 NADP+Triton搭建穩定高效的推理平臺
NADP+Triton搭建穩定高效的推理平臺
業務背景
蔚來自動駕駛研發平臺(NADP)是著力服務于自動駕駛核心業務方向的研發平臺。平臺化的推理能力作為常規機器學習平臺的重要組成部分,也是 NADP 所重點建設和支持的能力之一。NADP 所支持的推理業務,整體上有以下幾個特性:
10% 的業務產生 90% 的流量(優化重點業務收益大);
追求引擎層的高性能;
要求在算法框架,量化加速維度盡可能強的擴展性,為算法業務的框架選型, 與后續可能的加速方案都提供盡可能的兼容;
多個模型有業務關聯,希望能夠滿足多個模型之間串行/或者并行的調度。
經過對眾多方案的對比和篩選,NVIDIA Triton 在上述每一個方面都能滿足蔚來的需求。比如,Triton 支持多個模型或模塊進行 DAG 式的編排。其云原生友好的部署方式,能夠很輕松的做到多 GPU、多節點的擴展。從生產級別實踐的穩定性角度來看,即便是一個優秀的開源方案,作為平臺級的核心組件,也是需要長時間、高強度的驗證,才能放心的推廣到最核心業務上。經過半年的使用,Triton 證明了自己,在保證強大功能的前提下,也提供了很好的穩定性。另外,NVIDIA 有著優秀的生態建設與社區支持,提供了優質的 Triton 社區內容和文檔共享,保障了 NADP 的核心推理業務遷移到 Triton 方案上,并平穩運行至今。
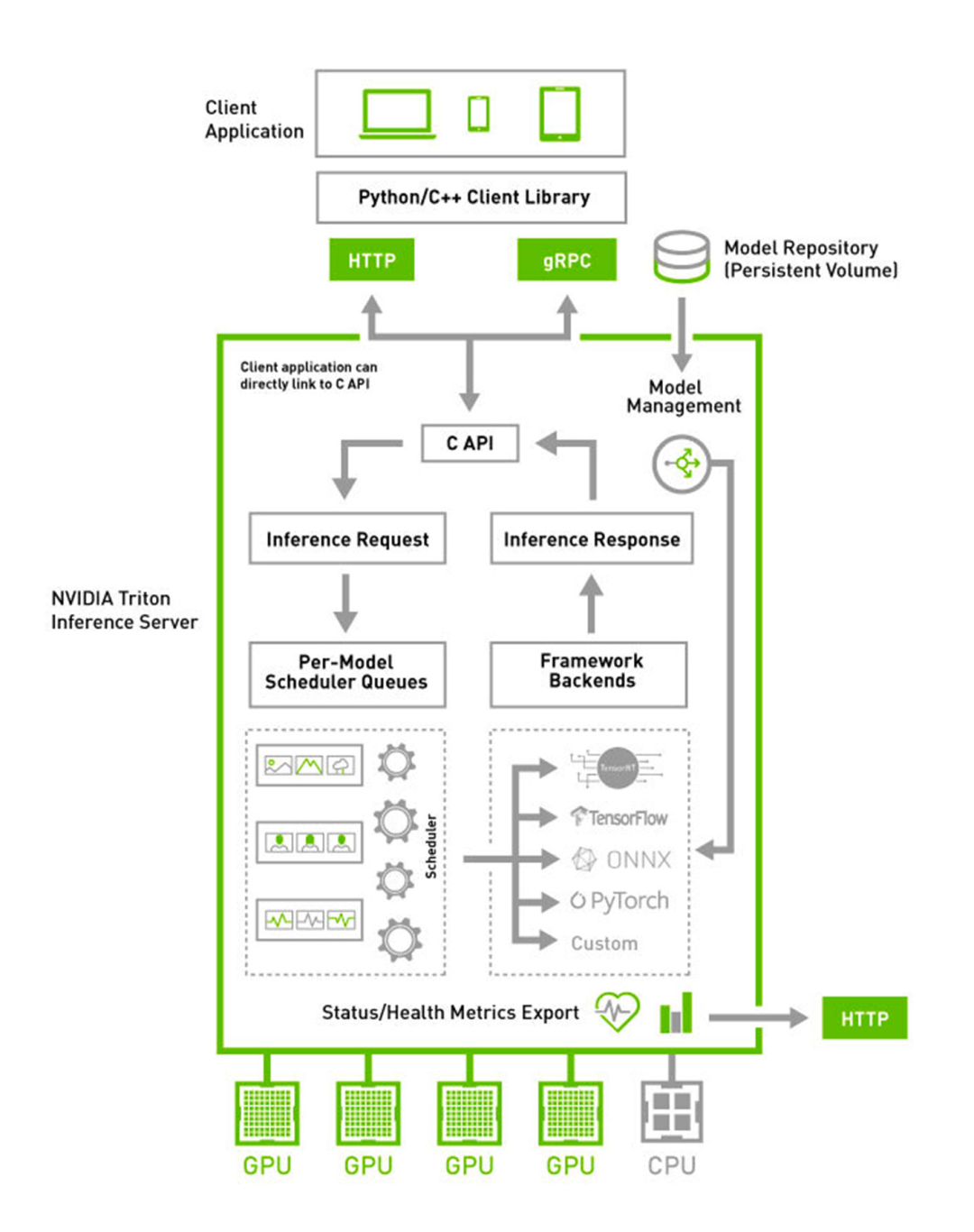
引入 Triton 之后的推理平臺架構
