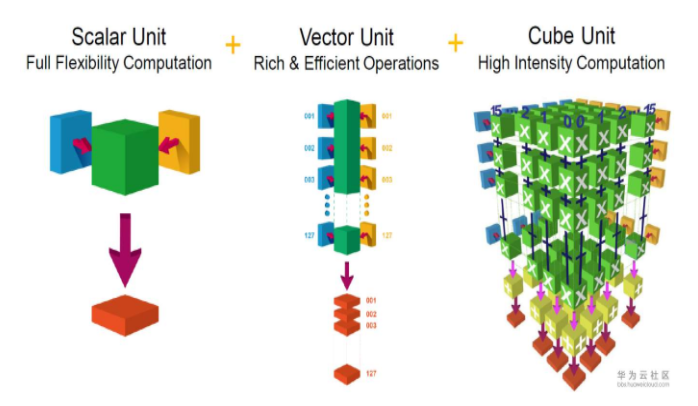
計算單元是AI Core中提供強大算力的核心單元,相當于AI Core的主力軍。 AI Core計算單元主要包含矩陣計算單元、向量計算單元、標量計算單元和累加器,矩陣計算單元和累加器主要完成與矩陣相關的運算,向量計算單元負責執行向量運算,標量計算單元主要負責各類型的標量數據運算和程序的流程控制。
1、矩陣計算單元
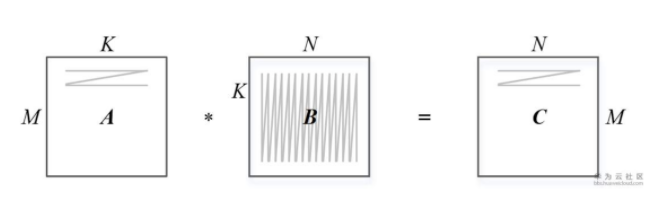
上圖表示一個矩陣A和另一個矩陣B之間的乘法運算C=A*B,其中M表示矩陣A的行數,K表示矩陣A的列數以及矩陣B的行數,N表示矩陣B的列數。 這個矩陣乘法在CPU如何實現?

該程序需要用到3個循環進行一次完整的矩陣相乘計算,如果在一個單發射的CPU上執行至少需要M?K?N個時鐘周期才能完成,當矩陣非常龐大時執行過程極為耗時。
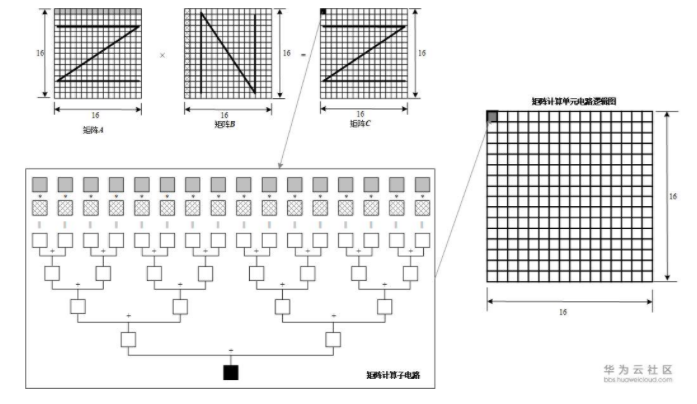
由于常見的深度神經網絡算法中大量的使用了矩陣計算,達芬奇架構中特意對矩陣計算進行了深度的優化并定制了相應的矩陣計算單元來支持高吞吐量的矩陣處理。 通過精巧設計的定制電路和極致的后端優化手段,矩陣計算單元可以用一條指令完成兩個16*16矩陣的相乘運算(標記為16^3,也是Cube這一名稱的來歷),等同于在極短時間內進行了16^3=4096個乘加運算,并且可以實現FP16的運算精度。 如圖3-7所示,矩陣計算單元在完成A?B=C的矩陣運算時,會事先將矩陣A按行存放在輸入緩沖區中,同時將矩陣B按列存放在輸入緩沖區中,通過矩陣計算單元計算后得到的結果矩陣C按行存放在輸出緩沖區中。 在矩陣相乘運算中,如圖3-7所示,矩陣C的第一元素由矩陣A的第一行的16個元素和矩陣B的第一列的16個元素由矩陣計算單元子電路進行16次乘法和15次加法運算得出。 矩陣計算單元中存在256個矩陣計算子電路組成,可以由一條指令并行完成矩陣C的256個元素計算。
2、向量計算單元
AI Core中的向量計算單元主要負責完成和向量相關的運算,能夠實現向量和標量,或雙向量之間的計算,功能覆蓋各種基本和多種定制的計算類型,主要包括FP32、FP16、INT32和INT8等數據類型的計算。
如上圖所示,向量計算單元可以快速完成兩個FP16類型的向量相加或者相乘。 向量計算單元的源操作數和目的操作數通常都保存在輸出緩沖器中。 對向量計算單元而言,輸入的數據可以不連續,這取決于輸入數據的尋址模式。
