 深度學習背景下的圖像三維重建技術進展綜述
深度學習背景下的圖像三維重建技術進展綜述
三維重建是指從單張二維圖像或多張二維圖像中重建出物體的三維模型,并對三維模型進行紋理映射的過程。三維重建可獲取從任意視角觀測并具有色彩紋理的三維模型,是計算機視覺領域的一個重要研究方向。傳統的三維重建方法通常需要輸入大量圖像,并進行相機參數估計、密集點云重建、表面重建和紋理映射等多個步驟。近年來,深度學習背景下的圖像三維重建受到了廣泛關注,并表現出了優越的性能和發展前景。
本文對深度學習背景下的圖像三維重建的技術方法、評測方法和數據集進行了全面的綜述。首先對三維重建進行分類,根據三維模型的表示形式可將圖像三維重建方法分類為基于體素的三維重建、基于點云的三維重建和基于網格的三維重建,由輸入圖像的類型可將圖像三維重建分類為單張圖像三維重建和多張圖像三維重建,隨后介紹了不同類別的三維重建方法,從三維重建方法的輸入、三維模型表示形式、模型紋理顏色、重建網絡的基準值類型和特點等方面進行了總結,描述了深度學習背景下的圖像三維重建方法的常用數據集和實驗對比,最后總結了當前圖像三維重建領域的待解決的問題以及未來的研究方向。
00 引言
三維重建的目標是從單張二維圖像或多張二維圖像中重建出物體和場景的三維模型,并對三維模型進行紋理映射。三維重建是計算機視覺領域的一個重要研究方向,利用計算機重建出物體的三維模型,已經成為眾多領域進行深入研究前不可或缺的一部分。在醫療領域中,利用三維模型診斷身體狀況;在歷史文化領域中,將文物進行立體重建,供科學研究及游客參觀。除此之外,在游戲開發、工業設計、航天航海等領域,三維重建技術具有重要的應用前景。
目前,研究人員主要利用三類方法來重建三維模型:
一是直接操作的人工幾何建模技術;
二是利用三維掃描設備對目標進行掃描,然后重建目標的三維模型;
三是圖像三維重建,采集單張或多張的圖像,運用計算機視覺技術來重建三維模型。
在上述三種方法中,圖像三維重建成本低、操作簡單,可以對不規則的自然或人工合成物體進行建模,重建真實物體的三維模型。
傳統的圖像三維重建是從多視圖幾何(Andrew等, 2001)的角度進行處理,從幾何上理解和分析從三維到二維的投影過程,設計從二維到三維的逆問題解決方案進行三維重建。傳統的三維重建通常需要大量已知相機參數的圖像,并進行相機參數估計、密集點云重建和表面重建等多個步驟。隨著卷積神經網絡(CNN)的發展,深度學習廣泛應用于計算機視覺中的各種領域,基于深度學習的技術方法利用先驗知識來解決各種復雜問題。人們通常能夠對物體和場景建立豐富的先驗知識,便于從單一視角重建物體的立體模型,推斷物體的大小和其他視角的形狀。
深度學習背景下的圖像三維重建方法利用大量數據建立先驗知識,將三維重建轉變為編碼與解碼問題,從而對物體進行三維重建。隨著三維數據集的數量不斷增加,計算機的計算能力不斷提升,深度學習背景下的圖像三維重建方法能夠在無需復雜的相機校準的情況下從單張或多張二維圖像中重建物體的三維模型。
三維模型的表示形式有三種:體素模型、網格模型和點云模型。體素是三維空間中的正方體,相當于三維空間中的像素;網格是由多個三角形組成的多面體結構,可以表示復雜物體的表面形狀;點云是坐標系中的點的集合,包含了三維坐標、顏色、分類值等信息。三維模型的表示形式如圖1所示。
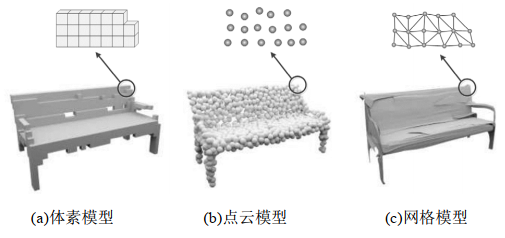
圖 1 三維模型的表示形式
根據三維模型的表示形式可以將圖像三維重建方法分類為基于體素的三維重建、基于點云的三維重建和基于網格的三維重建,其中基于網格的三維重建方法包含單一顏色的網格三維重建和具有色彩紋理的網格三維重建,由輸入圖像的類型可將圖像三維重建分類為單張圖像三維重建和多張圖像三維重建。圖像三維重建方法分類如圖2所示。
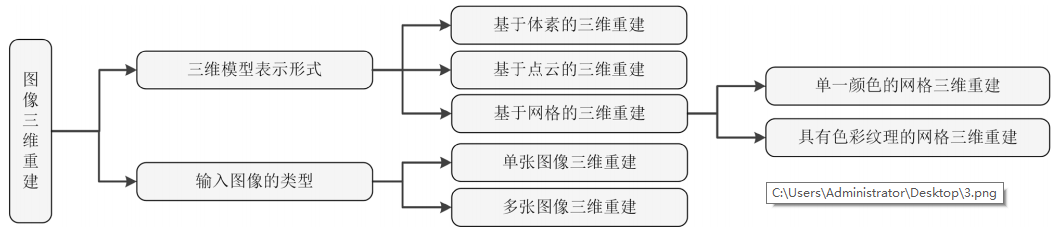
圖2 圖像三維重建方法的分類
典型的三維重建算法時間順序概述如圖3所示。
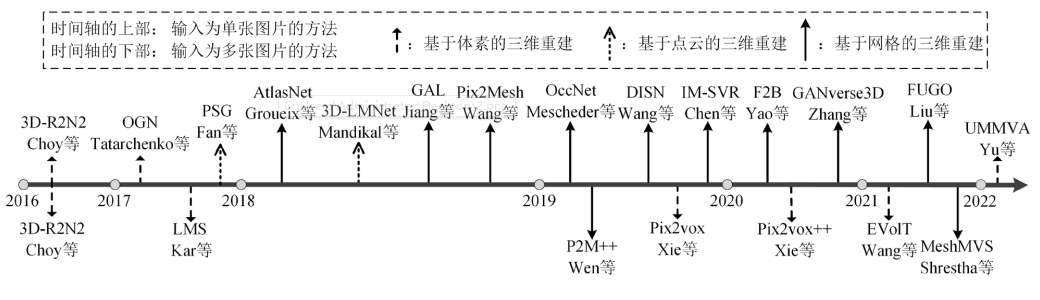
