") ChatGPT炒熱GPU,ASIC和FPGA能否分一杯羹?
ChatGPT炒熱GPU,ASIC和FPGA能否分一杯羹?
電子發(fā)燒友網(wǎng)報(bào)道(文/周凱揚(yáng))ChatGPT的出現(xiàn),對于數(shù)據(jù)中心硬件市場無疑是一針強(qiáng)心劑,不少GPU廠商更是從中受益,從再度興起的聊天機(jī)器人潮流中收獲了更多訂單。那么對于ChatGPT這類對AI算力有著不小需求的應(yīng)用來說,ASIC和FPGA是否也能借上這股東風(fēng)呢?
不同硬件的成本對比
在機(jī)器學(xué)習(xí)推理場景中,除了GPU外,還有一大通用AI硬件適合這一負(fù)載,那就是FPGA。與GPU一樣,在技術(shù)和算法還未成熟且仍在打磨階段時(shí),可以隨時(shí)重新編程改變芯片功能的FPGA架構(gòu)前期硬件成本顯著低于GPU。在推理性能上,現(xiàn)如今的FPGA加速卡算力遠(yuǎn)超CPU,甚至高過不少GPU產(chǎn)品。
而且在ChatGPT這樣的聊天機(jī)器人應(yīng)用上,將FPGA用于推理得以發(fā)揮其最大的優(yōu)勢,那就是高吞吐量和低時(shí)延。更高的吞吐量和更低的時(shí)延也就意味著更大的并發(fā),對ChatGPT這種應(yīng)用來說可以極大增強(qiáng)其響應(yīng)速度。 但隨著算法和模型逐漸成熟,F(xiàn)PGA在成本上的優(yōu)勢就慢慢不存在了,在大語言模型上需要用到更多的硬件,而FPGA量產(chǎn)規(guī)模的單價(jià)成本還是太高了,一旦擴(kuò)充至成千上萬張加速卡,其成本也是不小的。比如AMD推出的新加速卡Alveo V70,據(jù)傳單卡價(jià)格就在2000美元左右。如果我們以INT8精度來衡量算力的話,假設(shè)ChatGPT需要28936塊A100 GPU,那么改用Alveo V70的話,也需要44693塊加速卡。
所以還是有不少人將目光投向了量產(chǎn)規(guī)模成本更低的ASIC,比如谷歌就選擇用自研的TPU來部署其聊天機(jī)器人Bard。ASIC方案在單芯片算力上或許不是最高的,但計(jì)算效率卻是最高的,而且隨著量產(chǎn)化單片成本會逐漸降低。比如谷歌的單個(gè)TPU v4 Pod就集成了4096個(gè)TPU v4芯片,單芯片的BF16算力達(dá)到275TFLOPS,已經(jīng)相當(dāng)接近A100單卡峰值算力了。如果只是這樣簡單換算的話,只需幾個(gè)TPU v4 Pod,就能滿足與ChatGPT同量級的應(yīng)用了。
不過ASIC方案并沒有我們想象得那么美好,首先這類硬件的前期設(shè)計(jì)成本較大,要想投入數(shù)據(jù)中心商用,必須組建強(qiáng)大的硬件設(shè)計(jì)和軟件開發(fā)團(tuán)隊(duì),這樣才能有與GPU相抗衡的性能。其次,因?yàn)楸旧韺S糜布奶匦裕瑢S糜跈C(jī)器學(xué)習(xí)推理的ASIC方案很難最大化數(shù)據(jù)中心的硬件利用率,不像GPU還可以同時(shí)用于訓(xùn)練、視頻編解碼等等。
搭建屬于自己的ChatGPT的成本有多高
對于GPT-3這樣的大型模型來說,要想個(gè)人搭建和部署從成本上看肯定不是實(shí)惠的選擇,所以我們可以選擇其他的模型,比如Meta推出的1750億參數(shù)OPT-175B模型。加州大學(xué)伯克利分校的Sky Lab就借助該模型推出了一個(gè)開源系統(tǒng)Alpa,同時(shí)具備聊天機(jī)器人、翻譯、代碼編寫和數(shù)學(xué)計(jì)算的功能。
要想部署OPT-175B模型并搭建Alpa這樣的文字聊天應(yīng)用,對GPU的要求要遠(yuǎn)遠(yuǎn)小于ChatGPT。但這是建立在其本身響應(yīng)速度和功能特性就顯著弱于ChatGPT的情況下,比如一旦設(shè)定的回答長度過長,就需要等上數(shù)十秒,何況它列出的GPU需求也不算小。
