") 識別網(wǎng)絡(luò)爬蟲的策略分析
識別網(wǎng)絡(luò)爬蟲的策略分析
識別網(wǎng)絡(luò)爬蟲的策略分析
一、網(wǎng)絡(luò)爬蟲
爬蟲(crawler)也可以被稱為spider和robot,通常是指對目標網(wǎng)站進行自動化瀏覽的腳本或者程序,包括使用requests庫編寫腳本等。隨著互聯(lián)網(wǎng)的不斷發(fā)展,網(wǎng)絡(luò)爬蟲愈發(fā)常見,并占用了大量的網(wǎng)絡(luò)資源。由爬蟲產(chǎn)生的網(wǎng)絡(luò)流量占總流量的37.2%,其中由惡意爬蟲產(chǎn)生的流量約占65%[1]。如何在網(wǎng)絡(luò)流量中識別爬蟲,是判斷爬蟲行為意圖的前提,常見的使用爬蟲的場景包括:搜索引擎等使用爬蟲爬取網(wǎng)站上的信息,研究機構(gòu)使用爬蟲搜集數(shù)據(jù),以及攻擊者使用爬蟲搜集用戶信息、識別軟件后門等。
針對網(wǎng)絡(luò)爬蟲,目前常用的方法包括在服務(wù)器上的robots.txt文件中進行適當(dāng)?shù)呐渲茫瑢⒂脩舸砹腥氚酌麊蔚龋@些操作可以檢測和阻止一些低級別的惡意爬蟲。然而,高級和復(fù)雜的網(wǎng)絡(luò)爬蟲仍然難以檢測,因為它們通常會偽裝成合法的爬蟲或正常用戶。此外,運營部門需要投入較多的時間和資源來收集和分析網(wǎng)絡(luò)流量記錄報告,以發(fā)現(xiàn)隱藏的網(wǎng)絡(luò)爬蟲的痕跡。網(wǎng)絡(luò)爬蟲通常會觸發(fā)大量告警,給安全運營人員帶來了較大的數(shù)據(jù)處理壓力。此外,部分惡意攻擊者也會使用爬蟲來收集信息,因此從海量的告警中,識別出網(wǎng)絡(luò)爬蟲,并判斷其行為意圖十分重要。在安全運營場景中,如何根據(jù)安全設(shè)備產(chǎn)生的告警數(shù)據(jù),設(shè)計出識別爬蟲,并判斷其行為意圖的方案,目前仍需要不斷地探索以及深入的思考。
在往期內(nèi)容中,筆者已經(jīng)介紹了Aristaeus平臺使用瀏覽器指紋、TLS指紋和IP行為分析等方式識別爬蟲的行為意圖的工作[2],由于Aristaeus平臺使用的域名在實驗前均未注冊使用過,因此這一工作中采集到的流量均為爬蟲,并在此基礎(chǔ)上對良性/惡意的爬蟲進行了區(qū)分。本文對基于web日志信息識別爬蟲以及判斷其行為意圖的研究進行總結(jié)分析[3],包括常見的判斷爬蟲的方法,以及機器學(xué)習(xí)、深度學(xué)習(xí)等方法識別爬蟲,以及各種識別爬蟲行為意圖的方法。
二、識別網(wǎng)絡(luò)爬蟲的常見方法
常用的判定爬蟲的方法包括檢查其HTTP協(xié)議頭的User-agent字段,這一字段包含用戶訪問時所使用的操作系統(tǒng)及版本、瀏覽器類型及版本等標識信息。如果該字段中表明為瀏覽器等使用的爬蟲,使用DNS正向和反向查找的方法可以確定發(fā)起請求的IP地址是否與其聲明的一致,則可以將其進行判別。一個IP地址可能使用不同的用戶代理或者不同的自動化工具生成HTTP請求頭,這一現(xiàn)象可能是良性爬蟲使用NAT或者代理造成的,但也可能是惡意爬蟲在進行欺騙行為,包括在User-agent字段中更改操作系統(tǒng)、瀏覽器版本等[4],例如筆者在日常告警數(shù)據(jù)中觀察到User-Agent字段存在
“User-Agent: Mozilla/5.0+(compatible;+Baiduspider/2.0;++http://www.baidu.com/search/spider.html) Mozilla/5.0+(compatible;+Googlebot/2.1;++http://www.google.com/bot.html)”
這類情況。目前也有許多開源的項目使用上述方法檢測網(wǎng)絡(luò)爬蟲,例如CrawlerDetect 就是github上的一個開源項目[5],通過User-Agent和 http_from 字段檢測爬蟲,目前能夠檢測到 1,000 種網(wǎng)絡(luò)爬蟲。
