 摘要模型理解或捕獲輸入文本的要點
摘要模型理解或捕獲輸入文本的要點
Abstract & Intro
盡管基于預訓練的語言模型的摘要取得了成功,但一個尚未解決的問題是生成的摘要并不總是忠實于輸入文檔。造成不忠實問題的原因可能有兩個: (1)摘要模型未能理解或捕獲輸入文本的要點; (2)模型過度依賴語言模型,生成流暢但不充分的單詞。 在本文研究中,提出了一個忠實增強摘要模型(FES),旨在解決這兩個問題,提高抽象摘要的忠實度。對于第一個問題,本文使用問答(QA)來檢查編碼器是否完全掌握輸入文檔,并能夠回答關于輸入中的關鍵信息的問題。QA 對適當輸入詞的注意也可以用來規定解碼器應該如何處理輸入。 對于第二個問題,本文引入了一個定義在語言和總結模型之間的差異上的最大邊際損失,目的是防止語言模型的過度自信。在兩個基準總結數據集(CNN/DM 和 XSum)上的大量實驗表明,本文的模型明顯優于強基準。事實一致性的評估也表明,本文的模型生成的摘要比基線更可靠。
本文的主要貢獻如下: 1. 提出了一種信度增強摘要模型,從編碼器端和解碼器端都緩解了不信度問題。 2. 提出了一個多任務框架,通過自動 QA 任務來提高摘要性能。還提出了一個最大邊際損失來控制 LM 的過度自信問題。 3. 實驗結果表明,與基準數據集上的最新基線相比,本文提出的方法帶來了實質性的改進,并可以提高生成摘要的忠實度。
Model Architecture
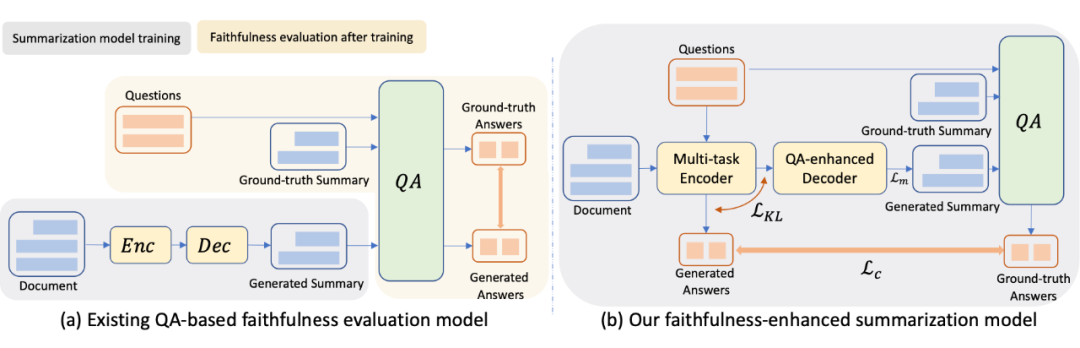
本文從三個方面實現了信度的提高: (1)多任務編碼器。它通過檢查輔助 QA 任務的編碼文檔表示的質量,提高了對輸入文檔的語義理解。編碼的表示因此捕獲關鍵輸入,以便做出忠實的總結。 (2)QA 注意增強解碼器。來自多任務編碼器的注意使解碼器與編碼器對齊,以便解碼器能夠獲取更準確的輸入信息以生成摘要。 (3)Max-margin 損失。這是一個與代損耗正交的損耗。它測量 LM 的準確性,防止它在生成過程中過度自信。
 ? ?
? ?
