 OpenHarmony 3.2 Beta Audio——音頻渲染
OpenHarmony 3.2 Beta Audio——音頻渲染
點擊藍字 ╳ 關注我們

巴延興
深圳開鴻數字產業發展有限公司
資深OS框架開發工程師
一、簡介
二、目錄
audio_framework
├── frameworks
│ ├── js #js 接口
│ │ └── napi
│ │ └── audio_renderer #audio_renderer NAPI接口
│ │ ├── include
│ │ │ ├── audio_renderer_callback_napi.h
│ │ │ ├── renderer_data_request_callback_napi.h
│ │ │ ├── renderer_period_position_callback_napi.h
│ │ │ └── renderer_position_callback_napi.h
│ │ └── src
│ │ ├── audio_renderer_callback_napi.cpp
│ │ ├── audio_renderer_napi.cpp
│ │ ├── renderer_data_request_callback_napi.cpp
│ │ ├── renderer_period_position_callback_napi.cpp
│ │ └── renderer_position_callback_napi.cpp
│ └── native #native 接口
│ └── audiorenderer
│ ├── BUILD.gn
│ ├── include
│ │ ├── audio_renderer_private.h
│ │ └── audio_renderer_proxy_obj.h
│ ├── src
│ │ ├── audio_renderer.cpp
│ │ └── audio_renderer_proxy_obj.cpp
│ └── test
│ └── example
│ └── audio_renderer_test.cpp
├── interfaces
│ ├── inner_api #native實現的接口
│ │ └── native
│ │ └── audiorenderer #audio渲染本地實現的接口定義
│ │ └── include
│ │ └── audio_renderer.h
│ └── kits #js調用的接口
│ └── js
│ └── audio_renderer #audio渲染NAPI接口的定義
│ └── include
│ └── audio_renderer_napi.h
└── services #服務端
└── audio_service
├── BUILD.gn
├── client #IPC調用中的proxy端
│ ├── include
│ │ ├── audio_manager_proxy.h
│ │ ├── audio_service_client.h
│ └── src
│ ├── audio_manager_proxy.cpp
│ ├── audio_service_client.cpp
└── server #IPC調用中的server端
├── include
│ └── audio_server.h
└── src
├── audio_manager_stub.cpp
└──audio_server.cpp三、音頻渲染總體流程
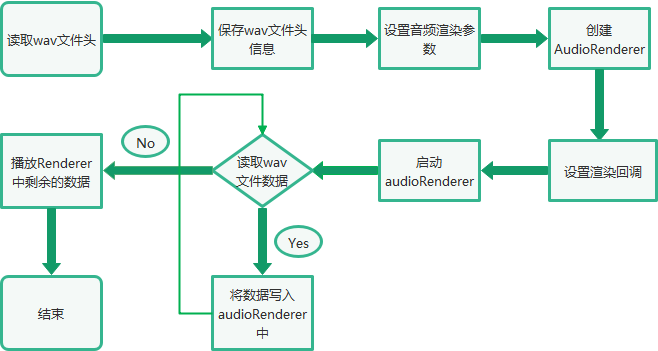
四、Native接口使用
bool TestPlayback(int argc, char *argv[]) const
{
FILE* wavFile = fopen(path, "rb");
//讀取wav文件頭信息
size_t bytesRead = fread(&wavHeader, 1, headerSize, wavFile);
//設置AudioRenderer參數
AudioRendererOptions rendererOptions = {};
rendererOptions.streamInfo.encoding = AudioEncodingType::ENCODING_PCM;
rendererOptions.streamInfo.samplingRate = static_cast(wavHeader.SamplesPerSec);
rendererOptions.streamInfo.format = GetSampleFormat(wavHeader.bitsPerSample);
rendererOptions.streamInfo.channels = static_cast(wavHeader.NumOfChan);
rendererOptions.rendererInfo.contentType = contentType;
rendererOptions.rendererInfo.streamUsage = streamUsage;
rendererOptions.rendererInfo.rendererFlags = 0;
//創建AudioRender實例
unique_ptr audioRenderer = AudioRenderer::Create(rendererOptions);
shared_ptr cb1 = make_shared();
//設置音頻渲染回調
ret = audioRenderer->SetRendererCallback(cb1);
//InitRender方法主要調用了audioRenderer實例的Start方法,啟動音頻渲染
