 groupby功能的大多數用例
groupby功能的大多數用例
groupby是Pandas在數據分析中最常用的函數之一。它用于根據給定列中的不同值對數據點(即行)進行分組,分組后的數據可以計算生成組的聚合值。 如果我們有一個包含汽車品牌和價格信息的數據集,那么可以使用groupby功能來計算每個品牌的平均價格。 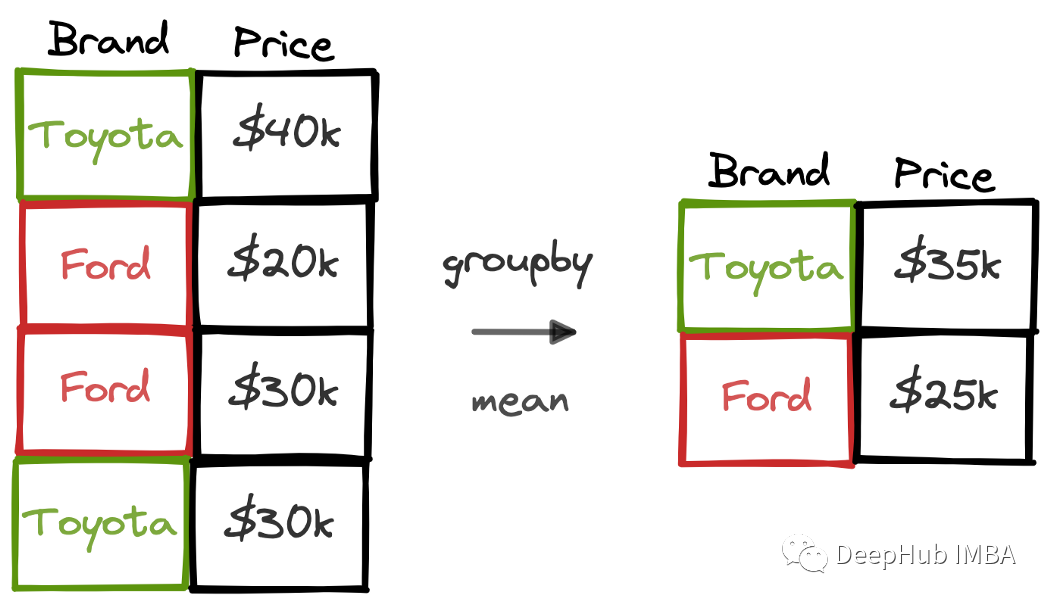 在本文中,我們將使用25個示例來詳細介紹groupby函數的用法。這25個示例中還包含了一些不太常用但在各種任務中都能派上用場的操作。 這里使用的數據集是隨機生成的,我們把它當作一個銷售的數據集。
在本文中,我們將使用25個示例來詳細介紹groupby函數的用法。這25個示例中還包含了一些不太常用但在各種任務中都能派上用場的操作。 這里使用的數據集是隨機生成的,我們把它當作一個銷售的數據集。
importpandasaspd sales=pd.read_csv("sales_data.csv") sales.head()
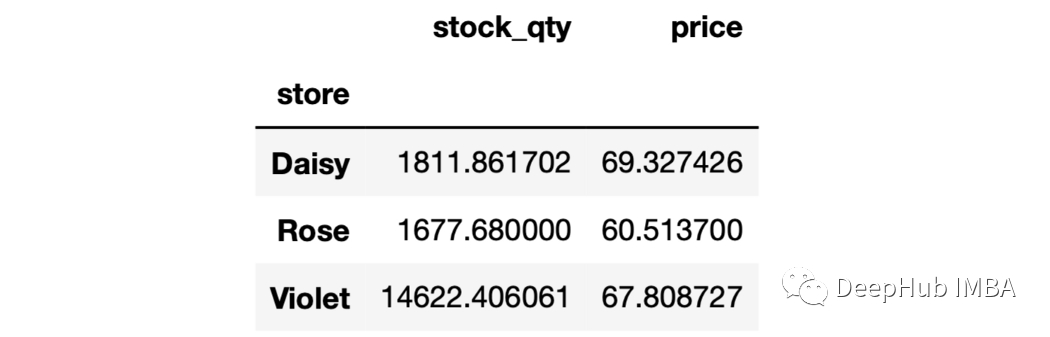
 1、單列聚合 我們可以計算出每個店鋪的平均庫存數量如下:
1、單列聚合 我們可以計算出每個店鋪的平均庫存數量如下:
sales.groupby("store")["stock_qty"].mean()
#輸出
store
Daisy1811.861702
Rose1677.680000
Violet14622.406061
Name:stock_qty,dtype:float64
2、多列聚合
在一個操作中進行多個聚合。以下是我們如何計算每個商店的平均庫存數量和價格。
sales.groupby("store")[["stock_qty","price"]].mean()sales.groupby("store")[["stock_qty","price"]].mean()
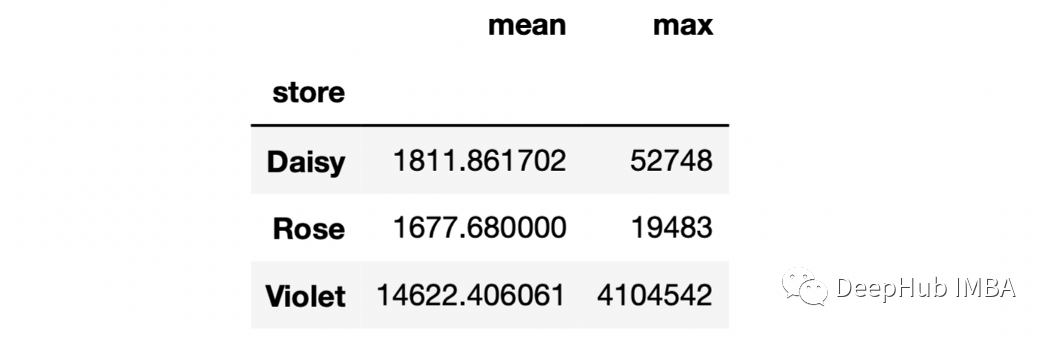
 3、多列多個聚合 我們還可以使用agg函數來計算多個聚合值。
3、多列多個聚合 我們還可以使用agg函數來計算多個聚合值。
