 用于弱監督大規模點云語義分割的混合對比正則化框架
用于弱監督大規模點云語義分割的混合對比正則化框架
為了解決大規模點云語義分割中的巨大標記成本,我們提出了一種新的弱監督環境下的混合對比正則化(HybridCR)框架,該框架與全監督的框架相比具有競爭性。具體而言,HybridCR是第一個利用點一致性,并以端到端方式來使用對比正則化和偽標記的框架。從根本上說,HybidCR明確有效地考慮了局部相鄰點之間的語義相似性和3D類的全局特征。我們進一步設計了一個動態點云增強器來生成多樣且魯棒的樣本視圖,其轉換參數與模型訓練聯合優化。通過大量實驗,HybridCR在室內和室外數據集(如S3DIS、ScanNet-V2、Semantic3D和SemanticKITTI)上都比SOTA方法取得了顯著的性能改進。
引言
學習大規模點云的精確語義,是機器智能理解復雜3D場景的基本感知任務。現有的基于深度學習的方法嚴重依賴于用于訓練的標記點云數據的可用性和數量[5,21,22,29]。然而,3D point-wise標記既耗時又費力。因此,我們的目標是探索弱監督學習,以最大限度地提高數據效率并減少標記3D點云的工作量。 最近,出現了幾種3D點云弱監督語義分割方法,通常可分為三類:
一致性正則化,在隨機修改輸入或模型function后,利用預測分布的一致性約束。
偽標記,也稱為自訓練,使用模型預測作為監督。
對比預訓練,側重于模型預訓練,然后使用較少的標簽對下游任務進行微調。
雖然現有方法取得了令人鼓舞的成果,但仍有一些局限性有待解決。首先,他們沒有充分考慮大規模場景中相鄰類的語義屬性和3D類的全局特征,未能充分利用有限但有價值的標記[33]。其次,許多pipelines [33,38]使用固定/人工的數據增強來獲得多視圖表示,導致次優的學習,因為增強的強度和類型強烈依賴于模型和數據集大小。此外,在fixed增強中忽略了樣本的形狀復雜度。第三,現有方法[9,37]通常涉及多個階段的預訓練和微調,與端到端訓練方案相比,這增加了訓練和部署的難度。 為了解決上述缺點,我們探索分別在標記空間和特征空間中同時利用一致性和對比性。受最近3D PSD[38]和2D FixMatch[27]的啟發,我們將偽標簽和一致性正則化策略結合到大規模點云的端到端訓練方案中。為了更好地使用對比信息,我們重新設計了錨點的正對和負對。一個關鍵的觀察結果是,高級語義場景理解不僅需要局部幾何特征,而且還需要全局幾何特征,使得點云實例的對比更加充分。此外,受分類任務中的PointAugment[15]的點云實例對比啟發,我們進一步引入動態點云增強器,以提供一致性和對比正則化的轉換,并進行聯合優化。 為了實現上述思想,我們提出了一種新的范式,稱為混合對比正則化(HybridCR),用于大規模點云的弱監督語義分割,該范式包括局部和全局指導的對比學習以及動態點云變換。如圖1所示,局部引導對比正則化迫使不同視圖的數據樣本靠近其相鄰點,遠離其他點。對于全局引導對比正則化,每個樣本都被要求靠近其類原型,遠離不同類原型。從根本上講,HybridCR顯式有效地考慮了局部相鄰點之間的語義相似性和3D點云類的全局特征。