if (!InitRender(audioRenderer)) {
AUDIO_ERR_LOG("AudioRendererTest: Init render failed");
fclose(wavFile);
return false;
}
//StartRender方法主要是讀取wavFile文件的數據,然后通過調用audioRenderer實例的Write方法進行播放
if (!StartRender(audioRenderer, wavFile)) {
AUDIO_ERR_LOG("AudioRendererTest: Start render failed");
fclose(wavFile);
return false;
}
//停止渲染
if (!audioRenderer->Stop()) {
AUDIO_ERR_LOG("AudioRendererTest: Stop failed");
}
//釋放渲染
if (!audioRenderer->Release()) {
AUDIO_ERR_LOG("AudioRendererTest: Release failed");
}
//關閉wavFile
fclose(wavFile);
return true;
}五、調用流程
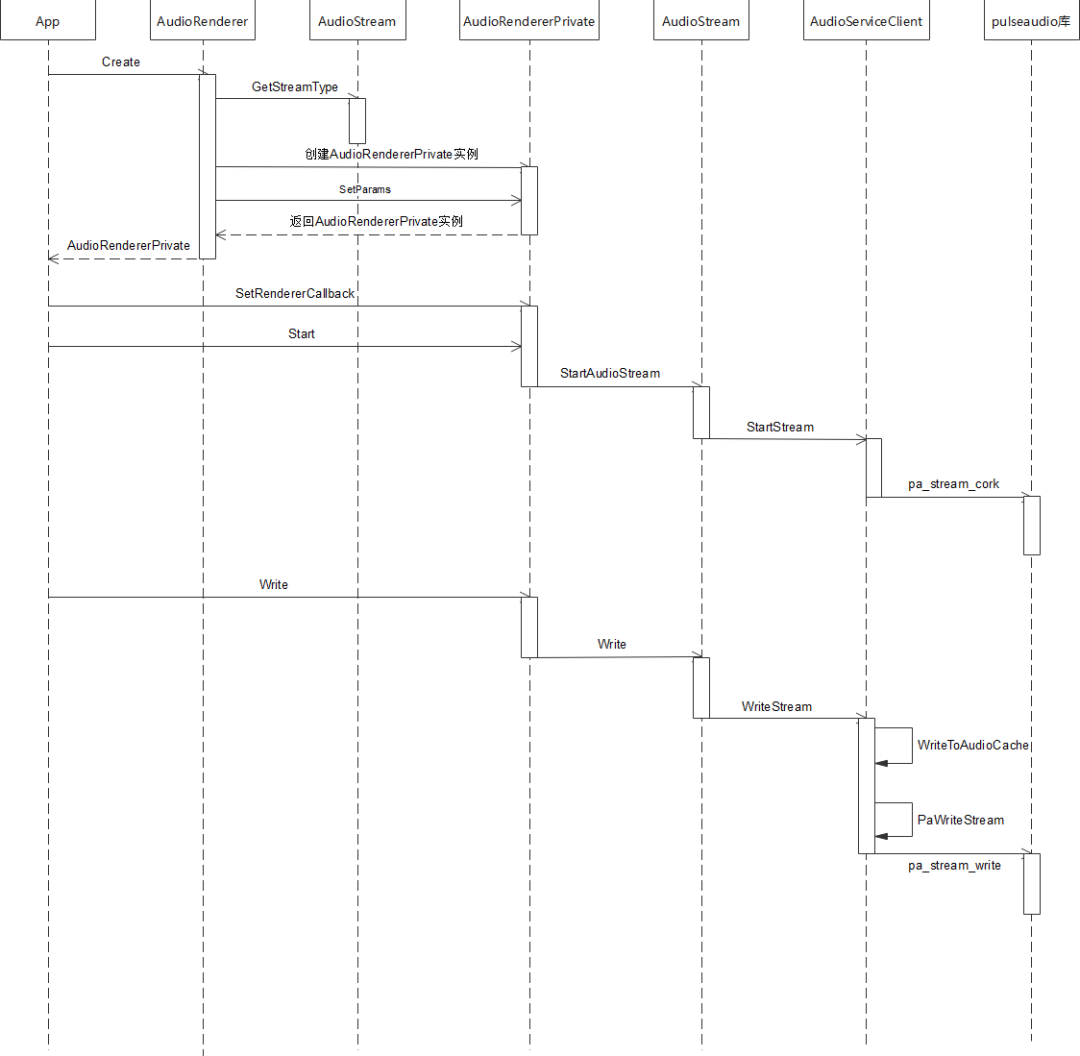
std::unique_ptr AudioRenderer::Create(const std::string cachePath,
const AudioRendererOptions &rendererOptions, const AppInfo &appInfo)
{
ContentType contentType = rendererOptions.rendererInfo.contentType;
StreamUsage streamUsage = rendererOptions.rendererInfo.streamUsage;
AudioStreamType audioStreamType = AudioStream::GetStreamType(contentType, streamUsage);
auto audioRenderer = std::make_unique(audioStreamType, appInfo);
if (!cachePath.empty()) {
AUDIO_DEBUG_LOG("Set application cache path");
audioRenderer->SetApplicationCachePath(cachePath);
}
audioRenderer->rendererInfo_.contentType = contentType;
audioRenderer->rendererInfo_.streamUsage = streamUsage;
audioRenderer->rendererInfo_.rendererFlags = rendererOptions.rendererInfo.rendererFlags;
AudioRendererParams params;
params.sampleFormat = rendererOptions.streamInfo.format;
params.sampleRate = rendererOptions.streamInfo.samplingRate;
params.channelCount = rendererOptions.streamInfo.channels;
params.encodingType = rendererOptions.streamInfo.encoding;
if (audioRenderer->SetParams(params) != SUCCESS) {
AUDIO_ERR_LOG("SetParams failed in renderer");
audioRenderer = nullptr;
return nullptr;
}
return audioRenderer;
}int32_t AudioRendererPrivate::SetRendererCallback(const std::shared_ptr &callback)
{
RendererState state = GetStatus();
if (state == RENDERER_NEW || state == RENDERER_RELEASED) {
return ERR_ILLEGAL_STATE;
}
if (callback == nullptr) {
return ERR_INVALID_PARAM;
}
// Save reference for interrupt callback
if (audioInterruptCallback_ == nullptr) {
return ERROR;
}
std::shared_ptr cbInterrupt =
std::static_pointer_cast(audioInterruptCallback_);
cbInterrupt->SaveCallback(callback);
// Save and Set reference for stream callback. Order is important here.
if (audioStreamCallback_ == nullptr) {
audioStreamCallback_ = std::make_shared();
if (audioStreamCallback_ == nullptr) {
return ERROR;
}
}
std::shared_ptr cbStream =