2.1 Multi-task Encoder
多任務編碼器設計用于對輸入文檔進行編碼,以便在集成訓練過程中進行摘要和問題回答,如圖 1(b)所示。這與之前的工作不同,之前的工作是在后期階段使用 QA 來評估生成摘要的忠實度,如圖 1(a)所示。本文讓 QA 更接近編碼器,而不是把它留給后生成的總結,并讓編碼器接受訓練,同時完成 QA 和總結任務。在多任務編碼器的綜合訓練中,除了摘要生成質量外,還將忠實度作為優化目標,答案是來自文檔的關鍵實體,因此 QA 對關注輸入中的關鍵信息。 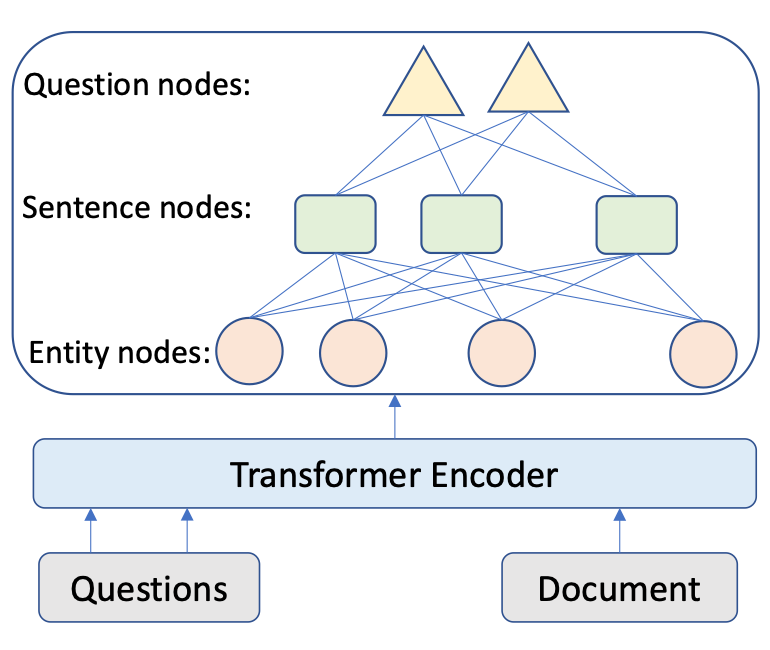
如圖 2 所示,我們首先應用經典的 Transformer 架構,獲得文檔和問題的 token 表示, 和 ,然后設計編碼器,從實體層和句子層理解問題和輸入文檔問題。
Encoding at Multi-level Granularity 本文通過在不同粒度級別組織表示學習來構建編碼器。我們使用實體作為基本語義單位,因為它們包含貫穿全文的緊湊而突出的信息,而閱讀理解題的重點是實體。由于問題通常很短,本文為每個問題創建一個節點。本文將雙向邊從問題添加到句子節點,從句子添加到實體節點。這些節點作為句與句之間的中介,豐富了句與句之間的關系。由于初始的有向邊不足以學習反向信息,本文在前面的工作的基礎上,在圖中添加了反向邊和自環邊。 在構造了具有節點特征的圖之后,使用圖注意網絡來更新語義節點的表示,圖注意層(GAT)設計如下:
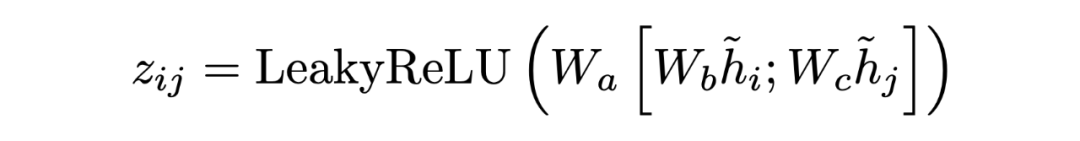
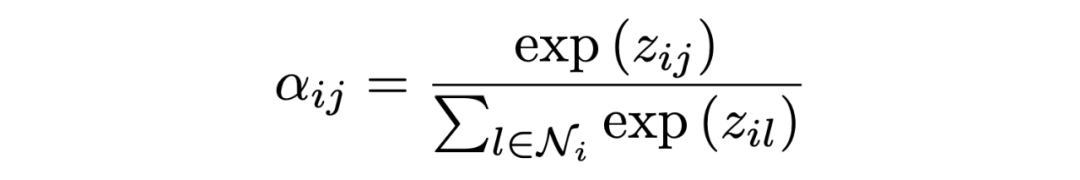
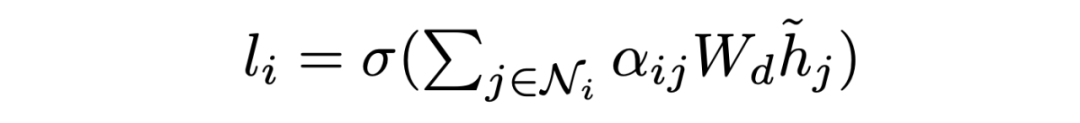
其中 是輸入節點的隱藏狀態,其中 N 是節點 i 的相鄰節點集, 是可訓練權值, 是 和 之間的注意權值。輸出實體特征矩陣、句子特征矩陣和問題矩陣:。 Answer Selector for the QA task 在融合來自問題和文檔的信息之后,可以從文檔中選擇實體作為問題的答案。