 怎么利用Kmeans算法實現用戶分類
怎么利用Kmeans算法實現用戶分類
一.項目背景
為了建立客戶信息資源管理及運營模式,某公司希望通過客戶的基本消費信息進行分析,
衡量客戶價值和客戶創利能力,優化客戶資源,提高營銷效率,避免不必要的資源
二.實現步驟
1.導包讀入數據,篩選所需數據
# 導入所需庫
import numpy as np
import pandas as pd
import datetime
import matplotlib.pyplot as plt
import time
import matplotlib.gridspec as gridspec
#import pyecharts
# 解決 matplotlib 顯示中文、負號問題
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
#獲取數據
def get_data(file_path):
#讀取數據
df1= pd.read_excel(file_path)
# 提取 RFM 模型所需特征列:'訂單編號','買家會員名','買家實際支付貨款','訂單付款時間','寶貝總數量'
df2 = df1[['訂單編號','買家會員名','買家實際支付金額','訂單付款時間','寶貝總數量']]
#返回數據
return df2
2.數據重復值缺失值處理
#處理數據
def process_data(df):
#判斷有沒有重復值
if df.duplicated().sum()==0:
print('無重復數據')
else:
#刪除重復值
df=df.drop_duplicates(inplace=True)
#判斷有沒有缺失值
if df.isnull().any().sum()==0:
print('無缺失值')
else:
#刪除缺失值
df=df.dropna(inplace=True)
#返回數據
return df
3.獲取RFMP各項值
#獲取R值
def get_R(df):
# 計算時間差
time_minus = datetime.datetime.now()- df['訂單付款時間']
# 將時間差轉換成數字格式
df['prior_R'] = time_minus.astype(str).str.findall('d+.*d*').map(lambda x: int(x[0]) + (int(x[1]) / 24) +
(int(x[2]) / (24 * 60)) + (float(x[3]) / (24 * 3600)))
# 按會員進行分組,確定每個會員最近一次購買離現在的時間間隔
R = df.groupby('買家會員名')['prior_R'].min()
return R
#獲取FMP值,P值表示買家購買數量
def get_F_M_P(df):
# 按會員進行分組,確定每個會員的訂單數量
F = df.groupby('買家會員名')['訂單編號'].count()
# 按會員進行分組,確定每個會員的實際支付金額
M = df.groupby('買家會員名')['買家實際支付金額'].sum()
# 按會員進行分組,確定每個會員的寶貝總數量
P = df.groupby('買家會員名')['寶貝總數量'].sum()
return (F,M,P)
#將RFMP數據合成DataFrame
def get_data(R,F,M,P):
#列名稱
col_list = list('RFMP')
#創建DataFrame
model_data = pd.DataFrame([], index=R.index)
#添加數據
for col_names, values in zip(col_list, [R, F, M, P]):
model_data[col_names] = values
#類型轉換
model_data = model_data.astype(float)
#返回數據
return model_data
4.利用Kmeans算法進行分類
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler, MinMaxScaler
#獲取數據
df0 = model_data.iloc[:, 0:4]
#標準化數據
res_std = StandardScaler().fit_transform(df0)
#分類簇數
n_clusters = range(2, 7)
#評分標準
scores = []
#遍歷每種分類
for i in range(len(n_clusters)):
#訓練模型
clf = KMeans(n_clusters = n_clusters[i], random_state = 20).fit(res_std)
#獲取評分
scores.append(silhouette_score(res_std, clf.labels_))
#獲取最大評分索引
maxindex = scores.index(max(scores))
#初始畫布
plt.figure(figsize = (8, 6), dpi = 100)
#繪制圖形
plt.plot(n_clusters, scores, linestyle = '-.', c = 'b', alpha = 0.6, marker = 'o')
#編輯最佳簇數
plt.axvline(x = n_clusters[maxindex], linestyle = '--', c = 'r', alpha = 0.5)
#設置標題
plt.title('RFMP的聚類輪廓系數圖')
#設置y軸標簽
plt.ylabel('silhouette_score')
#設置x軸標簽
plt.xlabel('n_clusters')
#存儲圖形
plt.savefig('./RFMP聚類輪廓系數圖.png')
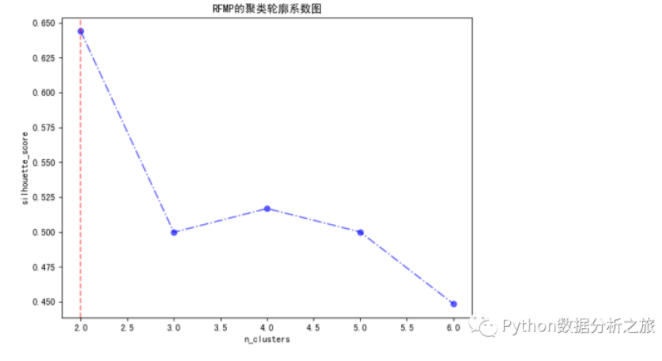
#獲取最佳分簇數模型
clf = KMeans(n_clusters = 2, random_state = 20).fit(res_std)
#添加label
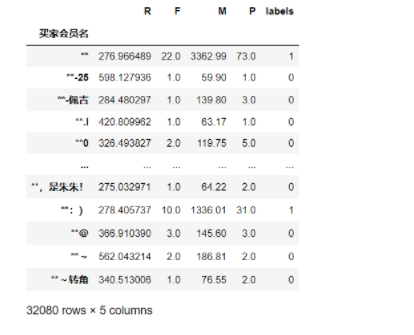
df0['labels'] = clf.labels_
df0
# 統計一下兩類用戶之間的差異,發現兩類客戶之間數量相差過大
print(f"類別0所占比例為:{df0['labels'].value_counts().values[0] / df0.shape[0]} t 類別1所占的比例為:{df0['labels'].value_counts().values[1] / df0.shape[0]}")
df0['labels'].value_counts()