std::static_pointer_cast(audioStreamCallback_);
cbStream->SaveCallback(callback);
(void)audioStream_->SetStreamCallback(audioStreamCallback_);
return SUCCESS;
}bool AudioRendererPrivate::Start(StateChangeCmdType cmdType) const
{
AUDIO_INFO_LOG("AudioRenderer::Start");
RendererState state = GetStatus();
AudioInterrupt audioInterrupt;
switch (mode_) {
case InterruptMode:
audioInterrupt = sharedInterrupt_;
break;
case InterruptMode:
audioInterrupt = audioInterrupt_;
break;
default:
break;
}
AUDIO_INFO_LOG("AudioRenderer: %{public}d, streamType: %{public}d, sessionID: %{public}d",
mode_, audioInterrupt.streamType, audioInterrupt.sessionID);
if (audioInterrupt.streamType == STREAM_DEFAULT || audioInterrupt.sessionID == INVALID_SESSION_ID) {
return false;
}
int32_t ret = AudioPolicyManager::GetInstance().ActivateAudioInterrupt(audioInterrupt);
if (ret != 0) {
AUDIO_ERR_LOG("AudioRendererPrivate::ActivateAudioInterrupt Failed");
return false;
}
return audioStream_->StartAudioStream(cmdType);
}bool AudioStream::StartAudioStream(StateChangeCmdType cmdType)
{
int32_t ret = StartStream(cmdType);
resetTime_ = true;
int32_t retCode = clock_gettime(CLOCK_MONOTONIC, &baseTimestamp_);
if (renderMode_ == RENDER_MODE_CALLBACK) {
isReadyToWrite_ = true;
writeThread_ = std::make_unique<std::thread>(&AudioStream::WriteCbTheadLoop, this);
} else if (captureMode_ == CAPTURE_MODE_CALLBACK) {
isReadyToRead_ = true;
readThread_ = std::make_unique<std::thread>(&AudioStream::ReadCbThreadLoop, this);
}
isFirstRead_ = true;
isFirstWrite_ = true;
state_ = RUNNING;
AUDIO_INFO_LOG("StartAudioStream SUCCESS");
if (audioStreamTracker_) {
AUDIO_DEBUG_LOG("AudioStream:Calling Update tracker for Running");
audioStreamTracker_->UpdateTracker(sessionId_, state_, rendererInfo_, capturerInfo_);
}
return true;
}int32_t AudioServiceClient::StartStream(StateChangeCmdType cmdType)
{
int error;
lock_guard lockdata(dataMutex);
pa_operation *operation = nullptr;
pa_threaded_mainloop_lock(mainLoop);
pa_stream_state_t state = pa_stream_get_state(paStream);
streamCmdStatus = 0;
stateChangeCmdType_ = cmdType;
operation = pa_stream_cork(paStream, 0, PAStreamStartSuccessCb, (void *)this);
while (pa_operation_get_state(operation) == PA_OPERATION_RUNNING) {
pa_threaded_mainloop_wait(mainLoop);
}
pa_operation_unref(operation);
pa_threaded_mainloop_unlock(mainLoop);
if (!streamCmdStatus) {
AUDIO_ERR_LOG("Stream Start Failed");
ResetPAAudioClient();
return AUDIO_CLIENT_START_STREAM_ERR;
