") 利用視覺+語言數(shù)據(jù)增強視覺特征
利用視覺+語言數(shù)據(jù)增強視覺特征
研究動機
傳統(tǒng)的多模態(tài)預訓練方法通常需要"大數(shù)據(jù)"+"大模型"的組合來同時學習視覺+語言的聯(lián)合特征。但是關注如何利用視覺+語言數(shù)據(jù)提升視覺任務(多模態(tài)->單模態(tài))上性能的工作并不多。本文旨在針對上述問題提出一種簡單高效的方法。
在這篇文章中,以醫(yī)療影像上的特征學習為例,我們提出對圖像+文本同時進行掩碼建模(即Masked Record Modeling,Record={Image,Text})可以更好地學習視覺特征。該方法具有以下優(yōu)點:
簡單。僅通過特征相加就可以實現(xiàn)多模態(tài)信息的融合。此處亦可進一步挖掘,比如引入更高效的融合策略或者擴展到其它領域。
高效。在近30w的數(shù)據(jù)集上,在4張NVIDIA 3080Ti上完成預訓練僅需要1天半左右的時間。
性能強。在微調階段,在特定數(shù)據(jù)集上,使用1%的標記數(shù)據(jù)可以接近100%標記數(shù)據(jù)的性能。
方法(一句話總結)
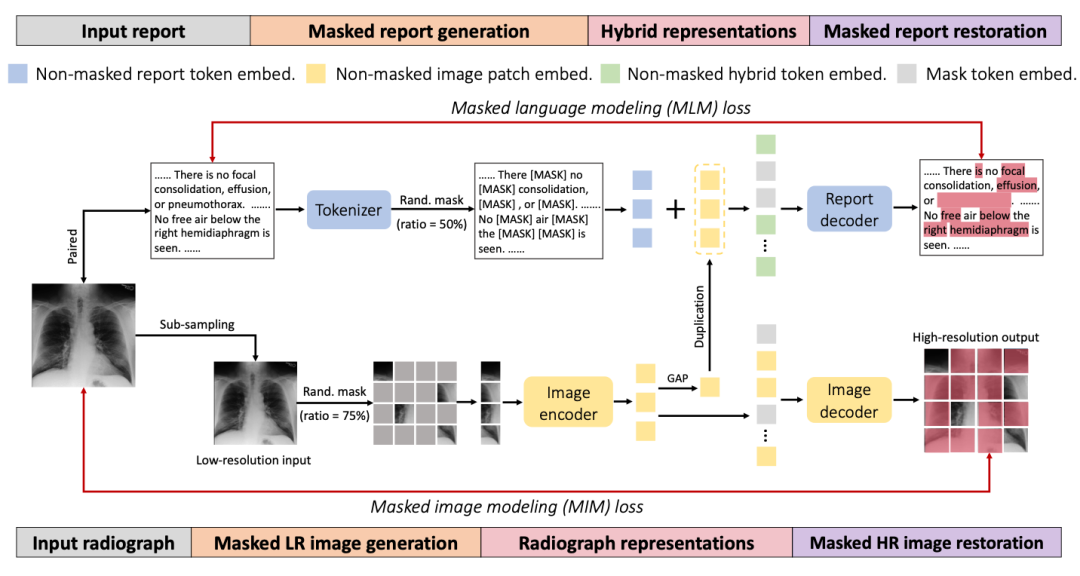
如上圖所示,我們提出的訓練策略是比較直觀的,主要包含三步:
隨機Mask一部分輸入的圖像和文本
使用加法融合過后的圖像+文本的特征重建文本
使用圖像的特征重建圖像。
性能
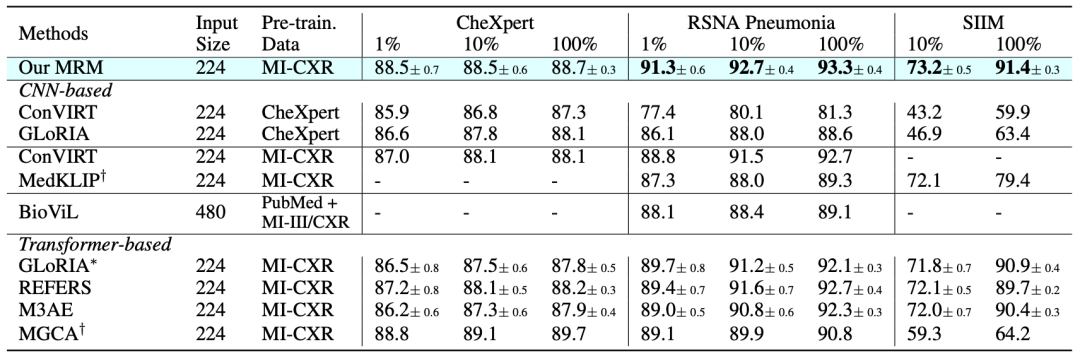
如上圖所示,我們全面對比了現(xiàn)有的相關方法和模型在各類微調任務上的性能。
在CheXpert上,我們以1%的有標記數(shù)據(jù)接近使用100%有標記數(shù)據(jù)的性能。
在RSNA Pneumonia和SIIM (分割)上,我們以較大幅度超過了之前最先進的方法。
審核編輯 :李倩
-
建模
+關注
關注
1文章
313瀏覽量
60853 -
數(shù)據(jù)集
+關注
關注
4文章
1209瀏覽量
24830 -
大數(shù)據(jù)
+關注
關注
64文章
8908瀏覽量
137786
原文標題:ICLR 2023 | 廈大&港大提出MRM:利用視覺+語言數(shù)據(jù)增強視覺特征
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
NaVILA:加州大學與英偉達聯(lián)合發(fā)布新型視覺語言模型
基于視覺語言模型的導航框架VLMnav
使用語義線索增強局部特征匹配

圖像采集卡:增強視覺數(shù)據(jù)采集

視覺檢測是什么意思?機器視覺檢測的適用行業(yè)及場景有哪些?
什么是機器視覺opencv?它有哪些優(yōu)勢?
機器視覺和計算機視覺有什么區(qū)別
機器視覺的應用實例解析
機器人視覺與計算機視覺的區(qū)別與聯(lián)系
計算機視覺和機器視覺區(qū)別在哪
機器視覺的應用流程是如何實現(xiàn)的
機器視覺控制的優(yōu)缺點有哪些
TDES9640增強視覺解串器數(shù)據(jù)表

什么是工業(yè)機器視覺?它有哪些作用?
視覺檢測設備的分類






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論