sales.groupby("store")["stock_qty"].agg(["mean","max"])
 4、對聚合結果進行命名 在前面的兩個示例中,聚合列表示什么還不清楚。例如,“mean”并沒有告訴我們它是什么的均值。在這種情況下,我們可以對聚合的結果進行命名。
4、對聚合結果進行命名 在前面的兩個示例中,聚合列表示什么還不清楚。例如,“mean”并沒有告訴我們它是什么的均值。在這種情況下,我們可以對聚合的結果進行命名。
sales.groupby("store").agg(
avg_stock_qty=("stock_qty","mean"),
max_stock_qty=("stock_qty","max")
)
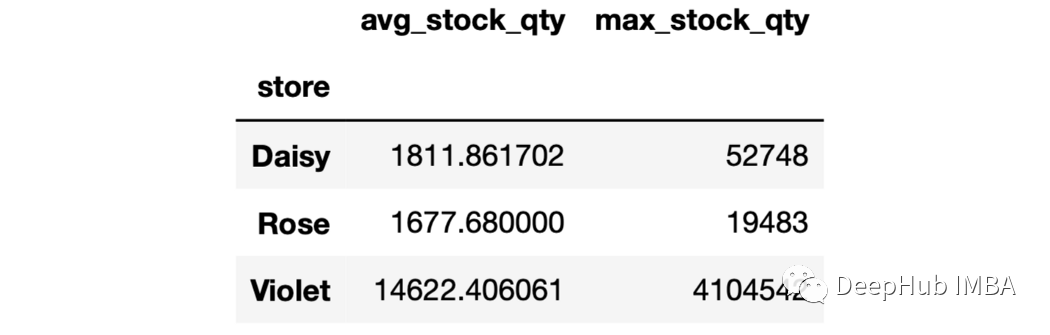 要聚合的列和函數名需要寫在元組中。 5、多個聚合和多個函數
要聚合的列和函數名需要寫在元組中。 5、多個聚合和多個函數
sales.groupby("store")[["stock_qty","price"]].agg(["mean","max"])
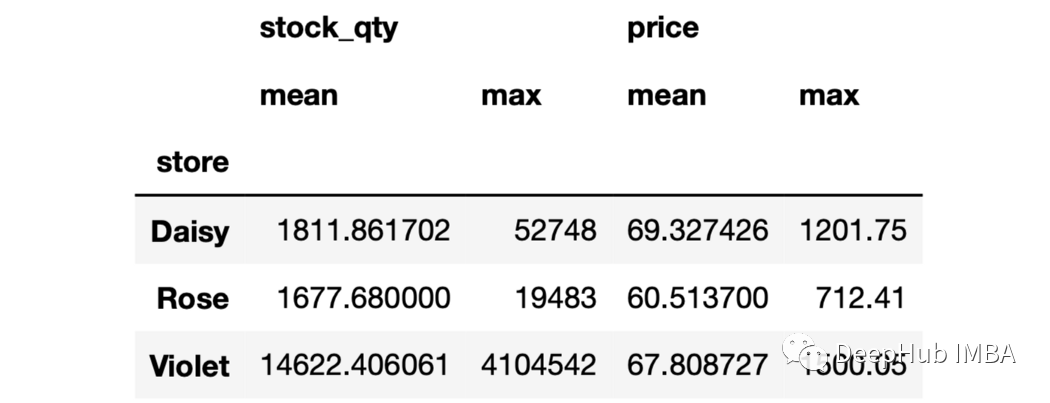
6、對不同列的聚合進行命名
sales.groupby("store").agg(
avg_stock_qty=("stock_qty","mean"),
avg_price=("price","mean")
)
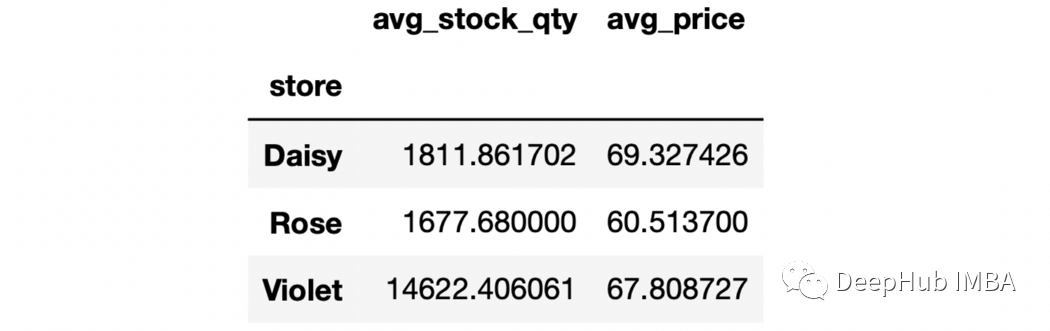 7、as_index參數 如果groupby操作的輸出是DataFrame,可以使用as_index參數使它們成為DataFrame中的一列。
7、as_index參數 如果groupby操作的輸出是DataFrame,可以使用as_index參數使它們成為DataFrame中的一列。
sales.groupby("store",as_index=False).agg(
avg_stock_qty=("stock_qty","mean"),
avg_price=("price","mean")
)
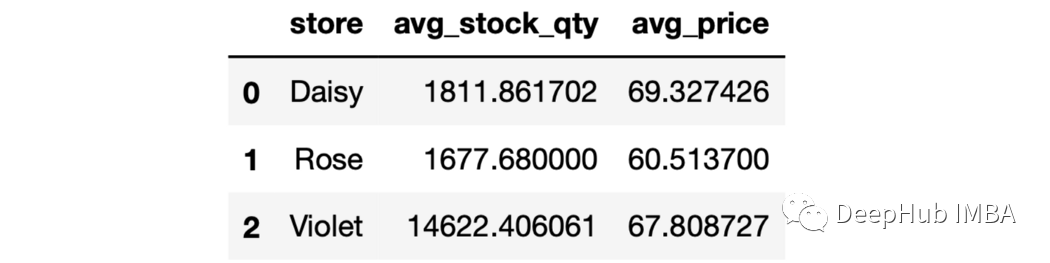 8、用于分組的多列 就像我們可以聚合多個列一樣,我們也可以使用多個列進行分組。