具體來說,本文在問題和圖中的實體之間應用了多頭交叉注意以獲得識別問題的實體表示:=MHAtt(),i 是問題索引。本文采用前饋網絡(FFN)生成實體提取概率 ,QA 的目標是最大限度地提高所有基本事實實體標簽的可能性: 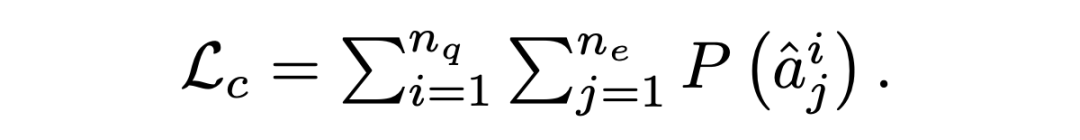
2.2 QA Attention-enhanced Decoder
一個忠實的解碼器需要注意并從編碼器中獲取重要的內容,而不是混合輸入。QA 對關鍵實體的關注可以被視為重要信號,表明哪些實體應該包含在摘要中。因此,本文提出了一個由 QA 關注增強的摘要生成器。一般來說,以實體為中介的解碼器狀態關注編碼器狀態,其中實體級別的注意由 QA 注意指導。
具體來說,對于每一層,在第 t 步解碼時,我們對 masked 摘要嵌入矩陣E進行自注意,得到 。基于 ,我們計算實體的交叉注意分數 。 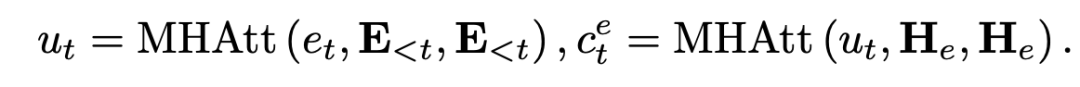 ? 實際上,第一個注意層捕獲已解碼序列的上下文特征,而第二層則包含 中的實體信息.我們最小化在第 t 步的實體上的 QA 注意 Ai 和摘要注意 Et 之間的 KL 散度,以幫助總結模型了解哪些實體是重要的:
? 實際上,第一個注意層捕獲已解碼序列的上下文特征,而第二層則包含 中的實體信息.我們最小化在第 t 步的實體上的 QA 注意 Ai 和摘要注意 Et 之間的 KL 散度,以幫助總結模型了解哪些實體是重要的:
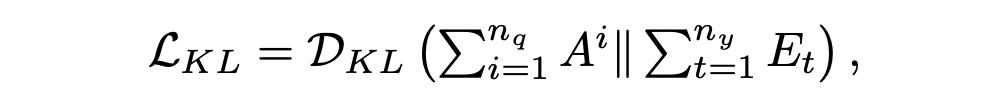
然后,通過在源詞序列 Hw 和 上應用另一個 MHAtt 層,我們使用實體級注意來指導與關鍵實體相關的源標記的選擇:
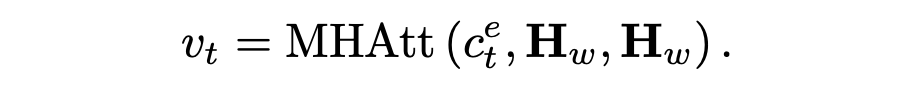
該上下文向量 vt 被視為從各種來源總結的顯著內容,被發送到前饋網絡以生成目標詞匯表的分布,即 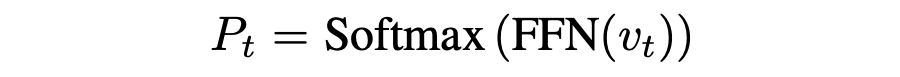 ? 通過優化預測目標詞的負對數似然目標函數,更新所有可學習參數