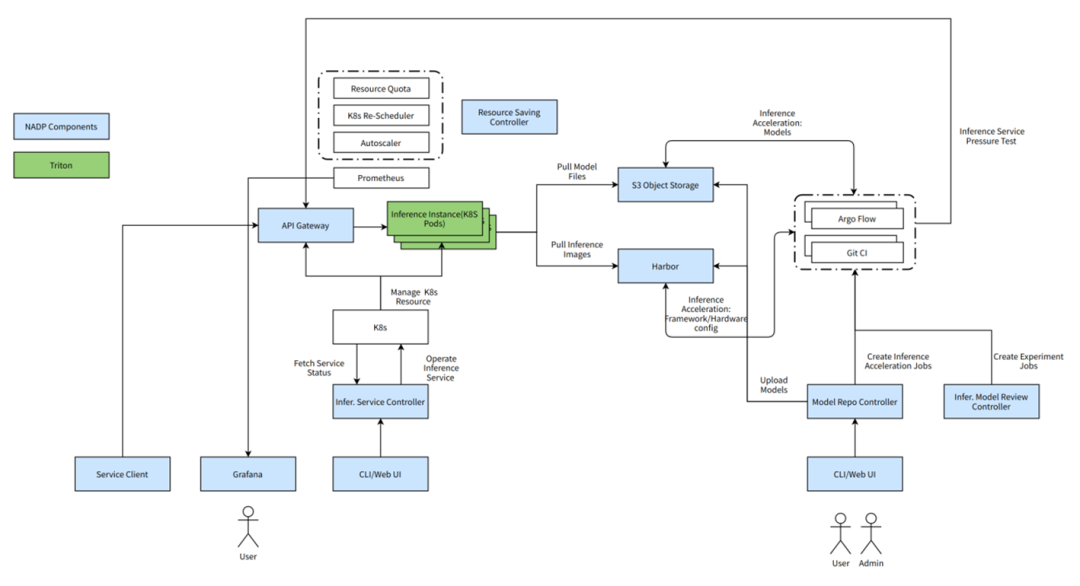
Triton 在設計之初,就融入了云原生的設計思路,為后面逐步圍繞 Triton 搭建完整的云原生平臺性推理解決方案提供了相當大的便利。作為 NADP 推理平臺的核心組件,Triton 與 NADP 的各個組件形成了一套完整的推理一站式解決方案。接下來,將集中在以下 4 個方面具體敘述 Triton 如何在 NADP 推理平臺中提供助力:
集成效率
高性能
易用性
高可用
01
集成效率
Triton + 模型倉庫 + Argo
Triton 與自建模型倉庫深度結合,配合 workflow 方案 Argo,完成全自動化的生產、量化、準入、云端部署、壓測和上線的 CICD 流程。
具體來講:
模型上傳,模型倉庫自動觸發配置好的 workflow;
創建與部署環境硬件環境一致容器,自動量化加速;
得益于 Triton 生態中提供的 perf analyzer,可以像使用 jMeter 一樣方便的按照模型的 Input Tensor Shape 自動生成請求與指定的負載。其壓測出的服務化之后模型的最大吞吐,很接近真實部署場景。
Triton + Jupyter
在 Triton 鏡像中集成了 Jupyter 組件之后,提供開箱即用的開發調試環境,在遇到復雜問題需要進行線上 debug 或者再線下復現問題時,Jupyter 能夠提供一個方便的開發環境供用戶進行調試。
02
高性能
Triton + Istio