8、用于分組的多列 就像我們可以聚合多個列一樣,我們也可以使用多個列進行分組。
sales.groupby(["store","product_group"],as_index=False).agg(
avg_sales=("last_week_sales","mean")
).head()
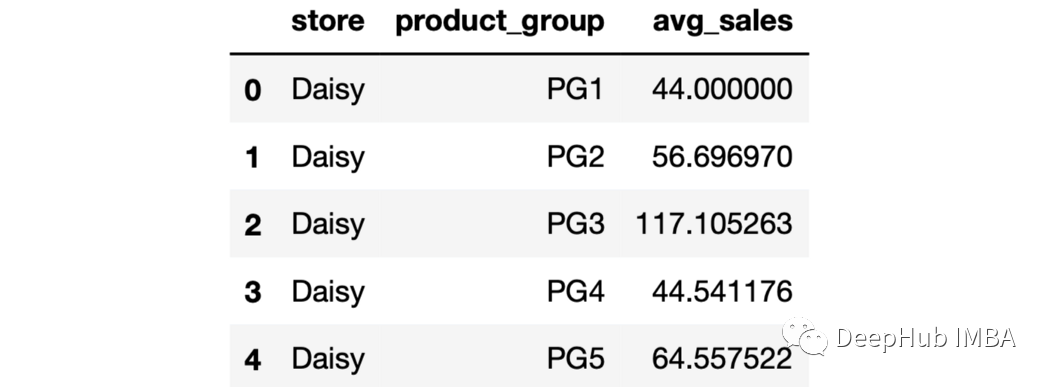 每個商店和產品的組合都會生成一個組。 9、排序輸出 可以使用sort_values函數根據聚合列對輸出進行排序。
每個商店和產品的組合都會生成一個組。 9、排序輸出 可以使用sort_values函數根據聚合列對輸出進行排序。
sales.groupby(["store","product_group"],as_index=False).agg(avg_sales=("last_week_sales","mean")
).sort_values(by="avg_sales",ascending=False).head()
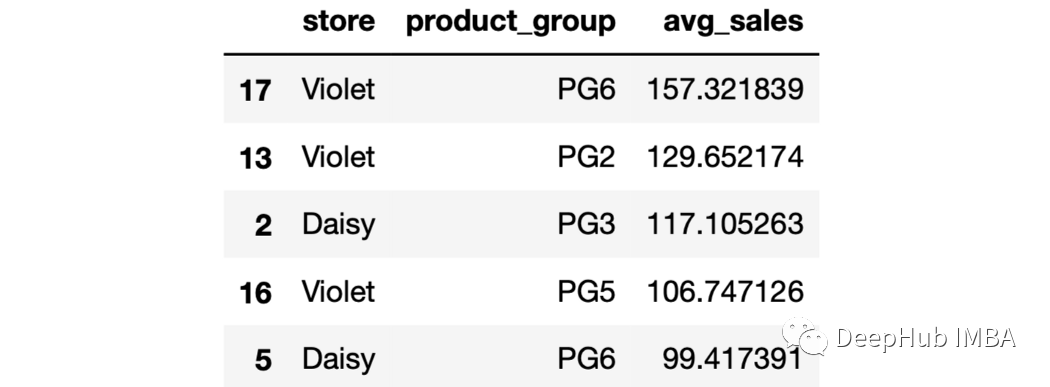 這些行根據平均銷售值按降序排序。 10、最大的Top N max函數返回每個組的最大值。如果我們需要n個最大的值,可以用下面的方法:
這些行根據平均銷售值按降序排序。 10、最大的Top N max函數返回每個組的最大值。如果我們需要n個最大的值,可以用下面的方法:
sales.groupby("store")["last_week_sales"].nlargest(2)
store
Daisy4131883
231947
Rose948883
263623
Violet9913222
3392690
Name:last_week_sales,dtype:int64
11、最小的Top N
與最大值相似,也可以求最小值
sales.groupby("store")["last_week_sales"].nsmallest(2)
12、第n個值
除上面2個以外,還可以找到一組中的第n個值。