? 通過優化預測目標詞的負對數似然目標函數,更新所有可學習參數 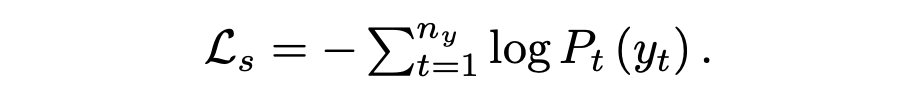
2.3 Max-margin Loss
信息不充分的解碼器會忽略一些源段,更像是一個開放的 LM,因此容易產生外部錯誤。受信度增強機器翻譯工作的啟發,本文在摘要任務中引入了一個 max-margin loss,以使摘要模型的每個 token 與 LM 的預測概率的差值最大化,如圖 3 所示,這抑制了摘要器產生常見但不忠實的單詞的趨勢。 
▲ 當 LM 不夠準確時,本文的模型可以通過最大邊際損失防止 LM 的過度自信,預測出正確的目標詞,而基線模型則不能。
具體來說,我們首先將摘要模型和 LM 之間的差值定義為預測概率的差值:
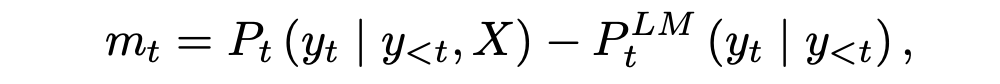
其中 X 為輸入文檔, 表示 LM 的第 t 個令牌的預測概率。如果 mt 很大,那么總結模型顯然比 LM 好。當 mt 很小的時候,有兩種可能。一是 LM 模型和總結模型都有很好的性能,因此預測的概率應該是相似的。另一種可能是 LM 不夠好,但過于自信,這會導致總結器性能不佳。LM 夠好,但過于自信,這會導致總結器性能不佳。 本文給出了最大邊際損失 Lm,它在邊際上增加了一個系數
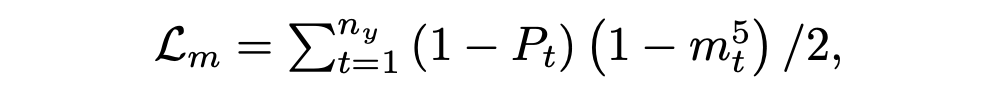
當 Pt 較大時,摘要模型可以很好地學習,不需要過多關注 mt。這體現在 mt 的小系數(1?Pt)上。另一方面,當 Pt 較小時,意味著摘要器需要更好地優化,大系數(1?Pt)使模型能夠從邊際信息中學習。
、、、 這四種損耗是正交的,可以組合使用來提高信度。
Experiment
3.1 Dataset
本文在兩個公共數據集(CNN/DM 和 XSum)上演示了方法的有效性,這兩個公共數據集在以前的摘要工作中被廣泛使用。這兩個數據集都基于新聞,由大量事件、實體和關系組成,可用于測試摘要模型的事實一致性。
本文的摘要模型伴隨著一個 QA 任務。因此,使用由 QuestEval 工具為每個用例預先構建 QA 對。
3.2 Result