此外,所提出的動態點云增強器使用多層感知機(MLP)和高斯噪聲來豐富上下文位移中的數據多樣性,其中增強器的參數可以與模型訓練聯合優化。大量實驗表明,HybridCR在室內場景(即S3DIS[1]和ScanNet-V2[6])和室外場景(即Semantic3D[8]和SemanticKITTI[2])中都達到了SOTA性能,證明了提出的框架的有效性。 總之,貢獻有四個方面: ? 提出了框架HybridCR,第一個以端到端的方式利用點一致性和對比特性進行弱監督點云語義分割。 ? 引入了局部和全局引導對比正則化,以促進high-level的3D語義場景理解任務。 ? 設計了一種新的動態點云增強器,用于轉換不同且穩健的樣本視圖,并在整個訓練過程中對其進行了聯合優化。 ? 與最近的弱監督方法相比,HybridCR取得了顯著的性能,在室內和室外數據集中,AP分別提高了平均2.4%和1.0%。 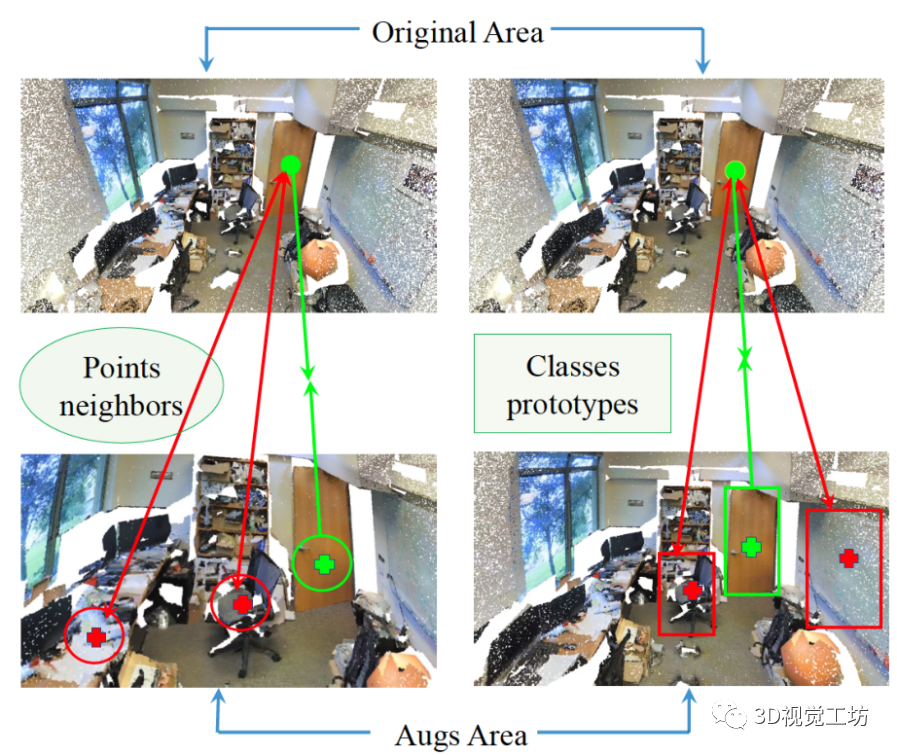 圖1. 局部和全局的混合對比正則化。 1)左圖:鼓勵錨點與匹配的正點及其相鄰點(綠色圓圈)相似,而與負點及其相鄰點(紅色圓圈)不同。 2)右圖:鼓勵錨點與匹配的正點和屬于同一類別的其他點(綠色框中)相似,而與不同類別的負點(紅色框中)不同。
圖1. 局部和全局的混合對比正則化。 1)左圖:鼓勵錨點與匹配的正點及其相鄰點(綠色圓圈)相似,而與負點及其相鄰點(紅色圓圈)不同。 2)右圖:鼓勵錨點與匹配的正點和屬于同一類別的其他點(綠色框中)相似,而與不同類別的負點(紅色框中)不同。
2、相關工作
2.1、弱監督點云分割
弱監督學習是降低高人工成本的有效方法。一些弱標記方法已經做了初步嘗試,例如標記一小部分點[18、33、38]或語義類[31]。現有方法使用各種手段來提高模型的表達能力。它們可以大致分為三類: 一致性正則化 在弱監督圖像分類中實現了透視性能[28、36、40]。Xu等人[33]介紹了一種點云特征的多分支監督方法,且采用了兩種類型的點云增強和一致性正則化。Zhang等人[38]通過擾動自蒸餾為隱式信息傳播提供了額外的監督。Shi等人[26]研究了label-efficient學習,并引入了基于 super-point的主動學習策略。盡管受益于不同網絡分支的一致性,但它們沒有考慮特征空間中的對比特性。 偽標記 根據由鄰域圖[11]或自訓練[19,35]指定的訓練模型[14,24]的預測創建監督。在弱監督環境中。Zhang等人[37]提出了一種基于轉移學習的方法,并引入稀疏偽標簽來正則化網絡學習。Hu等人[18]提出了一種自訓練策略,以利用偽標簽來提高網絡性能。Cheng等人[4]利用動態標簽傳播方案基于構建的超點圖生成偽標簽。然而,它們只使用偽標簽來獲得更多的監督信號,而忽略了標簽空間中的一致性屬性。 對比預訓練 首先由謝等人[32]提出,并通過提出點云場景的對比學習框架來啟動這項工作。然而,它主要關注具有100%標簽的下游任務。Hou等人[9]利用場景的內在屬性來擴展網絡可轉移性。Li等人[12]提出了引導點對比損失,并利用偽標記學習區分特征。然而,它們只在特征空間中進行point-level的對比,而忽略了點云的內在屬性,即幾何結構和類語義。 HybridCR重新設計了大規模點云的局部和全局的正負對,并充分探索了如何以端到端的方式利用且增強一致性和對比性。