sales_sorted=sales.sort_values(by=["store","last_month_sales"],ascending=False,ignore_index=True)
找到每個店鋪上個月銷售排名第五的產品如下:
sales_sorted.groupby("store").nth(4)
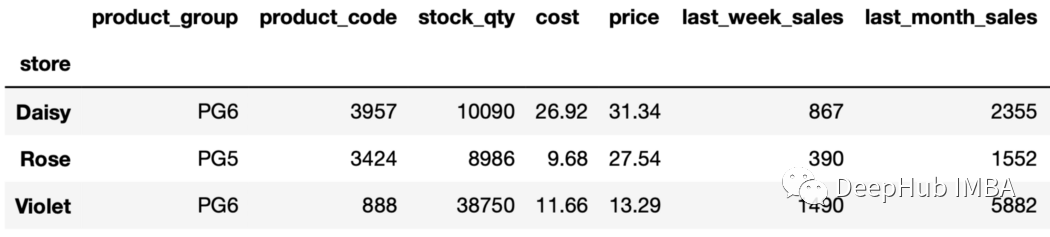 輸出包含每個組的第5行。由于行是根據上個月的銷售值排序的,所以我們將獲得上個月銷售額排名第五的行。 13、第n個值,倒排序 也可以用負的第n項。例如," nth(-2) "返回從末尾開始的第二行。
輸出包含每個組的第5行。由于行是根據上個月的銷售值排序的,所以我們將獲得上個月銷售額排名第五的行。 13、第n個值,倒排序 也可以用負的第n項。例如," nth(-2) "返回從末尾開始的第二行。
sales_sorted.groupby("store").nth(-2)
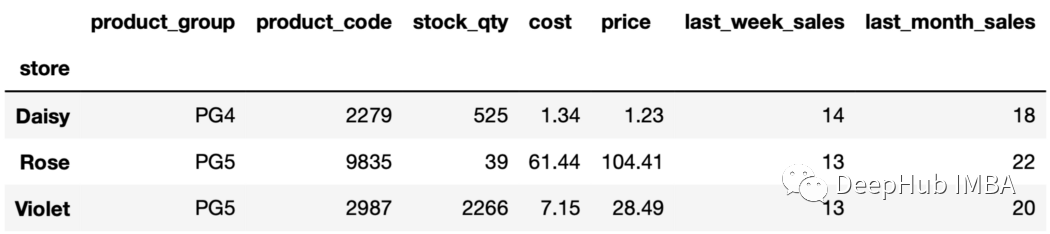 14、唯一值 unique函數可用于查找每組中唯一的值。例如,可以找到每個組中唯一的產品代碼如下:
14、唯一值 unique函數可用于查找每組中唯一的值。例如,可以找到每個組中唯一的產品代碼如下:
sales.groupby("store",as_index=False).agg(
unique_values=("product_code","unique")
)
 15、唯一值的數量 還可以使用nunique函數找到每組中唯一值的數量。
15、唯一值的數量 還可以使用nunique函數找到每組中唯一值的數量。
sales.groupby("store",as_index=False).agg(
number_of_unique_values=("product_code","nunique")
)
 16、Lambda表達式 可以在agg函數中使用lambda表達式作為自定義聚合操作。
16、Lambda表達式 可以在agg函數中使用lambda表達式作為自定義聚合操作。
sales.groupby("store").agg(
total_sales_in_thousands=(
"last_month_sales",
lambdax:round(x.sum()/1000,1)