向量計算單元可以作為矩陣計算單元和輸出緩沖區之間的數據通路和橋梁。 矩陣運算完成后的結果在向輸出緩沖區傳遞的過程中,向量計算單元可以順便完成在深度神經網絡尤其是卷積神經網絡計算中常用的ReLU激活函數、池化等功能并實現數據格式的轉換。 經過向量計算單元處理后的數據可以被寫回到輸出緩沖區或者矩陣計算單元中,以等待下一次運算。 所有的這些操作都可以通過軟件配合相應的向量單元指令來實現。 向量計算單元提供了豐富的計算功能,也可以實現很多特殊的計算函數,從而和矩陣計算單元形成功能互補,全面完善了AI Core對非矩陣類型數據計算的能力。
3、標量計算單元
標量計算單元負責完成AI Core中與標量相關的運算。 它相當于一個微型CPU,控制整個AI Core的運行。 標量計算單元可以對程序中的循環進行控制,可以實現分支判斷,其結果可以通過在事件同步模塊中插入同步符的方式來控制AI Core中其它功能性單元的執行流水。 它還為矩陣計算單元或向量計算單元提供數據地址和相關參數的計算,并且能夠實現基本的算術運算。 其它復雜度較高的標量運算則由專門的AI CPU通過算子完成。
在標量計算單元周圍配備了多個通用寄存器(General Purpose Register,GPR)和專用寄存器(Special Purpose Register,SPR)。 這些通用寄存器可以用于變量或地址的寄存,為算術邏輯運算提供源操作數和存儲中間計算結果。 專用寄存器的設計是為了支持指令集中一些指令的特殊功能,一般不可以直接訪問,只有部分可以通過指令讀寫。
AI Core中具有代表性的專用寄存器包括Core ID(用于標識不同的AI Core),VA(向量地址寄存器)以及STATUS(AI Core運行狀態寄存器)等。 軟件可以通過監視這些專用寄存器來控制和改變AI Core的運行狀態和模式。
04 DaVinci架構(存儲系統)
AI Core的片上存儲單元和相應的數據通路構成了存儲系統。 眾所周知,幾乎所有的深度學習算法都是數據密集型的應用。 對于昇騰AI芯片來說,合理設計的數據存儲和傳輸結構對于最終系統運行的性能至關重要。 不合理的設計往往成為性能瓶頸,從而白白浪費了片上海量的計算資源。 AI Core通過各種類型分布式緩沖區之間的相互配合,為深度神經網絡計算提供了大容量和及時的數據供應,為整體計算性能消除了數據流傳輸的瓶頸,從而支撐了深度學習計算中所需要的大規模、高并發數據的快速有效提取和傳輸。
1、存儲單元
芯片中的計算資源要想發揮強勁算力,必要條件是保證輸入數據能夠及時準確的出現在計算單元里。 達芬奇架構通過精心設計的存儲單元為計算資源保證了數據的供應,相當于AI Core中的后勤系統。 AI Core中的存儲單元由存儲控制單元、緩沖區和寄存器組成,如圖3-11中的加粗顯示。 存儲控制單元通過總線接口可以直接訪問AI Core之外的更低層級的緩存,并且也可以直通到DDR或HBM從而可以直接訪問內存。 存儲控制單元中還設置了存儲轉換單元,其目的是將輸入數據轉換成AI Core中各類型計算單元所兼容的數據格式。 緩沖區包括了用于暫存原始圖像特征數據的輸入緩沖區,以及處于中心的輸出緩沖區來暫存各種形式的中間數據和輸出數據。 AI Core中的各類寄存器資源主要是標量計算單元在使用。