由于上述方法只能判斷一部分網(wǎng)絡(luò)爬蟲,在安全運營場景中,對于其余無法識別的爬蟲,可以基于HTTP請求的速率、訪問量、請求方法、請求文件大小等行為特征,設(shè)計算法進行識別。由合法機構(gòu)運行的網(wǎng)絡(luò)爬蟲,包括搜索引擎和研究機構(gòu)等,通常不會造成網(wǎng)絡(luò)的阻塞。惡意的網(wǎng)絡(luò)爬蟲主要是在機器上運行的腳本編程,通常具有較高的 HTTP 請求率,且對URL訪問量很大。基于網(wǎng)絡(luò)爬蟲的這一特點,可以提取各個IP地址發(fā)出HTTP請求的速率、以及其URL的訪問量作為特征。由于爬蟲的主要目的是從網(wǎng)站下載信息,所以較多地使用GET方法,而不是使用POST方法進行上傳操作。此外,爬蟲通常需要在嘗試爬取文件之前確定文件的類型,所以與正常瀏覽相比,可能會使用更多的HEAD方法[4]。通過統(tǒng)計分析各個IP地址的HTTP請求中各類方法所占比例,可以提取出HTTP請求方法的分布特征。
通常網(wǎng)絡(luò)爬蟲對特定文件類型的請求更多,例如較多地請求 .html文件,而對 .jpeg等文件類型的請求較少。爬蟲通常會進行策略優(yōu)化,以實現(xiàn)在最短的時間內(nèi)將爬取效率最大化,往往會跳過大文件而去尋找較小的文件,所以HTTP的 GET方法可能會返回更多的小文件。如果某些被爬取的URL需要進一步驗證,爬蟲的請求將被定向到這些驗證頁面,因此會產(chǎn)生3XX 或 4XX 的 HTTP 請求返回碼[4]。通過統(tǒng)計分析各個IP地址請求的文件類型、大小的分布,以及響應(yīng)碼的分布,可以提取出描述請求文件和響應(yīng)特征,對應(yīng)于告警信息中的URI,content_length,q_body和r-body等字段。
Lagopoulos等人提出了一種用于網(wǎng)絡(luò)機器人檢測的語義方法[6],這一方法主要是基于以人為主體的網(wǎng)絡(luò)用戶通常對特定主題感興趣,而爬蟲則是隨機地在網(wǎng)絡(luò)上爬行的假設(shè),設(shè)計出了一套檢測方法。這一工作從會話中提取的典型特征包括:
請求總數(shù):請求的數(shù)量。
會話持續(xù)時間:第一個請求和最后一個請求之間經(jīng)過的總時間
平均時間:兩個連續(xù)請求之間的平均時間。
標準偏差時間:兩個連續(xù)請求之間時間的標準偏差。
重復(fù)請求:使用與以前相同的HTTP方法請求已經(jīng)訪問過的頁面。
HTTP請求:四個特性,每個特性包含與以下HTTP響應(yīng)代碼之一相關(guān)聯(lián)的請求的百分比:成功(2xx)、重定向(3xx)、客戶機錯誤(4xx)和服務(wù)器錯誤(5xx)。
特定類型請求:特定類型的請求占所有請求數(shù)的百分比,這一特征在不同的應(yīng)用程序中表現(xiàn)不同。
除了上述特征外,這一工作從會話中提取到了一部分語義特征:包括主題總數(shù)、獨特主題、頁面相似度、頁面的語義差異等,并使用了四種不同的模型,包括使用RBF的SVM,梯度增強模型,多層感知器和極端梯度增強來測試檢測結(jié)果。從不同特征集上的實驗結(jié)果可以看出,RBF在語義特征上取得了最好的性能,GB在簡單典型特征上取得了最好的性能,GB在典型特征和語義特征的結(jié)合上也取得了最好的性能。
此外,Wan等人在2019年提出了一種名為PathMarker的反爬蟲技術(shù),可以通過檢測網(wǎng)頁或請求之間的關(guān)系來檢測分布式爬蟲[7]。在這一方法中,通過向URL添加標記來跟蹤訪問該URL之前的頁面,并識別訪問該URL的用戶。根據(jù)URL訪問路徑和訪問時間的不同模式,使用支持向量機模型來區(qū)分惡意網(wǎng)絡(luò)爬蟲和普通用戶。實驗結(jié)果表明,該系統(tǒng)能夠成功識別96.74%的爬蟲長會話和96.43%的普通用戶長會話。PathMarker的體系結(jié)構(gòu)如圖1所示,最后使用自動化的公共圖靈測試(CAPTCHA)實時地識別爬蟲和普通用戶。
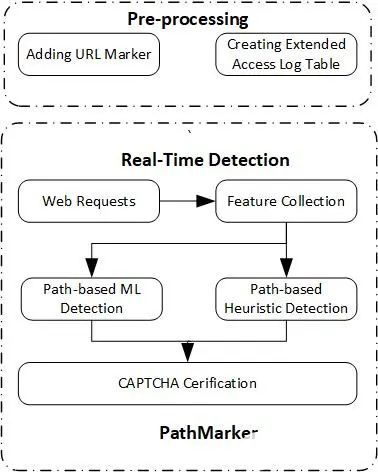
圖1 PathMarker的體系架構(gòu)
