 基于智能狀態和源代碼插樁的C程序內存安全性動態分析
基于智能狀態和源代碼插樁的C程序內存安全性動態分析
作者介紹
陳哲,南京航空航天大學副教授,碩士生導師。研究方向:軟件驗證,程序分析,形式化方法等。
摘要
C 程序的內存錯誤可能導致程序崩潰和安全缺陷,因此使用動態分析工具在運行時自動發現內存錯誤是工業界面臨的一個痛點,然而傳統的內存安全性動態分析工具具有三個缺點:低有效性、優化敏感和平臺依賴。
為了克服以上問題,我們提出了一種基于智能狀態的監控算法和一種源代碼級別的插樁框架,并依此實現了一款新的動態分析工具 —— Movec。實驗表明,Movec 工具比 AddressSanitizer、Valgrind 等著名工具能找到更多的內存錯誤,在性能和可用性方面也非常有競爭力。這項長達五年的持續研究已經在 ISSTA’19[1]、ISSTA’21[2]、ICSE’22[3]、IEEE TSE[4]等頂級會議和期刊發表了 4 篇論文,并獲得一次 ACM SIGSOFT 杰出論文獎。
以下為正文。
# 背景 #
今天為大家帶來 C 程序內存安全性動態分析相關工作的分享,包含兩個創新點,一個是 智能狀態,一個是 源代碼插樁。
C 語言經常被應用于系統軟件的編程,比如嵌入系統、操作系統、編譯器等,它可以對內存進行低級別的控制。然而由于開發人員水平參差不齊,C 程序極易出現內存錯誤,導致數據腐敗、程序崩潰等一系列漏洞。
使用靜態分析工具,可以在不運行程序的情況下,在程序編譯期間發現錯誤。 但由于不可判定性,靜態分析工具往往會產生誤報。這時我們需要在準確性和性能之間做出平衡,往往需要犧牲一些精確性來獲得更好的性能。
使用動態分析工具,可以在運行時動態分析程序執行有無錯誤。 動態分析工具一般情況下不會產生誤報,但可能產生一些 運行時負載,即程序的運行速度會比未插樁分析之前的程序慢。但通常來說,動態分析工具一般用于測試階段,這種為程序帶來的慢是可以接受的,所以動態分析工具現在很流行。
# 內存錯誤類別
我們將內存錯誤分為四類:
空間錯誤 Spatial Errors
即對空指針或未初始化指針的解引用。比如數組越界,定義一個數組,大小是 10,如果訪問第 11 個元素,那么就發生了越界,屬于空間錯誤。
包含懸空指針,或者對指針的二次釋放。比如在堆里分配一個內存,把它釋放掉后,接著又去訪問它或者釋放它。
段混淆錯誤 Segment Confusion Errors
即未根據指針預期的類型來使用指針。比如有一個函數指針,正常應該用指針去調用函數,但使用時卻用指針來輸出里面的指針所指向區域的數據。
內存泄漏錯誤 Memory Leaks
即堆內存上存在不會再被使用也未被釋放的對象。比如,在內存中分配了一個對象,但其既未被使用,也未被釋放,導致內存越用越少,形成內存泄露。
# 動態分析方法和工具
## 監控方法
動態分析的 監控方法 有很多種。這些監控方法有一個共同點,即 在運行時維護一些元數據。這些元數據用來描述程序當中的一些空間和時間信息,比如,一個對象“被分配了多少空間”、“是否現在還存在于內存當中”、“是否正在被使用”等等。根據這些元數據信息,可以判斷程序當中是否有內存錯誤。
下面列出了動態分析的幾種主要監控方法,以及支持的工具。比如 SoftBoundCETS[5],使用基于指針的方法和基于標識符的方法;Google 的 ASan[6]使用了面向對象的方法和內存哨兵技術。保存元數據是這些工具基本的思想。
基于指針的方法:SoftBoundCETS
基于標識符的方法:SoftBoundCETS
面向對象的方法:Google's ASan, Valgrind[7]
內存哨兵技術:Google's ASan
舉個例子,假設在內存當中使用 malloc 分配了一個內存空間,工具會記錄 p 所指向的空間的基地址是 p 的值,上界是 p+100。如果程序訪問的是 [p, p+100] 之間的內存,則工具會判定是合法的,若程序訪問超出了這個范圍的內存,比如 p+101,則工具會認定是一個內存錯誤。
int*p=malloc(100*sizeof(int)); //Thebaseofpis"p". //Theboundofpis"p+100".
