 數據中心手動操作關閉復制并開始使用
數據中心手動操作關閉復制并開始使用
在數據中心A中,ArangoDB集群A照常運行,不修改其代碼庫和API,并提供其正常負載。同樣,在數據中心B中,部署了第二個ArangoDB集群B,但最初處于空閑狀態。
在這兩個數據中心中,我們都部署了Kafka消息代理,這是一個標準的高性能容錯排隊系統,能夠在其消息隊列中緩沖大量數據。在卡夫卡中,單個隊列被稱為“主題”。這些主題可以從其他數據中心使用。卡夫卡有一定的保證,因此在網絡問題、個別中斷等情況下,不會丟失任何消息,遠程數據中心始終保持一致狀態。
此外,在每個數據中心中,都有幾個名為“ArangoDBSyncMaster”的程序實例。在每個數據中心,同步主機選擇一個負責人,負責人與另一個數據中心的同步主機對話,以組織復制。“組織”在這里意味著它計劃了必須在兩個數據中心中執行的單個任務,以使復制得以進行。從本質上講,我們必須復制元信息,如數據庫、集合和用戶的存在,以及切分集合中的實際數據。
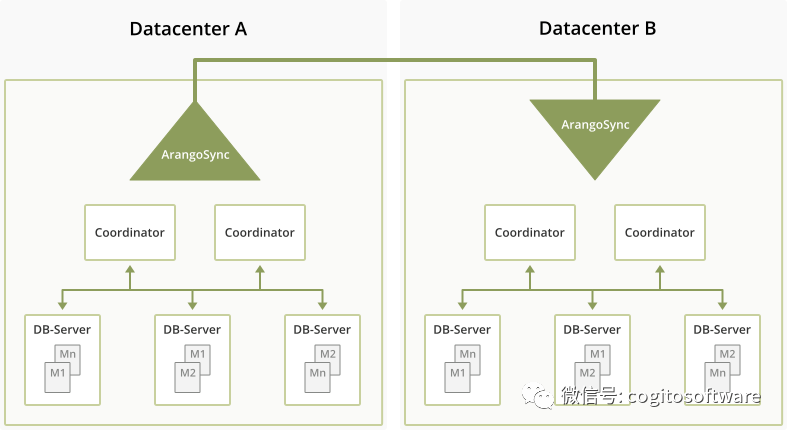
在每個數據中心,領先的SyncMaster領導一小群SyncWorker,他們執行實際的復制任務。例如,對于集合的每個碎片,數據中心a中有一個“發送碎片”任務,數據中心B中有一項“接收碎片”任務。所有這些碎片都由SyncMaster分配給某個SyncWorker。
這些任務負責初始增量同步階段(運行我們在ArangoDB中已有的現有分片同步協議),以及稍后的更新階段,在更新階段中,對分片的所有更新都復制到其他數據中心(在數據中心A中使用WAL-tailing)。
數據流如下:它從ArangoDB集群的某個數據庫服務器開始,到達數據中心A中的一個SyncWorker,然后進入數據中心A的Kafka。從那里,它將被數據中心B的SyncWorkers消耗,后者將其寫入數據中心B中的協調器。顯然,有一些控制消息朝相反的方向流動。這些控制消息將由數據中心A從數據中心B中的Kafka服務器中提取。
這對管理員來說都意味著,在初始部署后,只需告訴數據中心B中的SyncMaster它應該開始遵循數據中心A中的群集A,就可以用一個命令設置異步復制。從那時起,一切都是完全自動的,所有數據庫、集合、用戶和權限都會自動復制到另一個數據中心。顯然,有監控和配置設施,但本質上就是這樣。
局限性
這是實現多數據中心意識的第一步,因此自然會有局限性。首先,復制是異步的,因此它總是落后于數據中心a中的實際事件。通常情況下,由于良好的連接性和小于跨數據中心鏈路容量的寫入速率,這種延遲非常小。然而,應該注意,在突然停止復制并手動切換到集群B的情況下,一些最近編寫的更新可能會丟失。
整個設置是手動配置的,在兩個數據中心之間工作。在此階段不允許寫入副本群集。然而,副本群集可以同時作為另一個數據中心的源,并且源群集可以具有多個副本。也就是說,您可以形成數據中心樹。
最后,到目前為止,關閉復制并開始使用復制副本是一種手動操作,需要管理員做出決定和采取行動。
-
服務器
+關注
關注
12文章
9308瀏覽量
86071 -
數據中心
+關注
關注
16文章
4860瀏覽量
72384 -
數據庫
+關注
關注
7文章
3848瀏覽量
64688
原文標題:ArangoDB Enterprise—數據中心到數據中心的復制(下)
文章出處:【微信號:哲想軟件,微信公眾號:哲想軟件】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據中心子系統的組成
數據中心的健康檢查(電氣篇)
走向綠色數據中心的7種手段
數據中心的建設也看重風水
數據中心光互聯解決方案
未來數據中心與光模塊發展假設
數據中心太耗電怎么辦
數據中心是什么
PUE指標能準確衡量數據中心能效嗎?
什么是數據中心
數據中心網絡進行監控和管理如何操作
數據中心到數據中心的復制流程





 工商網監
工商網監
評論