當前 NADP 服務的業務場景,服務流量大,主要傳輸 cv 場景視頻文件+高分辨率圖片,必須使用高性能 rpc 協議進行加速,而且推理服務引擎必須對現有的 L4 Load Balancer 和服務發現方案有比較好的支持性。
而 Triton 原生支持 gRPC 的方案進行訪問,并且能夠很方便的部署為 k8s 容器。但因為 k8s 原生 service 不能夠很好的對 gRPC 進行請求級別的負載均衡(僅支持長連接的負載均衡),故在引入了 isito 之后,Triton 就能夠在傳輸協議上滿足我們的需求。
具體來講:
集群內容器直接訪問只需要一次跨物理機網絡轉發;
完美復用 k8s 的 readiness 狀態,通過和 Triton 節點的 liveness/readniess 探針進行服務的健康監控;
后續結合模型倉庫/配置中心提供用戶更友好的服務發現方式:基于域名的服務發現方案切換為基于模型的服務發現方案。
03
易用性
Triton + Apollo 配置中心
使用 Apollo 配置中心,可以極大程度提供更多的便利性。將基于域名的服務發現提升為基于模型名的服務發現。用戶將不需要了解模型所部署的具體的域名即可訪問模型。結合模型倉庫,用戶可以直接觸發模型的部署。
具體來講:
用戶在模型倉庫操作上線之后,將會將模型的真實域名寫入配置中心;
用戶使用 NADP 提供的客戶端可以從配置中心獲取到服務的真實域名,并直接訪問服務;
作為下一步規劃,當前的方案正在逐步遷移到基于開源的 model mesh 方案的版本上。
04
高可用
