 關于內存緩存的那些事
關于內存緩存的那些事
內存中的數據被劃分成若干個緩存塊,每個緩存塊的大小正好對應著一整個三級緩存的大小。如此一來,數據在內存中緩存塊里的偏移量正好就對應著該數據應該存在于緩存中的位置。舉個例子,假設內存中一共有四個緩存塊,記為00,01,10,11四塊。每個緩存塊又可以劃分成四個緩存行,記為00,01,10,11四行。結合起來,最上面緩存塊的最上面的緩存行就可以寫成0000,則這個部分的數據應該存在于緩存中的第一個緩存行的位置即00位置。如果1000號緩存行需要寫入,那么就要把0000號緩存行擦除再寫入,不能存儲在緩存中別的地方即使還有空間存放。
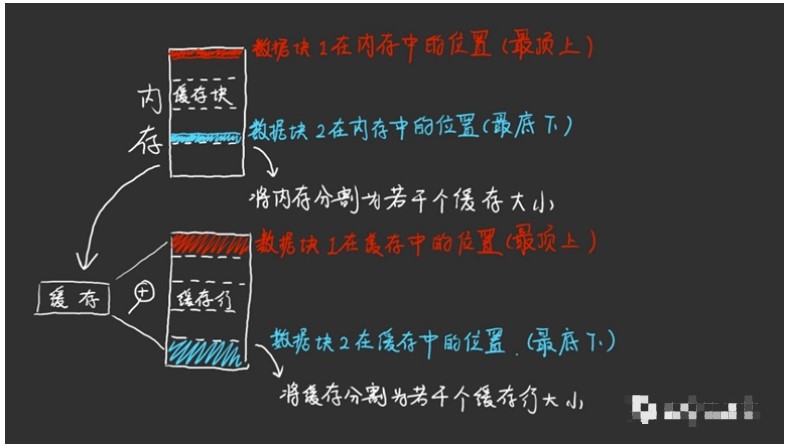
從內存到緩存的分類規則
我們會發現一個問題,就是如果我們持續需要0000號緩存行和1000號緩存行中的數據,那么這倆緩存行會被互相擦除寫入,就像打乒乓球一樣,擦了又寫,寫了又擦,而緩存中可能別的位置還空著,造成浪費資源,效率低下的乒乓效應。
解決的辦法之一就是加大緩存容量。很好理解,緩存變大了,取一個極限,假設緩存和內存一樣大了,那肯定就不存在乒乓效應了,但是這幾乎不可能。
還有一個有意思的思路是,設置一個受害者緩存,(哈哈,這個英文名是我自己亂翻譯的)。這個受害者緩存會暫時保留一下不久前剛被擦除的數據,緩存控制器在讀取緩存時就捎帶看看這個受害者緩存里有沒有想要的數據,如果真的碰到了,那這個數據真就是受害了,冤的很。這個電路實現也很簡單,沒啥難度,就是效果可能有點玄學。
有沒有什么不那么玄學的方法呢?于是前人提出了多路組關聯。既然前文如此粗暴的分割方式會造成乒乓效應,那么我們干脆多來幾個可替換的位置。還是以上面的例子,假設內存中一共有四個緩存塊,記為00,01,10,11四塊。每個緩存塊又可以劃分成四個緩存行,記為00,01,10,11四行。現在不同的是我們把緩存劃分成兩路,暫且叫做A路和B路吧。保持和上文中的緩存容量大小一致,那么每路緩存中現在只夠存儲兩個緩存行了,記為0號和1號緩存行。總結一下,現在緩存方面有AB兩路,每路有01兩行。內存方面則一共有四個緩存塊,每個緩存塊有四個緩存行。現在規定內存中緩存行編號最后一位是0的可以存在緩存的A或B路的0號緩存行中,內存中緩存行編號最后一位是1的可以存在緩存的A或B路的1號緩存行中。發現問題沒有?因為末尾為同一編號的緩存行可以同時存在于A或者B中,因此乒乓效應會有所改善。
上述例子展示的是兩路組關聯,目前主流使用的是四路組關聯,但實際上路的個數要結合緩存與內存的比例來綜合判斷,例如上述例子,兩路組關聯就不太合適,單路的容量被壓縮得太小了。
另外,上文所講的是內存和三級緩存之間的關聯情況,該情況可以推廣至三級緩存和二級緩存之間以及二級緩存和一級緩存之間。在此就不再贅述了。
這里還是要注意一個之前說過的細節,CPU并不會主動控制緩存寫入內存中的數據的,也就是說緩存對于CPU來講是透明的(這個詞不是很容易理解,但是這就是之前人們翻譯的,我建議翻譯成無感知)。CPU只是說我要讀這塊內存里的數據,它甚至不知道這個內存數據在哪里,它只負責宣布這件事,而緩存和內存則負責把它要的數據喂給它而已。緩存在喂給它之后留了個“心眼”——“咱家主子(CPU)最近偏愛000110100這塊內存數據,我就把這塊數據留在我這里,到時候要的時候拿著方便“。看懂了嗎?一切都是奴才自作主張。