## 插樁框架
動態分析工具的另一個基礎技術是 插樁框架。這些插樁框架需要在待驗證的程序中插入一些代碼片段,這些代碼片段實現的就是監控元數據的方法。被插入的代碼片段會隨著程序的運行而運行,并收集數據來判定是否有內存錯誤。
現有的插樁框架都是在中間代碼或者二進制層面上進行插樁,目前沒有在源代碼級別進行插樁的工具。
中間代碼層 (中間表示):SoftBoundCETS, Google's ASan
二進制層 (目標代碼,可執行文件):Valgrind
# 面臨的挑戰 #
現有的算法和框架,面臨著三個挑戰。
一是 有效性比較低 low effectiveness。現有的方法無法 確定地、完整地 找到所有的內存錯誤,包括子對象越界、釋放后使用、段混淆、內存泄漏。
此外,現有的算法工具 對優化敏感 optimization sensitivity。不同的編譯器優化級別會對檢測的最終結果造成影響,一些在低優化級別能找到的內存錯誤在高優化級別下就找不到了。
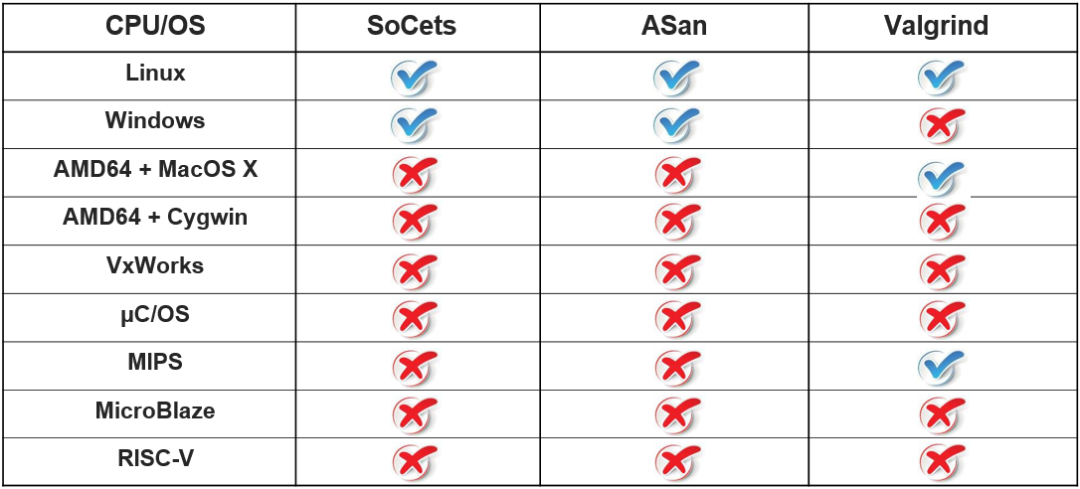
第三個挑戰是 平臺依賴 platform dependence。現有工具只能在一些主流的平臺上運行,如 Linux、Windows;無法在一些特定的領域系統上使用,如航空航天領域、嵌入式系統領域,操作系統如 VxWorks 和 uC/OS、架構如 MIPS, MicroBlaze, RISC-V 等。
下面是具體的挑戰舉例。
# 低有效性
段混淆錯誤
以非法的解引用為例。
下面的示例代碼中,定義了一個指針 s 指向一個函數 (第七行)。但在使用時 (第八行),訪問的是它所指向的內存空間里面的第 0 號元素。這個錯誤可能引起信息泄露 information leakage。
//Example1:Usingafunctionasdata //Thiserrormaycauseinformation //leakage. 1voidfoo();/*afunc*/ 2char*func(char*c){ 3returnc; 4} 5intmain(){ 6void(*p)()=foo; 7char*s=func(p); 8charch=s[0];/*error*/ 9return0; 10}
下面示例代碼中,定義了一個指針 p,指向數組里面的一個元素。但在使用時,把它當成了一個函數來調用 (第七行)。這種錯誤可能引起控制流劫持 control-flow hijacking。
//Example2:Usingdataasafunction
//Thiserrormaycausecontrol-
//flowhijacking.