圖3 典型的三維重建算法按時間順序的概述
盡管目前已有一些三維重建相關綜述文獻(鄭太雄等,2020;吳博劍等,2020;龍霄瀟等,2021),但已有的綜述文獻主要介紹傳統方法或特殊物體的三維重建,介紹深度學習背景下的圖像三維重建技術的文獻相對偏少。本文立足于三維重建領域,對圖像三維重建研究進行分析總結,從輸入圖像類型的角度分別對單張圖像三維重建和多張圖像三維重建進行了介紹,并對三維重建的評測方法、數據集、實驗對比方法以及三維重建領域的問題與未來研究方向進行了總結。
01 單張圖像三維重建
單張圖像三維重建使用卷積神經網絡,從大量的訓練數據中學習圖像中的特征來重建物體的三維模型。在的單張圖像三維重建方法中,早期的方法通常使用端到端網絡得到體素模型或點云模型形式表示的三維模型,另外一些方法首先獲取深度圖、點云或隱式函數,得到三維模型的中間表示,隨后再將三維模型的中間表示轉化為網格模型。
1.1 基于體素的單張圖像三維重建
基于體素模型的方法法使用體素模型對三維形狀進行表示,體素模型是在深度學習背景下的圖像三維重建技術最早應用的一種表示方法。通過使用體素模型,在圖像分析中使用的二維卷積可以很容易地擴展到三維。基于體素的單張圖像三維重建通常利用編碼器解碼器結構的網絡重建三維模型。
2016年,Choy等人(2016)在長短期記憶網絡(LSTM)基礎上設計了三維(3D)LSTM網絡處理單張圖像的編碼信息,網絡由三部分組成:CNN、3D-LSTM和3D-CNN,CNN將圖像編碼為低維特征,并送入3D-LSTM更新潛在編碼,最后利用3D-CNN解碼,使用體素交叉熵的和作為損失函數訓練網絡,重建體素模型,實現了從單張圖像端到端重建三維模型。Yang等人(2019)利用生成對抗網絡(GAN)(Goodfellow等, 2014)對體素模型重建網絡進行改進,但需要同時輸入深度圖,增大了獲取輸入信息的難度。對于輸入為單張圖像的體素重建網絡,可以從編碼器、解碼器和損失函數等方面進行優化改進。Liu等人(2018)使用三維卷積神經網絡進行編碼,將三維卷積代替解碼器中的二維卷積,可以適應三維模型,將學習到的潛在特征解碼為三維占用概率從而重建體素模型。Tulsiani等人(2017; 2018)使用多視角二維圖像和相應的掩膜圖像作為基準使用視圖一致性損失訓練網絡,減小了數據獲取的難度,利用單張圖像來預測體素占用概率并重建物體的體素模型。
為了提升體素分辨率,一些方法用八叉樹來表示體素空間,八叉樹是具有自適應單元大小的三維結構,在傳統的深度圖融合方式的三維重建等方面有著廣泛的應用,與常規體素網格相比,減少了內存的消耗。在體素上定義的函數可以轉換為在八分樹上定義的函數,首先以八個子空間代表整個空間,隨后遞歸地劃分每個空間為八個子空間,直至達到最大樹深度。Tatarchenko等人(2017)使用3DCNN輸出特征圖,特征圖解碼為八叉樹,然后低分辨率結構逐漸細化到高分辨率。Wang等人(2018)等從八叉樹的不同葉節點進行計算,將節點標記為空狀態、準確狀態和不準確狀態,結合八叉樹結構交叉熵和葉節點平面參數差作為損失函數生成八叉樹,最終根據八叉樹結構重建體素模型。Yu等人(2022)利用潛在空間中的特定類別的多模態先驗分布訓練變分自編碼器,利用潛在空間的子集就可以找到先驗分布的目標模態,獲取類別的先驗信息,隨后將先驗信息和圖像特征共同送入解碼器重建三維模型。
在基于體素的三維重建網絡中,處理體素的方式與處理圖像中的像素的方式類似,二維卷積能夠較簡單地轉變為三維卷積。基于體素模型的三維重建網絡的解碼器通常由三維卷積構成,利用三維體素模型進行訓練,但重建體素模型通常需要較大的內存,所需內存和計算要求與體素模型的分辨率大小成立方比例,因此重建的體素模型分辨率較低,基于體素模型的方法無法重建物體的細節部位。
1.2 基于點云的單張圖像三維重建