Automatic Evaluation
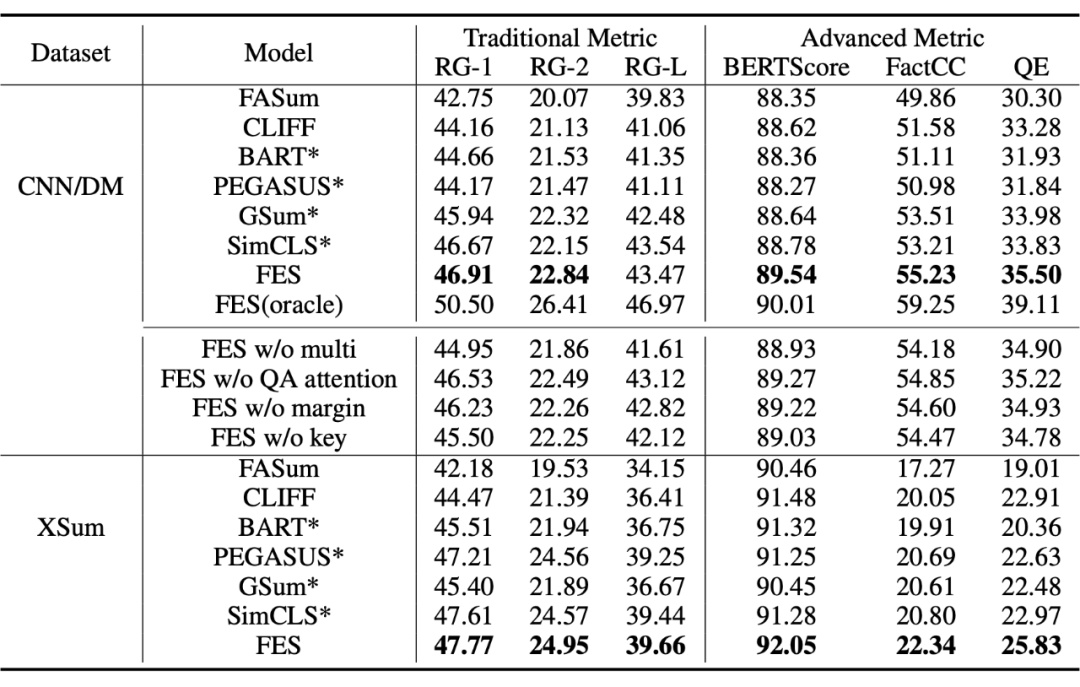 ▲ QE 加權 F1 分數
▲ QE 加權 F1 分數
當使用 oracle QA(黃金問答)對評估 QA 任務帶來的效益的上限時,我們還展示了我們的模型在測試數據集上的性能。我們可以看到,oracle 顯著地提高了性能,性能最好的模型達到了50.50 的 ROUGE-1 評分。結果表明:1)如果有較好的 QA 對,模型性能有進一步提高的潛力;2)輔助 QA 任務確實對模型有幫助。
Human Evaluation

▲ 在 CNN/DM 數據集上,比 BART 差、持平或更好的摘要的百分比。XSum 數據集上比 PEGASUS 差、與 PEGASUS 持平或優于 PEGASUS 的摘要的百分比
Ablation Study
1. 沒有多任務框架,各項指標都有所下降,表明在使用 QA 多任務時,編碼器確實增強了學習更全面表示的能力。
2. QA 注意指導被移除后,QE 分數下降了 0.28。這表明,將 QA 注意與重要實體的摘要注意對齊,可以幫助模型從輸入中捕獲要點信息,而將這種損失限制在有限部分實體上,可以引導解碼器從輸入中獲取有意義的內容。
3. 除去最大邊際損失后,FactCC 評分下降了 0.63。這表明,防止 LM 過度自信有助于提高信任度。
4. 最后,當使用隨機 QA 對作為引導時,FES 的性能有所下降,但大大優于 BART。這表明,加強對文檔的理解是有幫助的,即使它并不總是與關鍵信息相關。但是,通過對關鍵實體提出問題,可以進一步提高性能。
The Number of QA pairs
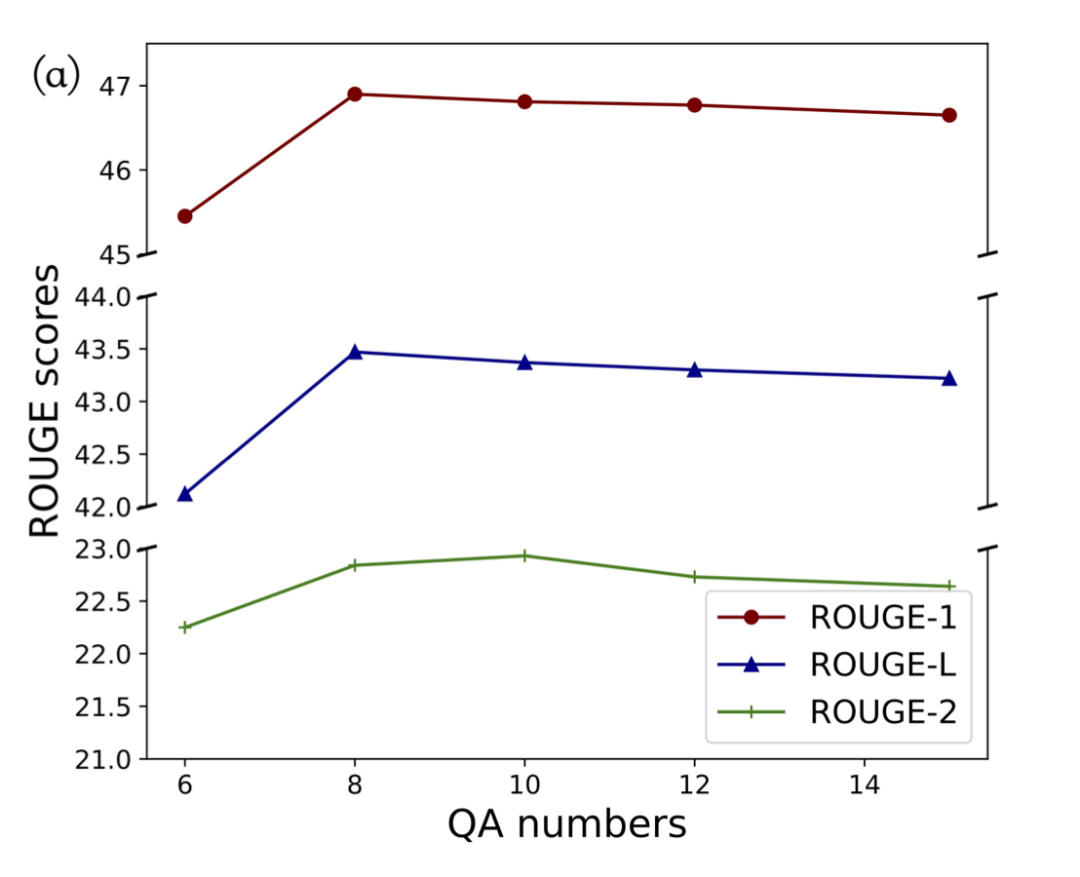 ? 首先看到 ROUGE 分數隨著 QA 對的數量而增加。達到 8 之后,這種改善開始消失。一個可能的原因是,答案不再關注文檔中的重要信息。注意,FES 的性能在 8-15 個 QA 對范圍內保持在較高水平,證明了 FES 的有效性和魯棒性。最后,我們選擇在模型中默認包含 8 個 QA 對。
