 一文了解多個段的相關程序
一文了解多個段的相關程序
這是 x86 匯編連載系列第七篇文章,前六篇文章見文末。
上回我們簡單認識了一下什么是段,段前綴和一段安全的段空間是哪里,但是程序中不會僅有一個段,復雜程序必然是包含多個段的,這篇文章我們就來了解下多個段的相關程序。
內存地址空間是由操作系統直接管理和分配的,一般操作系統分配空間有兩種方式:
程序由磁盤載入內存中時,會由操作系統直接為程序分配其運行所需要的內存空間。
程序在運行時可以動態向操作系統申請分配內存空間。
如果想要在程序被載入時獲得內存空間分配,我們就需要在源程序中對其進行聲明,通過定義多個段的方式來申請內存空間。這樣的好處是能夠保證段內的數據連續,而且對于我們來說也能夠清晰明白的看懂程序邏輯,所以我們一般采用定義多個段的方式編寫程序。
在代碼段 cs 中使用數據
現在考慮這樣一個問題,如何累加下面這幾個數據的和,并把它放在一個 ax 寄存器中呢?
0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
我們當然可以通過一個數據接一個數據這樣進行累加,并把每次累加的結果都用 ax 進行存儲,簡單一點的方式是通過循環的方式累加,一共需要累加 8 次數據,用 ax 存儲。但是現在就有一個問題,這 8 個數據應該放在哪呢?我們之前學的累加做法都是把他們放在一組連續的內存單元,這樣我們就可以累加內存中的數據來把它們進行累加了,但是如何把這些數據放在一個連續的內容單元中呢?這段內存單元又是從哪找呢?
我們可以不用自己找內存單元,直接讓操作系統分配,我們只需要定義這些數據并把它們放在一個連續的內存單元即可,具體該怎么做呢?請看下面代碼
assume cs:code code segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h mov ax,0 mov bx,0 mov cx,8 s: add ax,cs:[bx] add bx,2 loop s mov ax,4c00h int 21h code ends end
上面匯編代碼中出現了之前我們沒有學過的 dw,dw 的含義是定義字型數據,dw 的全稱就是 define word,上面代碼使用 dw 定義了 8 個字型數據,它們所占用的空間為 16 個字節。
定義了數據之后,我們就需要對這 8 個數據進行累加,我們該如何找到這 8 個數據呢?
仔細觀察上面代碼,我們可以知道這 8 個數據在代碼段 cs 中,所以我們可以通過 cs 來找到這幾個數據,所以 cs 是段地址,而偏移地址是用 ip 表示的,也就是說這 8 個數據的偏移地址分別是 cs:0 cs:2 cs:4 cs:6 cs:8 cs:a cs:c cs:e 。
我們將上面這段代碼編寫、編譯和鏈接后,對其 exe 文件進行 debug :

??????等下,這個 and ax,[bx+di] 是什么東西?再看下 cs:ip 的地址,是初始地址沒錯啊,為啥沒看到程序中的指令呢?我們再用 debug -u 看看
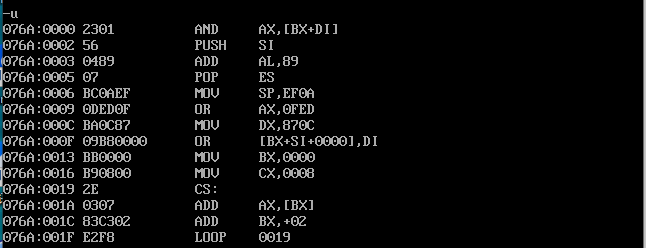
這前幾條指令都是什么東西?怎么 mov bx,0000 在偏移地址 0013 處?
從上圖中我們可以看到,程序被加載入內存之后,所占內存空間的前 16 個單元存放在源程序中用 dw 定義的數據,后面的單元存放源程序中匯編指令所對應的機器指令。
那么如何執行匯編指令所定義的機器指令呢?你可以直接 -t 慢慢的執行到 mov bx,0 處,也可以改變 ip 寄存器的值,也就是 ip = 10h,從而使 cs:ip 指向程序的第一條指令。
這兩種方式看起來哪個都有一定的局限性,那么還有沒有更簡潔一點的方式呢?
看下面這段代碼
assume cs:code code segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h start: mov ax,0 mov bx,0 mov cx,8 s: add ax,cs:[bx] add bx,2 loop s mov ax,4c00h int 21h code ends end start
仔細看這段代碼,和上面那段代碼有什么區別?
只有兩個區別,一是在 mov ax,0 前面加了一個 start: 標志,并且在 end 后加了一個 start 標志,這兩個標志分別指向程序的開始處和結束處。
那么問題來了,為什么你加一個 start: 標志就說這是程序的開始處,我隨便加個比如 begin: ,能不能成為程序的開始處呢?
assume cs:code code segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h begin: ...... code ends end begin
經過我的實驗驗證是可以的,為什么呢?