} else {
AUDIO_INFO_LOG("Stream Started Successfully");
return AUDIO_CLIENT_SUCCESS;
}
}int32_t AudioRendererPrivate::Write(uint8_t *buffer, size_t bufferSize)
{
return audioStream_->Write(buffer, bufferSize);
}size_t AudioStream::Write(uint8_t *buffer, size_t buffer_size)
{
int32_t writeError;
StreamBuffer stream;
stream.buffer = buffer;
stream.bufferLen = buffer_size;
isWriteInProgress_ = true;
if (isFirstWrite_) {
if (RenderPrebuf(stream.bufferLen)) {
return ERR_WRITE_FAILED;
}
isFirstWrite_ = false;
}
size_t bytesWritten = WriteStream(stream, writeError);
isWriteInProgress_ = false;
if (writeError != 0) {
AUDIO_ERR_LOG("WriteStream fail,writeError:%{public}d", writeError);
return ERR_WRITE_FAILED;
}
return bytesWritten;
}size_t AudioServiceClient::WriteStream(const StreamBuffer &stream, int32_t &pError)
{
size_t cachedLen = WriteToAudioCache(stream);
if (!acache.isFull) {
pError = error;
return cachedLen;
}
pa_threaded_mainloop_lock(mainLoop);
const uint8_t *buffer = acache.buffer.get();
size_t length = acache.totalCacheSize;
error = PaWriteStream(buffer, length);
acache.readIndex += acache.totalCacheSize;
acache.isFull = false;
if (!error && (length >= 0) && !acache.isFull) {
uint8_t *cacheBuffer = acache.buffer.get();
uint32_t offset = acache.readIndex;
uint32_t size = (acache.writeIndex - acache.readIndex);
if (size > 0) {
if (memcpy_s(cacheBuffer, acache.totalCacheSize, cacheBuffer + offset, size)) {
AUDIO_ERR_LOG("Update cache failed");
pa_threaded_mainloop_unlock(mainLoop);
pError = AUDIO_CLIENT_WRITE_STREAM_ERR;
return cachedLen;
}
AUDIO_INFO_LOG("rearranging the audio cache");
}
acache.readIndex = 0;
acache.writeIndex = 0;
if (cachedLen < stream.bufferLen) {
StreamBuffer str;
str.buffer = stream.buffer + cachedLen;
str.bufferLen = stream.bufferLen - cachedLen;
AUDIO_DEBUG_LOG("writing pending data to audio cache: %{public}d", str.bufferLen);
cachedLen += WriteToAudioCache(str);
}
}
pa_threaded_mainloop_unlock(mainLoop);
pError = error;
return cachedLen;
}六、總結
原文標題:OpenHarmony 3.2 Beta Audio——音頻渲染
文章出處:【微信公眾號:OpenAtom OpenHarmony】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
鴻蒙
+關注
關注
57文章
2392瀏覽量
43059 -
OpenHarmony
+關注
關注
25文章
3747瀏覽量
16592
原文標題:OpenHarmony 3.2 Beta Audio——音頻渲染
文章出處:【微信號:gh_e4f28cfa3159,微信公眾號:OpenAtom OpenHarmony】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
請問cc3200 audio boosterpack音頻采集是不是底噪很大?
基于TLV320AIC3254的音頻開發辦,我燒入wifi_audio_app例程(例程中關掉板載咪頭輸入,并將音量調到最大),另兩入輸入接口沒有接音頻信號,但是板子一直吱吱吱的響,是板子本身底噪就這么大嗎?