2.2、點云增強
現有網絡中的數據增強[33,38]主要包括隨機旋轉、縮放和抖動,這些都是在整個訓練過程中手工/固定的。Li等人[15]提出了一種利用對抗學習策略的自動增強框架。Chen等人[3]通過實例之間的插值來說明這一點。Kim等人[13]利用局部加權變換產生非剛性變形。但是,他們只關注 object-level的點云。此外,在實際應用中實現它們很復雜,這在訓練期間給調整參數帶來了困難,并且僅關注object-level點云。我們引入了一個動態點云增強器,在訓練期間為大規模點云生成各種變換。 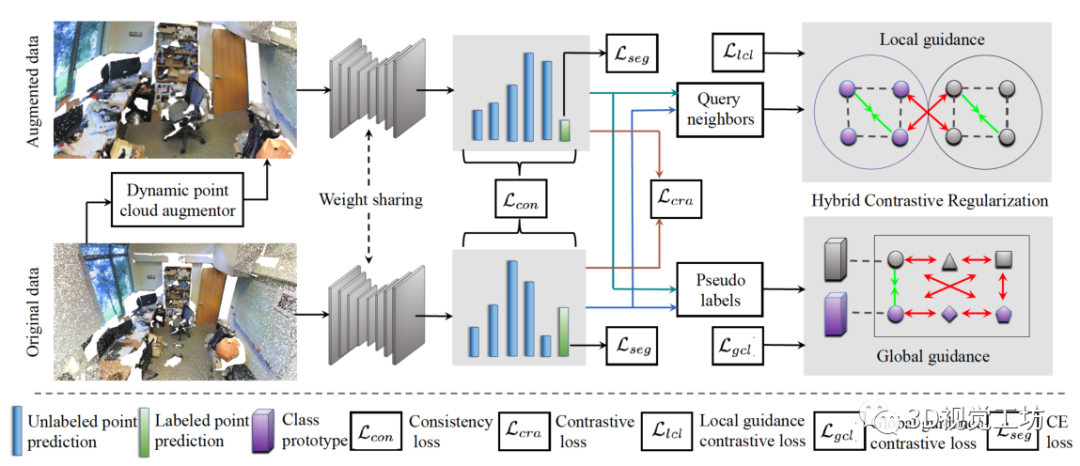 圖2. 原始點云首先被輸入動態增強器以生成增強點。然后,原始點和增強點通過Siamese網絡生成模型對所有點的預測,以及高置信度的未標記點的偽標簽。Point-level的一致性損失Lcon和對比損失Lcra用于所有點的預測,而softmax交叉熵損失Lseg用于有標記點的監督。同時,偽標簽用于計算每個類的原型。最后,HybridCR從局部和全局兩個角度進行,以形成局部和全局引導對比損失(即Llcl和Lgcl),為特征學習提供正則化。通過這種方式,HybridCR為端到端訓練方案中的弱監督框架服務。
圖2. 原始點云首先被輸入動態增強器以生成增強點。然后,原始點和增強點通過Siamese網絡生成模型對所有點的預測,以及高置信度的未標記點的偽標簽。Point-level的一致性損失Lcon和對比損失Lcra用于所有點的預測,而softmax交叉熵損失Lseg用于有標記點的監督。同時,偽標簽用于計算每個類的原型。最后,HybridCR從局部和全局兩個角度進行,以形成局部和全局引導對比損失(即Llcl和Lgcl),為特征學習提供正則化。通過這種方式,HybridCR為端到端訓練方案中的弱監督框架服務。
3、方法
在本部分中,我們首先描述了第3.1節中的符號和預備知識。然后,我們在第3.2節中介紹了具有局部和全局引導對比正則化的HybridCR的一般框架。接下來,我們在3.3節中介紹動態點云增強器。最后,我們在第3.4節中介紹了training的總體目標。
3.1、預備知識
問題設置和符號。

點級一致性和對比。點級一致性[33,38]已廣泛用于弱監督點云語義分割,它將具有不同增強的關聯點對強制到Siamese網絡中,以具有相同的特征表示。形式上,點級一致性損失公式為
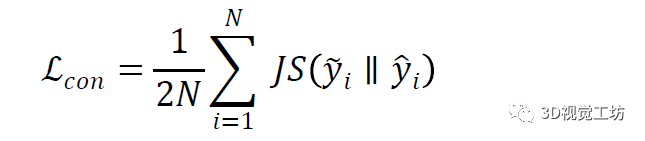


高級語義場景理解任務不僅需要局部信息,還需要全局信息,僅在point-level直接對比3D實例是不夠的[17,32]。因此,這促使我們探索更有效的對比策略,以充分利用點云在幾何結構和類語義中的固有特性。