再打個比方,CPU和緩存的關系就像我和我的胃。我不用控制我的胃蠕動消化,我不用控制神經元突觸釋放神經遞質,我只負責做最高級,最抽象的工作,比如控制我的手寫下這篇文章。我不知道我有胃這種東西,也不知道什么神經遞質、細胞、組織啥的,就像CPU不知道緩存一樣,我之所以知道這些是因為有人做了人體解剖等生物研究,CPU想了解這些可能得等人工智能解剖另一個人工智能的時候,或者——用它的意識來讀讀我這篇文章。
話說回來,各級緩存之間有兩種不太相同的緩存策略,分別是Inclusive和Exclusive。
前者意思是包含,后者意思是不包含。包含的意思是,三級緩存中一定會存在著二級緩存和一級緩存里的數據,二級緩存一定會存在著一級緩存的數據,其實質就是數據從三級往一級走的過程中用的是“復制”。
而不包含的意思是,三級緩存中必不存在二級緩存和一級緩存里的數據,二級緩存中必不存在一級緩存的數據,其實質就是數據從三級往一級走的過程中用的是“剪切”。這兩種緩存策略的優劣應該一眼能看出:包含策略會造成緩存空間浪費,并且各級之間的數據更新需要保持同步,優點則是數據的廢除很直接,還有一個優點這里先挖個坑吧。而不包含策略則不會造成緩存浪費,并且具有很好的緩存一致性(即不需要同步),但是數據交換量會變得很大。
這里分別用緩存寫入數據的例子說說包含和不包含兩種緩存策略。一開始,CPU首先發出一個讀內存指令,該指令會附帶著該內存地址從CPU內核轉發至一級緩存控制器,假設一級緩存沒有在本級緩存找到想要的數據,那么就會將讀內存指令的請求往二級緩存控制器轉發,以此類推,如果都沒能找到數據,那么最后內存控制器會得到這條讀內存指令,并將數據返回至CPU內核,同時該條數據會在CPU的一級緩存上得到保存(如果是使用Inclusive緩存策略,那么該數據也同時會在二級和三級緩存上得到保存),以便于下次再次使用。然而緩存在電腦開機之后不久肯定就被填滿了,這時候要有新的數據要寫入緩存那么肯定需要把一些過時的數據給替換出去。那么具體是怎么個替換策略呢?這就考驗奴才們對于主子心思的把控了。這時候有個聰明的奴才在總結了多次經驗后,提出了LRU替換策略,中文名譯為最近最少使用替換策略,很容易理解,就是最近最少使用的數據將會被新數據替換掉。
而包含和不包含的區別在這里就會有所體現。如果是包含策略,那么新數據直接覆蓋舊數據即可,舊數據等于直接作廢,除非這個數據最近在CPU中被改寫過,需要返回到內存中進行保存,那么才需要將該緩存行刷回內存(那么如何確定該緩存行是否被改寫過呢?可以用一個名為dirty的標志位注明)。而如果是不包含策略,那么一級緩存淘汰下來的數據就要放置到二級緩存,如果不巧二級緩存也滿了,那么仍需淘汰一個緩存下來。當然,你也可以選擇如果二級緩存或者三級緩存沒空位,那么就直接把淘汰下來的數據扔回內存,但是這樣命中率就會嚴重下降(等于整個緩存體系的容量和一級緩存是一樣大的)。并且如果是二級緩存或者三級緩存中的數據要寫入到一級緩存中,那么需要把該二級或者三級緩存的緩存行與一級緩存做一個交換,而不是覆蓋。
那究竟是用Inclusive還是Exclusive呢?各大CPU廠商給出了答案,Exclusive成為目前主流使用的緩存策略。Intel前幾年還在用Inclusive來著,最近這幾年也轉而使用了Exclusive,說明Exclusive的優勢比我們想象的大。
審核編輯:劉清
-
控制器
+關注
關注
112文章
16445瀏覽量
179451 -
cpu
+關注
關注
68文章
10902瀏覽量
213013 -
緩存器
+關注
關注
0文章
63瀏覽量
11692
發布評論請先 登錄
相關推薦
Linux服務器卡頓救星之一招釋放Cache內存
緩存對大數據處理的影響分析
HTTP緩存頭的使用 本地緩存與遠程緩存的區別
緩存技術在軟件開發中的應用
緩存之美——如何選擇合適的本地緩存?