1void(*f(void(*p)()))(){
2returnp;
3}
4intmain(){
5inta[100];
6void(*p)()=f(a);
7(*p)();/*error*/
8return0;
9}
這些錯誤已有的工具都是發現不了的。
子對象越界
下面示例代碼中,有一個指針 p,指向一個結構體 s 的成員 m1 (第七行),但在使用時,超出了 m1 的范圍 (第八行)。
//Example3:Sub-objectoverflow //Anoverflowfromafieldofa //structtoanother 1typedefstruct{ 2intm1; 3intm2; 4}st; 5intmain(){ 6sts; 7int*p=&s.m1; 8p[1]=0;/*spatialerror*/ 9return0; 10}
下面示例代碼中,定義了數組 buf (第二行),但在訪問時,超出了數組所指向的范圍 (第七行)。由于 buf 是處于結構體的內部,所以已有的工具也發現不了。
//Example4:Intra-arrayoverflow
//Anoverflowfromanarrayelement
//toanother
1typedefstruct{
2charbuf[10];
3inti;
4}st;
5intmain(){
6starr[5];
7p[2].buf[20]='A';
8/*spatialerror*/
9return0;
10}
內存釋放后使用
這種錯誤指釋放一個內存對象之后再訪問它。對于這種錯誤,現有的工具只能以概率的方式 (lock key scheme) 或者部分的方式 (object-based 和 quarantine-based 方法) 來檢測此種錯誤,受限于算法本身的缺陷,會造成假陰性 false negative 的結果。
內存泄漏
現有工具只能在程序終止時才能檢測到內存泄漏,在程序運行過程當中,也就是內存泄漏發生的地方,工具是無法及時發現的。
# 優化敏感
空間錯誤
下面代碼示例中有一個內存錯誤,指針 p 指向了變量 i 的地址 (第四行),在解引用時超出了 i 的范圍 (第六行)。
//Example5:Aspatialerror //*(p+5)causesaspatialeror. /*Option-O1hideserror.*/ 1#include2intmain(){ 3inta[10]={0}; 4inti=1,sum=0,*p=&i; 5 6*(p+5)=1;/*spatialerror*/ 7 8for(i=0;i<10;?i++) 9??????sum?+=?a[i]; 10???printf("sum?is?%d ",?sum); 11???return?0; 12?}
針對上面的錯誤,已有的工具檢測結果如下所示。當使用比較高級別的優化時,工具就沒有那么有效了。

ASan and Valgrind are the same on other programs.
時間錯誤
下面示例中,第九行 *n 存在時間錯誤。
//Example6:Atemporalerror //Dereferencingnaccessesanout-of //-scopestackvariablex,resulting //inatemporalerror. /*Option-O2hideserror*/ 1#include2voidfoo(int**p_addr){ 3intx; 4*p_addr=&x; 5} 6intmain(){ 7int*n; 8foo(&n); 9printf("%d ",*n); 10/*temporalerror*/ 11return0; 12}