3.2、混合對比正則化
如圖2所示,我們為大規模點云提出了一個緊湊的弱監督語義分割框架,該框架包含新型混合對比正則策略(HybridCR),且具有有效的動態點云增強器。原始點云首先被輸入到動態點云增強器,以生成不同的變換。然后,原始輸入點和增強點通過Siamese網絡,使用模型對未標記點的預測來生成偽標簽。通過使用不同變換的匹配3D點對,鼓勵模型在訓練期間學習相似和魯棒的特征。同時,生成的偽標簽用于計算每個類的原型。最后,在局部和全局引導的角度上,進行HybridCR,以學習未標記點和標記點之間的特征關系,這也利用了標記點的傳統分割損失,且具有點級一致性和對比損失。 3.2.1 局部引導對比正則化 局部鄰域信息對于點云對象的特征學習至關重要。例如,遮擋和孔洞始終存在于室內和室外場景的對象中。如果模型從其他完整對象中學習局部結構信息(球體、角點等),則可以在訓練期間增強模型對不完整對象的魯棒性。而點云的局部特征主要來自于點及其鄰域,這啟迪我們通過提出的局部引導對比正則化,來建模點云的局域信息。為了實現這一點,我們首先查詢錨點的相鄰點,然后促使每個點的不同增強視圖靠近其相鄰點,遠離其他點。

事實上,提出的局部引導對比損失更一般化為等式2。注意,如果K設置為1,等式4退化為等式2。 3.2.2 全局引導對比正則化

3.3、動態點云增強器
數據增強器是所提出的HybridCR中一個重要的組成部分,它生成各種錨點、正負樣本,并通過在輸入中添加特定噪聲來提取不變表示。受[15]的啟發,我們使用MLP和高斯噪聲來實現可學習的動態點云增強器,它豐富了上下文位移中的數據多樣性,并在同一場景中生成不同的變換。

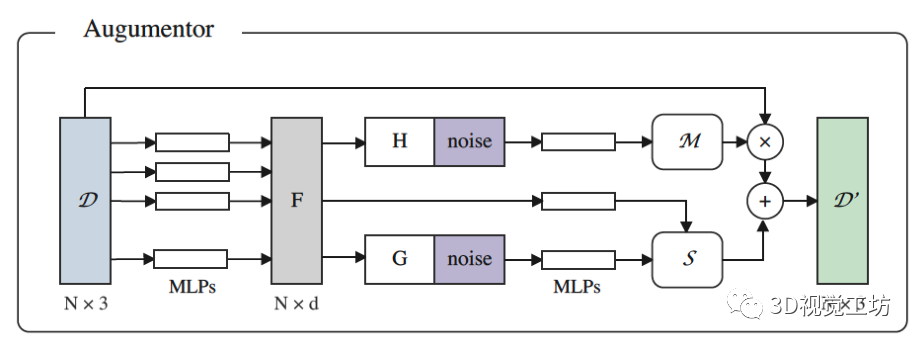 圖3. 動態點云增強器的架構。與[33,38]中采用的傳統增強器相比,在訓練期間進行了聯合優化。
圖3. 動態點云增強器的架構。與[33,38]中采用的傳統增強器相比,在訓練期間進行了聯合優化。
3.4、總體目標
如上所述,在端到端地訓練方案中,HybridCR可以作為弱監督點云語義分割框架的有效對比正則化策略。網絡的總體目標如下:

4、實驗
4.1、實驗設置
實驗數據集包含S3DIS[1]、ScanNetV2[6]、Semantic3D[8]和SemanticKITTI[2]。S3DIS是用于語義分割的常用室內3D點云數據集。它有271個點云場景,跨越6個區域,共13個類別。ScanNet-V2也是一個室內三維點云數據集,包含1613個三維掃描,共20個類別。整個數據集被分成訓練集(1201個掃描)、驗證集(312個掃描)和測試集(100個掃描)。Semantic3D是一個室外數據集,它提供了一個具有超過40億個點的大規模標記3D點云。它涵蓋了一系列不同的城市場景,原始3D點有8類,包含多種信息,如3D坐標、RGB信息和強度。SemanticKITTI是一個大型戶外點云數據集,用于自動駕駛場景中的3D語義分割,共有19個類。數據集包含22個序列,這些序列被劃分為訓練集(10個序列,有19k幀)、驗證集(1個序列,有4k幀)和測試集(11個序列,有20k幀)。 