 對比學習中的4種典型范式的應用分析
對比學習中的4種典型范式的應用分析
對比學習是無監督表示學習中一種非常有效的方法,核心思路是訓練query和key的Encoder,讓這個Encoder對相匹配的query和key生成的編碼距離接近,不匹配的編碼距離遠。想讓對比學習效果好,一個核心點是擴大對比樣本(負樣本)的數量,即每次更新梯度時,query見到的不匹配key的數量。負樣本數量越多,越接近對比學習的實際目標,即query和所有不匹配的key都距離遠。
對比學習目前有4種最典型的范式,分別為End-to-End、Memory Bank、Momentum Encoder以及In-Batch Negtive。這幾種對比學習結構的差異主要體現在對負樣本的處理上,4種方法是一種逐漸演進的關系。下面,我們來看看4種對比學習結構的經典工作。關于對比學習的損失函數,建議參考之前的文章表示學習中的7大損失函數梳理。

End-to-End End-to-End是一種最直接的對比學習方法,對于一個query,每次采樣一個正樣本以及多個負樣本,使用對比學習loss計算損失,正樣本和負樣本都進行梯度反向傳播。下面介紹幾篇End-to-End的對比學習經典論文。
第一篇是Unsupervised Embedding Learning via Invariant and Spreading Instance Feature(2019)。本文的目標是學習圖像好的表示,滿足相似的圖像embedding離得近,不相似的圖像embedding離得遠的特點。具體的,希望同一個圖像經過不同的數據增強方式進行轉換后,能夠具有embedding的不變性,同時不同圖像的embedding有明顯差異。
這篇文章在原來每個樣本為一個類別的分類基礎上進行了優化,將每個圖像進行一種數據增強的轉換后,去讓轉換前后的圖像的embedding離得更近。首先采樣一個batch的圖像,然后對每一個圖像使用一種數據增強方法進行轉換。優化的目標是讓每一個圖像xi轉換后的圖像xi‘能夠被分為xi這個樣本的類別。模型的訓練仍然采用多個二分類的方式,每個樣本的loss可以表示為:

最終采用底層共享參數的孿生網絡結構進行模型訓練。在訓練階段,每個樣本的會使用該batch內其他樣本作為負樣本進行訓練,并使用一種隨機的argumentation策略生成一個正樣本。

LEARNING DEEP REPRESENTATIONS BY MUTUAL INFORMATION ESTIMATION AND MAXIMIZATION(ICLR 2019,DIM)是另一個典型的End-to-End對比學習框架。本文提出在Deep InfoMax基礎上進行對比學習,首先介紹一下Deep InfoMax。Deep InfoMax是一種無監督圖像表示學習方法,目標是讓輸入樣本和其經過Encoder后的表示互信息最大,互信息越大表明兩個變量相關性越強,互信息可以采用InfoNCE、Jensen-Shannon MI estimator等方法求解。
具體實現上,隨機采樣一個圖像,經過卷積得到feature map f(x),再經過網絡得到一個圖像的表示向量h(f(x)),整個過程相當于取了整個encoder中某一層的表示f(x),以及encoder的最終輸出h(f(x)),讓這兩個表示的互信息盡可能大。同時隨機選擇其他圖像,生成其feature map f(x’)。這樣f(x)和h(f(x))構成正樣本,f(x‘)和h(f(x))構成負樣本,再代入loss進行優化。基本思路采用了MINE的方法,去求一個下界。使用一個discriminator去判別輸入是配對的feature map和representaion的聯合概率分布還是不配對的feature map和representaion的邊緣概率分布的乘積。
最終學習的是中間表示中某一個部分的信息和最終encoder得到feature的相關性,互信息可以理解為在是否獲取encoder最終表示的情況下,我們能預測出的中間層某部分的表示會好多少。這是使用相對的預估能力而非絕對的預估能力進行評估。


Learning Representations by Maximizing Mutual Information Across Views(2019)擴展了DIM,學習一個圖像的兩種不同增強方式的互信息最小。DIM使用同一張圖像最終層和中間層的表示計算互信息,而本文采用一個圖像的不同增強后的view計算。