)
)
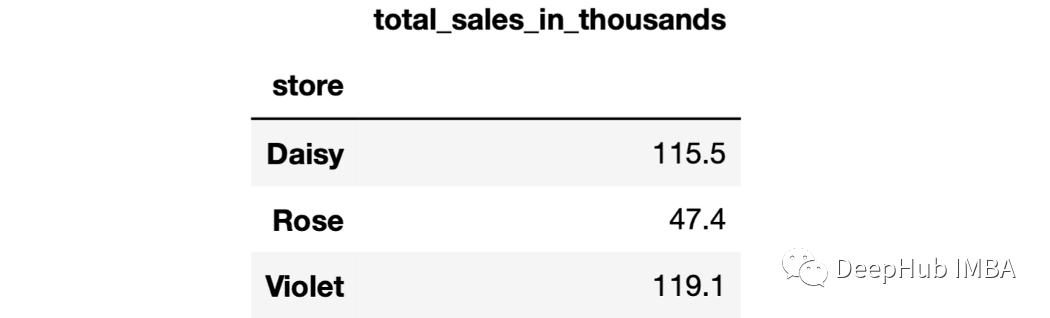 17、apply函數 使用apply函數將Lambda表達式應用到每個組。例如,我們可以計算每家店上周銷售額與上個月四分之一銷售額的差值的平均值,如下:
17、apply函數 使用apply函數將Lambda表達式應用到每個組。例如,我們可以計算每家店上周銷售額與上個月四分之一銷售額的差值的平均值,如下:
sales.groupby("store").apply(
lambdax:(x.last_week_sales-x.last_month_sales/4).mean()
)
store
Daisy5.094149
Rose5.326250
Violet8.965152
dtype:float64
18、dropna
缺省情況下,groupby函數忽略缺失值。如果用于分組的列中缺少一個值,那么它將不包含在任何組中,也不會單獨顯示。所以可以使用dropna參數來改變這個行為。 讓我們首先添加一個缺少存儲值的新行。
sales.loc[1000]=[None,"PG2",10000,120,64,96,15,53]
然后計算帶有dropna參數和不帶有dropna參數的每個商店的平均價格,以查看差異。
sales.groupby("store")["price"].mean()
store
Daisy69.327426
Rose60.513700
Violet67.808727
Name:price,dtype:float64
看看設置了缺失值參數的結果:
sales.groupby("store",dropna=False)["price"].mean()
store
Daisy69.327426
Rose60.513700
Violet67.808727
NaN96.000000
Name:price,dtype:float64
groupby函數的dropna參數,使用pandas版本1.1.0或更高版本。 19、求組的個數 有時需要知道生成了多少組,這可以使用ngroups。
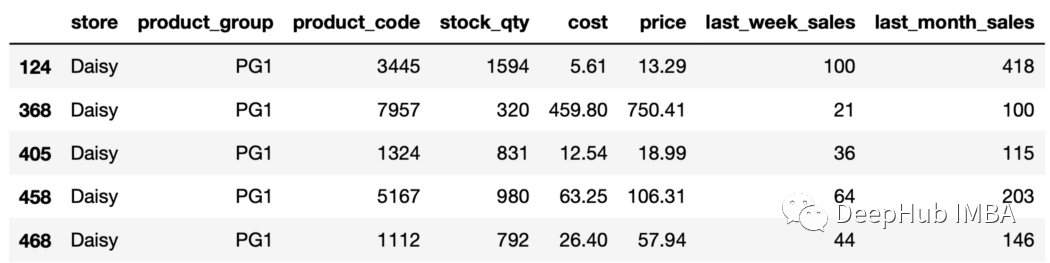
