 在沒有機器學習技能的情況下實施預測性維護
在沒有機器學習技能的情況下實施預測性維護
如今,工程師們越來越意識到,預測性維護現在幾乎是人工智能 (AI) 技術的專有領域,他們首先需要學習機器學習 (ML) 和神經網絡技能來實現此類應用程序。MathWorks 高級產品營銷經理 Aditya Baru 表示,工程師仍然可以部署預測性維護,而無需學習新的 AI 和 ML 技能。
在最近與EDN的一次談話中,Baru 概述了實施預測性維護的四個基本步驟,并補充說每個步驟都有專門的工具可用。
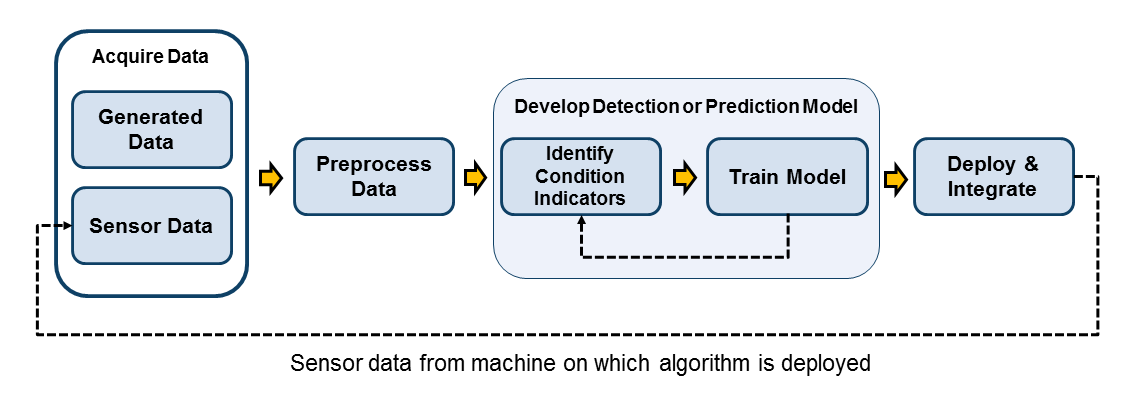
圖 1. 基本的預測性維護工作流程包括四個基本步驟。
1.數據處理
對于不是數據科學家或沒有機器學習背景的工程師來說,查看由傳感器和工業設備(如風力渦輪機、發電機、泵和電機)生成的大量數據并不容易。工程師處理的數據主要是原始數據;它又臟又臟。
勘探作業中的噴氣發動機或油泵每天可以輕松創建 1TB 的數據;現在想象一下在 TB 的數據中尋找故障條件。那么,工程師能做什么呢?“工程師可以查看大量傳入的數據,找出原始數據中是否有任何變化,識別任何系統退化,并確定系統出現異常行為的原因,”Baru 說。
例如,在石油勘探泵中,工程師可以查看原始數據的一件事是對持續旋轉的泵進行光譜分析。因此,他們可以識別故障出現的頻率。“雖然工程師已經了解這臺機器,但他們現在要做的是確定最有效的方法。”