實現細節。我們使用初始學習率為0.001、動量為0.9的Adam優化器,在NVIDIA RTX Titan GPU上為所有數據集訓練100個epochs。相鄰點的數量K為16,batch-size為6,初始學習率為0.01,衰減率為0.98,每個epoch的迭代steps設置為500。注意,由于其有效性和效率,我們選擇基于點的backbone PSD[38]作為baseline。 評估協議。我們評估原始測試集中所有點的最終性能。為了進行定量比較,我們使用平均交并比(mIoU)作為度量標準。我們實驗研究了兩種類型的弱標記:1pt和1%設置。此外,我們將HybridCR擴展到全監督的方式。 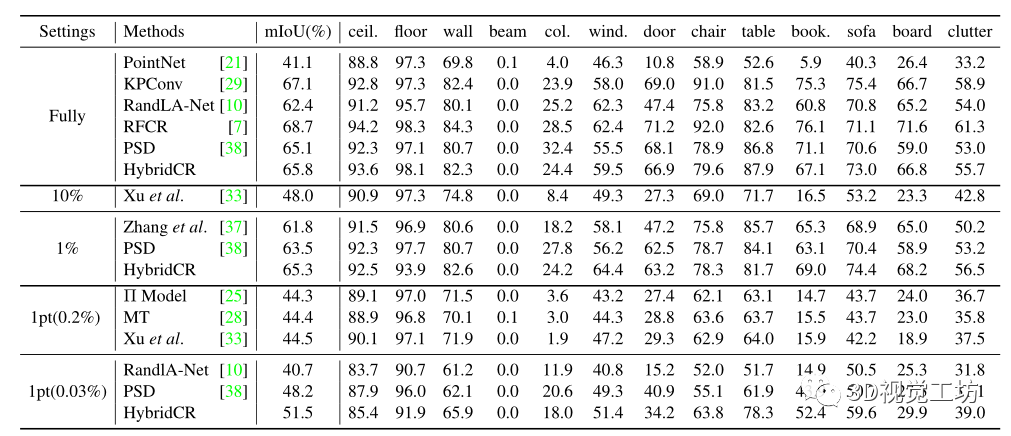 表1 . S3DIS區域5的定量結果。“*”表示我們使用官方代碼訓練的方法的結果。請注意,我們的1pt表示整個空間中每個類別僅有一個標記點,而不是Xu等人[33]的小塊(例如1×1米)。在我們的1pt設置中,標記點的數量占總點的0.03%,在Xu等人[33]中約為0.2%。
表1 . S3DIS區域5的定量結果。“*”表示我們使用官方代碼訓練的方法的結果。請注意,我們的1pt表示整個空間中每個類別僅有一個標記點,而不是Xu等人[33]的小塊(例如1×1米)。在我們的1pt設置中,標記點的數量占總點的0.03%,在Xu等人[33]中約為0.2%。
4.2、與SOTA方法比較
在S3DIS和ScanNet-V2上的定量結果。首先,我們將HybridCR與S3DIS Area-5上的SOTA方法進行了比較,其定量結果在表1中總結。顯然,與Zhang等人[37]、PSD[38]、Π模型[25]、MT[28]、Xu等人[33]和RandLA Net[10]相比,我們所提出的HybridCR在1pt和1%的設置下實現了最高的mIoU。例如,在1pt(0.03%)的設置時,我們的方法比PSD和RandLA Net分別高出3.3%和10.8%。此外,與Xu等人[33]相比,我們的方法還實現了7.0%的性能增益,Xu等人利用了約0.2%的更多點標記。在1pt(0.03%)設置下的特定類方面,我們的方法顯著提高了性能,相對于PSD,“椅子”、“桌子”和“沙發”分別提高了8.7%、16.4%和8.9%。 對于1%的設置,我們的方法比PSD baseline獲得1.8%的mIoU增益,甚至超過Xu等人在設置為10%時[33]。為了解釋這一點,我們的方法通過添加所提出的hydrid對比正則化,從大規模點云數據中學習不同的幾何結構。基于此,我們的方法僅使用1%的點來優于全監督的RandLA-Net和PSD。為了進行公平的比較,我們還擴展了在 6-fold設置時、基于S3DIS數據集與其他方法的比較,其結果如表2所示。對于ScanNet-V2,與基于場景或者subcloud-level標注的WyPR[23]和MPRM[31]相比,HybridCR在測試集上的1%設置下實現了56.8%的最高mIoU。