End-to-End方法的主要問題在于,采樣的負樣本數量受到GPU內存限制,因此這種方法的每次更新能夠使用到的負樣本數量非常有限,影響了對比學習效果。 Memory Bank 針對End-to-End負樣本采樣數量受GPU內存限制的問題,基于Memory Bank的方法進入人們視野。Memory Bank的核心思路是,將某一輪模型對數據集中所有樣本的表示存儲起來,這些樣本在作為負樣本時,可以不進行梯度更新,極大提升了每個batch負樣本數量。
Memory Bank對比學習的主要論文是Unsupervised feature learning via non-parametric instance discrimination(ICLR 2018)。當進行圖像分類時,如果兩個類別的圖像相似,那么模型更容易把這兩類的預測搞混,softmax得分排第二的的類別往往是和待預測類別比較相似的。這說明模型在學習的過程中,能夠從圖像數據本身學出哪些圖片表達相似的事物,而不需要引入標簽。因此本文希望只利用無監督的圖片,就學習出比較好的圖像表示,將原來的分類問題進行一個擴展,每個圖片視為一個類別,做多分類任務,這樣無需有監督數據就能學習圖像表示。同時,將softmax中每個類別對應的權重替換為每個樣本的embedding結果,將原來的softmax去掉每個類別的權重參數w后變為了 non-parametric softmax,最終表示為:

然而一個圖像為一個類別帶來的問題是計算softmax多分類損失時,分類的類別數和樣本數相同。因此本文提出利用InfoNCE loss來近似擬合softmax多分類損失,它與層次softmax、negative sampling都是解決類別較多時多分為問題的高效方法。InfoNCE loss將多分類問題轉換為多個二分類問題,原來是預測當前樣本屬于哪個類別,轉換成判斷每個樣本(一個正樣本和多個負樣本)是否和當前樣本匹配,或區分數據樣本和噪聲樣本。 為了提升運行效率,本文采用Model Bank的方法,每個樣本的表示更新后會存儲到model bank中。下次需要負樣本的時候直接從model bank取該樣本表示,而不會進行前向計算和反向傳播。每個類別只有一個樣本會導致模型訓練不穩定,因此本文在損失函數中引入平滑項,讓模型在t輪迭代計算的表示和t-1輪相似,引入兩輪表示的L2正則。隨著模型不斷收斂,這一項L2正則會逐漸變為0,整體又變成原來的InfoNCE loss。

Model Bank方法的問題在于,Model Bank中存儲的樣本表示不是最新訓練的encoder產出的,和當前encoder生成的表示有一定差異,導致模型訓練過程存在問題,例如當前encoder產出的編碼可能要和n輪迭代之前產出的encoder編碼做比較。同時,Model Bank側兩次樣本表示更新不具備連續性,也會導致訓練不穩定 Momentum Encoder Momentum Encoder主要為了解決Model Bank中每個樣本緩存的表示和Encoder更新不一致的問題。Momentum Encoder的核心思路是,模型在key側的encoder不進行訓練,而是平滑拷貝query側encoder的參數,如下面的公式:

這種更新方式保證了key側參數的平滑性,且每次都能用最新的參數得到key側樣本的表示結果。典型的Momentum Encoder工作是Facebook提出的MoCo,論文Momentum Contrast for Unsupervised Visual Representation Learning。

In-Batch Negtive In-Batch Negtive也是對比學習中經常采用的一種擴大負樣本數量的方法。對于匹配問題,假設每個batch內有N個正樣本對,那么讓這N個正樣本之間互為負樣本,這樣每個樣本就自動生成了2*(N-1)個負樣本。這種技巧提出的很早,在近期對比學習中又得到非常廣泛的應用。
A Simple Framework for Contrastive Learning of Visual Representations(2020)就采用了In-Btahc Negtive的方法。此外,本文也提出了對比學習的一些關鍵發現,包括對數據的argumentation的方式、batch size的大小、生成的embedding進行normalize、對對比學習loss的temperature進行調節都對對比學習效果有重要影響。融合了上述優化,本文提出SimCLR對比學習框架,以最大化同一個圖像經過不同argumentation后表示的相關性為目標。整個流程分為3個步驟,首先對圖像進行兩種不同的增強得到一對正樣本,然后經過Encoder得到表示,最后將表示映射后計算對比學習loss,采用In-Batch Negtive的方法進行學習。
在圖像和文本匹配的多模態領域,In-Batch Negtive也非常常用,例如Learning Transferable Visual Models From Natural Language Supervision提出的CLIP模型。In-Batch Negtive的優點是非常簡單,計算量不會顯著增加。缺點是負樣本只能使用每個batch內的數據,是隨機采樣的,無法針對性的構造負樣本。
總結 本文總結了對比學習的4種基本訓練結構,包括End-to-End、Memory Bank、Momentum Encoder以及In-Batch Negtive,以及各自的優缺點。對比學習訓練方式發展的核心是,如何實現量級更大、質量更好、更平穩的負樣本表示。通過優化負樣本,可以顯著提升對比學習的效果。 審核編輯:郭婷
-
gpu
+關注
關注
28文章
4777瀏覽量
129362 -
編碼
+關注
關注
6文章
957瀏覽量
54954
原文標題:對比學習中的4種經典訓練模式
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
半導體激光器和光纖激光器的對比分析
【書籍評測活動NO.54】典型電子電路設計與測試
zeta在機器學習中的應用 zeta的優缺點分析
RoCE與IB對比分析(二):功能應用篇
網關和路由器的對比分析
深度學習的典型模型和訓練過程
機器學習在數據分析中的應用
深度學習與傳統機器學習的對比
交流伺服電機與直流伺服電機的對比分析
不同地物分類方法在長江中下游典型湖區應用對比分析