工具查找結果如下圖所示。

出現這種問題的根本原因是 編譯器優化。編譯器優化會導致源代碼和二進制代碼之間并不完全一致,這會使得工具在對優化之后的代碼進行插樁時出現一些問題,使得原來在源碼中的錯誤無法被檢測到。這也是在中間表示和二進制代碼上插樁的局限性。
所以,我們在使用這些工具的時候,需要在性能和有效性上做一個平衡。比如使用 -O0 的時候,獲得的有效性會比較高,但犧牲了性能;選擇更高的優化水平,比如使用 -O3 時,就要接受其有效性可能會受到一定的損失。
# 平臺依賴性
中間表示級或二進制級的工具總是被集成到有限的依賴于平臺的宿主編譯器中。比如基于 LLVM 的 SoCets 和 ASan,以及基于二進制級的框架 Valgrind。但 C 是一種跨平臺的編程語言,這些強平臺依賴的工具無法支持我們在不支持的平臺上測試或者部署插樁代碼。
下圖總結了目前工具所適用的平臺情況。
# 我們的工作 —— Movec #
有什么辦法來解決上述的三個局限性呢?我們從兩個方面來解決這三個問題。
第一個是在 監控算法 上面的創新。
我們提出一種 基于智能狀態的監控算法 (smart-status-based, Smatus),該監控算法可以全面地檢測到上文提到的所有內存錯誤。
其核心思想是使用了 狀態節點,當在內存當中創建一個內存對象時,就會給這個對象創建一個狀態節點,記錄內存對象當前的狀態,比如是否仍在活躍當中、是否已被釋放等。除了跟蹤每個指針所指的邊界外,還會維護一個引用計數,用以記錄這些內存狀態到底被多少個指針所引用。由于有了這些額外的元信息,我們就可以找出現有工具找不出的內存錯誤。
第二,我們提出了一個新的 源代碼級別的插樁框架。
這個插樁框架并不改寫中間表示或二進制代碼,而是直接對程序員所寫的原始源代碼進行操作,并且插入 ANSI C 的源代碼片段,因此插樁后產生的源代碼擺脫了平臺依賴,可以使用任何的 C 編譯器編譯。
我們實現了一個工具 Movec,結合了上面兩方面的技術。Movec 架構和工作流如下,包含了一個預處理器、一個 AST 解析器、一個 AST 訪問器 (這個訪問器里面實際上包含了源代碼的插樁框架)。當輸入一個 C 程序時,程序會依次經過 預處理器 -> 解析器 -> 訪問器。
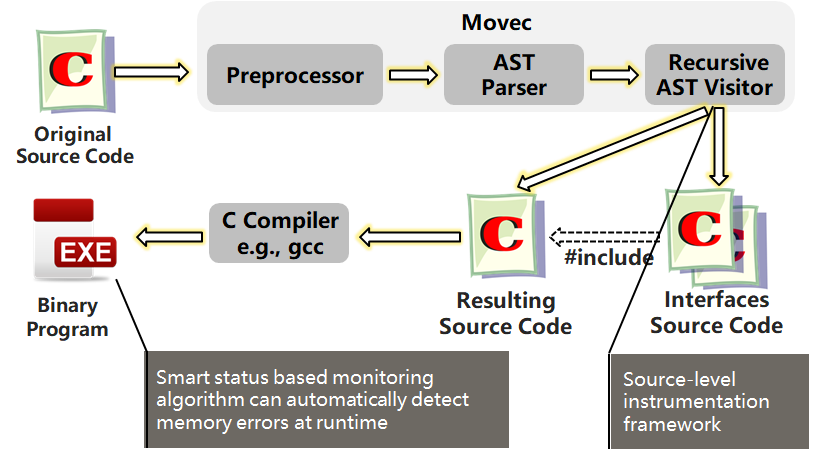
代碼插樁發生在 AST 訪問器 (AST Visitor) 里。Movec 會對源代碼進行改寫,生成一個修改后的源程序,以及一些接口源文件。這些接口源文件包含了監控算法的代碼,會被自動地包含到修改后的 C 程序當中,通過對此時的 C 程序進行編譯,就得到了一個可執行文件。運行該可執行文件時,基于智能狀態的監控算法就能夠自動地捕獲程序里的錯誤。
# 基于智能狀態的監控算法
## 算法實現原理
下面通過幾個例子,說明基于智能狀態的監控算法的基本原理,便于大家有一個更直觀的理解。
子對象越界
定義結構體 st 中有兩個成員 m1 和 m2。
聲明一個結構體 s,假設給 s 分配的內存空間范圍是 [0x3000, 0x3016]。此時,監控算法會給 s 創建一個狀態節點,包括狀態 stack,和一個引用計數 1。
接下來執行第二行代碼,讓一個指針 p 指向 s.m1,這個時候會給 p 創建一個元數據,元數據里面會記錄 p 指向的上界 0x3008 和下界 0x3000。元數據里還有一個指針會指向 s 的狀態節點,通過指針就能夠找到它所指向的變量是在堆中還是棧中。同時,引用計數變成 2。