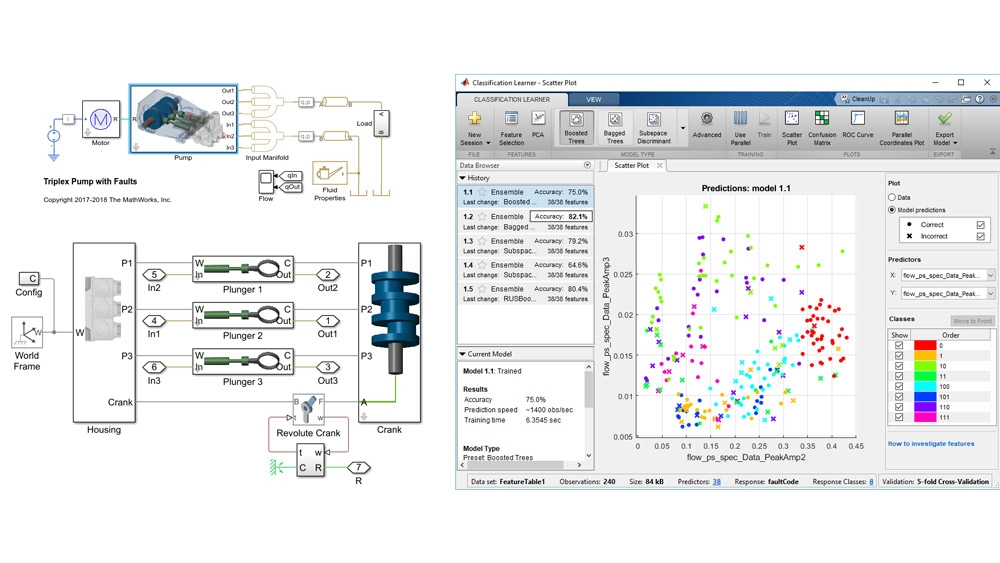
圖 2. 工程師可以通過跟蹤電機摩擦的變化來檢測泵中的泄漏和堵塞。
這將我們帶到第二個基本步驟,條件指標,一種數據縮減方法。
2.狀態指標
如果工程師有 100 個時間序列數據樣本,他應該設法將其減少到一個數字,而這個數字必須捕獲這 100 個樣本中的所有相關信息。“我們的想法是你獲取一個巨大的數據集并將其減少為更少的特征。”
Baru 提到了最近的一個項目,在該項目中,MathWorks 與戴姆勒梅賽德斯合作開發了一個異常檢測應用程序,該應用程序分析大量時間序列數據并確定生產線是否存在異常情況。在這里,MathWorks 工具將大量數據減少為一組較小的特征(例如模式和時間延遲),從而將數據處理減少了 250 倍。
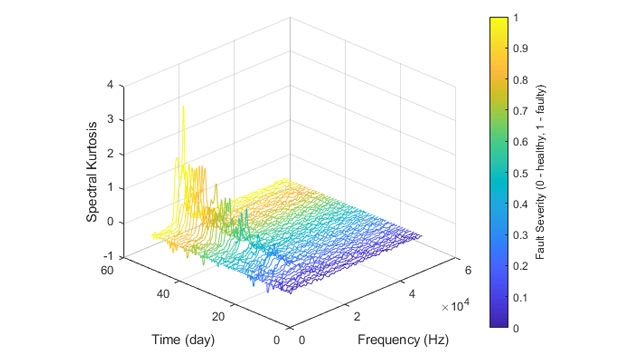
圖 3. 工程師可以從原始傳感器數據中提取特征,并使用基于時間和頻率的技術創建條件指標。資料來源:數學工作
現在工程師正在研究較少數量的條件指標,他們可以根據這些條件指標構建預測模型。
3.預測模型
使用代表整個大型數據集并捕獲獨特信息的小得多的數據集,工程師可以使用合適的工具來創建預測學習模型,而無需學習 AI 和 ML 技能集。
各種模型(例如時間序列模型、統計模型和基于概率的模型)同樣適用于構建預測模型。“有很多用于構建預測模型的傳統工程技術,”Baru 說。