sales.groupby(["store","product_group"]).ngroups 18在商店和產品組列中有18種不同值的不同組合。 20、獲得一個特定分組 get_group函數可獲取特定組并且返回DataFrame。 例如,我們可以獲得屬于存儲“Daisy”和產品組“PG1”的行如下:
aisy_pg1=sales.groupby( ["store","product_group"]).get_group(("Daisy","PG1") ) daisy_pg1.head()
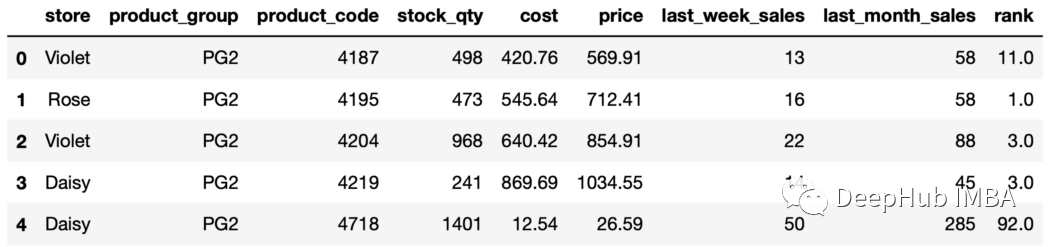
 21、rank函數 rank函數用于根據給定列中的值為行分配秩。我們可以使用rank和groupby函數分別對每個組中的行進行排序。
21、rank函數 rank函數用于根據給定列中的值為行分配秩。我們可以使用rank和groupby函數分別對每個組中的行進行排序。
sales["rank"]=sales.groupby("store"["price"].rank(
ascending=False,method="dense"
)
sales.head()
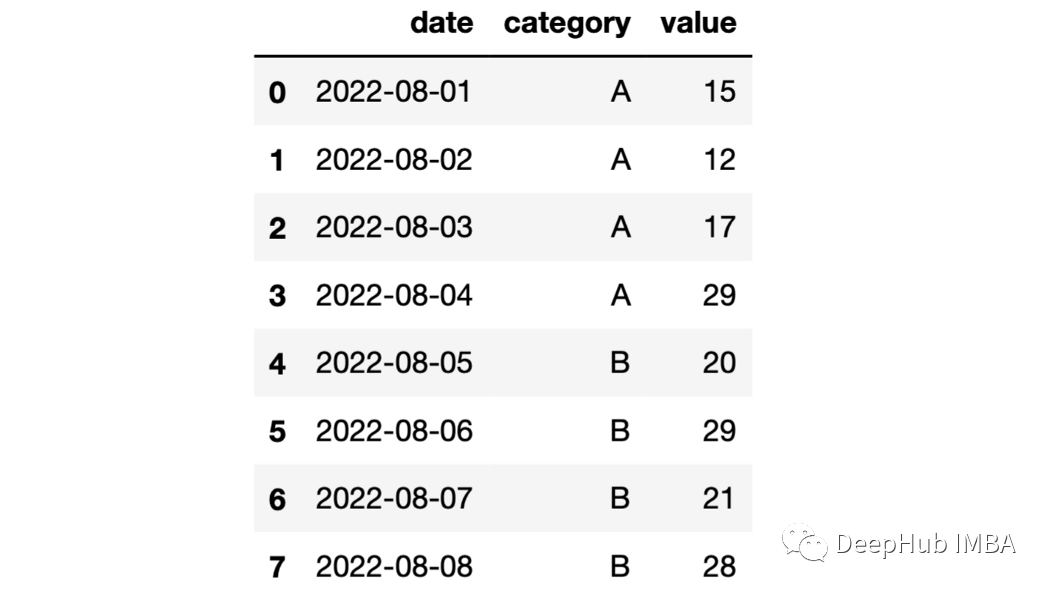
 22、累計操作 們可以計算出每組的累計總和。
22、累計操作 們可以計算出每組的累計總和。
importnumpyasnpdf=pd.DataFrame(
{
"date":pd.date_range(start="2022-08-01",periods=8,freq="D"),
"category":list("AAAABBBB"),
"value":np.random.randint(10,30,size=8)
}
)
 我們可以單獨創建一個列,包含值列的累計總和,如下所示:
我們可以單獨創建一個列,包含值列的累計總和,如下所示:
df["cum_sum"]=df.groupby("category")["value"].cumsum()
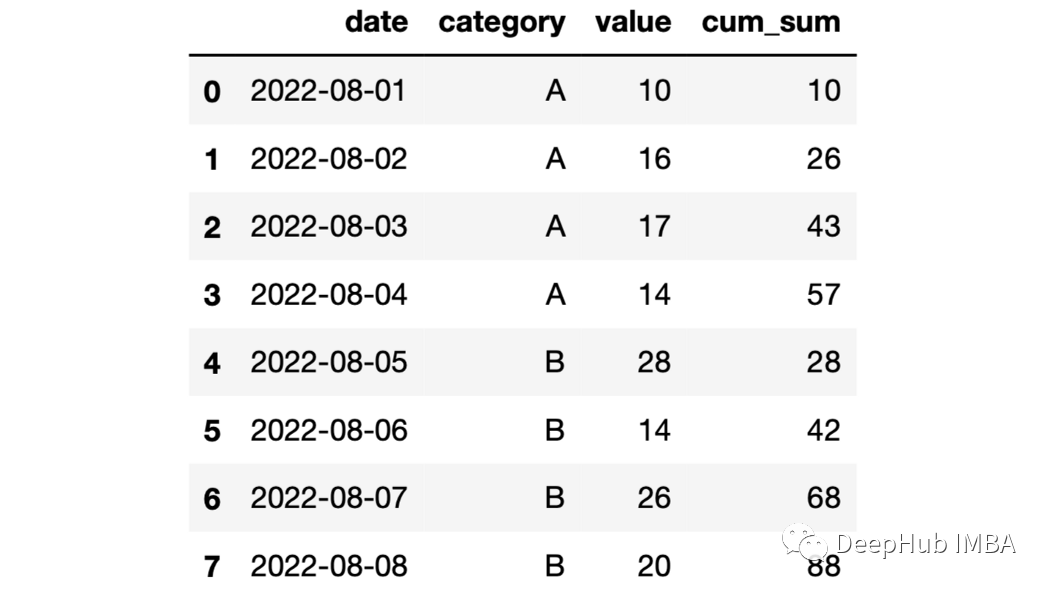 23、expanding函數 expanding函數提供展開轉換。但是對于展開以后的操作還是需要一個累計函數來堆區操作。例如它與cumsum 函數一起使用,結果將與與sum函數相同。