同時,在相同數量的標注下,HybridCR比Zhang等人實現了5.7%的mIoU增益。此外,在全監督的情況下,我們的方法比RandLA-Net實現了2.1%的mIoU增益。 S3DIS和ScanNet-V2的定性結果。 我們分別在圖4和圖5中展示了S3DIS的定性結果和Scanne-V2的定量結果。在S3DIS上,與PSD相比,HybridCR在“板”和“椅子”上實現了更好的分割。此外,HybridCR的分割結果與真實情況非常一致。在ScanNet-V2上,我們觀察到HybridCR獲得了良好且真實的分割結果。在ScanNet-V2上,與PSD相比,HybridCR在“沙發”和“書桌”上表現良好。原因可能是,HybridCR可以有效地利用動態點云增強器生成的各種變換來提高表示能力并提高分割性能。 Semantic3D和SemanticKITTI的定量結果。我們進一步評估了在室外大型點云數據集Semantic3D(reduced-8)和SemanticKITTI上的HybridCR,并將結果分別顯示在表2中。對于Semantic3D,與Zhang等人[37]和PSD相比,我們的方法在1%的設置下也實現了更好的性能,mIoU改善了4.2%和1.0%。對于SemanticKITTI,我們的方法在1%的設置下,在驗證和測試數據集上報告的結果分別為51.9%和52.3%。可以看出,我們的方法在標注有限的情況下大大優于其他基于點的方法。 Semantic3D和SemanticKITTI的定性結果。 我們分別在圖6和圖7中給出了Semantic3D和SemanticKITTI的定性結果。在Semantic3D上,我們的方法是對PSD的改進,特別是實現了對“建筑物”的精確分割。在SemanticKITTI上,可以看出,我們的方法實現了與ground-truth的一致性分割結果,特別是在“道路”和“汽車”中,這兩個場景在自動駕駛應用中很難區分,但在稀疏的室外場景中很關鍵。結果證明了該方法在室外數據集上的有效性。 全監督設置的結果。 基于室內和室外數據集,我們進一步擴大了與當前SOTA方法的全監督設置上的比較,其定量結果在表2中總結。可以看出,HybridCR在它們之間具有競爭力。例如,HybridCR在S3DIS和ScanNet-V2上分別以0.7%和2.1%的mIoU改進超過了RandLA Net,在SemanticKITTI上獲得0.1%mIoU改善。此外,在mIoU中,HybridCR在Semantic3D上比KPConv高1.8%。 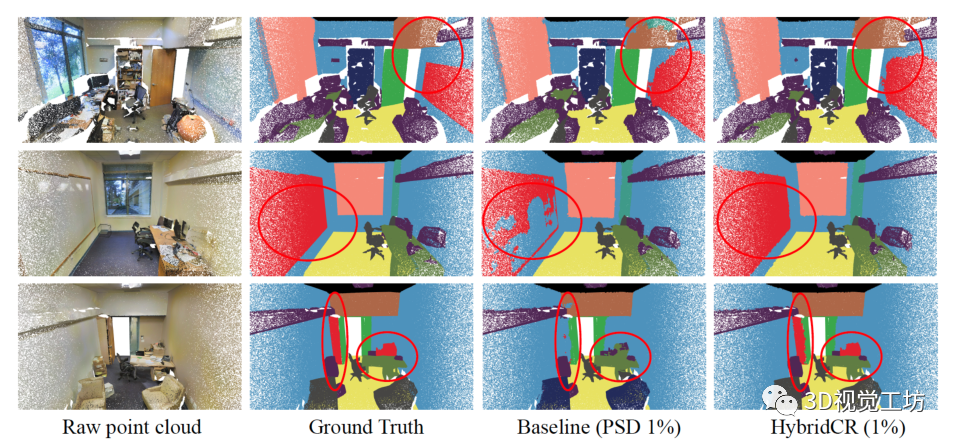 圖4. S3DIS Area-5測試集的可視化結果。原始點云、語義標簽、baseline結果和我們的結果,分別從左到右顯示。
圖4. S3DIS Area-5測試集的可視化結果。原始點云、語義標簽、baseline結果和我們的結果,分別從左到右顯示。 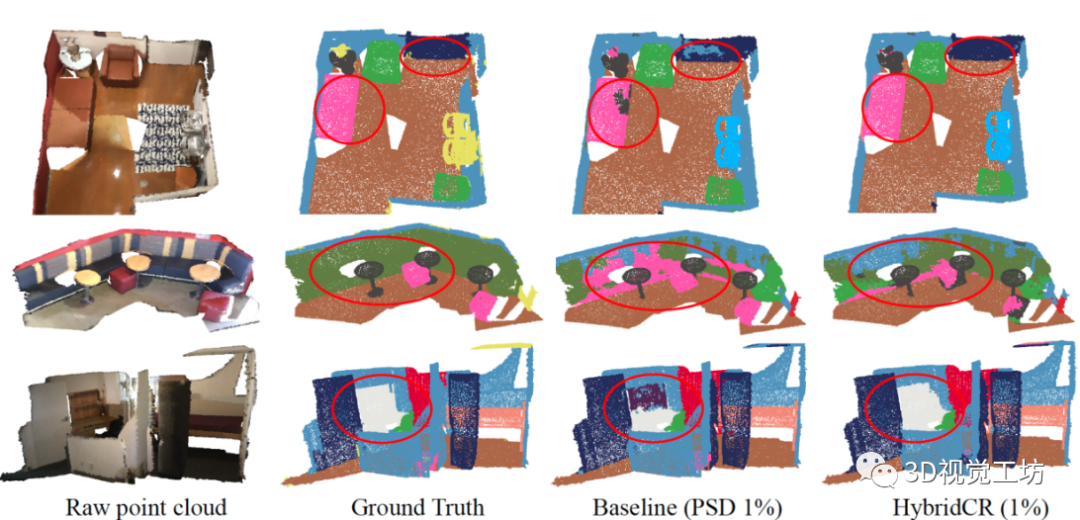 圖5. ScanNetV2驗證集的可視化結果。原始點云、語義標簽、基線結果和我們的結果,分別從左到右顯示。