Triton + k8s CRD
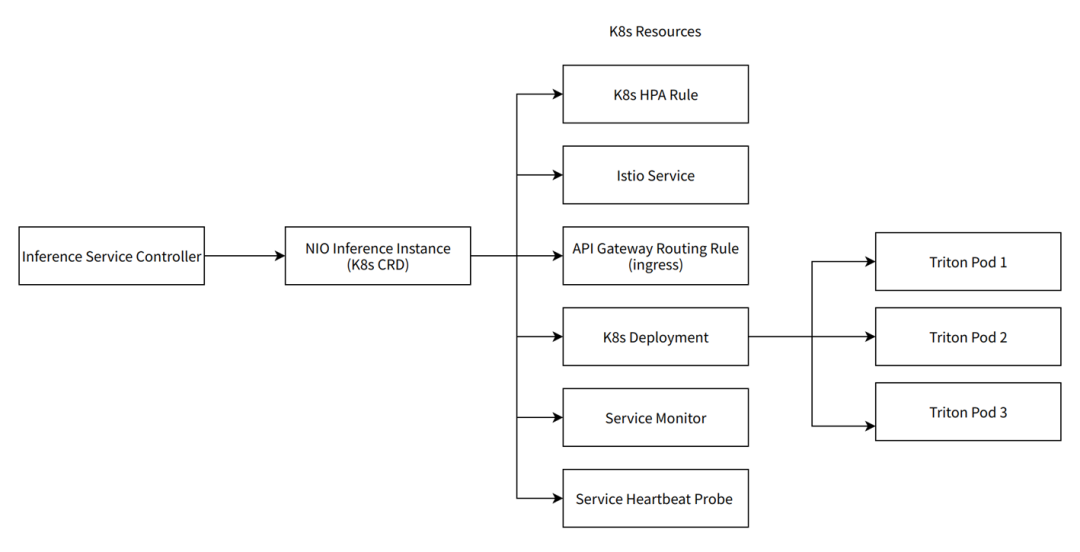
圍繞 Triton 蔚來搭建了服務 NIO 推理場景的 K8s CRD。它是以下幾個 K8s 原生 CRD 或其他自研 CRD 的組合。而這每一個組件都在一定程度上保障了服務的高可用。
自動擴縮容規則(HPA Rule):進行基于流量的自動擴縮容,在服務流量上升時自動擴容;
Istio service:可靠的 side car 機制,保障 gRPC 流量的服務發現和負載均衡;
Ingress:多實例部署,動態擴容的 Ingress 節點,保障跨集群流量的訪問;
k8s deploy:在一個推理實例內管理至少 3 個 Triton Pod,消除了服務的單點問題,并且通過 Triton server 加載多個模型的功能,實現多模型混布共享 GPU 算力,而且消除單點的同時不引入額外的 GPU 資源浪費;
Service Monitor:用于 prometheus 指標的收集,隨時監控服務狀態,上報異常信息;
Service Heartbeat Probe:集成了 Triton Perf Analyzer 的 Pod。Triton 生態中的 Perf Analyzer 工具能夠根據部署的模型 meta 信息生成真實請求并部署為主動請求探針,在沒有流量的時候監控服務的健康狀態并主動重啟異常實例,同時上報異常信息。
Triton + Promethus/Grafana