上述兩個工作均引入了語義內(nèi)容作為檢測爬蟲的特征之一,其核心思想在于普通用戶和爬蟲請求網(wǎng)頁的主題不同。基于這一結(jié)果,可以使用doc2vec 和 word2vec替換LDA,以更好地表示會話中訪問內(nèi)容的語義[6]。
三、識別爬蟲的行為意圖
匹配黑名單是常用的識別惡意爬蟲的方式,然而在目前觀測到的攻擊中,大多數(shù)惡意IP都是被感染的個人設(shè)備,且爬蟲經(jīng)常會切換新的IP地址,多數(shù)IP的生存周期都不超過一天,這些操作都可以避免被黑名單過濾。例如,在Aristaeus平臺監(jiān)測到的發(fā)出惡意請求的IP地址中,只有13%出現(xiàn)在當(dāng)前流行的惡意IP黑名單中,這表明黑名單對惡意爬蟲的IP地址覆蓋率較低[2]。此外,還可以根據(jù)訪問行為是否符合robots協(xié)議來判斷是否為惡意爬蟲。通常每個網(wǎng)站都會設(shè)置robots.txt,內(nèi)容包含不要訪問某些文件夾或文件,或限制爬蟲訪問網(wǎng)站的頻率。通常我們認為惡意爬蟲不會遵守robots協(xié)議,并且會使用robots.txt來識別他們可能忽略的站點,這一行為模式可以用于識別惡意爬蟲。然而,在Aristaeus平臺的研究中,并未發(fā)現(xiàn)爬蟲發(fā)出的請求違背robots協(xié)議的現(xiàn)象[2],這表明爬蟲采取的策略中已明確避免出現(xiàn)上述行為,所以這類方式在實際應(yīng)用中可能難以有效地識別爬蟲。
基于這一實際情況,采用更加細粒度的方式描述爬蟲行為,并提取相應(yīng)的行為特征是后續(xù)識別爬蟲行為意圖的解決方向。例如,良性的爬蟲不會發(fā)送未經(jīng)請求的POST或利用漏洞進行攻擊,與之相反,惡意爬蟲則會向身份驗證端點發(fā)送未經(jīng)請求的POST或無效的請求,可以視為偵察行為。爬蟲請求中是否存在欺騙的行為也可以用于判斷其意圖,例如構(gòu)建wget、curl、Chrome等工具的TLS指紋庫,通過將請求中聲明的用戶代理與其TLS指紋進行匹配[2],可以檢測出進行身份欺瞞的爬蟲,并在后續(xù)的分析中進一步分析其行為特征。
四、結(jié)論
通過使用User-Agent字段及DNS正方向查詢可以初步識別常見搜索引擎的爬蟲,基于IP地址發(fā)出HTTP請求的行為特征,并引入對請求行為的語義特征描述等,可以在剩余告警信息中檢測出使用腳本得到的爬蟲。隨著爬蟲策略的優(yōu)化更新,使用靜態(tài)黑名單過濾或判斷爬蟲是否遵守robots協(xié)議,通常很難達到較好的效果。如果需要進一步辨別爬蟲的行為意圖,可以通過建立構(gòu)建爬蟲程序的指紋庫,判斷爬蟲的真實身份是否與其聲明一致。針對IP的請求內(nèi)容,構(gòu)建描述是否對web應(yīng)用程序進行指紋識別、是否在掃描可能存在的敏感文件等指紋庫,可以更加精確地檢測惡意爬蟲。在后續(xù)的研究工作中,筆者希望通過將上述檢測方法付諸實踐,基于告警信息對爬蟲進行檢測,并深入分析爬蟲的行為意圖,進而輔助安全運營人員研判。
審核編輯:湯梓紅
-
服務(wù)器
+關(guān)注
關(guān)注
12文章
9303瀏覽量
86060 -
網(wǎng)絡(luò)爬蟲
+關(guān)注
關(guān)注
1文章
52瀏覽量
8718
發(fā)布評論請先 登錄
相關(guān)推薦
應(yīng)對反爬蟲的策略
網(wǎng)絡(luò)爬蟲之關(guān)于爬蟲http代理的常見使用方式
網(wǎng)絡(luò)爬蟲nodejs爬蟲代理配置
python網(wǎng)絡(luò)爬蟲概述
網(wǎng)絡(luò)爬蟲 Python和數(shù)據(jù)分析
一種維護WAP網(wǎng)站的網(wǎng)絡(luò)爬蟲的設(shè)計
一種新型網(wǎng)絡(luò)爬蟲的設(shè)計與實現(xiàn)
網(wǎng)絡(luò)爬蟲的爬行策略
網(wǎng)絡(luò)爬蟲的原理是什么
網(wǎng)絡(luò)爬蟲是否合法
常用的網(wǎng)絡(luò)爬蟲軟件
如何使用本體語義實現(xiàn)災(zāi)害主題爬蟲的策略





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論