根據(jù)Alpa的官方說明,雖然不需要用到最新一代的A100 80GB這樣價(jià)格高昂的GPU或是InfiniBand這樣先進(jìn)的互聯(lián)方案,但對顯存的最低要求也已經(jīng)達(dá)到了350GB。所以Alpa給的建議是使用32個(gè)英偉達(dá)Tesla V100 GPU,從而提供512GB的顯存,這樣硬件造價(jià)在50萬到150萬之間。

Tesla V100 GPU / 英偉達(dá)
如果你只是想開展聊天機(jī)器人的服務(wù),而不是自己買硬件的話,也可以選擇各大公有云服務(wù)廠商的方案,比如亞馬遜AWS的EC2 P3系列,就是專為機(jī)器學(xué)習(xí)和HPC準(zhǔn)備的實(shí)例。每個(gè)EC2 P3.16xlarge實(shí)例上有8塊Tesla V100 GPU,所以至少租賃4個(gè)實(shí)例就能運(yùn)行Alpa了。
不過這樣一來服務(wù)器的費(fèi)用也并不算便宜,單個(gè)實(shí)例按需付費(fèi)每小時(shí)的花費(fèi)在24.48美元左右,也就是說如果要全天運(yùn)行的話,運(yùn)行Alpa的成本為2400美元一天。哪怕云服務(wù)廠商通常都會給到長期承諾使用的折扣,這也是一筆不小的支出。
谷歌推出的Cloud TPU方案也是如此,如果真的打算以租賃服務(wù)器的方式來打造ChatGPT,那么谷歌目前給出的按需定價(jià)是每芯片小時(shí)價(jià)格3.22美元。要想部署數(shù)萬規(guī)模的TPU v4芯片媲美ChatGPT,那么一定逃不掉超高的費(fèi)用。
結(jié)語
不久前我們已經(jīng)提到了ChatGPT的加入或許會給微軟的現(xiàn)有產(chǎn)品帶來定價(jià)的提升,如今這個(gè)猜測也已經(jīng)成真。微軟近日宣布,從今年5月1日開始,微軟Bing搜索API的定價(jià)將會直線飆升,其中超大并發(fā)(每秒250次處理)的S1實(shí)例定價(jià)從每千次處理7美元提升至25美元,而額外的Bing統(tǒng)計(jì)更是從每千次處理1美元的價(jià)格拔高至10美元。如此看來,可見大語言模型的推理成本有多高可見一斑了,哪怕是微軟也經(jīng)不起這樣燒錢。
所以對于ChatGPT這種應(yīng)用,其運(yùn)營者不同,對待硬件成本的看法也會不同,比如微軟、谷歌之類已經(jīng)擁有大規(guī)模服務(wù)器硬件的廠商,必然會利用現(xiàn)有GPU資源的同時(shí),考慮如何用定制化的ASIC進(jìn)一步節(jié)省成本。而體量較小的運(yùn)營者,例如聊天機(jī)器人應(yīng)用開發(fā)商、研究機(jī)構(gòu)等,還是會選擇租賃服務(wù)器或小規(guī)模本地部署,其首選硬件也會是GPU。
再說回FPGA,雖然從目前數(shù)據(jù)中心的市場現(xiàn)狀來看,F(xiàn)PGA的AI推理加速卡仍處于一個(gè)弱勢的位置。但隨著AMD開始推出Alveo V70這樣全新XDNA架構(gòu)的方案,或許能給未來需要更大吞吐量的模型提供新的出路,尤其是視頻分析推理應(yīng)用。
不同硬件的成本對比
在機(jī)器學(xué)習(xí)推理場景中,除了GPU外,還有一大通用AI硬件適合這一負(fù)載,那就是FPGA。與GPU一樣,在技術(shù)和算法還未成熟且仍在打磨階段時(shí),可以隨時(shí)重新編程改變芯片功能的FPGA架構(gòu)前期硬件成本顯著低于GPU。在推理性能上,現(xiàn)如今的FPGA加速卡算力遠(yuǎn)超CPU,甚至高過不少GPU產(chǎn)品。