所有的緩沖區和寄存器的讀寫都可以通過底層軟件顯式的控制,有經驗的程序員可以通過巧妙的編程方式來防止存儲單元中出現讀寫沖突而影響流水線的進程。 對于類似卷積和矩陣這樣規律性強的計算模式,高度優化的程序可以實現全程無阻塞的流水線執行。
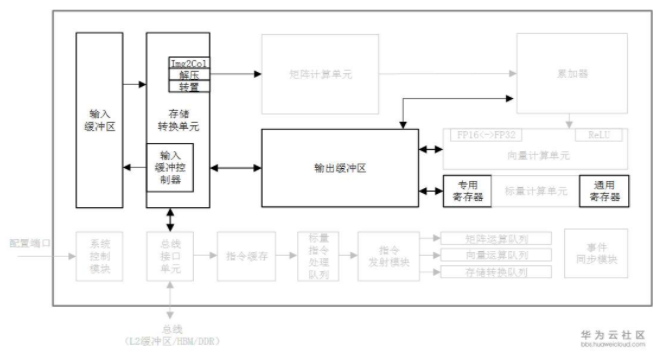
上圖中的總線接口單元作為AI Core的“大門”,是一個與系統總線交互的窗口,并以此通向外部世界。 AI Core通過總線接口從外部L2緩沖區、DDR或HBM中讀取或者寫回數據。 總線接口在這個過程中可以將AI Core內部發出的讀寫請求轉換為符合總線要求的外部讀寫請求,并完成協議的交互和轉換等工作。
輸入數據從總線接口讀入后就會經由存儲轉換單元進行處理。 存儲轉換單元作為AI Core內部數據通路的傳輸控制器,負責AI Core內部數據在不同緩沖區之間的讀寫管理,以及完成一系列的格式轉換操作,如補零,Img2Col,轉置、解壓縮等。 存儲轉換單元還可以控制AI Core內部的輸入緩沖區,從而實現局部數據的緩存。
在深度神經網絡計算中,由于輸入圖像特征數據通道眾多且數據量龐大,往往會采用輸入緩沖區來暫時保留需要頻繁重復使用的數據,以達到節省功耗、提高性能的效果。 當輸入緩沖區被用來暫存使用率較高的數據時,就不需要每次通過總線接口到AI Core的外部讀取,從而在減少總線上數據訪問頻次的同時也降低了總線上產生擁堵的風險。 另外,當存儲轉換單元進行數據的格式轉換操作時,會產生巨大的帶寬需求,達芬奇架構要求源數據必須被存放于輸入緩沖區中,才能夠進行格式轉換,而輸入緩沖控制器負責控制數據流入輸入緩沖區中。 輸入緩沖區的存在有利于將大量用于矩陣計算的數據一次性的被搬移到AI Core內部,同時利用固化的硬件極高的提升了數據格式轉換的速度,避免了矩陣計算單元的阻塞,消除了由于數據轉換過程緩慢而帶來的性能瓶頸。
在神經網絡中往往可以把每層計算的中間結果放在輸出緩沖區中,從而在進入下一層計算時方便的獲取數據。 由于通過總線讀取數據的帶寬低,延遲大,通過充分利用輸出緩沖區就可以大大提升計算效率。
在矩陣計算單元還包含有直接的供數寄存器,提供當前正在進行計算的大小為1616的左、右輸入矩陣。 在矩陣計算單元之后,累加器也含有結果寄存器,用于緩存當前計算的大小為1616的結果矩陣。 在累加器配合下可以不斷的累積前次矩陣計算的結果,這在卷積神經網絡的計算過程中極為常見。 在軟件的控制下,當累積的次數達到要求后,結果寄存器中的結果可以被一次性的傳輸到輸出緩沖區中。