圖5. ScanNetV2驗證集的可視化結果。原始點云、語義標簽、基線結果和我們的結果,分別從左到右顯示。 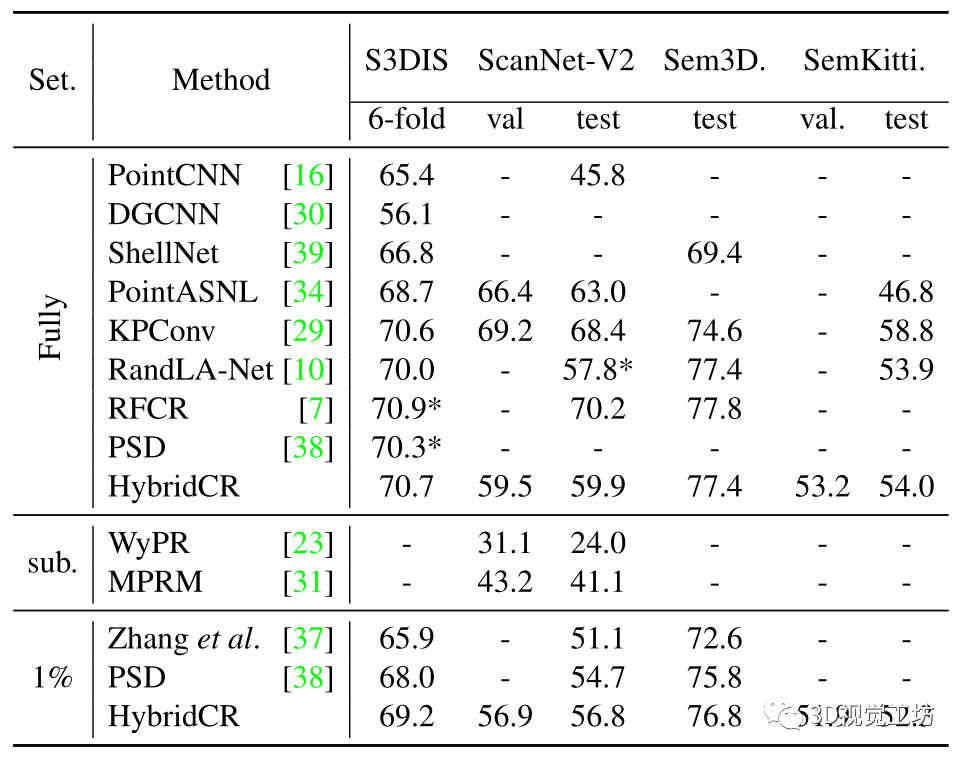 表2. S3DIS 6-fold、ScanNetV2驗證集、Semantic3D(reduced-8)和SemanticKITTI驗證集的定量結果(mIoU(%)),帶有完全標記數據和1%標記數據。特別地是,在100%標記數據的實驗中,我們的混合對比損失用作輔助特征學習損失。“*”表示我們使用官方代碼訓練的方法的結果。
表2. S3DIS 6-fold、ScanNetV2驗證集、Semantic3D(reduced-8)和SemanticKITTI驗證集的定量結果(mIoU(%)),帶有完全標記數據和1%標記數據。特別地是,在100%標記數據的實驗中,我們的混合對比損失用作輔助特征學習損失。“*”表示我們使用官方代碼訓練的方法的結果。 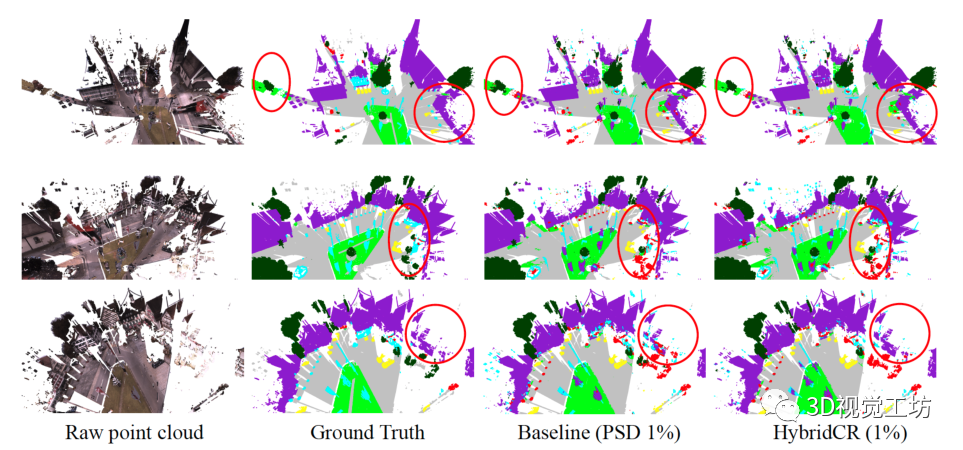 圖6. Semantic3D驗證集的可視化。原始點云、語義標簽、基線結果和我們的結果,從左到右分別顯示。
圖6. Semantic3D驗證集的可視化。原始點云、語義標簽、基線結果和我們的結果,從左到右分別顯示。 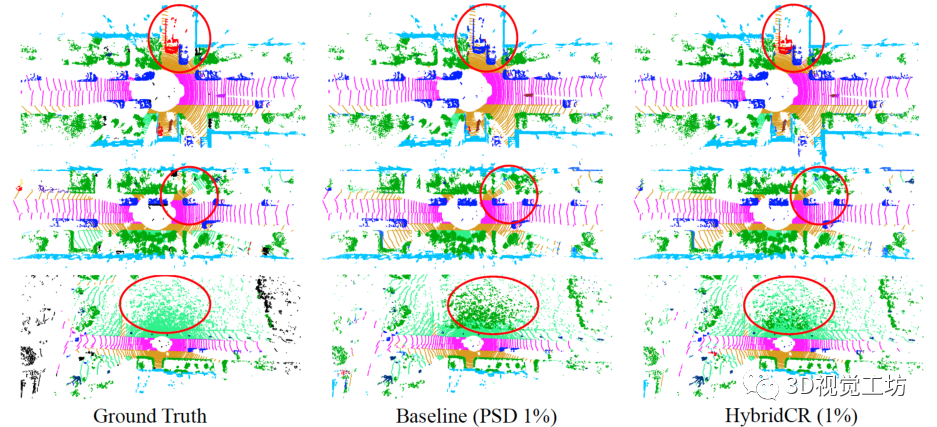 圖7. SemanticKITTI驗證集的可視化結果。語義標簽、基線結果和我們的結果,從左到右分別顯示。
圖7. SemanticKITTI驗證集的可視化結果。語義標簽、基線結果和我們的結果,從左到右分別顯示。
4.3、消融研究
我們進一步評估消融研究的基本組件的有效性,包括動態點云增強器和局部/全局引導對比正則化。所有實驗均在S3DIS Area-5上進行,結果如表3所示。請注意,#1由PSD報告,而#8由HybridCR報告,我們使用平均值和標準偏差(5 runs)報告結果。 動態數據增廣器的有效性。為了驗證數據增廣帶來的改進,我們比較了Base。在帶有數據增強時,進行相比,在1pt和1%的設置下,#1和#2分別獲得了2.5%和1.0%的增益。對于#5和#8,在1pt和1%設置下,其分別比HybridCR獲得了0.4%和0.3%的增益。結果表明,通過不同的轉換,HybridCR從數據增強中獲得了許多好處。 局部引導對比損失的有效性。在1pt和1%設置下,從#1和#3的比較來看,它在mIoU方面分別比Base 優于1.6%和0.4%。對于#7和#8,其分別比HybridCR提高0.5%和0.2%。這些結果表明。這進一步提高了性能,因為它在增強特征學習的同時,利用了模型訓練期間的相鄰信息。 全局引導對比損失的有效性。類似地,從#1和#4的比較來看,它優于Base。在1pt和1%的設置下分別增加2.0%和0.5%。對于#6和#8,它分別比HybridCR獲得1.3%和0.6%的增益。結果表明,全局引導利用類原型有效地提高了弱監督語義分割任務的性能。 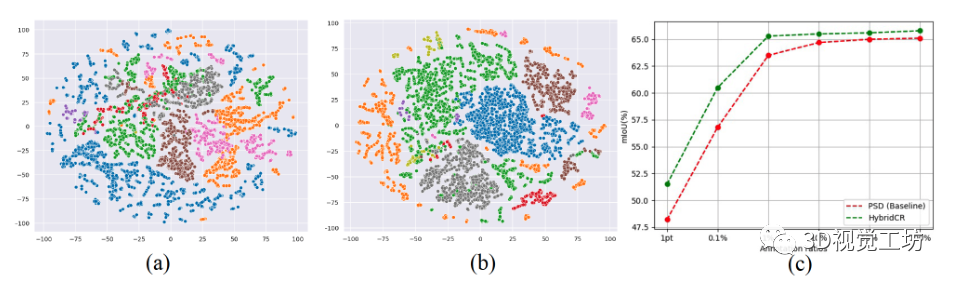 圖8. 1%設置下點embedding的可視化。(a) 是PSD的embedding,(b)是HybridCR的embedding。從S3DIS的測試集中隨機選擇場景。(c)是標記點的數量與性能之間的關系。
