 TVM學習之從relay到TOPI
TVM學習之從relay到TOPI
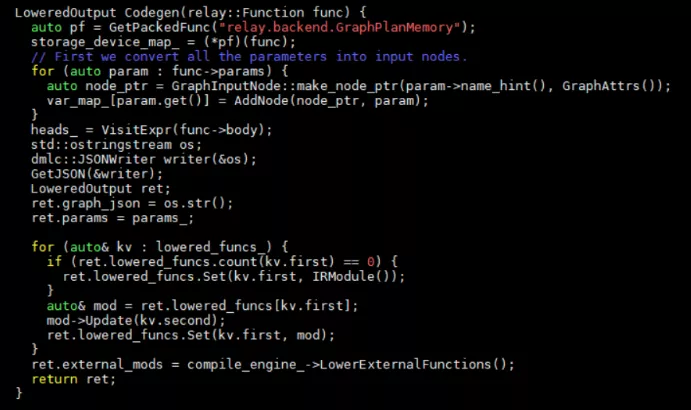
Lower操作完成從高級算子(relay)到低級算子(TOPI)的轉化。Lower開始于以下代碼(src/relay/backend/graph_runtime_codegen.cc):
LoweredOutput Codegen(relay::Function func) {
auto pf = GetPackedFunc("relay.backend.GraphPlanMemory");
storage_device_map_ = (*pf)(func);
// First we convert all the parameters into input nodes.
for (auto param : func->params) {
auto node_ptr = GraphInputNode::make_node_ptr(param->name_hint(), GraphAttrs());
var_map_[param.get()] = AddNode(node_ptr, param);
}
heads_ = VisitExpr(func->body);
std::ostringstream os;
dmlc::JSONWriter writer(&os);
GetJSON(&writer);
LoweredOutput ret;
ret.graph_json = os.str();
ret.params = params_;
for (auto& kv : lowered_funcs_) {
if (ret.lowered_funcs.count(kv.first) == 0) {
ret.lowered_funcs.Set(kv.first, IRModule());
}
auto& mod = ret.lowered_funcs[kv.first];
mod->Update(kv.second);
ret.lowered_funcs.Set(kv.first, mod);
}
ret.external_mods = compile_engine_->LowerExternalFunctions();
return ret;
}
在完成內存申請優化之后,VisitExpr對圖進行遍歷并lower每個relay算子。我們來看CallNode節點的處理。主要代碼如下:
auto pf0 = GetPackedFunc("relay.backend._make_CCacheKey");
auto pf1 = GetPackedFunc("relay.backend._CompileEngineLower");
Target target;
// Handle external function
if (func->GetAttr(attr::kCompiler).defined()) {
target = tvm::target::ext_dev();
CCacheKey key = (*pf0)(func, target);
CachedFunc ext_func = (*pf1)(compile_engine_, key);
這一步是當存在外部compiler的時候,使用外部compiler進行lower。CCacheKey將function和target打包到一起,可能是方便后邊compiler的調用。而lower函數會調用src/relay/backend/compile_engine.cc中CompileEngineImpl類中的LowerInternal函數,在這個函數中實現了外部編譯器lower和內部lower的代碼,如果是有外部compiler參與,其將function,target等打包成CCacheValue返回,等待后邊外部編譯器統一處理。
如果沒有外部編譯器,那么TVM將對relay算子轉換到TOPI庫中算子。
CachedFunc lowered_func = (*pf1)(compile_engine_, key);
if (!lowered_funcs_.count(target->str())) {
lowered_funcs_[target->str()] = IRModule();
}
lowered_funcs_[target->str()]->Update(lowered_func->funcs);
return GraphAddCallNode(op, _GetUniqueName(lowered_func->func_name), lowered_func->func_name);
同樣會調用LowerInternal函數,首先建立schedule:
CachedFunc CreateSchedule(const Function& source_func, const Target& target) {
return ScheduleGetter(target).Create(source_func);
}
在Create函數中,首先將inputs都轉換成te的算子表示:
for (Var param : prim_func-> params) {
Array inputs;
if (const auto* ttype = param->checked_type().as< TensorTypeNode>()) {
tvm::te::Tensor tensor = tvm::te::placeholder(GetShape(ttype-> shape), ttype->dtype);
cache_node-> inputs.push_back(tensor);
inputs.push_back(tensor);
} else {
// flatten tuple of tensor type.
const auto* tuple_type = param-> type_as ();
for (Type field : tuple_type-> fields) {
const auto* ttype = field.as< TensorTypeNode> ();
// TODO(@icemelon): Allow recursive tuple
CHECK(ttype != nullptr);
tvm::te::Tensor tensor = tvm::te::placeholder(GetShape(ttype-> shape), ttype-> dtype);
cache_node-> inputs.push_back(tensor);
inputs.push_back(tensor);
}
}
memo_[param] = inputs;
}
然后遍歷其它node來實現lower操作。
我們還是來看CallNode的訪問。
Array VisitExpr_(const CallNode* call_node) final {
static auto fpattern = Op::GetAttrMap("TOpPattern");
static auto flower_call = tvm::runtime::Registry::Get("relay.backend.lower_call");
CHECK(flower_call) << "relay.backend.lower_call is not registered.";
Array inputs;
int count_tuple = 0;
for (Expr arg : call_node->args) {
if (arg->checked_type().as()) {
++count_tuple;