AI Core中的存儲系統為計算單元提供源源不斷的數據,高效適配計算單元的強大算力,綜合提升了AI Core的整體計算性能。 與谷歌TPU設計中的統一緩沖區設計理念相類似,AI Core采用了大容量的片上緩沖區設計,通過增大的片上緩存數據量來減少數據從片外存儲系統搬運到AI Core中的頻次,從而可以降低數據搬運過程中所產生的功耗,有效控制了整體計算的能耗。
達芬奇架構通過存儲轉換單元中內置的定制電路,在進行數據傳輸的同時,就可以實現諸如Im2Col或者其它類型的格式轉化操作,不光是節省了格式轉換過程中的消耗,同時也節省了數據轉換的指令開銷。 這種能將數據在傳輸的同時進行轉換的指令稱為隨路指令。 硬件單元對隨路指令的支持為程序設計提供了便捷性。
2、數據通路
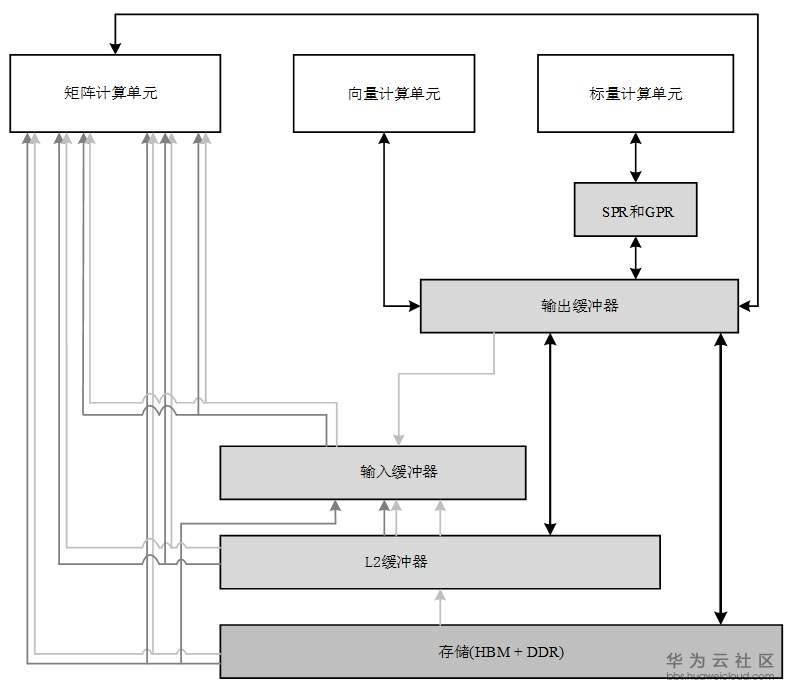
數據通路指的是AI Core在完成一個計算任務時,數據在AI Core中的流通路徑。 前文已經以矩陣相乘為例簡單介紹了數據的搬運路徑。 圖3-12展示了達芬奇架構中一個AI Core內完整的數據傳輸路徑。 這其中包含了DDR或HBM,以及L2緩沖區,這些都屬于AI Core核外的數據存儲系統。 圖中其它各類型的數據緩沖區都屬于核內存儲系統。
核外存儲系統中的數據可以通過LOAD指令被直接搬運到矩陣計算單元中進行計算,輸出的結果會被保存在輸出緩沖區中。 除了直接將數據通過LOAD指令發送到矩陣計算單元中,核外存儲系統中的數據也可以通過LOAD指令先行傳入輸入緩沖區,再通過其它指令傳輸到矩陣計算單元中。 這樣做的好處是利用大容量的輸入緩沖區來暫存需要被矩陣計算單元反復使用的數據。
矩陣計算單元和輸出緩沖區之間是可以相互傳輸數據的。 由于矩陣計算單元容量較小,部分矩陣運算結果可以寫入輸出緩沖區中,從而提供充裕的空間容納后續的矩陣計算。 當然也可以將輸出緩沖區中的數據再次搬回矩陣計算單元作為后續計算的輸入。 輸出緩沖區和向量計算單元、標量計算單元以及核外存儲系統之間都有一條獨立的雙向數據通路。 輸出緩沖區中的數據可以通過專用寄存器或通用寄存器進出標量計算單元。
值得注意的是,AI Core中的所有數據如果需要向外部傳輸,都必須經過輸出緩沖區,才能夠被寫回到核外存儲系統中。 例如輸入緩沖區中的圖像特征數據如果需要被輸出到系統內存中,則需要先經過矩陣計算單元處理后存入輸出緩沖區中,最終從輸出緩沖區寫回到核外存儲系統中。 在AI Core中并沒有一條從輸入緩沖區直接寫入到輸出緩沖區的數據通路。 因此輸出緩沖區作為AI Core數據流出的閘口,能夠統一的控制和協調所有核內數據的輸出。