而且在ChatGPT這樣的聊天機(jī)器人應(yīng)用上,將FPGA用于推理得以發(fā)揮其最大的優(yōu)勢,那就是高吞吐量和低時(shí)延。更高的吞吐量和更低的時(shí)延也就意味著更大的并發(fā),對ChatGPT這種應(yīng)用來說可以極大增強(qiáng)其響應(yīng)速度。 但隨著算法和模型逐漸成熟,F(xiàn)PGA在成本上的優(yōu)勢就慢慢不存在了,在大語言模型上需要用到更多的硬件,而FPGA量產(chǎn)規(guī)模的單價(jià)成本還是太高了,一旦擴(kuò)充至成千上萬張加速卡,其成本也是不小的。比如AMD推出的新加速卡Alveo V70,據(jù)傳單卡價(jià)格就在2000美元左右。如果我們以INT8精度來衡量算力的話,假設(shè)ChatGPT需要28936塊A100 GPU,那么改用Alveo V70的話,也需要44693塊加速卡。

所以還是有不少人將目光投向了量產(chǎn)規(guī)模成本更低的ASIC,比如谷歌就選擇用自研的TPU來部署其聊天機(jī)器人Bard。ASIC方案在單芯片算力上或許不是最高的,但計(jì)算效率卻是最高的,而且隨著量產(chǎn)化單片成本會逐漸降低。比如谷歌的單個(gè)TPU v4 Pod就集成了4096個(gè)TPU v4芯片,單芯片的BF16算力達(dá)到275TFLOPS,已經(jīng)相當(dāng)接近A100單卡峰值算力了。如果只是這樣簡單換算的話,只需幾個(gè)TPU v4 Pod,就能滿足與ChatGPT同量級的應(yīng)用了。
不過ASIC方案并沒有我們想象得那么美好,首先這類硬件的前期設(shè)計(jì)成本較大,要想投入數(shù)據(jù)中心商用,必須組建強(qiáng)大的硬件設(shè)計(jì)和軟件開發(fā)團(tuán)隊(duì),這樣才能有與GPU相抗衡的性能。其次,因?yàn)楸旧韺S糜布奶匦裕瑢S糜跈C(jī)器學(xué)習(xí)推理的ASIC方案很難最大化數(shù)據(jù)中心的硬件利用率,不像GPU還可以同時(shí)用于訓(xùn)練、視頻編解碼等等。
搭建屬于自己的ChatGPT的成本有多高
對于GPT-3這樣的大型模型來說,要想個(gè)人搭建和部署從成本上看肯定不是實(shí)惠的選擇,所以我們可以選擇其他的模型,比如Meta推出的1750億參數(shù)OPT-175B模型。加州大學(xué)伯克利分校的Sky Lab就借助該模型推出了一個(gè)開源系統(tǒng)Alpa,同時(shí)具備聊天機(jī)器人、翻譯、代碼編寫和數(shù)學(xué)計(jì)算的功能。
要想部署OPT-175B模型并搭建Alpa這樣的文字聊天應(yīng)用,對GPU的要求要遠(yuǎn)遠(yuǎn)小于ChatGPT。但這是建立在其本身響應(yīng)速度和功能特性就顯著弱于ChatGPT的情況下,比如一旦設(shè)定的回答長度過長,就需要等上數(shù)十秒,何況它列出的GPU需求也不算小。
根據(jù)Alpa的官方說明,雖然不需要用到最新一代的A100 80GB這樣價(jià)格高昂的GPU或是InfiniBand這樣先進(jìn)的互聯(lián)方案,但對顯存的最低要求也已經(jīng)達(dá)到了350GB。所以Alpa給的建議是使用32個(gè)英偉達(dá)Tesla V100 GPU,從而提供512GB的顯存,這樣硬件造價(jià)在50萬到150萬之間。
Tesla V100 GPU / 英偉達(dá)
不過這樣一來服務(wù)器的費(fèi)用也并不算便宜,單個(gè)實(shí)例按需付費(fèi)每小時(shí)的花費(fèi)在24.48美元左右,也就是說如果要全天運(yùn)行的話,運(yùn)行Alpa的成本為2400美元一天。哪怕云服務(wù)廠商通常都會給到長期承諾使用的折扣,這也是一筆不小的支出。
谷歌推出的Cloud TPU方案也是如此,如果真的打算以租賃服務(wù)器的方式來打造ChatGPT,那么谷歌目前給出的按需定價(jià)是每芯片小時(shí)價(jià)格3.22美元。要想部署數(shù)萬規(guī)模的TPU v4芯片媲美ChatGPT,那么一定逃不掉超高的費(fèi)用。
結(jié)語