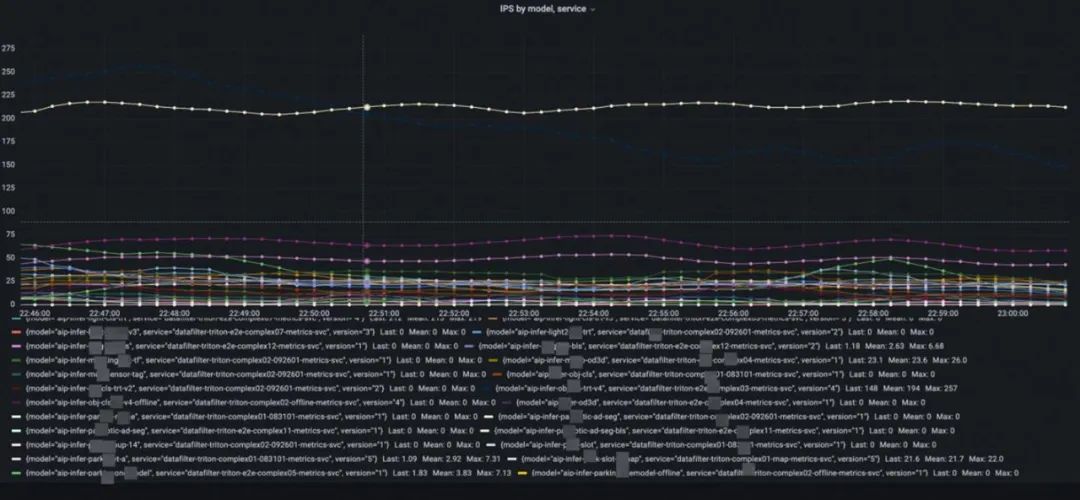
Triton 提供了一套完整的,基于模型維度的模型服務指標。打點幾乎包括了整個服務端推理鏈路的每個關鍵節點,甚至能夠區分執行推理的排隊時間和計算時間,使得能夠在不需要進入 debug 模式的情況下進行細致的線上模型服務性能診斷和分析。另外,因為指標的格式支持了云原生主流的 Promethus/Grafana, 用戶能夠非常方便的配置看板和各維度的報警, 為服務的高可用提供指標支持。
模型的級別時延監控
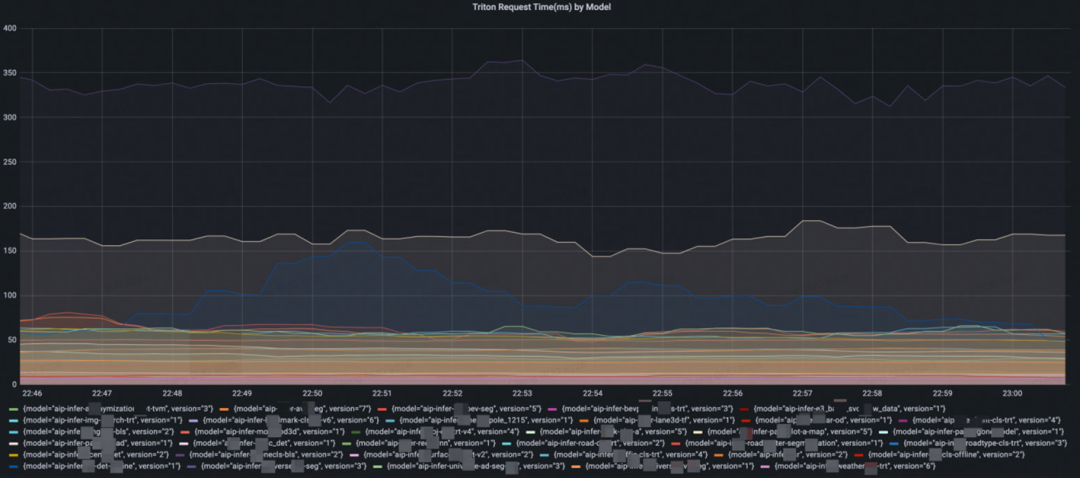
模型的級別的 qps 監控
服務業務場景:數據挖掘
目前,NADP 數據挖掘業務下的相關模型預測服務已經全部遷移至 Triton Inference Server,為上百個模型提供了高吞吐預測能力。同時在某些任務基礎上,通過自實現前處理算子、前后處理服務化、BLS 串聯模型等手段,將一些模型任務合并起來,極大的提升了處理效率。
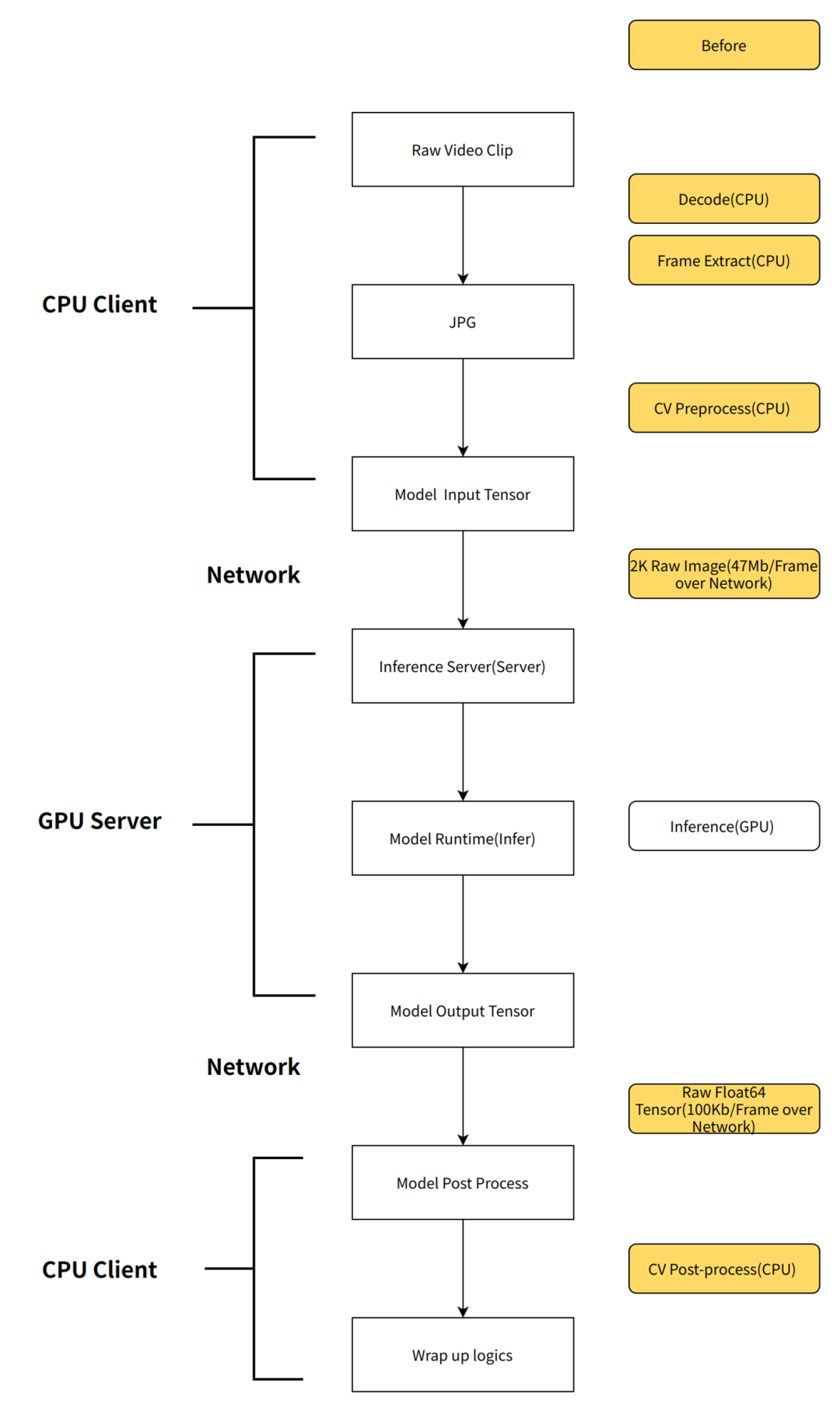
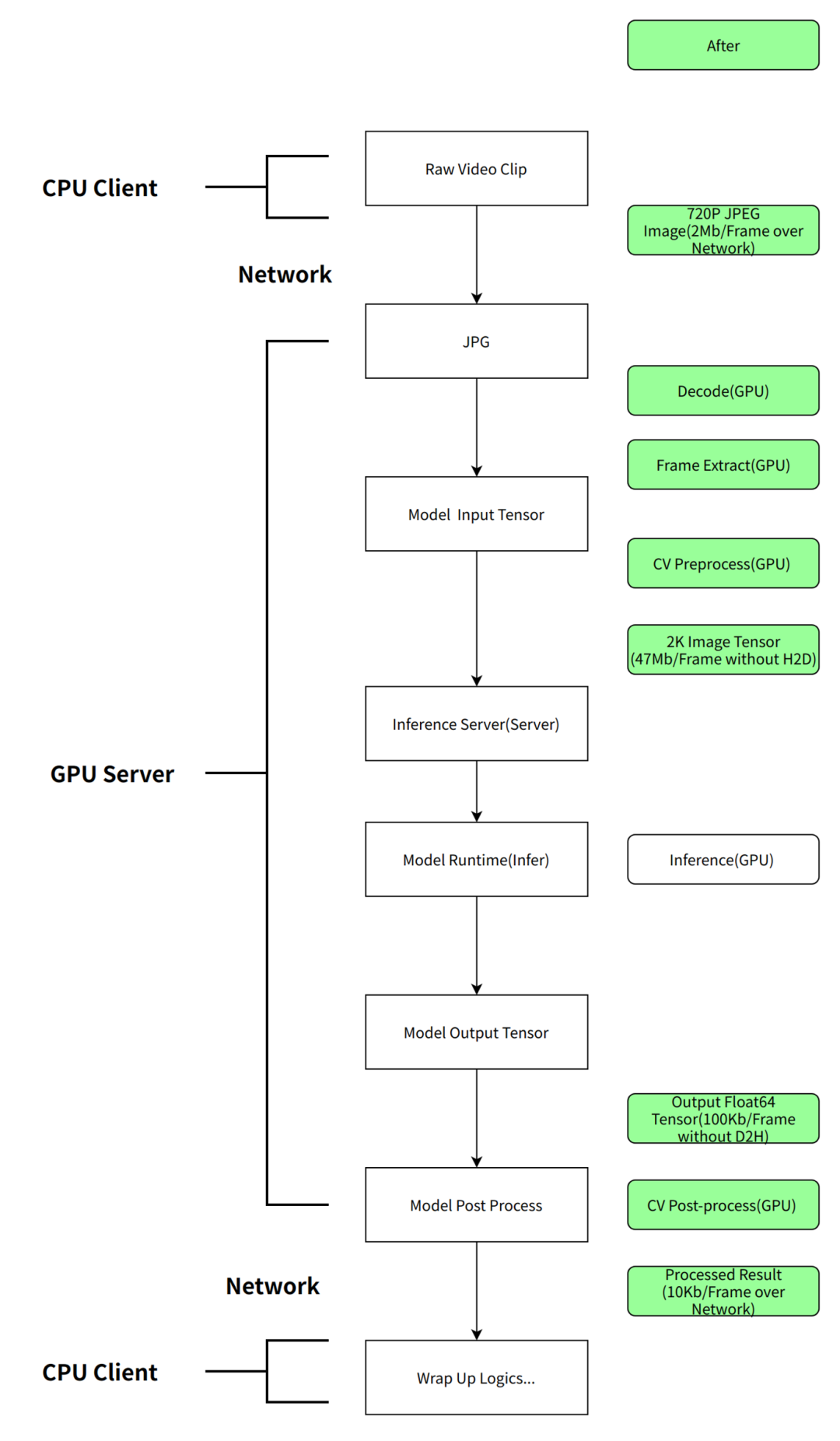
服務端模型前處理
通過將服務的前后處理從客戶端移動到服務端,不僅能夠在網絡傳輸上節省大量的時間,而且 GPU 服務端(Triton)可以用 Nvjpeg 進行 GPU 解碼,并在 GPU 上做 resize、transpose 等處理。能夠大幅加速前處理,明顯減輕 client 端 CPU 計算壓力。