23、expanding函數 expanding函數提供展開轉換。但是對于展開以后的操作還是需要一個累計函數來堆區操作。例如它與cumsum 函數一起使用,結果將與與sum函數相同。
df["cum_sum_2"]=df.groupby( "category" )["value"].expanding().sum().values
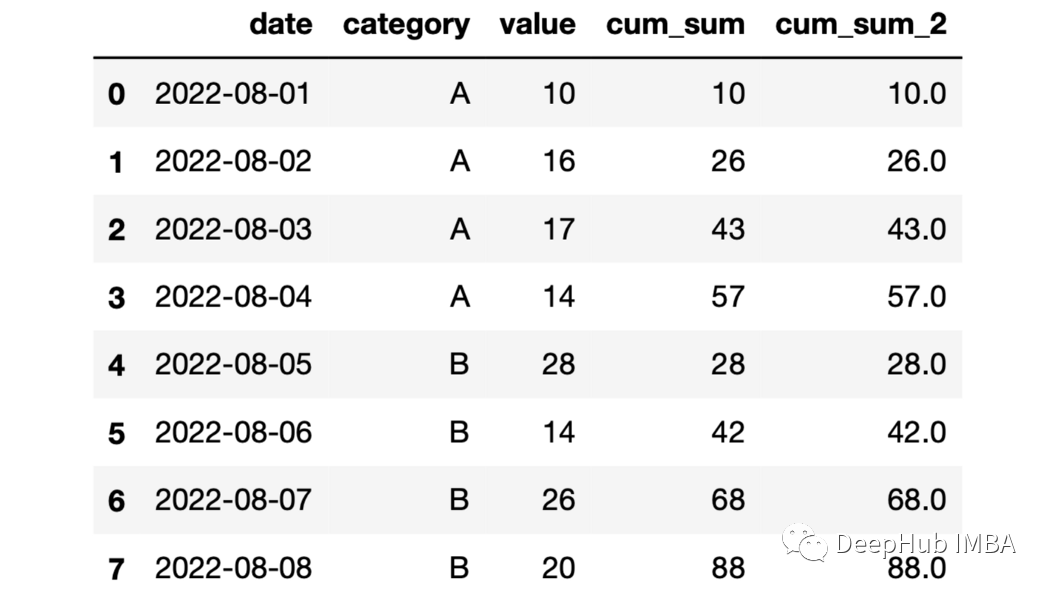 24、累積平均 利用展開函數和均值函數計算累積平均。
24、累積平均 利用展開函數和均值函數計算累積平均。
df["cum_mean"]=df.groupby( "category" )["value"].expanding().mean().values
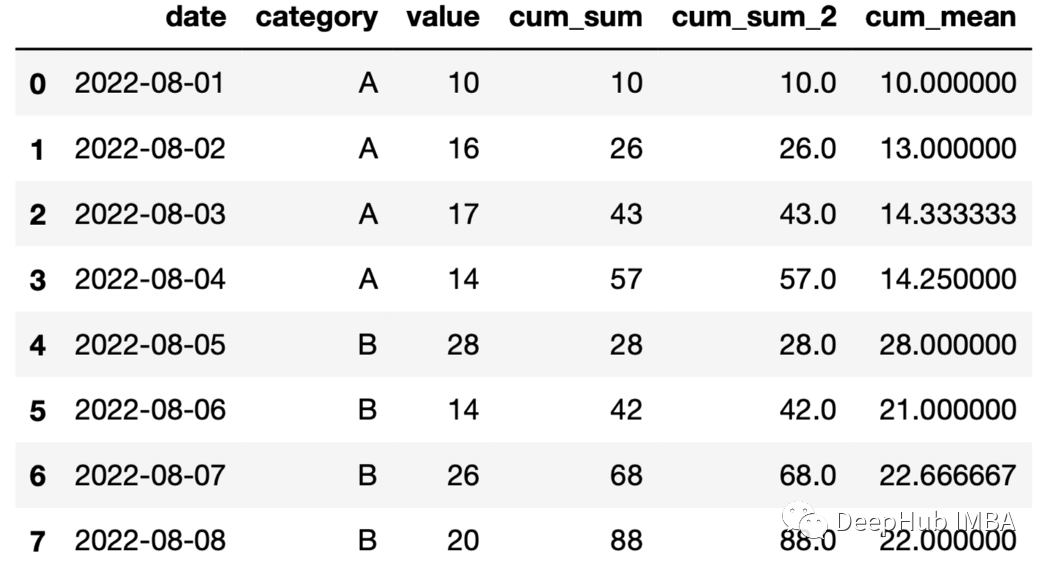 25、展開后的最大值 可以使用expand和max函數記錄組當前最大值。
25、展開后的最大值 可以使用expand和max函數記錄組當前最大值。
df["current_highest"]=df.groupby( "category" )["value"].expanding().max().values
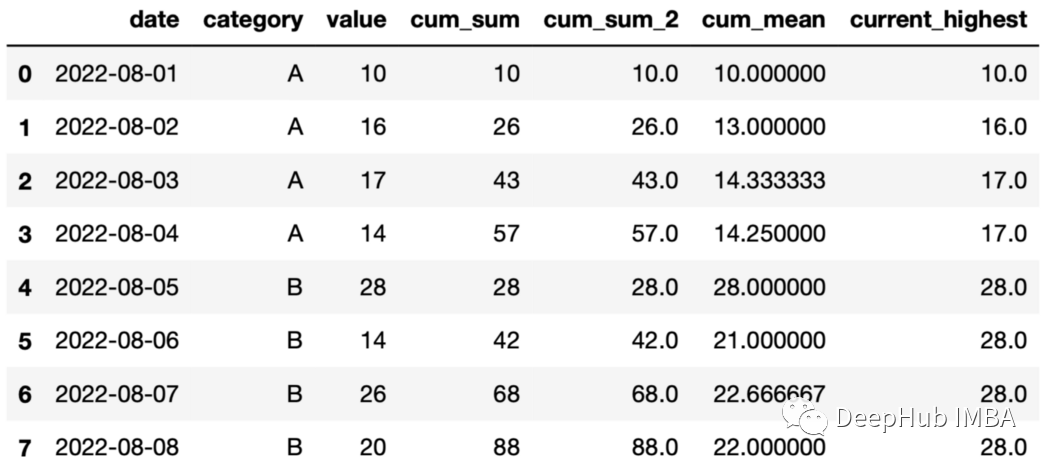 在Pandas中groupby函數與aggregate函數共同構成了高效的數據分析工具。在本文中所做的示例涵蓋了groupby功能的大多數用例,希望對你有所幫助。
在Pandas中groupby函數與aggregate函數共同構成了高效的數據分析工具。在本文中所做的示例涵蓋了groupby功能的大多數用例,希望對你有所幫助。
審核編輯:彭靜
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
函數
+關注
關注
3文章
4346瀏覽量
62979 -
數據分析
+關注
關注
2文章
1461瀏覽量
34168 -
數據集
+關注
關注
4文章
1209瀏覽量
24835
原文標題:25 個例子學會 Pandas Groupby 操作!