}
for (te::Tensor tensor : VisitExpr(arg)) {
inputs.push_back(tensor);
}
}
if (count_tuple) {
CHECK_EQ(call_node-> args.size(), 1U) << "Only allow function with a single tuple input";
}
CHECK(call_node->op.as>OpNode> ()) >> "Primitive function only allows call into primitive ops";
Op op = Downcast>Op>(call_node-> op);
Array>te::Tensor> outputs;
OpImplementation impl;
// Skip fcompute for device copy operators as it is not registered.
if (op == device_copy_op_) {
const auto* copy_input = inputs[0].operator->();
outputs.push_back(te::Tensor(copy_input->shape, copy_input->dtype, te::Operation(), 0));
} else {
LoweredOutput lowered_out = (*flower_call)(GetRef>Call>(call_node), inputs, target_);
outputs = lowered_out->outputs;
這里lower操作會去調用python中注冊的lower_call函數,這個函數位于python/tvm/relay/backend/compile_engine.py中。在這個函數中最主要的是select_implementation。
Select_implementation是去選擇relay算子的一個TOPI層級的實現方式。同一個relay算子在不同target上有不同實現方式,具體采用哪種方式要依據target的屬性。在select_implementation中首先通過gat_valid_implementation獲得所有已經注冊的實現方式。
fstrategy = op.get_attr("FTVMStrategy")
assert fstrategy is not None, "%s doesn't have FTVMStrategy registered" % op.name
with target:
strategy = fstrategy(attrs, inputs, out_type, target)
analyzer = tvm.arith.Analyzer()
ret = []
for spec in strategy.specializations:
if spec.condition:
# check if all the clauses in the specialized condition are true
flag = True
for clause in spec.condition.clauses:
clause = analyzer.canonical_simplify(clause)
if isinstance(clause, tvm.tir.IntImm) and clause.value:
continue
flag = False
break
if flag:
for impl in spec.implementations:
ret.append(impl)
else:
for impl in spec.implementations:
ret.append(impl)
return ret
fstrategy指向的是op attr的"FTVMStrategy"對應的函數。比如con2d注冊的策略有:
def conv2d_strategy(attrs, inputs, out_type, target):
"""conv2d generic strategy"""
logger.warning("conv2d is not optimized for this platform.")
strategy = _op.OpStrategy()
data, kernel = inputs
dilation = get_const_tuple(attrs.dilation)
groups = attrs.groups
layout = attrs.data_layout
kernel_layout = attrs.kernel_layout
(dilation_h, dilation_w) = dilation
if dilation_h > 1 or dilation_w > 1:
raise ValueError("dilation should be positive value")
if groups == 1:
if layout == "NCHW":
assert kernel_layout == "OIHW"
strategy.add_implementation(
wrap_compute_conv2d(topi.nn.conv2d_nchw),
wrap_topi_schedule(topi.generic.schedule_conv2d_nchw),
nam)
可見一個conv2d即使同一個target也會注冊不同的策略。Add_implementation將會把compute,schedule的具體函數注冊到strategy中。Strategy是一個包含了一個relay算子implementation方式的數據結構。它包含了很多OpSpecialization,每個OpSpecialization中包含一些列OpImplementation,OpImplementation中就對應著schedule和compute的具體方式,schedule是一個算子計算的排布,compute是對應了TOPI庫算子。
獲得了所有有效implementation之后,會依據兩種方式選擇,一種是通過auto TVM來自動化搜索最優的實現方式,另外一種在不適用auto TVM工具情況下,會選擇plevel最大的implementation。選擇好了implementation之后,就調用src/relay/backend/compile_engine.cc中的LoweredOutput類建立一個實例。可以看出,lower_call實現了將relay算子統一用更底層的的抽象進行了表示。這種表示中包含了relay算子,以及這個算子的計算方式以及schedule信息。這樣就方便后邊對其進行schedule優化了。
然后將這些LoweredOutput進行打包成CachedFuncNode。CachedFuncNode會作為后邊schedule優化的入參。
審核編輯:湯梓紅
-
TVM
+關注
關注
0文章
19瀏覽量
3689 -
relay
+關注
關注
0文章
1瀏覽量
4478
發布評論請先 登錄
相關推薦
TVM主要的編譯過程解析
TVM整體結構,TVM代碼的基本構成
什么是frame relay,frame relay概念
將TVM用于移動端常見的ARM GPU,提高移動設備對深度學習的支持能力
什么是波場虛擬機TVM
TVM的編譯流程是什么

TVM學習(三)編譯流程
TVM學習(四)codegen
TVM學習(二):算符融合
使用TVM在android中進行Mobilenet SSD部署

TVM學習(八)pass總結






 工商網監
工商網監
評論