? 首先看到 ROUGE 分數隨著 QA 對的數量而增加。達到 8 之后,這種改善開始消失。一個可能的原因是,答案不再關注文檔中的重要信息。注意,FES 的性能在 8-15 個 QA 對范圍內保持在較高水平,證明了 FES 的有效性和魯棒性。最后,我們選擇在模型中默認包含 8 個 QA 對。
Margin between FES and the LM
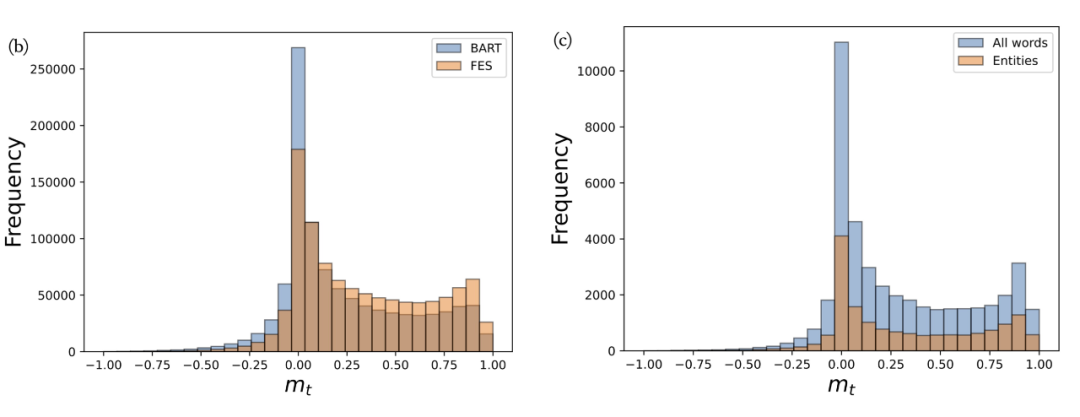
▲ 負 mt 為過度自信,mt 為 0 和 1 時模型準確 首先,圖(b)中 BART 仍然有很多 mt 為負的 token,并且有大量 mt 在 0 附近,這說明 LM 對于很多令牌可能是過度自信的。與 BART 相比,FES 降低了 2.33% 的負 mt,提高了 0.11 點的平均 mt。這證明 LM 的過度自信問題在很大程度上得到了解決。此外,我們在圖(c)中繪制了 mt 在所有單詞和實體單詞上的比較。可以看出,實體詞在 0 左右的比例明顯降低,驗證了我們的假設,LM 對于很多虛詞是準確的。
Conclucion
本文提出了具有最大邊際損失的多任務框架來生成可靠的摘要。輔助問答任務可以增強模型對源文檔的理解能力,最大邊際損失可以防止 LM 的過度自信。實驗結果表明,該模型在不同的數據集上都是有效的。
-
編碼器
+關注
關注
45文章
3669瀏覽量
135246 -
語言模型
+關注
關注
0文章
538瀏覽量
10341 -
數據集
+關注
關注
4文章
1209瀏覽量
24834
原文標題:NIPS'22 | 如何提高生成摘要的忠實度?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
基于統計和理解的自動摘要方法

一種基于多任務聯合訓練的閱讀理解模型

基于圖集成模型的自動摘要生產方法

基于多層CNN和注意力機制的文本摘要模型


基于語義感知的中文短文本摘要生成技術
基于LSTM的表示學習-文本分類模型
輸入捕獲-獲取一個高電平的持續時間

如何使用BERT模型進行抽取式摘要





 工商網監
工商網監
評論