第三行代碼中,使用 p[1] 訪問 p 所指向的對象,這時候監控算法會去查詢元數據,看到它能夠訪問的正常范圍 [0x3000, 0x3008],而我們要訪問的范圍實際上是 [0x3000, 0x3016],顯然超出了所記載的范圍,這個時候工具就會報錯,因為訪問的范圍超過了元數據中所記錄的范圍。

?段混淆
程序中有一個函數 foo(),在內存當中會給這個函數分配一個空間。假設它的內存地址是 [0x1000, 0x1256]。接下來會給這個函數創建一個狀態節點,說明它的狀態是一個函數 function,它的引用計數初始值是 1。
第一行代碼中,用一個指針 p 指向這個函數,給指針 p 創建一個元數據,記錄它所指向的上界和下界。由于它是一個函數,進行特殊處理后,記錄上界是 0x1000,下界是 0x1001。它也有一個指針指向它的狀態節點,引用計數變成 2。
第二行代碼中,指針變量 s 也指向這一個函數。也會給 s 創建一個元數據,它的上界是 0x1000,下界是 0x1001。它有一個指針指向狀態節點,同時引用計數變成 3。
第三行代碼中,用 s[0] 來訪問元素,監控算法會去查詢它所指向的對象是什么。圖中顯示是一個函數 function,但是解引用的方式卻使用了數組元素解引用的方式,所以會發現它的段類型和使用指針的方式并不匹配,是一個段混淆錯誤。

時間錯誤
首先,使用 malloc 在堆里面分配一個內存對象,范圍是 [0x2000, 0x2008]。接下來給這個內存對象創建一個狀態節點,說明它的狀態是 heap,計數器初始值是 0。
在執行 p1 = (int*)malloc(8) 時,給 p1 創建一個元數據,p1 的狀態節點指針也指向這一個狀態節點,計數器為 1,現在有一個指針指向它。接下來 p2=p1,給 p2 也創建一個指針元數據,記錄 base 和 bound,它的指針也指向這一個狀態節點,計數器變成 2。
接下來程序執行 free(p1),釋放堆中的內存,將狀態節點中的狀態從 heap 改成 invalid,表示它已經被釋放。
對 p2 進行解引用,監控算法會去檢查 p2 所指向的對象是否還存在于內存當中。結果發現狀態變成了 invalid,顯然這是一個已經被釋放的對象,所以工具會發現在訪問一個已經被釋放的內存對象,是一個時間錯誤。

內存泄露
在內存中分配一個堆中的對象,給它創建一個狀態節點,指針 p1、p2 的元數據指向這個狀態節點,計數器變成 2。
接下來使用 p1、p2 指向 i 的地址,i 是一個棧里面的變量,這時 i 的計數器變為 2,heap 的計數器變為 0。
這時監控算法會發現有一個堆中的狀態節點,計數器是 0,也沒有指針指向它,報出一個內存泄漏的錯誤。

## 算法數據結構
接下來,我會對 Smatus 算法中的基本數據結構做一個介紹。
為了檢測對象和子對象層面的空間錯誤,Smatus 算法會維護一個指針元數據 (pointer metadata, PMD) 的結構,包括所指向內存的 base 和 bound,還有一個指針指向內存塊的狀態節點。
typedefstruct{
void*base;
void*bound;
SND*snda;
}PMD;
Smatus 也會為每個內存對象維護一個狀態節點 (status node, SND)。狀態節點的結構包括一個記錄狀態的成員 stat,和一個引用計數的成員 count。狀態 stat 主要記錄內存塊是有效還是無效,是在堆中還是棧中等。引用計數 count 主要記錄有多少個指針指向它。
typedefenum{
function,...