點云是利用三維坐標、顏色等信息表示物體表面的點的集合,為三維重建網絡提供了更好的表示形式。基于點云的方法重建的形狀更加平滑,相較于體素模型運算所占用的內存更少。基于點云的單張圖像三維重建通常利用編碼器-解碼器結構的網絡重建點云模型。Fan等人(2017)在圖像編碼后使用全連接和反卷積作為解碼器,使用倒角距離和搬土距離作為損失函數的指標,重建點云形式的三維模型。Mandikal等人(2019)使用全連接作為解碼器,利用搬土距離建立損失函數重建稀疏點云,然后使用多層感知機(MLP)提取點云特征,使用倒角距離作為損失函數的指標對初始的稀疏點云進行密集重建來獲取物體的點云模型。另外一些研究者聯合不同損失函數設計單張圖像點云模型重建的網絡。Mandikal等人(2019)使用點云自編碼器來學習三維點云的潛在空間。圖像編碼器將二維圖像以概率的方式映射潛在空間,推斷出多個三維重建模型,聯合匹配損失和多樣性損失重建點云模型。Jiang等人(2018)聯合生成對抗損失和多視圖一致損失,使用GAN網絡重建點云模型。
由于點云的無序性,二維卷積無法直接應用在基于點云的三維重建方法的解碼器中,基于點云的三維重建方法通常使用全連接層組成MLP解碼點云信息,計算量隨點云增多而增大,為減少計算量,通常側重于重建表面的點,由于點云的離散性,重建的點云模型表面不完整,分辨率較低。
1.3 基于網格的單張圖像三維重建
1.3.1 基于多階段網絡的單張圖像三維重建
相比于體素模型和點云模型,網格模型能夠更加完整地表示物體表面形狀,一些方法利用深度估計、點云重建等多個階段構建深度學習網絡重建網格形式的三維模型。Groueix等人(2018)使用Resnet(He等, 2016)作為圖像的編碼器,隨后使用MLP進行解碼,將二維點映射為三維點,以點的倒角損失作為損失函數重建點云模型,使用泊松重建算法重建網格模型。
深度圖和表面法向表示物體部分視角的立體結構,深度估計和表面法向估計可作為網格重建的中間步驟。深度圖的像素表示物體到相機所在平面的距離,表面法向表示物體表面的點的切線方向。基于深度學習的深度估計方法(宋巍等, 2022)已發展較長時間,Eigen等人(2014)提出單張圖像深度估計的卷積神經網絡框架,使用兩個卷積神經網絡分別從全局和局部范圍對圖像對應的深度圖進行粗略估計和細化,Hu等人(2019)提出多尺度特征融合策略的網絡結構,提高了深度估計的效果,Chen等人(2019)設計了基于感知結構的殘差金字塔網絡結構,在深度估計網絡中更高效地進行特征融合。傳統的表面法向估計方法使用光度立體算法(Woodham, 1980; Shi等,2014)進行表面法向估計,為提高性能,一些研究者(Chen等,2018; Ju等,2021)將深度學習與光度立體算法相結合,更高效地回歸表面法向,舉雅琨等人(2022)提出了一種多層聚合和權值共享回歸結構的光度立體網絡,利用不同尺度的特征回歸出高分辨的表面法向。Yao等人(2020)將深度估計和表面法向估計作為中間步驟來重建網格模型,首先估計物體前方的深度和表面法向,隨后利用GAN網絡估計物體后方的深度和表面法向,利用深度圖和表面法向重建點云,使用泊松重建算法將點云模型轉換為網格模型。Liu等人(2021)在空間占有的基礎上提出類別自適應的聯合占有,將類別特征添加到潛在編碼中,估計表面法向重建形狀,提高三維重建網絡重建不同類別的物體的性能,聯合反照率重建具有顏色紋理的網格模型。
基于深度和表面法向的網格模型重建對不可見部位的重建效果較差,而人臉圖像中的不可見部位較少,Sengupta等人(2018)提取圖像特征后使用殘差塊將圖像特征分離為表面法向特征和反照率特征,并估計光照特征,重建具有紋理的人臉三維模型。Abrevaya等人(2020)設計了圖像編碼器和表面法向解碼器之間的跳連接,進行人臉圖像到人臉表面法向的轉換。Zhang等人(2021)的網絡學習人臉身份一致性,估計反照率、深度、姿態、光照和置信度,從圖像中重建人臉三維模型。
1.3.2 基于模板的單張圖像三維重建