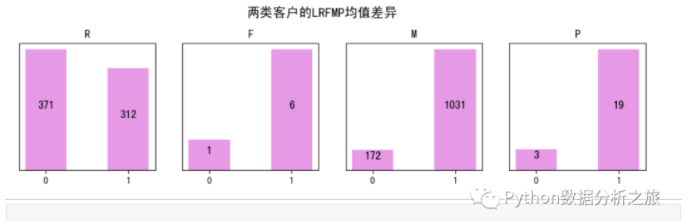
#用均值來評估兩類樣本之間的LRFMP
R_avg = df0.groupby('labels').agg({'R': np.mean}).reset_index()
F_avg = df0.groupby('labels').agg({'F': np.mean}).reset_index()
M_avg = df0.groupby('labels').agg({'M': np.mean}).reset_index()
P_avg = df0.groupby('labels').agg({'P': np.mean}).reset_index()
# 繪制相關的條形圖
def plot_bar(df_list, nrow, ncol):
#初始畫布
fig, axs = plt.subplots(nrow, ncol, figsize = (2 * (ncol + 2), 2.5), dpi = 100)
#遍歷每個坐標系
for i in range(len(axs)):
#獲取坐標系
ax = axs[i]
#獲取數據
df = df_list[i]
#畫柱狀圖
ax.bar(df.iloc[:, 0], df.iloc[:, 1], color = 'm', alpha = 0.4, width = 0.5)
#獲取RFMP標簽對應數值
for x, y in enumerate(df.iloc[:, 1].tolist()):
#標注數據
ax.text(x, y / 2, '%.0f' % y, va = 'bottom', ha = 'center', fontsize = 12)
#設置x軸刻度
ax.set_xticks([0, 1])
#設置y軸刻度
ax.set_yticks(())
#設置小標題
ax.set_title(f'{df.columns[1]}')
#設置大標題
plt.suptitle('兩類客戶的RFMP均值差異', y = 1.1, fontsize = 14)
#存儲圖片
plt.savefig('./兩類客戶LRFMP均值差異.png')
#獲取數據
df_list = [ R_avg, F_avg, M_avg, P_avg]
#繪制圖形
plot_bar(df_list, 1, 4)
總結:分為兩類用戶效果確實很明顯,但是分析還是有點一刀切,我們發現圖中四類效果也
不是很差,后期感興趣讀者可以進行四類用戶分類,在這里主要還是給大家一個思維拓展.
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
分析
+關注
關注
2文章
134瀏覽量
33349 -
模式
+關注
關注
0文章
65瀏覽量
13430 -
信息資源
+關注
關注
0文章
3瀏覽量
5936
發布評論請先 登錄
相關推薦
基于多通道分類合成的SAR圖像分類研究
。目前,SAR圖像分類多是基于單通道圖像數據。多通道SAR數據極大地豐富了地物目標信息量,利用多通道數據進行分類,是SAR圖像分類的重要發展方向。本文提出基于多通道
發表于 04-23 11:52
利用labSQL做一個用戶管理 如何實現
和pc機連接是沒問題的 我現在可以實現利用labSQL的添加刪除查詢等簡單實現現在我想實現用戶管理的功能,包括查找庫里是否存在該用戶刪除選定
發表于 09-28 15:44
labview巧用配置文件實現用戶登錄系統
;gt;在利用labview虛擬儀器時,需要制作一個登陸系統。這里總結了3種方法:1、利用固定常量數組制作登錄系統該方法實現簡單,但用戶名和密碼不能修改。這里不做詳細介紹。2、
發表于 11-27 15:49
基于用戶身份特征的多標簽分類算法
目前對于智慧校園中的家校溝通,缺乏一種衡量和參考的方法。針對智慧校園中特有的聊天特點即存在明顯的身份特征,提出了一種基于用戶身份特征的多標簽分類算法-Adaboost. ML。首先,新增加了啟發式
發表于 12-01 16:22
?0次下載
如何使用直方圖條件熵實現水聲數據分類的算法
,對水聲數據直方圖進行分段,使用條件熵判別式分別計算出每一個分段直方圖的最佳特征閾值,賦予其相應的不透明度傳遞函數,以實現對水聲數據的分類。實驗結果表明,該算法能夠較好地實現水聲數據的
發表于 01-20 10:18
?22次下載

愛立信性能優化器實現用戶體驗最優化
作為愛立信認知軟件產品組合的一部分,“愛立信性能優化器(Ericsson Performance Optimizers)”采用了數字孿生技術,以及深度強化學習等先進AI技術,充分利用網絡優化技術的自動化、可擴展性、速度、精度和一致性,同時實現用戶體驗最優化與運營商效益最大






 工商網監
工商網監
評論