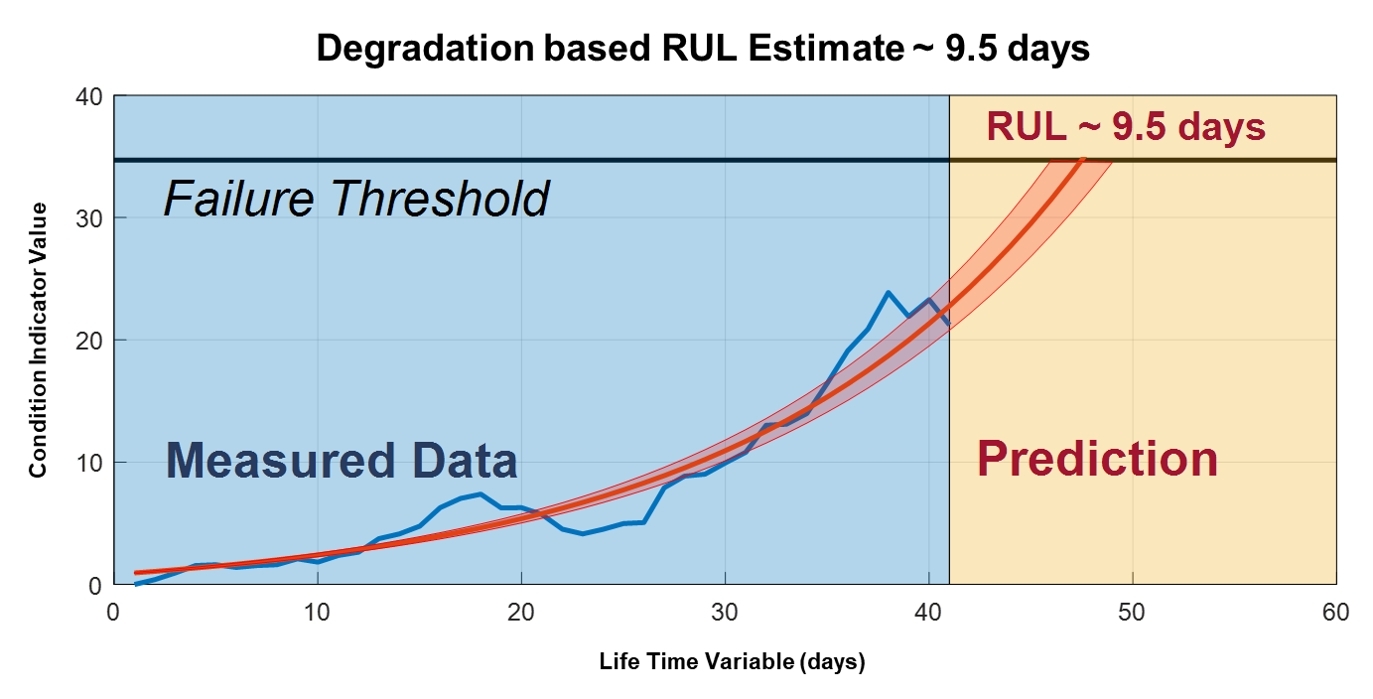
圖 4. Predictive Maintenance Toolbox使工程師能夠估計剩余使用壽命 (RUL) 并提供與預測相關的置信區間。資料來源:MathWorks
工程師還可以將工具重新用于稍微不同的應用程序。Baru 提到了 Safran,這是一家航空航天公司,它使用信號調理技術來預測系統何時可能出現故障。這項工作是在MATLAB中完成的,這是一個用于算法開發、數據分析、可視化和數值計算的編程環境。
4.算法部署
第四步可能是最重要的:在生產環境中為預測模型部署算法。工程師可以通過多種方式部署算法。這包括本地嵌入機器的預測模型、作為本地服務器在本地運行的小型計算機,或者在連接可行時將數據流式傳輸到云服務。
在這個四步工作流程中實施的預測性維護允許工程師部署維護服務,以保證機器在 90% 的時間內保持運行。并且可以使用工具來有效地管理所有這四個基本步驟。
審核編輯:郭婷
-
發電機
+關注
關注
26文章
1654瀏覽量
67936 -
人工智能
+關注
關注
1796文章
47666瀏覽量
240274 -
機器學習
+關注
關注
66文章
8438瀏覽量
133080
發布評論請先 登錄
相關推薦
傳感器在工業 4.0 預測性維護中的應用







 工商網監
工商網監
評論