由于網格模型的頂點相互連接,將網格的頂點作為圖結構進行處理,使用圖卷積神經網絡處理網格模型的頂點,從而對初始的網格模型進行變形優化,重建更加精細的網格形式的三維模型。Wang等人(2018)根據編碼器提取的圖像特征使用圖卷積神經網絡對初始橢球體形狀的網格模型進行多個階段的變形,聯合倒角損失和表面法向損失重建網格模型。Tang等人(2019)綜合多種方法設計了骨架橋接網絡,該網絡分為三個階段分別重建物體的骨架模型、體素模型和網格模型,使用MLP提取骨架點,根據圖像特征和骨架點重建粗糙的體素模型,隨后使用3D-CNN處理體素模型并將體素模型網格化,聯合倒角距離損失和拉普拉斯平滑度的正則化構建損失函數,利用圖卷積神經網絡重建網格模型。
不同的人體和人臉之間存在相似性,因此可用參數化模型表示人體和人臉三維模型。人體三維重建方法通常使用蒙皮多人線性模型(SMPL)作為人體參數化模型,Kanazawa等人(2018)設計了人體模型重建網絡將CNN作為編碼器獲得圖像特征,由圖像特征回歸相機參數以及SMPL模型的形狀參數和姿態參數,由參數生成SMPL模型。Kolotouros等人(2019)將輸入圖像編碼為低維特征向量,附加到網格模型的三維坐標,隨后使用圖卷積神經網絡對網格進行處理,回歸網格模型頂點的三維坐標。Lin等人(2021)提取圖像特征向量,并將圖像特征與三維坐標連接,學習圖像和網格頂點之間的相關性,使用Transformer回歸網格頂點的三維坐標。人臉三維重建方法使用可變形人臉模型(3DMM)作為人臉參數化模型,Richardson等人(2017)的網絡由CoarseNet和FineNet兩部分組成,CoarseNet基于ResNet網絡生成由幾何和姿態參數表示的粗糙模型,Finenet對粗糙模型的參數進行優化,獲取3DMM人臉參數化模型的細節。Zhu等人(2019)通過級聯卷積神經網絡對圖像進行擬合,預測參數更新,并作為3DMM人臉參數化模型的參數生成模型。
基于模板的單張圖像三維重建通過變形初始網格模型或回歸參數化模型的方式對三維模型進行重建,通常只能重建特定頂點數量的網格模型,對三維模型細節部位的重建效果較差。
1.3.3 基于隱式函數的單張圖像三維重建
為減少訓練期間的內存并進一步提高重建效果,一些研究者提出可表示三維形狀的隱式函數,通過學習重建目標的隱式函數來重建網格形式的三維模型。常用的隱式函數有符號距離函數、空間占有率和點標簽。在神經網絡構建表示三維形狀的隱式函數后,使用提取算法從學習到的三維表示中提取信息,重建網格三維模型。
Wang等人(2019)首先估計相機姿態并投影,隨后使用MLP構建符號距離函數,使用符號距離函數隱式函數表示物體形狀并重建網格模型。Mescheder等人(2019)使用標記立方體算法設計了一種連續占用網絡預測空間占有率,隱式表示三維形狀,聯合等位面損失和表面法向損失重建網格模型。Chen等人(2019)使用點相對形狀的內外狀態作為點標簽建立隱式函數表示物體,編碼器使用Resnet網絡對圖像進行編碼,將特征編碼和點坐標送入MLP,解碼出點標簽的值,將點標簽的加權均方誤差作為損失函數建立物體的隱式函數,隨后使用提取算法從學習到的三維表示中提取網格信息,重建網格形式的三維模型。Popov等人(2020)通過構建網格頂點的概率分布函數隱式表示物體形狀,使用跳連接來連接編碼器和解碼器,提高重建三維模型的性能。
基于隱式函數的三維重建方法可使用特定的數據集和圖像編碼器對人體等特定物體進行重建,Saito等人(2019)使用像素對齊的隱式函數預測人體模型的內外點標簽。使用堆疊沙漏網絡對圖像進行編碼,通過多層感知機解碼隱式函數,預測三維點在人體模型的內部和外部的分布,構建點標簽形式的隱式函數,重建人體模型。Saito等人(2020)使用兩級別的像素對齊預測網絡進行高分辨率的三維重建。粗糙級別的重建網絡捕獲圖像的像素特征,高分辨率的網絡通過預測的表面法向獲取細節特征,隨后與粗糙級別的三維特征共同送入多層感知機建立隱式函數,重建精細的人體三維模型。基于隱式函數的三維重建方法使用隱式函數表示物體形狀,可重建具有完整表面和細節信息的三維模型。
1.3.4 基于可微渲染的單張圖像三維重建