01
業務流程
02
收益
傳壓縮圖片,而非 input tensor,只需要幾百 KB 就能將一張 2K 原圖 bytes 傳輸過去,以當前 onemodel 2k 輸入圖片為例,模型輸入必須為 1920*1080*3*8 byte 大小,而且必須走網絡,而在加入服務端后處理之后,在精度損失允許的范圍內,可以將原圖改為傳壓縮過的三通道 720P jpg 圖片(1280*720*3),在服務端在 resize 成 1920*1080*3*8 byte,節約大量帶寬;
服務端前處理完成后將 GPU 顯存指針直接送入模型預測,還能省去 Host2Device 的拷貝;
服務端可以封裝模型的后處理,使得每次模型升級的時候,client 端不用感知到服務后處理的變化,從而不需要修改處理邏輯代碼;
使用 nvJpeg,DALI 等使用 GPU 算力的組件來進行前后處理,加速整體的數據處理速度。
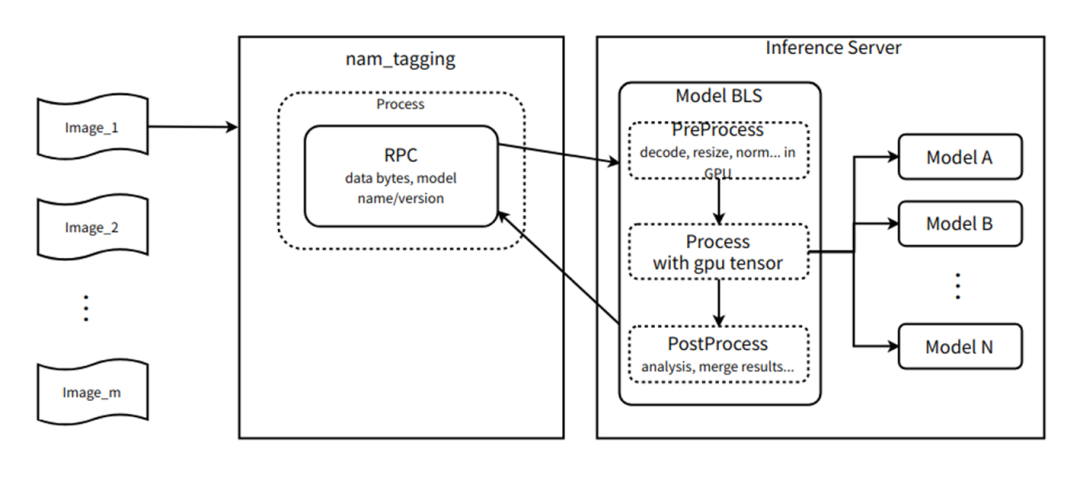
多模型 DAG 式編排
一個統一的前處理模型,一份輸入復制多份到多個后端識別模型,該流程在服務端單 GPU 節點內完成,不需要走網絡,在 Triton + bls/ensemble 的支持下,甚至可以節約 H2D、D2H 拷貝。
01
業務流程
02
收益
當業務邏輯強制使用多模型 DAG 式編排多個模型之后,每次產生模型的輸入/輸出都可以疊加服務端前后處理改造的收益,當前部署的 triton 服務最多使用 BLS 串聯了 9 個模型;