圖8. 1%設置下點embedding的可視化。(a) 是PSD的embedding,(b)是HybridCR的embedding。從S3DIS的測試集中隨機選擇場景。(c)是標記點的數量與性能之間的關系。
4.4、分析
點embedding的可視化。如圖8(a)和(b)所示,與PSD相比,HybridCR學習的點embedding變得更加緊湊和分離。這表明,通過利用局部和全局引導對比損失以及動態點云增強器生成的有效變換,分割網絡可以生成更多的區別特征,并產生有前景的結果。 標記點和性能。在圖8(c)中,我們進一步討論了性能與標記比率{1pt,0.1%,1%,10%,50%,100%}之間的關系。隨著比率的增加,兩種方法的性能都有所提高,增長趨勢逐漸放緩。注意,當比率小于1%時,性能略有下降,這表明保持一定量的監督信號是必要的。此外,當比率為10%時的性能接近100%,這表明不需要密集標注來獲得良好的分割結果。 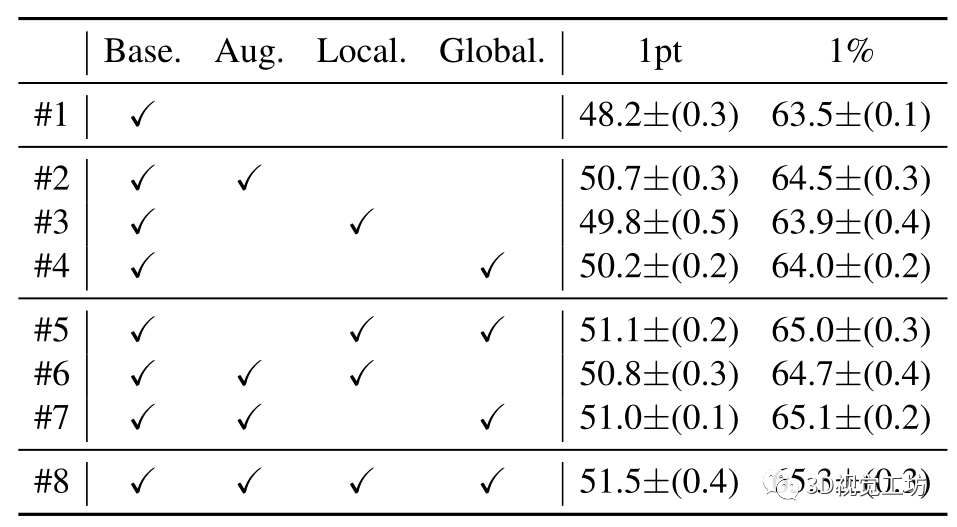 表3. S3DIS Area-5上不同組件的消融實驗情況。
表3. S3DIS Area-5上不同組件的消融實驗情況。
5、結論
在本文中,我們提出了一種用于弱監督大規模點云語義分割的混合對比正則化框架。利用我們提出的局部和全局引導對比正則化,網絡通過利用相鄰點和偽標簽學習更多的鑒別特征。同時,我們提出了一種動態點云增強器,用于在訓練過程中通過聯合優化實現更多樣的轉換,從而有利于對比策略。室內和室外數據集的大量實驗結果表明,和SOTA方法相比,HybridCR獲得了顯著的增益。此外,消融研究驗證了引入的關鍵部件的有效性。結果進一步證明了我們的方法利用有限標記的大規模點云方面的有效性,并提高模型的泛化能力。
-
3D
+關注
關注
9文章
2910瀏覽量
107991 -
數據
+關注
關注
8文章
7139瀏覽量
89569 -
深度學習
+關注
關注
73文章
5513瀏覽量
121544
原文標題:HybridCR:基于混合對比正則化的弱監督3D點云語義分割(CVPR 2022)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種基于機器學習的建筑物分割掩模自動正則化和多邊形化方法
van-自然和醫學圖像的深度語義分割:網絡結構
一個benchmark實現大規模數據集上的OOD檢測
半監督的譜聚類圖像分割


如何縮小弱監督信號與密集預測之間的差距
第一個大規模點云的自監督預訓練MAE算法Voxel-MAE
普通視覺Transformer(ViT)用于語義分割的能力
點云分割相較圖像分割的優勢是啥?
一種在線激光雷達語義分割框架MemorySeg





 工商網監
工商網監
評論