關鍵點并不在于你定義的是什么標志,而在于最后的 end,end 除了能夠告訴編譯器程序結束的位置外,還能夠告知編譯器程序是從哪里開始的,在上面代碼中我們用 start: 和 end start 告訴程序從 start 處開始,并執行到 end start 處結束,而 mov ax,0 是程序的第一條指令。
程序開始標志 start: 和 IP
我們知道,CS 和 IP 這兩個寄存器能夠指明程序的開始處和程序執行的偏移地址,而且 start: 標號指明了程序開始的地方,那么 start: 標號所指向的偏移地址是不是我們之前討論的 10h 處呢?

我們編譯鏈接執行程序看一下。
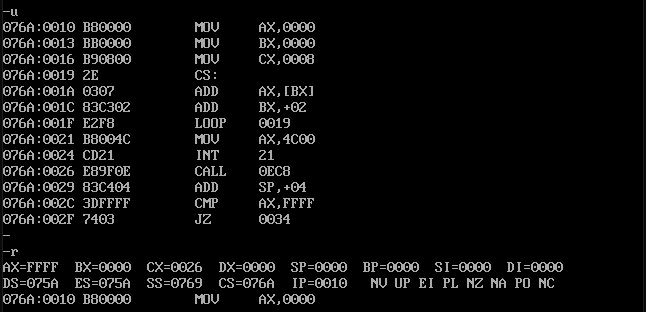
我們通過 -u 和 -r 分別執行了一下,可以看到,程序的起始地址都是 076A:0010 ,這也就是說,除了我們 dw 定義的幾條數據外,IP 指向的偏移地址 0010 就是程序的開始處。
所以有了這種方法,我們就可以這樣安排程序框架:
assume cs:code code segment ...數據 start: ... 代碼 code ends end start
在代碼段 cs 中使用棧
除了在 cs 代碼段中定義數據,還可以在 cs 代碼段中定義棧,比如下面這個需求:
利用棧將程序定義的數據逆序存放,源代碼如下
assume cs:codesg codesg segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h ...... codesg ends end
如何實現將數據逆序存放呢?可以這么思考:
先定義一段和數據相同大小的棧空間,然后把數據入棧,然后再依次出棧就能夠實現逆序存放了,因為棧是后入先出的數據結構,最開始 push 進去的最后 pop 。
代碼如下:
assume cs:codesg codesg segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 start:mov ax,cs mov ss,ax mov sp,30h mov bx,0 mov cx,8 s0:push cs:[bx] add bx,2 loop s mov bx,0 mov cx,8 s1:pop cs:[bx] add bx,2 loop s1 mov ax,4c00h int 21h codesg ends end start
解釋下上面這段代碼:
首先先定義了 16 個值為 0 的字型數據,程序被載入內存后,操作系統會為程序分配 16 個字型數據空間,用于存放 16 個數據,把這段空間當做棧來使用。
start 標號處開始程序,首先先要設置一段空間為棧段,由于我們只有一個 cs 段,所以程序是從 cs 段開始的,剛開始 dw 的 8 個數據所需的地址空間為 cs:0 ~ cs:f,后面 dw 定義的 16 個字所需的地址空間是 cs:10 ~ cs:2f ,由于 ss:sp 這兩個寄存器始終指向棧頂,目前還沒有數據入棧,所以棧頂必須為 2f + 1 ,也就是 30h 才可。
編譯鏈接執行后的棧段如下圖所示
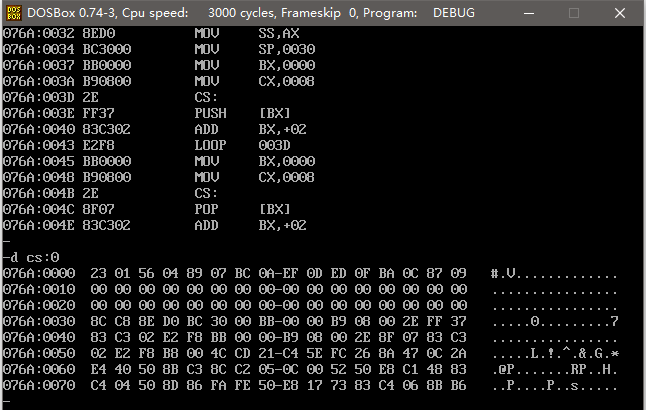
這是程序被載入后的內存分配情況,可以看到,cs:0 ~ cs:f 存儲的是 8 個字型數據,cs:10 ~ cs:2f 存儲的是 16 個字型 0 數據。
程序執行完成后的內存分配圖如下,可以看到已經實現了數據的逆序存放。
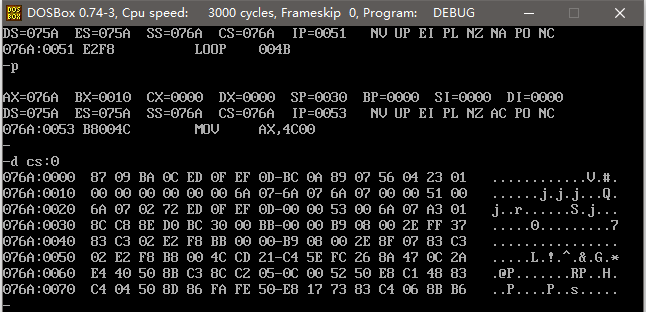
可見,我們定義這些數據的最終目的,是通過它們取得一定容量的內存空間,所以我們在描述 dw 的作用時,可以說用它來定義數據,也可以說用它來開辟一段內存空間。比如上面的 dw 0123h ... 0987h ,可以說定義了 8 個字型數據,也可以說開辟了 8 個內存空間,它們的效果是一樣的。
多個段的使用
上面討論的內容都是將數據和棧放入一個段中,這樣做雖然比較省事,但是程序邏輯不夠清晰,像個大雜燴一樣,而且都放入一個段中,這個段的內存有可能不夠用(8086 CPU 中一個段最大不能超過 64 KB)。
