 用TensorFlow2.0框架實現BP網絡
用TensorFlow2.0框架實現BP網絡
熬過了上一篇漫長的代碼,稍微解開了一丟丟疑惑,使得抽象的BP有一點具體化了,可是還是有好多細節的東西沒有講清楚,比如,為什么要用激活函數?為什么隨機梯度下降沒有提到?下面我們來一一解開疑惑。
首先是為什么要使用激活函數?這要回顧一下我們在學習BP之前學習的感知器模型。它模仿的是人類體內的信號傳導的過程,當信號達到一定的閾值時,就可以繼續向后傳播。
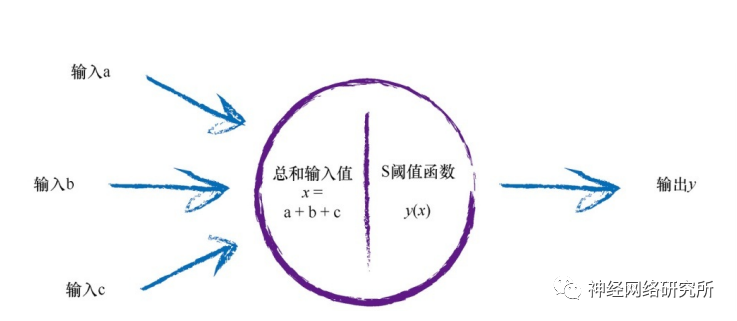
那這個感知器模型和BP網絡有什么關系呢?在我們所看到的BP網絡的結構圖中,其實是被簡化了的,下面小編畫了一個邏輯更清晰一點的圖:
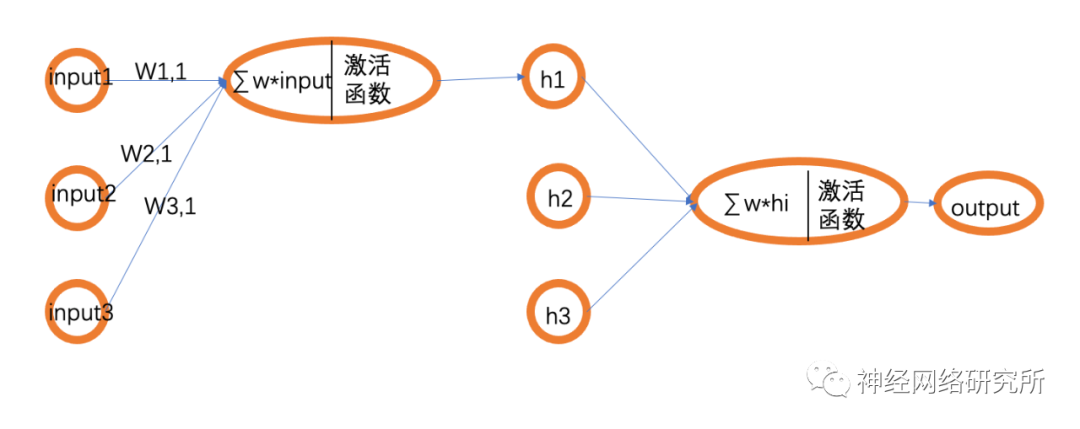
這樣我們就可以看出來,其實BP網絡是由一個一個的感知器組成,也就構成了一個真正的神經網絡,自然就能理解為什么要使用激活函數了。
接下來我們來看一下TensorFlow實現BP神經網絡到底有多簡單!
#構建一個結構為[10,15,1]的BP神經網絡
model = tf.keras.Sequential([tf.keras.layers.Dense(15,activation='relu',input_shape=(10,)),
tf.keras.layers.Dense(1)])
model.summary() #顯示網絡結構
model.compile(optimizer='SGD',loss='mse') #定義優化方法為隨機梯度下降,損失函數為mse
#x->訓練集,y——>bia標簽,epochs=10000訓練的次數,validation_data=(test_x,test_y)——>驗證集
history = model.fit(x,y,epochs=10000,validation_data=(test_x,test_y))
上面就是一個最簡單的BP網絡的網絡結構,小編還準備好了完整的通用框架代碼,不用總是修改隱藏層,可以直接使用哦!公眾號發送“BP源碼”就可以獲取!是不是非常驚訝!昨天的百行代碼完全消失了,這短短幾行代碼就可實現一個BP網絡。
這里解釋一下validation_data,這是驗證集,作用和測試集是一樣的,只不過驗證集是在訓練過程中對模型進行測試,這樣方便觀察模型的準確性。loss函數的作用是計算模型的預測誤差,也就是是衡量模型的準確度,常用的誤差函數還有mse,mae,rmse,mape等等,模型中有很多誤差函數不能直接調用,但是可以自己定義。
SGD就是我們所說的隨機梯度下降算法了,但是現在我們普遍認為“adam”是目前最好的優化算法,當然這也根據不同的神經網絡做不同的選擇。想要研究理論的讀者可以去查一查資料,小編作為實戰派就不對理論做過多的闡述了!
另外再列出來同樣強大的pytorch框架的代碼,大家可以自行選取。
class Model(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(10, 15),
nn.ReLU(),
nn.Dropout(), #防止過度擬合,TensorFlow也有
nn.Linear(15, 2)
)
def forward(self, x):
x = self.fc(x)
return x
關于選擇哪一個框架的問題,在TensorFlow2.0出現之前,小編會推薦pytorch,現在的TensorFlow2.0和pytorch代碼風格已經越來越接近了,但是TensorFlow2.0可以支持的平臺更多,所以這里推薦TensorFlow2.0。
有什么問題,歡迎大家留言討論!
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
信號
+關注
關注
11文章
2804瀏覽量
77099 -
閾值
+關注
關注
0文章
123瀏覽量
18549 -
函數
+關注
關注
3文章
4346瀏覽量
62968 -
BP網絡
+關注
關注
0文章
27瀏覽量
22068 -
tensorflow
+關注
關注
13文章
329瀏覽量
60629
發布評論請先 登錄
相關推薦
labview BP神經網絡的實現
請問:我在用labview做BP神經網絡實現故障診斷,在NI官網找到了機器學習工具包(MLT),但是里面沒有關于這部分VI的幫助文檔,對于”BP神經
發表于 02-22 16:08
深度學習框架TensorFlow&TensorFlow-GPU詳解
TensorFlow&TensorFlow-GPU:深度學習框架TensorFlow&TensorFlow-GPU的簡介、安裝、使用方法詳細
發表于 12-25 17:21
高階API構建模型和數據集使用
了TensorFlow2.0Beta版本,同pytorch一樣支持動態執行(TensorFlow2.0默認eager模式,無需啟動會話執行計算圖),同時刪除了雜亂低階API,使用高階API簡單地構建復雜神經網絡模型,本文主要分享
發表于 11-04 07:49
TensorFlow的特點和基本的操作方式
2015年11月在GitHub上開源,在2016年4月補充了分布式版本,最新版本為1.10,2018年下半年將發布Tensorflow 2.0預覽版。Tensorflow目前仍處于快速開發迭代中,不斷推出新功能和優化性能,現已成
發表于 11-23 09:56
TensorFlow實戰之深度學習框架的對比
Google近日發布了TensorFlow 1.0候選版,這第一個穩定版將是深度學習框架發展中的里程碑的一步。自TensorFlow于2015年底正式開源,距今已有一年多,這期間TensorF
發表于 11-16 11:52
?4610次閱讀