}status;
typedefstruct{
statusstat;
size_tcount;
}SND;
對不同內存錯誤的檢查會用到不同的成員。若是檢查空間錯誤,主要使用 base 和 bound;如果檢查時間錯誤和段混淆錯誤,主要使用狀態 status;如果檢查內存泄漏錯誤,主要使用引用計數 count。
Smatus 也會為每個有指針參數或返回指針的函數創建并維護一個函數元數據 (function metadata, FMD)。當把一些指針傳到函數里面,或者是函數返回一個指針的時候,FMD 會儲存這個指針的元數據。
對于庫函數的調用,Smatus 也有一些特殊的處理。如果庫函數是有源代碼的,可以用工具直接插樁,不需要做額外的處理。如果沒有源代碼,是預編譯的,需要給它提供一些包裝函數 wrapper functions,并且在調用原始函數之前,檢查參數的 PMDs 以確保內存安全,在調用后更新存儲返回值的變量的 PMDs。
在 Movec 中,我們已經為 C 語言自帶的一些庫函數寫好了包裝函數,這部分是可以直接使用的。更多的技術細節在 ISSTA2021 [2] 的論文中,會具體描述監控算法是如何起作用的,此處不再贅述。
# 源代碼插樁框架
## 傳統基于 IR 的插樁框架
傳統的 IR 級別的插樁,會先定義三個基本的接口:
pmd_tbl_lookup() 主要用來查找元數據表,查詢元數據的狀態、base、bound 等
pmd_tbl_update() 主要用來更新元數據表,當給一個指針進行賦值的時候,需要更新它的元數據
check_dpv() 是當在對指針進行解引用的時候,用來檢查是否有產生內存錯誤
插樁過程舉例。
T *p; 定義一個指針 p,通過 pmd_tbl_update 更新 p 的元數據。
p = &i; 給 p 賦值,再次通過 pmd_tbl_update 更新 p 的元數據。根據 p 的地址索引到它的元數據,將元數據更新為 i 的狀態、起始地址、結束地址。
p1 = p; 需要將 p1 的元數據更新成和 p 的元數據一致。首先通過 pmd_tbl_lookup 找出 p 的元數據,存到 pmd 變量中,然后通過 pmd_tbl_update 將 pmd 更新到 p1 的元數據中,這樣 p1 就獲得了它所指向對象的元數據。
i = *p1; 最后對 p1 解引用之前,需要通過 check_dpv 檢查 p1 所指向的元數據和它要訪問的范圍。
T*p;/*orT*p=NULL*/ pmd_tbl_update(&p,NULL,NULL,NULL); p=&i; pmd_tbl_update(&p,i_status,&i,&i+1); p1=p;/*p1=p+iorp1=&p[i]*/ pmd=pmd_tbl_lookup(&p); pmd_tbl_update(&p1,pmd->status,pmd->base,pmd->bound); check_dpv(pmd_tbl_lookup(&p1),p1,sizeof(*p1)); i=*p1;/*or*p1=i*/
上述方法僅適用于基于 IR 的插樁 (比如 SSA 格式),如果要在源代碼上做插樁,該方法會帶來一些問題。
首先是內嵌的表達式。比如當兩個操作符寫在一個語句里面時,在 IR 級別,語句會被拆成兩個語句。我們可以在中間插入一些語句進行檢測。但是在源代碼級別,我們是無法在一個內嵌的語句中間插入一個語句的。
/*nestedexpressions*/ *(--p); /*attheIR-level*/ --p; /*wecaninsertacheckhere*/ /*whichisimpossibleatthesource-level*/ check_dpv(pmd_tbl_lookup(&p),p,sizeof(*p)); *p;
類似地,還有指針算術運算、副作用、內嵌的函數調用等問題。
## 源代碼插樁
那么如何解決上述問題?
第一步,我們需要將程序中所有可能出現指針的地方列出來。我們定義了一個系統的分類,如下所示,用以表示類型可能在什么地方出現。

Types and storage classes.
具體來說,表中 dlr 表示類型有可能出現在一個指針變量的定義處 (d - definition),還有可能出現在指針變量賦值表達式的左邊 (l - lhs),或者是一個賦值表達式的右邊 (r - rhs);e 表示指針的解引用 (e - dereference);vpa 表示函數的定義和調用處 (v - return value, p - parameter, a - argument)。除此之外,在結構體和數組當中,也可能包含指針,也需要考慮進去。
我們的源代碼插樁框架,主要是通過一個遞歸的 AST 訪問器來遍歷整個 AST,并在可能出現指針的地方進行插樁。
我們定義了很多的接口,包括一系列針對不同情況下更新元數據的方法、以及檢測的方法,這邊不再細述。
/*Interfacesofmetadatatables*/
/*Lookupforthepmdofapointervariablebyaddress.*/