為了能夠清晰說明程序邏輯,并且能夠容納數據和棧,我們一般使用多個段的方式分別將數據、代碼和棧分別放入各自的段中。
比如我們通過多個段的方式將上面實現逆序存放的程序進行改寫,代碼如下
assume cs:codesg,ds:data,ss:stack data segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h data ends stack segment dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 stack ends code segment start: mov ax,stack mov ss,ax mov sp,20h mov ax,data mov ds,ax mov bx,0 mov cx,8 s0: push [bx] add bx,2 loop s0 mov bx,0 mov cx,8 s1: pop [bx] add bx,2 loop s1 mov ax,4c00h int 21h code ends end start
如上代碼所示,在 assume 后面定義了三個段,這些都是偽指令,只是為了方便說明段的類型。然后分別在 data segment 和 stack segment 定義了相關數據,最后再 code segment 編寫的程序代碼。
基本上代碼和在一個段中的定義是一樣的,值得說明是,同一個段中的 ss:sp 指向的是 ss:30 ,而在這段代碼中的 ss:sp 指向的是 ss:20 ,這個大家知道是怎么回事吧?由于數據會直接定義在 data segment 中,所以棧段的 16 個字型數據占用的空間就是 ss:0 ~ ss:1f,所以 ss:sp 指向 20h 處。
其實,代碼段、數據段、棧段完全是我們自己定義的,但是并不是我們分別定義了 cs:code,ds:data,ss,stack 之后,程序就會把它們分別當做程序段、數據段和棧段的。要知道這些和 assume 一樣都是偽指令,它們是由編譯器執行的,CPU 并不知道這些指令的存在,所以我們必須要在程序中告訴 CPU 哪個是棧段、哪個是數據段。
該如何告訴 CPU 呢?
我們看下棧段的設置指令
mov ax,stack mov ss,ax mov sp,20h
這樣就會將 ss 指向 stack ,ss:sp 用來指向 stack 棧段的棧頂地址,只有在這個指令執行后,CPU 才會把 stack 段當做棧段來使用。
相同的,CPU 如果想訪問 data 段中的數據,則可用 ds 指向 data 段,用其他寄存器比如 bx 來存放 data 段中的偏移地址即可。
所以,我們完全可以按照下面這種方式來定義程序
assume cs:a,ds:b,ss:c b segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h b ends c segment dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 c ends a segment d: mov ax,c mov ss,ax mov sp,20h mov ax,b mov ds,ax mov bx,0 mov cx,8 s0: push [bx] add bx,2 loop s0 mov bx,0 mov cx,8 s1: pop [bx] add bx,2 loop s1 mov ax,4c00h int 21h code a end d
最終程序的功能和上面的一模一樣。
-
數據
+關注
關注
8文章
7139瀏覽量
89576 -
內存
+關注
關注
8文章
3055瀏覽量
74327 -
操作系統
+關注
關注
37文章
6892瀏覽量
123742 -
程序
+關注
關注
117文章
3795瀏覽量
81406 -
代碼
+關注
關注
30文章
4825瀏覽量
69046
原文標題:多個段的程序
文章出處:【微信號:cxuangoodjob,微信公眾號:程序員cxuan】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文了解STM32啟動過程






 工商網監
工商網監
評論