TensorFlow的框架結構解析
TensorFlow是谷歌的第二代開源的人工智能學習系統,是用來實現神經網絡的內置框架學習軟件庫。目前,TensorFlow機器學習已經成為
發表于 04-04 14:39
?7145次閱讀
機器學習框架Tensorflow 2.0的這些新設計你了解多少
總是無法被撼動。而就在即將到來的2019年,Tensorflow 2.0將正式入場,給暗流涌動的框架之爭再燃一把火。
TensorFlow2.0終于問世,Alpha版可以搶先體驗
之前開發者反饋,希望TensorFlow能夠簡化API、減少冗余并改進文檔和示例。這次2.0發布,聽取了開發者的建議,因此新版本有以下三大特點:簡單、強大、可拓展。

基于TensorFlow框架搭建卷積神經網絡的電池片缺陷識別研究
基于TensorFlow框架搭建卷積神經網絡對電池片電致發光圖像進行缺陷識別。選取公開的數據集,其中包含了電池片的不同種類缺陷。
IJCAI 2019上的一個TensorFlow2.0實操教程,117頁PPT干貨分享
如果您有興趣開始學習TensorFlow,或者學習新發布的2.0版本,那么本教程非常適合您。前提是您需要事先熟悉一些基本的機器學習知識。我們將介紹深度學習中的關鍵概念。我們的目標是幫助您高效地開始使用TensorFlow,這樣您
tensorflow能做什么_tensorflow2.0和1.0區別
等多項機器學習和深度學習領域,對2011年開發的深度學習基礎架構DistBelief進行了各方面的改進,它可在小到一部智能手機、 大到數千臺數據中心服務器的各種設備上運行。TensorFlow將完全開源,任何人都可以用。
神經網絡原理簡述—卷積Op求導
目前主流的CNN訓練框架,如pytorch、mxnet、tensorflow2.0中都已經集成了autograd的機制,自動求導的機制相較于傳統訓練框架如caffe、te...
發表于 02-07 11:29
?0次下載

卷積神經網絡的實現工具與框架
卷積神經網絡因其在圖像和視頻處理任務中的卓越性能而廣受歡迎。隨著深度學習技術的快速發展,多種實現工具和框架應運而生,為研究人員和開發者提供了強大的支持。 TensorFlow 概述





 工商網監
工商網監
評論