智算中心網絡交換機需要什么樣的緩存架構

如何優化RAM內存使用
Cache和內存有什么區別
什么是CPU緩存?它有哪些作用?
芯片設計流片、驗證、成本的那些事

如何檢測內存泄漏
ESP8266緩存AP后,是否會自動連接到任何緩存的AP?
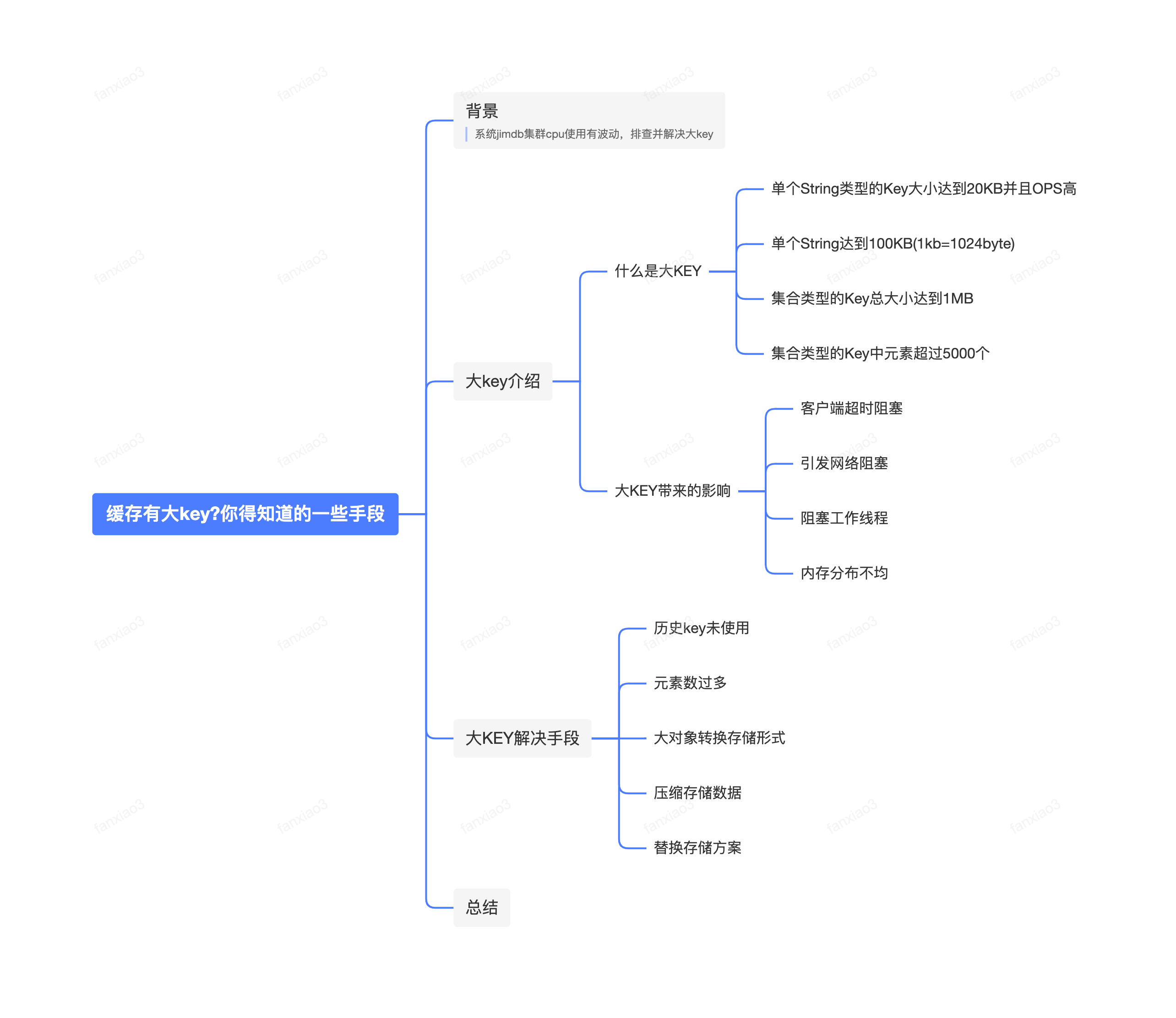
緩存有大key?你得知道的一些手段





 工商網監
工商網監
評論