不久前我們已經(jīng)提到了ChatGPT的加入或許會給微軟的現(xiàn)有產(chǎn)品帶來定價(jià)的提升,如今這個(gè)猜測也已經(jīng)成真。微軟近日宣布,從今年5月1日開始,微軟Bing搜索API的定價(jià)將會直線飆升,其中超大并發(fā)(每秒250次處理)的S1實(shí)例定價(jià)從每千次處理7美元提升至25美元,而額外的Bing統(tǒng)計(jì)更是從每千次處理1美元的價(jià)格拔高至10美元。如此看來,可見大語言模型的推理成本有多高可見一斑了,哪怕是微軟也經(jīng)不起這樣燒錢。
所以對于ChatGPT這種應(yīng)用,其運(yùn)營者不同,對待硬件成本的看法也會不同,比如微軟、谷歌之類已經(jīng)擁有大規(guī)模服務(wù)器硬件的廠商,必然會利用現(xiàn)有GPU資源的同時(shí),考慮如何用定制化的ASIC進(jìn)一步節(jié)省成本。而體量較小的運(yùn)營者,例如聊天機(jī)器人應(yīng)用開發(fā)商、研究機(jī)構(gòu)等,還是會選擇租賃服務(wù)器或小規(guī)模本地部署,其首選硬件也會是GPU。
再說回FPGA,雖然從目前數(shù)據(jù)中心的市場現(xiàn)狀來看,F(xiàn)PGA的AI推理加速卡仍處于一個(gè)弱勢的位置。但隨著AMD開始推出Alveo V70這樣全新XDNA架構(gòu)的方案,或許能給未來需要更大吞吐量的模型提供新的出路,尤其是視頻分析推理應(yīng)用。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報(bào)投訴
發(fā)布評論請先 登錄
相關(guān)推薦
ASIC和GPU的原理和優(yōu)勢
芯片”。 準(zhǔn)確來說,除了它倆,計(jì)算芯片還包括大家更熟悉的CPU,以及FPGA。 行業(yè)里,通常會把半導(dǎo)體芯片分為數(shù)字芯片和模擬芯片。其中,數(shù)字芯片的市場規(guī)模占比較大,達(dá)到70%左右。 數(shù)字芯片,還可以進(jìn)一步細(xì)分,分為:邏輯芯片、存儲芯片以及微控制單元(MCU)。CPU、
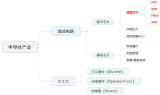
FPGA與ASIC的區(qū)別 FPGA性能優(yōu)化技巧
FPGA與ASIC的區(qū)別 FPGA(現(xiàn)場可編程門陣列)和ASIC(專用集成電路)是兩種不同的集成電路技術(shù),它們在多個(gè)方面存在顯著的區(qū)別: FPGA
ASIC集成電路與FPGA的區(qū)別
ASIC(專用集成電路)與FPGA(現(xiàn)場可編程門陣列)是兩種不同的集成電路技術(shù),它們在多個(gè)方面存在顯著的區(qū)別。以下是兩者的主要差異: 一、設(shè)計(jì)與制造 ASIC 是為特定應(yīng)用定制設(shè)計(jì)的集
電源IC U6203DC概述和特點(diǎn)
久坐生活方式已經(jīng)成為了當(dāng)今社會的一大公共衛(wèi)生問題,都市白領(lǐng)、司機(jī)、開車一族、學(xué)生等,長期坐著的人群,都面臨腰肌勞損問題,所以腰部按摩儀市場正活躍。想要在腰部按摩儀市場分一杯羹的小伙伴,不妨先鎖定專注按摩儀充電器電源ic的廠家——
FPGA和ASIC在大模型推理加速中的應(yīng)用
隨著現(xiàn)在AI的快速發(fā)展,使用FPGA和ASIC進(jìn)行推理加速的研究也越來越多,從目前的市場來說,有些公司已經(jīng)有了專門做推理的ASIC,像Groq的LPU,專門針對大語言模型的推理做了優(yōu)化,因此相比

FPGA與ASIC的優(yōu)缺點(diǎn)比較
FPGA(現(xiàn)場可編程門陣列)與ASIC(專用集成電路)是兩種不同的硬件實(shí)現(xiàn)方式,各自具有獨(dú)特的優(yōu)缺點(diǎn)。以下是對兩者優(yōu)缺點(diǎn)的比較: FPGA的優(yōu)點(diǎn) 可編程性強(qiáng) :FPGA具有高度的可編程
到底什么是ASIC和FPGA?