發表于 10-25 06:28
TPS6595 Audio Codec輸出音頻偶發混入7Khz雜波是怎么回事?
主芯片是DM3730, 音頻使用的是TPS65950的Audio 外設。
DM3730使用MCBSP輸出8Khz音頻數據,通過I2C設置 TPS65950相關寄存器。 采用Audio
發表于 10-15 07:08
Auracast廣播音頻創造全新音頻體驗
音頻(LE Audio)發布以來,Auracast廣播音頻在音頻市場持續發力,對音頻設備和相關產品產生了深遠影響。
【龍芯2K0300蜂鳥板試用】OpenHarmony代碼
fetch origin OpenHarmony-3.2-Release:OpenHarmony-3.2-Release
git switch OpenHarmony-3.2
發表于 09-18 11:42
LE Audio音頻技術助推影音、助聽市場,藍牙+助聽芯片成為趨勢
3.0版本支持高速數據傳輸和更低的功耗,藍牙4.0版本引入了低功耗模式(BLE),藍牙5.0版本提高了傳輸速度。再到藍牙5.2版本提出了LE Audio,增強了藍牙音頻體驗。 進入無損時代,LE Audio帶來低延遲、高音質體驗
HarmonyOS NEXT Developer Beta1中的Kit
管理服務)、Network Kit(網絡服務)等。
媒體相關Kit開放能力:Audio Kit(音頻服務)、Media Library Kit(媒體文件管理服務)等。
圖形相關Kit開放能力
發表于 06-26 10:47
使用提供的esp_audio_codec 的庫組件時,不能將AAC音頻解碼回PCM音頻,為什么?
使用提供的esp_audio_codec 的庫組件時,能夠將PCM音頻編碼為AAC音頻,但是不能將AAC音頻解碼回PCM音頻,是為什么導致的
發表于 06-05 06:39
鴻蒙開發接口媒體:【@ohos.multimedia.audio (音頻管理)】
音頻管理提供管理音頻的一些基礎能力,包括對音頻音量、音頻設備的管理,以及對音頻數據的采集和渲染等

HarmonyOS實戰開發-合理選擇條件渲染和顯隱控制
開發者可以通過條件渲染或顯隱控制兩種方式來實現組件在顯示和隱藏間的切換。本文從兩者原理機制的區別出發,對二者適用場景分別進行說明,實現相應適用場景的示例并給出性能對比數據。
原理機制
條件渲染
發表于 05-10 15:16
【RTC程序設計:實時音視頻權威指南】音頻采集與渲染
在進行視頻的采集與渲染的同時,我們還需要對音頻進行實時的采集和渲染。對于rtc來說,音頻的實時性和流暢性更加重要。
聲音是由于物體在空氣中振動而產生的壓力波,聲波的存在依賴于空氣介質,
發表于 04-28 21:00
【開源鴻蒙】下載OpenHarmony 4.1 Release源代碼
本文介紹了如何下載開源鴻蒙(OpenHarmony)操作系統 4.1 Release版本的源代碼,該方法同樣可以用于下載OpenHarmony最新開發版本(master分支)或者4.0 Release、3.2 Release等發
鴻蒙ArkUI開發學習:【渲染控制語法】
ArkUI開發框架是一套構建 HarmonyOS / OpenHarmony 應用界面的聲明式UI開發框架,它支持程序使用?`if/else`?條件渲染,?`ForEach`?循環渲染以及?`LazyForEach`?懶加載

3.2W單聲道D類音頻功率放大器TPA2037D1數據表
電子發燒友網站提供《3.2W單聲道D類音頻功率放大器TPA2037D1數據表.pdf》資料免費下載
發表于 03-20 09:17
?0次下載

【鴻蒙】OpenHarmony運行docker詳細步驟
1.環境和設備 系統版本: 3.2release(64 位) OpenHarmony 內核版本:5.10 標準系統設備: DAYU200 Docker:18.03.1 (64 位) sd 卡一張
鴻蒙開發實戰項目:錄音變聲應用
概述
本示例使用AudioCapturer提供的JS接口對音頻進行采集,并進行變聲處理。
涉及OpenHarmony技術特性
媒體
基礎信息
應用端
簡介
AudioChangeDemo是裝在
發表于 03-01 17:24





 工商網監
工商網監
評論