4芯M16接頭不同類型的對比分析

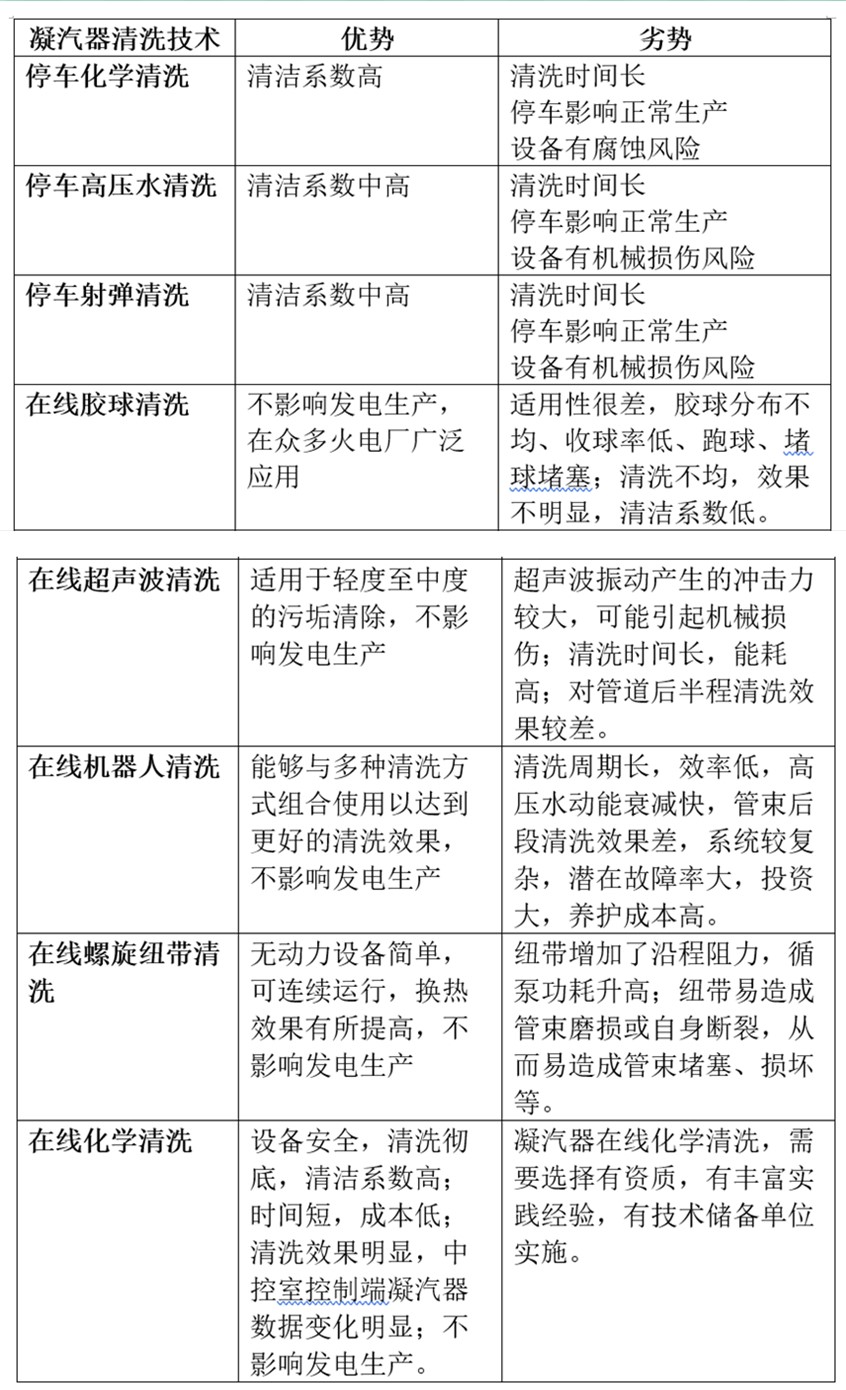
火電廠凝汽器不停車在線清洗與凝汽器停車清洗八種技術對比分析





 工商網監
工商網監
評論