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
為什么圖騰柱電路大多數用三極管來實現的呢
本帖最后由 夢想號 于 2014-7-18 22:13 編輯
怎么我見到很多的圖騰柱電路大多數都是用npn+pnp來實現的。三極管不是有比較大的壓降的嗎,還有三極管的速度不怎么快,輸出電流不夠
發表于 07-18 22:08
為什么現在大多數四軸飛行器都采用的是X型布局
`四軸飛行器不單單只有X型,還有十型和H型。為什么現在大多數四軸飛行器都采用的是X型布局呢?據我了解,十字型布局更加簡單,更容易上手?`
發表于 05-06 16:49
如何解決大多數電源完整性問題
。有時候,只需要用四層電路板上的一個電源層和一個地層,就可以解決大多數電源完整性問題。除了電源層以外,還可以為每只IC去耦,以解決設計中繁瑣的電源問題。不過,現在的PCB空間(還有成本與你的日程)都很緊...
發表于 12-28 08:08
大多數為單指令周期
大多數為單指令周期
ATtiny10/11/12特點1. AVR RISC 結構2. AVR 高性能低功耗RISC 結構90 條指令大多數為單指令周期32 個8 位通用工作寄存器工作在 8MHz
發表于 03-26 16:51
?23次下載
大多數用戶并不習慣在智能音箱上收聽新聞
聽音樂、播報新聞、查詢天氣等被視為智能音箱最常用的功能,但實際上功能調取的頻率與用戶的感受并不一定高度相關。近日,外媒公布的最新報告顯示,大多數用戶實際上并不習慣在智能音箱上收聽新聞。
發表于 11-20 14:31
?1630次閱讀
為什么大多數加密貨幣沒有存在的必要
大多數人窮盡一生都在尋找自我存在的理由。這是個非常有趣的論點,但本文的重點是尋找加密貨幣(大多數,不是所有)存在的理由。我將首先解釋競爭幣存在的主要原因,然后再介紹比特幣及其目前和未來的發展,最后會說明為什么大多數競爭幣可能沒有
發表于 07-04 10:34
?823次閱讀
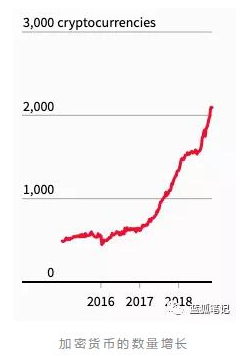
大多數加密數字貨幣都存在什么問題
據加密數字貨幣分析師Willy Woo在推特上發布的最新數據顯示,大多數加密數字貨幣項目都嚴重缺乏市場流動性,這使許多嚴肅的投資者望而卻步。
發表于 11-28 10:07
?1746次閱讀
大多數企業擔憂5G技術帶來的網絡安全風險
據外媒報道,德勤(Deloitte)的一項調查顯示,大多數專業人士表示,他們所在的企業擔心采用5G技術帶來的網絡安全風險。

滿足大多數倒計時控件的視圖教程
CountDownView是一個具有倒計時功能的View,滿足大多數倒計時控件需求。 集成 方式一: 通過library生成har包,添加har包到libs文件夾內 在entry的gradle內添加
發表于 04-01 11:03
?1次下載
為何大多數PLC采用ARM架構CPU
因為大多數PLC使用ARM架構的芯片就夠用了啊!不僅如此,如果你拆開PLC的外殼查看設備的PCB會發現,不僅其架構是ARM的,而且還是很多年前版本的,這是為什么呢?簡單來聊聊。
大多數人5G隨身WiFi用戶被商家引導,如何避免“劣質”隨身WiFi?
大多數5G隨身WiFi商家,所吹捧的宣傳點,基本和網速快慢及穩定性完全不相關。我們以電商平臺上,隨機4款5G隨身WiFi產品詳情為例。






 工商網監
工商網監
評論