大多數單張圖像三維重建的方法重建單一顏色的網格,一些方法通過可微渲染估計對三維模型進行紋理映射,重建具有顏色紋理的網格模型。Chen等人(2019)設計了可微渲染框架,通過可微渲染將初步重建的三維模型渲染為二維圖像并與輸入圖像構建二維圖像損失,通過估計形狀、照明和紋理來重建具有顏色紋理的網格模型。Niemeyer等人(2020)將二維圖像和深度圖作為基準,利用可微渲染將網格模型渲染為二維圖像并與輸入圖像對比,聯合深度損失和空間占有損失重建網格模型,重建具有顏色紋理的網格模型。Zhang等人(2020)利用StyleGAN(Karras等, 2019)網絡生成物體的其他視角的圖像,隨后將多視角圖像作為基準,訓練基于可微渲染框架的三維重建網絡,估計物體的形狀、照明和紋理,重建具有顏色紋理的網格模型。
基于可微渲染的單張圖像三維重建使用僅包含圖像的數據集進行訓練,降低了數據集的獲取難度,可重建三維模型的顏色紋理。
典型的單張圖像三維重建網絡結構如圖4所示。
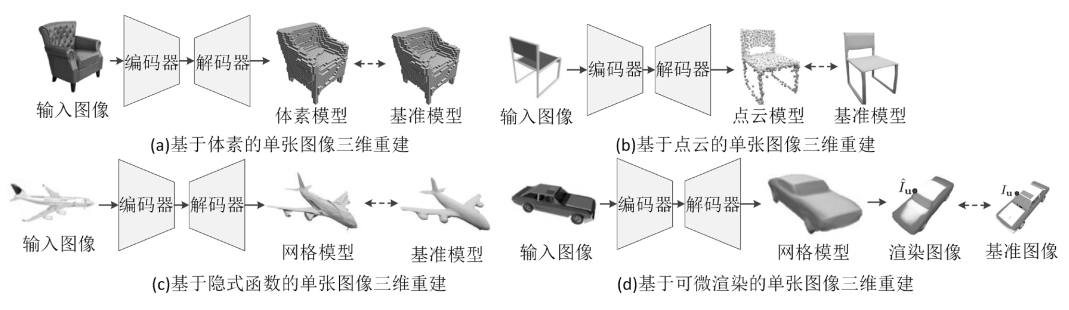
圖4 典型的單張圖像三維重建網絡結構
02 多張圖像三維重建
單張圖像三維重建的輸入為單一視角的單張圖像,重建的三維模型的完整性較差,因此一些方法在單張圖像方法的基礎上進行多張圖像三維重建,多張圖像三維重建的方法結合多張圖像的信息重建三維模型,提高三維重建網絡的性能。
2.1 基于體素的多張圖像三維重建
基于體素的多張圖像三維重建網絡結構與單張圖像三維重建網絡類似,為編碼器-解碼器結構,將編碼器輸出的多張圖像特征進行融合,并根據圖像特征對體素模型進行細化調整,實現多張圖像三維重建。早期的方法基于循環神經網絡對圖像特征進行融合,Choy等人(2016)等依次處理多張圖像,將圖像的編碼特征送入3D-LSTM,3D-LSTM單元根據特征編碼更新潛在編碼,選擇性地更新之前的視圖中的被遮擋部位,通過關閉輸入門來保留可見部位的潛在編碼,最后3D-CNN解碼重建體素模型,基于圖像特征融合進行多張圖像三維重建,網絡結構如圖5(a)所示。Kar等人(2017)等通過特征編碼器對多張圖像進行處理,并根據圖像相應的相機參數投影到三維特征中,以循環的方式匹配并生成融合的體積特征,由3D-CNN網絡轉換為體素模型。另外一些方法首先利用單視角圖像初步估計形狀,隨后利用相機參數或姿態編碼將形狀特征進行融合。Spezialetti等人(2020)通過姿態估計、姿態優化、體素估計和體素細化重建體素模型。Xie等人(2019)使用VGG網絡對不同視圖分別進行編碼,3D卷積解碼獲取相應的粗糙模型,然后使用上下文注意力模塊進行特征融合,獲取最終的體素模型,網絡結構如圖5(b)所示。之后的Pix2Vox++(Xie等, 2020)網絡的結構與Pix2Vox類似,其中圖像編碼器使用Resnet網絡,提高了圖像編碼的性能。Wang等人(2021)使用二維Transformer作為編碼器,三維Transformer作為解碼器,同時進行特征提取和視圖融合,提高了輸入圖像較多的情況下的體素三維重建方法的性能。
基于循環神經網絡的重建方法依次處理多張圖像,重建結果與圖像的輸入順序相關,運行速度較慢。基于形狀特征融合的方法對多張圖像分別進行編碼、解碼,重建粗糙的形狀模型并進行融合,運行速度較快,在圖像較少的情況下重建效果較好,基于圖像特征融合的方法的重建效果隨著圖像數量增加而提高,在圖像較多的情況下重建效果較好。多張圖像三維重建的網絡結構如圖5所示。
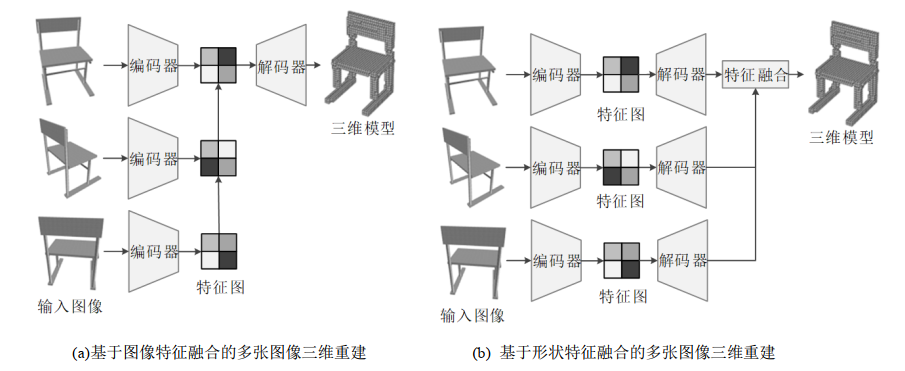
圖5 多張圖像三維重建網絡結構
2.2 基于網格的多張圖像三維重建