PRFpmd*PRFpmd_tbl_lookup(ptr_addr);
/*Updatethepmdofapointervarusingstatus,baseandbound.*/
PRFpmd*PRFpmd_tbl_update_as(ptr_addr,status,base,bound);
/*Updatethepmdofapointervarandreturnthelastparam.*/
void*PRFpmd_tbl_update_as_ret(ptr_addr,status,base,bound,ret);
/*Updatethepmdofapointervarusingthepmdofanotherone.*/
PRFpmd*PRFpmd_tbl_update_ptr(ptr_addr,ptr_addr2);
/*Updatethepmdofapointervarandreturnthelastparam.*/
void*PRFpmd_tbl_update_ptr_ret(ptr_addr,ptr_addr2,ret);
/*Interfacesofcheckingpmd*/
/*Checkdereferencesofpointervariables.*/
void*PRFcheck_dpv(pmd,ptr,size,...){
stat=PRFpmd_get_stat(pmd);
/*Checkpointervalidity.*/
if(ptr==NULL)print_error();
/*Checktemporalsafety.*/
if(pmd==NULL||stat==PRFinvalid)print_error();
/*Checkspatialsafety.*/
if(ptrbase||ptr+size>pmd->bound)print_error();
returnptr;
}
/*Morecheckingfunctions*/
/*Checkdereferencesofpointerconstants.*/
void*PRFcheck_dpc(base,bound,ptr,size,...);
/*Checkdereferencesoffunctionpointervariables.*/
void*PRFcheck_dpfv(pmd,ptr,...);
/*Checkdereferencesoffunctionpointerconstants.*/
void*PRFcheck_dpfc(base,bound,ptr,...);
除此之外,還有幾個核心的操作。
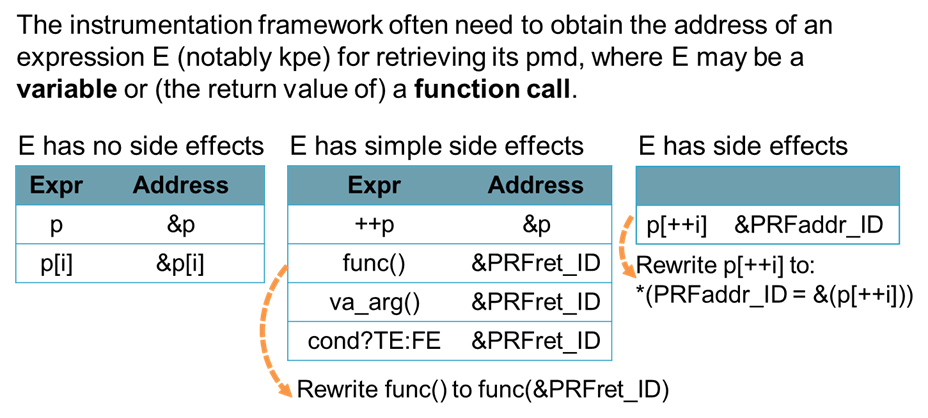
Getting KPE
第一個是獲得核心指針表達式的操作 (比如為了處理加法操作符),如下圖所示。在這一個表達式里面,實際上有三個指針 p、p1、p2,在插樁的時候,程序應該要能夠自動分析出 p 是指向 p1 所指向的對象,還是 p2 所指向的對象。這里需要使用靜態分析的方法,根據類型來進行推導,由于 p1 是一個指針,而 p2 是一個整數,所以右邊的表達式中最主要的表達式是 p1,因此 p 應該將其元數據更新為與 p1 一致。

Getting Address
第二個是獲得表達式的地址的操作。在存儲元數據時,是用指針的地址來作為索引的。所以在更新指針的時候,首先要獲得表達式的地址,才能更新它的元數據。簡單的變量是很好處理的,比如一個指針變量 p,地址就是 &p。同樣地,對于一個數組下標表達式,在前面加一個取地址符即可。
但對于一些復雜的情況,比如 ++p,我們需要先把 p 的地址給存起來 (而不是 ++p 的地址)。對于函數,我們會構造一個新變量 PRFret_ID 去存它的地址,并且將原函數 func() 重寫為 func(&PRFret_ID),得到函數返回值的地址,再去索引其函數返回值的元素。
Getting Status, Base, and Bound
類似地,對于一個指針常量,需要獲得它的狀態、基地址、上界,也是需要靜態分析去做的。

有了這些基本的分析以后,就解決了上文基于 IR 插樁中存在的挑戰。
當然,在開發的過程中,我們也面臨著一些設計上的選擇。比如使用了分離的元數據空間 disjoint metadata space,這可能會在運行時帶來更高的負載,但是它的兼容性更好。我們還使用了多種存儲元數據的方法,包括哈希表和 Trie 中。此外,還可以將一部分元數據當成變量存起來,這樣可以帶來更快的查找速度,一定程度上降低時間上的負載。
如果大家感興趣,可以去看我們 ISSTA 2019[1]、IEEE TSE 2022[3]的論文。
# 實驗結果 #
工具 Movec 實現了前述的技術。
我們在包括 SARD、MiBench、SPEC、以及自行構建的多個測試集上進行了大量測試,用以評估 Movec 的有效性和性能。
1197 benchmarks from Suites IDs 81, 88 and 89 of the NISTSoftware Assurance Reference Dataset (SARD).