對于 2k 分辨率的輸入來講,每幀圖片的大小為 1920 * 1080 * 3 * 8 = 47Mb, 假設全幀率為 60fps,則每秒輸入數據量為 1920 * 1080 * 3 * 8 * 60 = 2847 Mb。如果使用 bls 串聯了 9 個模型,則每秒需要產生的數據傳輸量為 1920 * 1080 * 3 * 8 * 60 * 9 = 25 Gb = 3GB;
如果使用 PCIe 傳輸,假設 PCIe 帶寬為 160Gb = 20GB 每秒, 則理論上每秒產生的數據可以節約 150ms 在數據傳輸上;
如果使用網絡傳輸,假設可用帶寬為 16Gb=2Gb 每秒,則理論上每秒產生的數據可以節約 1500ms 在數據傳輸上。
總結和展望
NIO 基于 NVIDIA Triton 搭建的推理服務平臺,在數據挖掘業務場景下,通過上文詳細介紹的“服務器端模型前處理”和“多模型 DAG 式編排”,GPU 資源平均節省 24%;在部分核心 pipeline 上,吞吐能力提升為原來的 5 倍,整體時延降低為原來的 1/6。
另外,NIO 當前已經實現了輸入為原始視頻而非抽幀后圖片的預研版本工作流上線,但只承載了小部分流量。而主要流量還是使用 jpg 壓縮圖片作為輸入的版本。當前只是使用本地腳本完成了數據加載和模型推理,后續會逐步地將當前流程遷移到 Triton 的模型編排能力上。
關于作者 ——郭城