基于網格的多張圖像三維重建的輸入通常為已知相機參數的多張圖像,通過結合多視圖中每張圖像所對應的相機參數,能夠獲取圖像之間的對應關系,從而提高重建三維模型的效果。Bautista等人(2021)由U型網絡編碼器生成特征圖,然后根據相機參數將特征圖連接,通過MLP生成特征點,隨后使用類似空間占用網絡的方法,預測空間占有率并通過隱式函數重建三維模型。Shrestha等人(2021)先估計物體的體素模型,然后利用體素模型渲染出深度圖,再將渲染出的深度圖與多視角立體估計的深度圖進行對比,以從粗到細的方式利用對比特征將三維模型進一步細化,最后獲取網格形式的三維模型。Wen等人(2019)在單張圖像三維重建Pixel2mesh(Wang等, 2018)的輸出之后建立多視圖變形網絡,利用圖卷積神經網絡對粗糙模型進行迭代細化。多視圖變形網絡由多張輸入圖像的特征生成每個頂點周圍區域的假設位置,并估計最優變形,網絡結構與基于形狀特征融合的多張圖像三維重建方法的網絡結構相似。Yuan等人(2021)將具有權重的輔助視圖特征添加到主視圖特征中,使用圖卷積神經網絡對初步重建三維模型進行變形,結合多張圖像特征逐步細化網格模型。
大多數重建室內場景的方法屬于基于圖像特征融合的多張圖像三維重建,重建室內場景的網絡利用截斷符號距離函數表示場景的三維形狀,利用行進立方體算法提取網格模型。Murez等人(2020)等使用CNN網絡提取多張圖像特征并轉化為三維特征,將三維特征融合并送入3DCNN回歸截斷符號距離函數。Sun等人(2021)將特征金字塔網絡作為編碼器,利用門控循環神經網絡網絡進行特征融合,解碼器使用MLP,提高了運行速度,可對室內場景進行實時三維重建,網絡結構如圖5(a)所示。
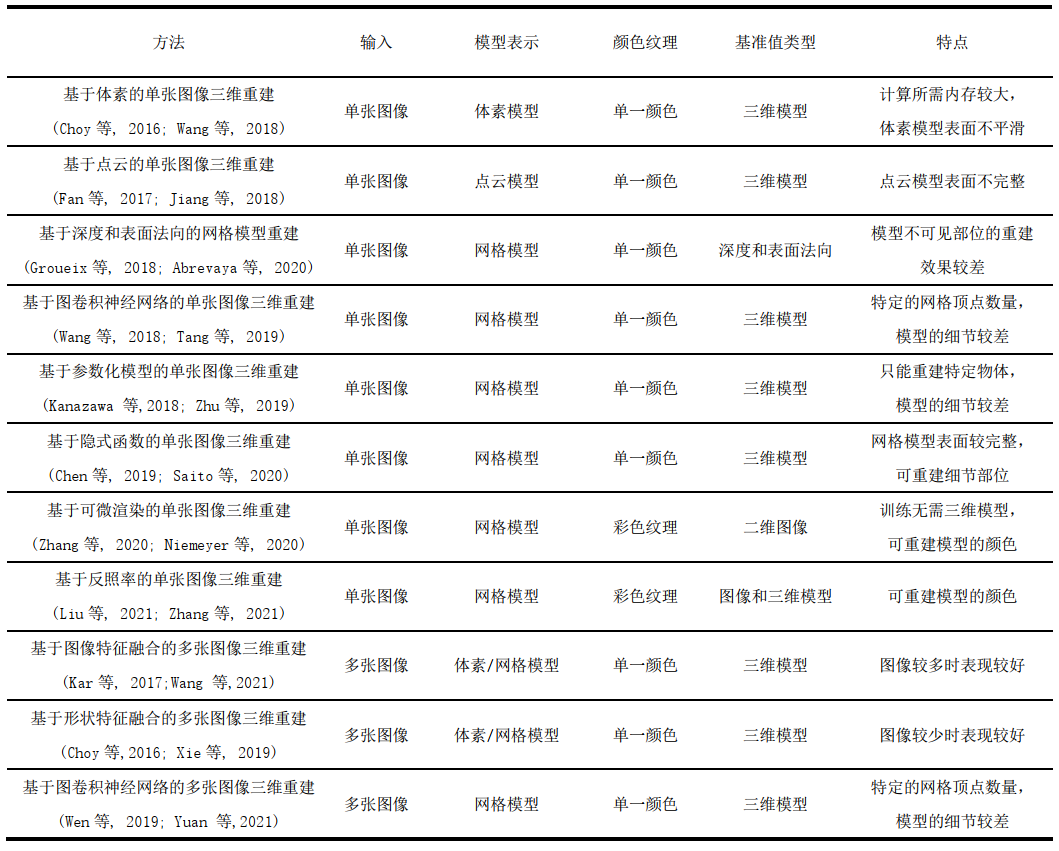
表1 總結了本文介紹的圖像三維重建方法。
表1 圖像三維重建方法總結
03 數據集與實驗對比
在本節中,主要針對深度學習背景下的圖像三維重建中的常用數據集以及不同方法在ShapeNet數據集上的實驗對比進行相應的介紹。
3.1 數據集介紹
目前,在圖像三維重建任務中可用的數據集有ShapeNet、ModelNet、Pix3D、PASCAL 3D+、ObjectNet3D、DTU、NYU depth和KITTI等,這些數據集包含了三維模型或注釋信息,其中Shapenet數據集和ModelNet數據集中的圖像為三維模型渲染合成,不同視角渲染的多視角圖像可用于多張圖像三維重建,Pix3D、PASCAL 3D+和ObjectNet3D數據集中的圖像為真實圖像,三維模型與二維圖像相互匹配,PASCAL 3D+和ObjectNet3D數據集中的三維模型匹配相同類別的模型,不能與圖像精準對齊,Pix3D數據集中的圖像與三維模型進行像素對齊,DTU數據集包含場景的二維圖像、深度圖及點云模型,NYU depth數據集和KITTI數據集包含二維圖像和深度圖,數據集的具體信息如表2所示。
表2 圖像三維重建數據集總結
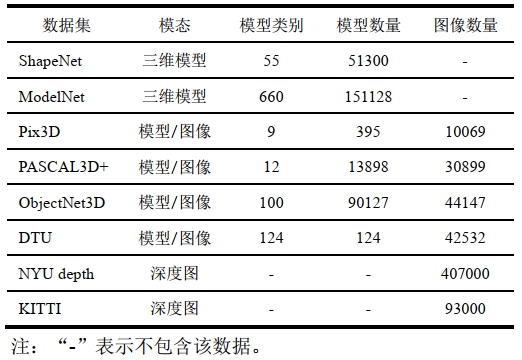
ShapeNet數據集是三維重建領域的常用數據集,由Chang等人(2015)構建,收集了大量三維模型并對三維模型添加相應的對齊、部位分割和尺寸等注釋。ShapeNet數據集包含55個類別的51300個三維模型。大多數三維重建方法使用由13個類別的44000個模型組成的ShapeNet數據集的子集,數據集中的二維圖像由三維模型渲染合成。ModelNet數據集由Wu等人(2015)創建,收集了660個類別的151128個三維模型。Pix3D數據集由Sun等人(2018)構建,包含9個類別的395個三維模型和10069張真實圖像,每個三維模型都與一組真實圖像相關聯,三維模型和圖像中的輪廓進行了像素對齊,具有精確的三維注釋信息。DTU數據集由Aan?s等人(2016)構建,包含124個不同場景,每個場景具有相應的點云模型和49個視角的7種亮度的二維圖像及對應的深度圖。PASCAL 3D+數據集和ObjectNet3D數據集為三維物體識別數據集,也可應用于三維重建領域。PASCAL 3D+數據集(Xiang等, 2014)采用PascalVOC2012數據集中的12個類別的剛性物體。數據集中的基準三維模型使用二維圖像中同類物體的三維模型進行配準,并從ImageNe數據集中為每個類別的三維模型匹配更多的圖像。ObjectNet3D數據集由Xiang等人(2016)構建,通過對齊將ImageNet數據集中的二維圖像和ShapeNet數據集中的三維模型進行匹配,為二維圖像提供三維姿態標注和三維形狀標注ObjectNet3D數據集共包含100個類別的90127個圖像和44147個三維模型。