達芬奇架構數據通路的特點是多進單出,數據流入AI Core可以通過多條數據通路,可以從外部直接流入矩陣計算單元、輸入緩沖區和輸出緩沖區中的任何一個,流入路徑的方式比較靈活,在軟件的控制下由不同數據流水線分別進行管理。 而數據輸出則必須通過輸出緩沖區,最終才能輸出到核外存儲系統中。
這樣設計的理由主要是考慮到了深度神經網絡計算的特征。 神經網絡在計算過程中,往往輸入的數據種類繁多并且數量巨大,比如多個通道、多個卷積核的權重和偏置值以及多個通道的特征值等,而AI Core中對應這些數據的存儲單元可以相對獨立且固定,可以通過并行輸入的方式來提高數據流入的效率,滿足海量計算的需求。 AI Core中設計多個輸入數據通路的好處是對輸入數據流的限制少,能夠為計算源源不斷的輸送源數據。 與此相反,深度神經網絡計算將多種輸入數據處理完成后往往只生成輸出特征矩陣,數據種類相對單一。 根據神經網絡輸出數據的特點,在AI Core中設計了單輸出的數據通路,一方面節約了芯片硬件資源,另一方面可以統一管理輸出數據,將數據輸出的控制硬件降到最低。
綜上,達芬奇架構中的各個存儲單元之間的數據通路以及多進單出的核內外數據交換機制是在深入研究了以卷積神經網絡為代表的主流深度學習算法后開發出來的,目的是在保障數據良好的流動性前提下,減少芯片成本、提升計算性能、降低控制復雜度。
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19409瀏覽量
231193 -
存儲
+關注
關注
13文章
4355瀏覽量
86177 -
AI
+關注
關注
87文章
31536瀏覽量
270343 -
控制單元
+關注
關注
0文章
77瀏覽量
12850 -
davinci
+關注
關注
0文章
33瀏覽量
12417
原文標題:昇騰AI處理器:全面解密DaVinci架構
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
華為發布全球算力最強AI處理器,芯片昇騰910問世!
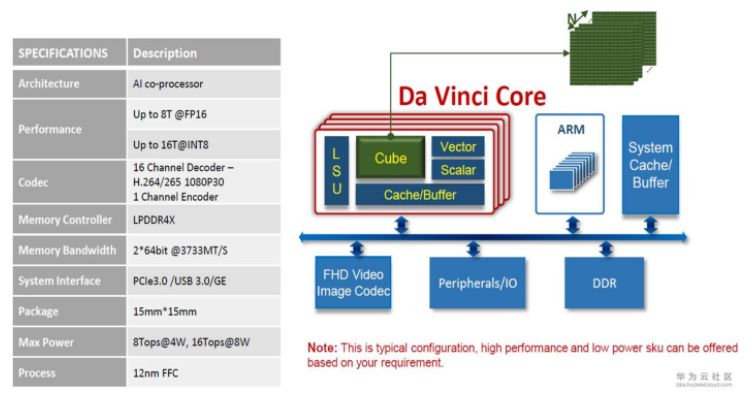
華為正式推出兩款AI芯片:昇騰910和昇騰310
華為昇騰師資培訓沙龍成都場
昇騰310的用途以及設計細節
華為推出昇騰910、昇騰310兩款AI芯片,昇騰910的半精度算力可達到256 TFLOPs
華為發布最強的AI處理器“昇騰910”與打造全棧全場景AI解決方案

深度解析昇騰AI全棧架構設計
昇騰AI框架全棧深度介紹
昇騰與昇思原生,助力智譜打造自主創新大模型體系!






 工商網監
工商網監
評論