124 benchmarks from a new suite to cover typical memory errors that are not included in the SARD.
20 MiBench benchmarks and 5 pure-C SPEC CPU 2017 benchmarks.
我們將 Movec 與三個最先進的工具進行比較,即谷歌的 ASan、SoCets 和Valgrind。
Movec 和相關實驗已通過了 Artifact Evaluation[8]。

實驗結果如下。
在檢測能力 (即有效性) 方面,Movec 在 SARD 測試集中找出了全部錯誤,而其他的工具或多或少都會漏掉一些。此外,在打開編譯器 O3 優化的情況下,Movec 依然不受影響地找出了全部錯誤,但是其他的工具找到的錯誤會大幅度減少。在其他的測試集上,Movec 找到的錯也是最多的。
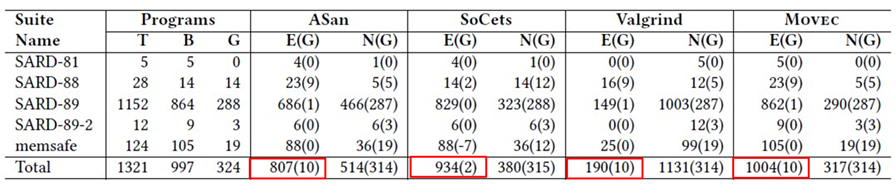
在性能方面,ASan 的速度可能會更快一些,但是它耗費的內存比 Movec 要多。而相比 SoCets 和 Valgrind,Movec 在速度和內存方面都更優。
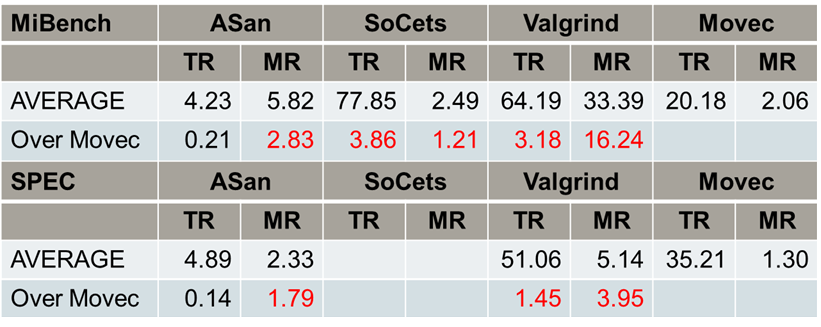
在可用性方面,Movec 支持跨平臺,并且報錯友好度更高。

# 總結 #
本次分享中,我們提出了一種新的、全面的智能監測算法 Smatus,其中智能的狀態是這個方法的核心。Smatus 可以同時檢測空間錯誤、時間錯誤、段混淆錯誤和內存泄漏。
我們還提出了一種新的基于源碼級的插樁框架,并從中獲得了很多好處,比如找到了更多的錯誤、優化不敏感、支持跨平臺、報錯友好度更高等。
實驗結果表明,Movec 有著更強的錯誤查找能力和可用性,并且開銷適中。
審核編輯:湯梓紅
-
內存
+關注
關注
8文章
3055瀏覽量
74327 -
源代碼
+關注
關注
96文章
2946瀏覽量
66953 -
C程序
+關注
關注
4文章
255瀏覽量
36131
原文標題:基于智能狀態和源代碼插樁的 C 程序內存安全性動態分析
文章出處:【微信號:編程語言Lab,微信公眾號:編程語言Lab】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
nios如何保證安全性的
邊緣智能的邊緣節點安全性
安全閃存鑄就高安全性智能卡
如何支持物聯網安全性和低功耗要求設計
藍牙mesh系列的網絡安全性
lc72130的應用C程序源代碼
KIOCWORK:通過源代碼分析保證軟件安全性
動態路由協議安全性分析







 工商網監
工商網監
評論