NYU Depth數據集由Silberman等人(2012)構建,包含464個室內場景中的407000張圖像及對應深度圖。KITTI數據集由Geiger等人(2012)構建,包含室外場景的93000張二維圖像及對應深度圖。
3.2 三維重建的實驗對比
為了驗證不同算法在ShapeNet數據集上的性能,本文總結了8種單張圖像三維重建算法和8種多張圖像三維重建算法,使用倒角距離(CD)、F1分數(F1-score,F1)、交并比(IoU)作為評測指標進行對比。CD是三維模型之間的平均最短距離,具體為
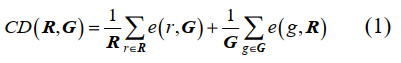
式中, R和G表示重建模型和基準模型, r和g分別表示R和G中的任意一點,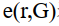 表示r到G的最短距離,
表示r到G的最短距離,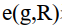 表示g到R的最短距離。
表示g到R的最短距離。
F1分數考慮精確率和召回率的標準,具體為

式中, P和R分別表示精確率和召回率。
IoU是重建模型R和基準模型G之間的交集區域與并集區域的比值,具體為
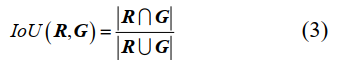
單張圖像三維重建方法在ShapeNet數據集上的具體結果如表3所示。
表3 ShapeNet 數據集上單張圖像實驗對比
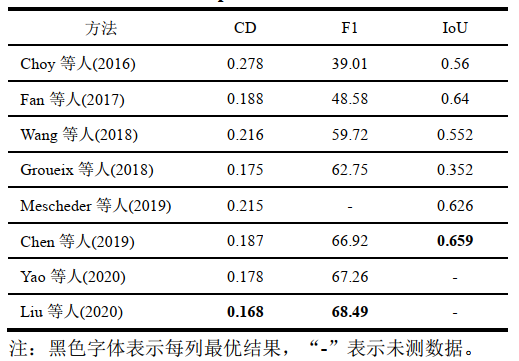
由表3可知,在CD和F1分數指標上,Choy等人(2016)方法表現最差,之后的算法的性能逐步提升,Chen等人(2019)方法和Yao等人(2020)方法的性能表現相當,Liu等人(2020)方法表現最佳。Choy等人(2016)方法和Fan等人(2017)方法的表現主要受輸出形式的影響,Choy等人(2016)方法的輸出為體素模型,重建體素模型的內存需求較大,因此輸出的分辨率較低,性能表現不佳,Fan等人(2017)方法的輸出為點云模型,點云模型中的點是離散的,不能完整地表示三維模型,因此在F1分數指標上的性能較差。Wang等人(2018)方法通過對橢球體進行變形來獲取網格模型,網格模型可以完整地表示物體表面,因此在CD指標上的數值大于之前的方法在CD指標上的數值,但對物體的孔洞和細小部位的重建效果較差,在IoU指標上的性能較差。Chen等人(2019)方法和Yao等人(2020)方法分別通過構建隱式函數和估計深度、表面法向的方式提升了網格模型重建的性能,Liu等人(2020)方法通過同時預測分類、形狀和光照的方式達到了最佳性能。多張圖像實驗在ShapeNet數據集上的結果如表4所示。
表4 ShapeNet 數據集上多張圖像實驗對比
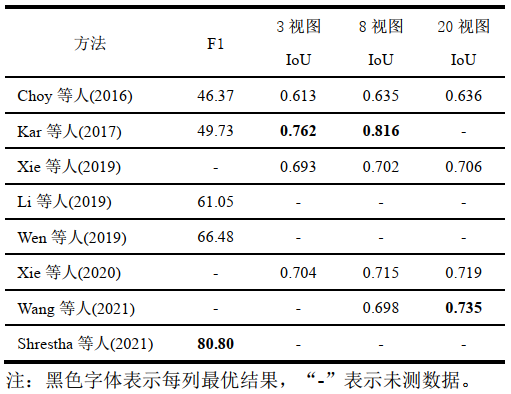
由表4可知,Choy等人(2016)方法的性能表現最差,在F1指標上Shrestha等人(2021)方法表現最佳,在IoU指標上Kar等人(2017)方法表現最佳。Choy等人(2016)方法基于RNN網絡依次處理圖像,不能充分利用多張輸入圖像之間的特征來細化三維模型,因此在F1指標上表現最差,Shrestha等人(2021)方法較之前的方法提高了21.5%~74.2%,主要是因為利用多視角立體網絡估計多張圖像的深度圖并使用圖神經網絡對粗糙網格模型進行優化。Kar等人(2017)方法在IoU指標上表現最好,主要是因為該方法將多張圖像和相機參數作為輸入,利用相機參數確定多張圖像之間的相對位置,更加充分地利用了多張圖像的特征。在無需相機參數的方法中,Xie等人(2020)方法利用上下文感知模塊融合多張圖像重建的三維模型,提升了性能,Wang等人(2021)方法利用Transformer處理長距離依賴關系,在圖像較多時達到了最佳性能。