郭城是 NIO 自動駕駛研發平臺(NADP)的高級工程師,負責為 NIO 自動駕駛搭建可靠高效的推理平臺和深度學習模型 CICD 工具鏈。在加入 NIO 之前,他在小米技術委員會參與了小米集團機器學習平臺的搭建。他個人對 ML-ops、以及所有其他深度學習工程相關的主題感興趣。
-
NVIDIA
+關注
關注
14文章
5076瀏覽量
103718 -
Triton
+關注
關注
0文章
28瀏覽量
7060 -
DAG
+關注
關注
0文章
17瀏覽量
8193 -
自動駕駛
+關注
關注
785文章
13930瀏覽量
167002 -
云原生
+關注
關注
0文章
252瀏覽量
7985
原文標題:技術博客:NADP + Triton,搭建穩定高效的推理平臺
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
新品| LLM630 Compute Kit,AI 大語言模型推理開發平臺

搭建家庭云平臺電腦,搭建家庭云平臺電腦的操作方法
Triton編譯器與GPU編程的結合應用
Triton編譯器如何提升編程效率
Triton編譯器在高性能計算中的應用
Triton編譯器的優化技巧
Triton編譯器的優勢與劣勢分析
Triton編譯器在機器學習中的應用
Triton編譯器支持的編程語言
Triton編譯器與其他編譯器的比較
Triton編譯器功能介紹 Triton編譯器使用教程
企業云服務器平臺設計與搭建
高效大模型的推理綜述

使用NVIDIA Triton推理服務器來加速AI預測
在AMD GPU上如何安裝和配置triton?






 工商網監
工商網監
評論