上一篇文章,小棗君給大家介紹了CPU和GPU。今天,我繼續(xù)介紹計(jì)算芯片領(lǐng)域的另外兩位主角——ASIC和FPGA。█ASIC(專用集成電路)上

在FPGA設(shè)計(jì)中是否可以應(yīng)用ChatGPT生成想要的程序呢
當(dāng)下AI人工智能崛起,很多開發(fā)領(lǐng)域都可看到ChatGPT的身影,FPGA設(shè)計(jì)中,是否也可以用ChatGPT輔助設(shè)計(jì)呢?
發(fā)表于 03-28 23:41
fpga與asic在概念上有什么區(qū)別
FPGA(現(xiàn)場可編程門陣列)和ASIC(應(yīng)用特定集成電路)在概念上存在明顯的區(qū)別。
fpga和asic的區(qū)別
FPGA(現(xiàn)場可編程門陣列)和ASIC(專用集成電路)是兩種不同類型的集成電路,它們在設(shè)計(jì)靈活性、制造成本、應(yīng)用領(lǐng)域等方面有著顯著的區(qū)別。
FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈?b class='flag-5'>GPU
現(xiàn)場可編程門陣列 (FPGA) 解決了 GPU 在運(yùn)行深度學(xué)習(xí)模型時(shí)面臨的許多問題
在過去的十年里,人工智能的再一次興起使顯卡行業(yè)受益匪淺。英偉達(dá) (Nvidia) 和 AMD 等公司的股價(jià)也大幅
發(fā)表于 03-21 15:19
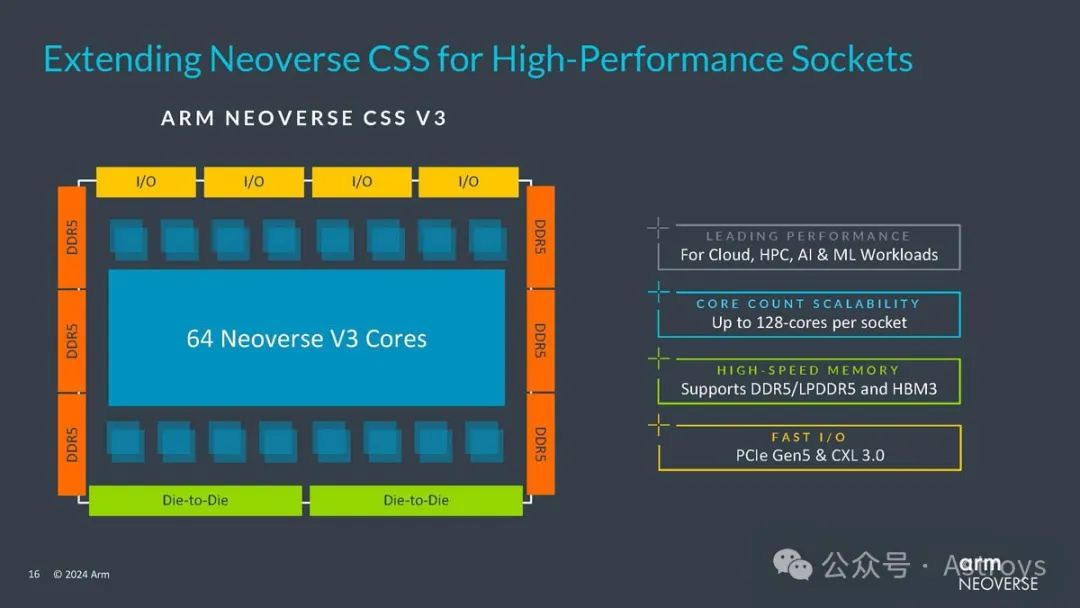
Arm通過Neoverse更新加倍發(fā)力AI和Chiplet
AI市場被視為頂級經(jīng)濟(jì)增長驅(qū)動力,每個(gè)人都想分得一杯羹。
【國產(chǎn)FPGA+OMAPL138開發(fā)板體驗(yàn)】(原創(chuàng))6.FPGA連接ChatGPT 4
的復(fù)雜系統(tǒng),然后將其映射到FPGA上運(yùn)行。FPGA通常與CPU、GPU等并行處理單元一起工作,通過網(wǎng)絡(luò)接口與后端服務(wù)器通信。然而,如果編寫一
發(fā)表于 02-14 21:58





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論