04 討論與展望
隨著技術的發展,使用深度學習技術的圖像三維重建取得了一定的成果,但圖像三維重建領域仍面臨著許多的問題與挑戰。本節介紹當前圖像三維重建領域中的待解決的問題以及未來的研究方向。
1)三維重建方法的泛化能力
三維重建的目標是從任意圖像重建物體的三維模型,但目前的大多數方法只在與數據集中圖像類似的圖像上表現良好,在數據集中未包含類別的物體或圖像較少的物體的表現不佳,人體和人臉等特定對象的三維重建方法在未訓練的數據集上的重建效果相對較差,因此三維重建方法的泛化能力是一個亟待解決的問題。
2)三維重建的精細度
當前的三維重建方法重建的三維模型較粗糙,對細節的重建效果較差,三維重建方法的精細度有待進一步提高,繼續提高三維重建方法的精細度是圖像三維重建領域的重點研究方向。
3)三維重建與分割識別任務相結合
目前的數據集的圖像大多數是無背景的單個物體圖像,而真實的圖像往往更加復雜,因此三維重建需要與分割識別進一步相結合,對復雜圖像中待重建物體進行語義分割或識別,更加高效地進行重建。在特定物體的重建方法中,人體三維重建方法首先進行語義分割或人體姿態識別,人臉三維重建方法可與人臉屬性識別相結合。三維重建與分割識別相結合是深度學習背景下的圖像三維重建技術發展中的一個重要方向,同時也是提高圖像三維重建的精細度的重要方法。
4)三維模型的紋理映射
早期的圖像三維重建方法只能重建物體的三維形狀,近期的圖像三維重建方法可在重建物體形狀后進行紋理映射,通過預測三維模型網格頂點的顏色或建立紋理貼圖來獲取具有顏色紋理的三維模型,但目前的方法對細節部位的紋理映射的效果較差,三維模型的紋理映射方法有待進一步發展。
5)三維重建的評測體系
三維重建的評測體系需進行進一步完善,一些三維重建的評測指標僅適用于特定任務,如IoU適用于體素模型的評測,而F1分數在不同方法所使用的距離閾值不同的情況下無法進行比較。此外,目前的大多數三維重建算法只對物體重建的形狀進行評測而忽略了紋理信息,三維重建中紋理的評測指標也限制了三維模型的紋理映射的發展,因此未來需要繼續探索統一高效的三維重建的評測體系。
05 總結
三維重建技術受到廣泛關注,成為當前的研究熱點,得益于三維模型的大量出現以及計算機視覺技術的廣泛應用。人工建立三維模型的時間成本較高,深度學習背景下的圖像三維重建技術具有較高的研究價值。
本文主要對近年來深度學習背景下的圖像三維重建的分類和研究現狀進行總結,整體分為六個部分:引言、單張圖像三維重建、多張圖像三維重建、數據集與實驗對比、討論與展望、總結。本文旨在為三維重建領域的研究人員提供有價值的參考,促進三維重建領域的進一步發展。
審核編輯 :李倩
-
三維模型
+關注
關注
0文章
52瀏覽量
13153 -
深度學習
+關注
關注
73文章
5513瀏覽量
121546
原文標題:深度學習背景下的圖像三維重建技術進展綜述
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
三維測量在醫療領域的應用
商湯科技運用AI大模型實現實景三維重建
CASAIM與東北大學達成合作,三維掃描技術助力異形建材模型重建及尺寸精準分析

三維堆疊封裝新突破:混合鍵合技術揭秘!

CASAIM與邁普醫學達成合作,三維掃描技術助力醫療輔具實現高精度三維建模和偏差比對
建筑物邊緣感知和邊緣融合的多視圖立體三維重建方法

三維可視化技術的應用現狀和發展前景
留形科技借助NVIDIA平臺提供高效精確的三維重建解決方案
基于大模型的仿真系統研究一——三維重建大模型
激光距離選通三維成像技術研究進展綜述

三維掃描與3D打印在法醫頭骨重建中的突破性應用
常用的RGB-D SLAM解決方案
泰來三維|文物三維掃描,文物三維模型怎樣制作






 工商網監
工商網監
評論